Quando os usuários solicitam dados de um sistema, eles geralmente gostam de vê-los em uma ordem específica... mesmo quando estão retornando milhares de linhas. Como muitos DBAs e desenvolvedores sabem, ORDER BY pode causar estragos em um plano de consulta, porque requer que os dados sejam classificados. Às vezes, isso pode exigir um operador SORT como parte da execução da consulta, o que pode ser uma operação dispendiosa, principalmente se as estimativas estiverem incorretas e se espalharem para o disco. Em um mundo ideal, os dados já estão ordenados graças a um índice (índices e ordenações são muito complementares). Muitas vezes falamos sobre a criação de um índice de cobertura para satisfazer uma consulta – para que o otimizador não precise voltar para a tabela base ou índice clusterizado para obter colunas adicionais. E você pode ter ouvido as pessoas dizerem que a ordem das colunas no índice é importante. Você já considerou como isso afeta suas operações de SORT?
Examinando ORDER BY e Classificações
Começaremos com uma nova cópia do banco de dados AdventureWorks2014 em uma instância do SQL Server 2014 (versão 12.0.2000). Se executarmos uma consulta SELECT simples em Sales.SalesOrderHeader sem ORDER BY, veremos um simples e antigo Clustered Index Scan (usando o SQL Sentry Plan Explorer):
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader];
 Consulta sem ORDER BY, verificação de índice clusterizado
Consulta sem ORDER BY, verificação de índice clusterizado Agora vamos adicionar um ORDER BY para ver como o plano muda:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID];
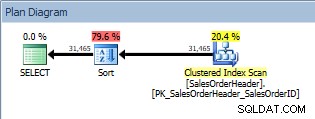 Consulte com um ORDER BY, verificação de índice clusterizado e uma classificação
Consulte com um ORDER BY, verificação de índice clusterizado e uma classificação Além do Clustered Index Scan, agora temos um Sort introduzido pelo otimizador e seu custo estimado é significativamente maior do que o do scan. Agora, o custo estimado é apenas estimado, e não podemos dizer com absoluta certeza aqui que o Sort levou 79,6% do custo da consulta. Para realmente entender o quão caro é o Sort, precisaríamos olhar também para IO STATISTICS, que está além do objetivo de hoje.
Agora, se essa fosse uma consulta executada com frequência em seu ambiente, você provavelmente consideraria adicionar um índice para suportá-la. Nesse caso, não há cláusula WHERE, estamos apenas recuperando quatro colunas e ordenando por uma delas. Uma primeira tentativa lógica em um índice seria:
CREATE NONCLUSTERED INDEX [IX_SalesOrderHeader_CustomerID_OrderDate_SubTotal] ON [Sales].[SalesOrderHeader]( [CustomerID] ASC) INCLUDE ( [OrderDate], [SubTotal]);
Vamos reexecutar nossa consulta depois de adicionar o índice que tem todas as colunas que queremos e lembre-se de que o índice fez o trabalho de classificar os dados. Agora vemos uma varredura de índice em nosso novo índice não clusterizado:
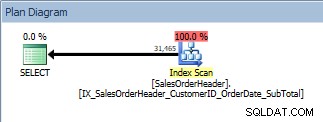 Consulte com um ORDER BY, o novo índice não clusterizado é verificado
Consulte com um ORDER BY, o novo índice não clusterizado é verificado Esta é uma boa notícia. Mas o que acontece se alguém alterar essa consulta – seja porque os usuários podem especificar por quais colunas desejam ordenar ou porque uma alteração foi solicitada a um desenvolvedor? Por exemplo, talvez os usuários queiram ver os CustomerIDs e SalesOrderIDs em ordem decrescente:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] DESC;
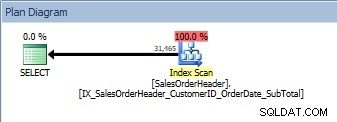 Consulta com duas colunas no ORDER BY, o novo índice não clusterizado é verificado
Consulta com duas colunas no ORDER BY, o novo índice não clusterizado é verificado Temos o mesmo plano; nenhum operador Sort foi adicionado. Se olharmos para o índice usando o sp_helpindex de Kimberly Tripp (algumas colunas recolhidas para economizar espaço), podemos ver porque o plano não mudou:
 Saída de sp_helpindex
Saída de sp_helpindex A coluna de chave para o índice é CustomerID, mas como SalesOrderID é a coluna de chave para o índice clusterizado, ela também faz parte da chave de índice, portanto, os dados são classificados por CustomerID e, em seguida, SalesOrderID. A consulta solicitou os dados classificados por essas duas colunas, em ordem decrescente. O índice foi criado com as duas colunas em ordem crescente, mas por ser uma lista duplamente vinculada, o índice pode ser lido de trás para frente. Você pode ver isso no painel Propriedades no Management Studio para o operador de verificação de índice não clusterizado:
 Painel de propriedades da verificação de índice não clusterizado, mostrando que estava para trás
Painel de propriedades da verificação de índice não clusterizado, mostrando que estava para trás Ótimo, sem problemas com essa consulta, mas e esta:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] DESC, [SalesOrderID] ASC;
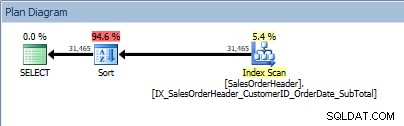 Consulta com duas colunas no ORDER BY e uma classificação é adicionada
Consulta com duas colunas no ORDER BY e uma classificação é adicionada Nosso operador SORT reaparece, pois os dados provenientes do índice não são classificados na ordem solicitada. Veremos o mesmo comportamento se classificarmos em uma das colunas incluídas:
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] ORDER BY [CustomerID] ASC, [OrderDate] ASC;
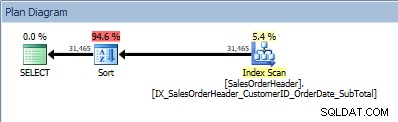 Consulta com duas colunas no ORDER BY e uma classificação é adicionada
Consulta com duas colunas no ORDER BY e uma classificação é adicionada O que acontece se (finalmente) adicionarmos um predicado e alterarmos ligeiramente o nosso ORDER BY?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] = 13464 ORDER BY [SalesOrderID];
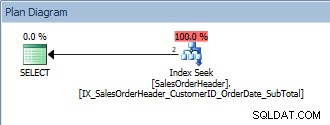 Consulta com um único predicado e um ORDER BY
Consulta com um único predicado e um ORDER BY Esta consulta está correta porque, novamente, SalesOrderID faz parte da chave de índice. Para este CustomerID, os dados já estão ordenados por SalesOrderID. E se consultarmos um intervalo de CustomerIDs, classificados por SalesOrderIDs?
SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 13464 AND 13466 ORDER BY [SalesOrderID];
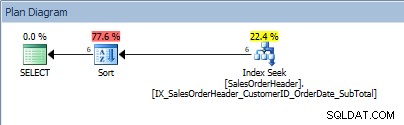 Consulta com um intervalo de valores no predicado e um ORDER BY
Consulta com um intervalo de valores no predicado e um ORDER BY Ratos, nosso SORT está de volta. O fato de os dados serem ordenados por CustomerID só ajuda na busca do índice para encontrar aquele intervalo de valores; para o ORDER BY SalesOrderID, o otimizador deve inserir o Sort para colocar os dados na ordem solicitada.
Agora, neste ponto, você pode estar se perguntando por que estou fixado no operador Sort que aparece nos planos de consulta. É porque é caro. Pode ser caro em termos de recursos (memória, IO) e/ou duração.
A duração da consulta pode ser afetada por uma classificação porque é uma operação de parada e partida. Todo o conjunto de dados deve ser classificado antes que a próxima operação no plano possa ocorrer. Se apenas algumas linhas de dados tiverem que ser ordenadas, isso não é grande coisa. Se são milhares ou milhões de linhas? Agora estamos esperando.
Além da duração geral da consulta, também temos que pensar no uso de recursos. Vamos pegar as 31.465 linhas com as quais estamos trabalhando e empurrá-las para uma variável de tabela e, em seguida, executar essa consulta inicial com ORDER BY em CustomerID:
DECLARE @t TABLE (CustomerID INT, SalesOrderID INT, OrderDate DATETIME, SubTotal MONEY); INSERT @t SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM [Sales].[SalesOrderHeader]; SELECT [CustomerID], [SalesOrderID], [OrderDate], [SubTotal] FROM @t ORDER BY [CustomerID];
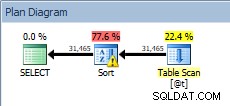 Consulte a variável da tabela, com a classificação
Consulte a variável da tabela, com a classificação Nosso SORT está de volta, e desta vez tem um aviso (observe o triângulo amarelo com o ponto de exclamação). Os avisos não são bons. Se observarmos as Propriedades da classificação, podemos ver o aviso "O operador usou o tempdb para derramar dados durante a execução com o nível de derramamento 1":
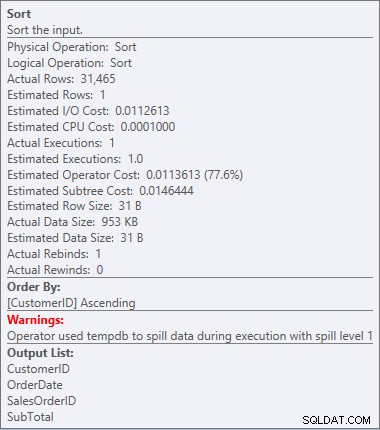 Aviso de classificação
Aviso de classificação Isso não é algo que eu quero ver em um plano. O otimizador fez uma estimativa de quanto espaço seria necessário na memória para classificar os dados e solicitou essa memória. Mas quando ele realmente tinha todos os dados e foi classificá-los, o mecanismo percebeu que não havia memória suficiente (o otimizador pediu muito pouco!), então a operação de classificação foi derramada. Em alguns casos, isso pode se espalhar para o disco, o que significa leituras e gravações – que são lentas. Não estamos apenas esperando para colocar os dados em ordem, é ainda mais lento porque não podemos fazer tudo na memória. Por que o otimizador não pediu memória suficiente? Ele tinha uma estimativa ruim sobre os dados que precisava classificar:
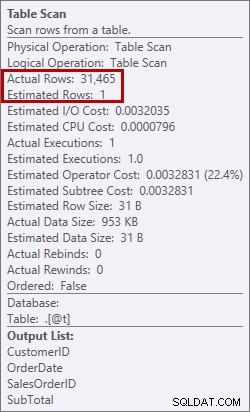 Estimativa de 1 linha versus real de 31.465 linhas
Estimativa de 1 linha versus real de 31.465 linhas Nesse caso, forcei uma estimativa ruim usando uma variável de tabela. Existem problemas conhecidos com estimativas de estatísticas e variáveis de tabela (Aaron Bertrand tem um ótimo post sobre opções para tentar resolver isso), e aqui, o otimizador acreditava que apenas 1 linha seria retornada da verificação da tabela, não 31.465.
Opções
Então, o que você, como DBA ou desenvolvedor, pode fazer para evitar SORTs em seus planos de consulta? A resposta rápida é:"Não peça seus dados". Mas isso nem sempre é realista. Em alguns casos, você pode descarregar essa classificação para o cliente ou para uma camada de aplicativo - mas os usuários ainda precisam esperar para classificar os dados naquele camada. Nas situações em que você não pode alterar o funcionamento do aplicativo, pode começar examinando seus índices.
Se você oferece suporte a um aplicativo que permite que os usuários executem consultas ad-hoc ou altere a ordem de classificação para que eles possam ver os dados ordenados como quiserem... não pare de ler ainda!). Você não pode indexar para todas as opções. É ineficiente e você criará mais problemas do que resolverá. Sua melhor aposta aqui é conversar com os usuários (eu sei, às vezes é assustador sair do seu canto da floresta, mas tente). Para as consultas que os usuários executam com mais frequência, descubra como eles normalmente gostam de ver os dados. Sim, você também pode obter isso do cache do plano - você pode recuperar consultas e planos até o conteúdo do seu coração para ver o que eles estão fazendo. Mas é mais rápido falar com os usuários. O benefício adicional é que você pode explicar por que está perguntando e por que essa ideia de "classificar todas as colunas porque posso" não é tão boa. O saber é metade da batalha. Se você puder gastar algum tempo educando seus usuários avançados e os usuários que treinam novas pessoas, poderá fazer algo de bom.
Se você oferecer suporte a um aplicativo com opções limitadas de ORDER BY, poderá fazer uma análise real. Revise quais variações ORDER BY existem, determine quais combinações são executadas com mais frequência e indexe para dar suporte a essas consultas. Você provavelmente não atingirá todos, mas ainda pode causar impacto. Você pode dar um passo adiante conversando com seus desenvolvedores e educando-os sobre o problema e como resolvê-lo.
Por fim, quando você estiver analisando planos de consulta com operações SORT, não se concentre apenas em remover o Sort. Veja onde a classificação ocorre no plano. Se acontecer à esquerda do plano e for normalmente algumas linhas, pode haver outras áreas com um fator de melhoria maior para focar. A classificação à esquerda é o padrão em que focamos hoje, mas uma classificação nem sempre ocorre devido a um ORDER BY. Se você vir uma classificação na extremidade direita do plano e houver muitas linhas passando por essa parte do plano, você saberá que encontrou um bom lugar para começar a ajustar.