Em um mundo perfeito, não importaria qual sintaxe T-SQL específica escolhemos para expressar uma consulta. Qualquer construção semanticamente idêntica levaria exatamente ao mesmo plano de execução física, com exatamente as mesmas características de desempenho.
Para conseguir isso, o otimizador de consultas do SQL Server precisaria conhecer todas as equivalências lógicas possíveis (supondo que pudéssemos conhecê-las todas) e ter tempo e recursos para explorar todas as opções. Dado o enorme número de maneiras possíveis de expressar o mesmo requisito em T-SQL e o grande número de transformações possíveis, as combinações rapidamente se tornam incontroláveis para todos, exceto para os casos mais simples.
Um "mundo perfeito" com total independência de sintaxe pode não parecer tão perfeito para usuários que precisam esperar dias, semanas ou até anos para que uma consulta modestamente complexa seja compilada. Assim, o otimizador de consulta se compromete:ele explora algumas equivalências comuns e se esforça para evitar gastar mais tempo em compilação e otimização do que economiza em tempo de execução. Seu objetivo pode ser resumido como tentar encontrar um plano de execução razoável em um tempo razoável, consumindo recursos razoáveis.
Um resultado de tudo isso é que os planos de execução geralmente são sensíveis à forma escrita da consulta. O otimizador tem alguma lógica para transformar rapidamente algumas construções equivalentes amplamente usadas em uma forma comum, mas essas habilidades não são bem documentadas nem (em qualquer lugar perto) abrangentes.
Certamente podemos maximizar nossas chances de obter um bom plano de execução escrevendo consultas mais simples, fornecendo índices úteis, mantendo boas estatísticas e nos limitando a conceitos mais relacionais (por exemplo, evitando cursores, loops explícitos e funções não-inline), mas isso é não uma solução completa. Também não é possível dizer que uma construção T-SQL irá sempre produzir um plano de execução melhor que uma alternativa semanticamente idêntica.
Meu conselho usual é começar com o formulário de consulta relacional mais simples que atenda às suas necessidades, usando qualquer sintaxe T-SQL que você achar preferível. Se a consulta não atender aos requisitos após a otimização física (por exemplo, indexação), pode valer a pena tentar expressar a consulta de uma maneira ligeiramente diferente, mantendo a semântica original. Esta é a parte complicada. Qual parte da consulta você deve tentar reescrever? Qual reescrita você deve tentar? Não existe uma resposta simples para todas essas perguntas. Parte disso se resume à experiência, embora saber um pouco sobre otimização de consultas e mecanismos de execução internos também possa ser um guia útil.
Exemplo
Este exemplo usa a tabela TransactionHistory do AdventureWorks. O script abaixo faz uma cópia da tabela e cria um índice clusterizado e não clusterizado. Não modificaremos os dados; esta etapa é apenas para tornar a indexação clara (e para dar à tabela um nome mais curto):
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
A tarefa é produzir uma lista de IDs de produtos e históricos para seis produtos específicos. Uma maneira de expressar a consulta é:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360);
Esta consulta retorna 764 linhas usando o seguinte plano de execução (mostrado no SentryOne Plan Explorer):

Essa consulta simples se qualifica para a compilação do plano TRIVIAL. O plano de execução apresenta seis operações de busca de índice separadas em uma:
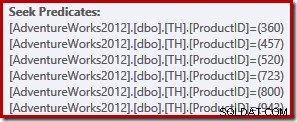
Leitores atentos devem ter notado que as seis buscas estão listadas em ascendente ordem de ID do produto, não na ordem (arbitrária) especificada na lista IN da consulta original. De fato, se você mesmo executar a consulta, é bem provável que observe os resultados sendo retornados em ordem crescente de ID do produto. A consulta não é garantida para retornar resultados nessa ordem, é claro, porque não especificamos uma cláusula ORDER BY de nível superior. No entanto, podemos adicionar uma cláusula ORDER BY, sem alterar o plano de execução produzido neste caso:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID;
Não vou repetir o gráfico do plano de execução, porque é exatamente o mesmo:a consulta ainda se qualifica para um plano trivial, as operações de busca são exatamente as mesmas e os dois planos têm exatamente o mesmo custo estimado. Adicionar a cláusula ORDER BY não nos custou exatamente nada, mas nos deu uma garantia de ordenação do conjunto de resultados.
Agora temos a garantia de que os resultados serão retornados na ordem do ID do produto, mas nossa consulta não especifica como as linhas com o mesmo ID do produto será pedido. Observando os resultados, você pode observar que as linhas para o mesmo ID de produto parecem ser ordenadas por ID de transação, em ordem crescente.
Sem um ORDER BY explícito, esta é apenas outra observação (ou seja, não podemos confiar nessa ordenação), mas podemos modificar a consulta para garantir que as linhas sejam ordenadas por ID de transação em cada ID de produto:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Novamente, o plano de execução para esta consulta é exatamente o mesmo de antes; o mesmo plano trivial com o mesmo custo estimado é produzido. A diferença é que os resultados agora são garantidos a ser pedido primeiro pelo ID do produto e depois pelo ID da transação.
Algumas pessoas podem ficar tentadas a concluir que as duas consultas anteriores também sempre retornariam linhas nesta ordem, porque os planos de execução são os mesmos. Esta não é uma implicação segura, porque nem todos os detalhes do mecanismo de execução são expostos nos planos de execução (mesmo no formato XML). Sem uma cláusula order by explícita, o SQL Server é livre para retornar as linhas em qualquer ordem, mesmo que o plano pareça o mesmo para nós (ele poderia, por exemplo, realizar as buscas na ordem especificada no texto da consulta). A questão é que o otimizador de consulta conhece e pode impor certos comportamentos dentro do mecanismo que não são visíveis para os usuários.
Caso você esteja se perguntando como nosso índice não exclusivo não clusterizado no ID do produto pode retornar linhas no produto e Ordem de ID de transação, a resposta é que a chave de índice não clusterizada incorpora a ID de transação (a chave de índice clusterizada exclusiva). Na verdade, o físico estrutura do nosso índice não clusterizado é exatamente o mesmo, em todos os níveis, como se tivéssemos criado o índice com a seguinte definição:
CREATE UNIQUE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID, TransactionID);
Podemos até escrever a consulta com um DISTINCT ou GROUP BY explícito e ainda obter exatamente o mesmo plano de execução:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Para ser claro, isso não requer nenhuma alteração no índice não clusterizado original. Como exemplo final, observe que também podemos solicitar resultados em ordem decrescente:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID DESC, TransactionID DESC;
As propriedades do plano de execução agora mostram que o índice é varrido para trás:

Fora isso, o plano é o mesmo – foi produzido na fase de otimização do plano trivial, e ainda tem o mesmo custo estimado.
Reescrevendo a consulta
Não há nada de errado com a consulta ou plano de execução anterior, mas podemos ter escolhido expressar a consulta de forma diferente:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 OR ProductID = 723 OR ProductID = 457 OR ProductID = 800 OR ProductID = 943 OR ProductID = 360;
Claramente, este formulário especifica exatamente os mesmos resultados que o original e, de fato, a nova consulta produz o mesmo plano de execução (plano trivial, várias buscas em uma, mesmo custo estimado). O formulário OR talvez deixe um pouco mais claro que o resultado é uma combinação dos resultados para os seis IDs de produtos individuais, o que pode nos levar a tentar outra variação que torna essa ideia ainda mais explícita:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 723 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 457 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 800 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 943 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 360;
O plano de execução para a consulta UNION ALL é bem diferente:
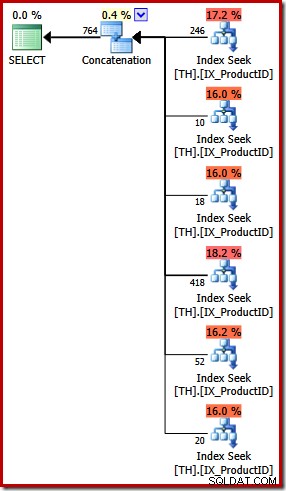
Além das diferenças visuais óbvias, esse plano exigia otimização baseada em custos (FULL) (não se qualificava para um plano trivial), e o custo estimado é (relativamente falando) um pouco mais alto, em torno de 0,02> unidades versus cerca de 0,005 unidades antes.
Isso remonta às minhas observações iniciais:o otimizador de consulta não conhece todas as equivalências lógicas e nem sempre pode reconhecer consultas alternativas como especificando os mesmos resultados. O ponto que estou enfatizando neste estágio é que expressar essa consulta específica usando UNION ALL em vez de IN resultou em um plano de execução menos ideal.
Segundo exemplo
Este exemplo escolhe um conjunto diferente de seis IDs de produto e as solicitações resultam no pedido de ID da transação:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Nosso índice não clusterizado não pode fornecer linhas na ordem solicitada, portanto, o otimizador de consulta pode escolher entre procurar no índice não clusterizado e classificar ou verificar o índice clusterizado (que é codificado apenas no ID da transação) e aplicar os predicados do ID do produto como um resíduo. Os IDs de produtos listados têm uma seletividade menor do que o conjunto anterior, portanto, o otimizador escolhe uma verificação de índice clusterizado neste caso:
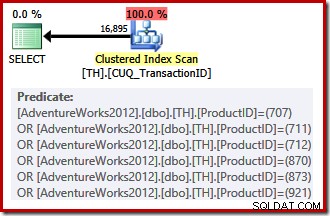
Como há uma escolha baseada em custo a ser feita, esse plano de execução não se qualifica para um plano trivial. O custo estimado do plano final é de cerca de 0,714 unidades. A verificação do índice clusterizado requer 797 leituras lógicas em tempo de execução.
Talvez surpresos que a consulta não tenha usado o índice do produto, podemos tentar forçar uma busca do índice não clusterizado usando uma dica de índice ou especificando FORCESEEK:
SELECT ProductID, TransactionID FROM dbo.TH WITH (FORCESEEK) WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
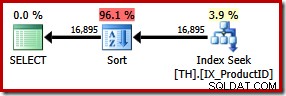
Isso resulta em uma classificação explícita por ID de transação. Estima-se que a nova classificação represente 96% do 1,15 do novo plano custo unitário. Esse custo estimado mais alto explica por que o otimizador escolheu a varredura de índice clusterizado aparentemente mais barata quando deixada por conta própria. O custo de E/S da nova consulta é menor:quando executado, a busca de índice consome apenas 49 leituras lógicas (abaixo de 797).
Também podemos ter escolhido expressar essa consulta usando a ideia UNION ALL (anteriormente malsucedida):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
O programa produz o seguinte plano de execução (clique na imagem para ampliar em uma nova janela):

Este plano pode parecer mais complexo, mas tem um custo estimado de apenas 0,099 unidades, que é muito menor do que a varredura de índice clusterizado (0,714 unidades) ou busca mais classificação (1,15 unidades). Além disso, o novo plano consome apenas 49 leituras lógicas em tempo de execução – o mesmo que o plano de busca + classificação e muito menor que o 797 necessário para a varredura de índice clusterizado.
Desta vez, expressar a consulta usando UNION ALL produziu um plano muito melhor, tanto em termos de custo estimado quanto de leituras lógicas. O conjunto de dados de origem é um pouco pequeno demais para fazer uma comparação realmente significativa entre as durações da consulta ou o uso da CPU, mas a verificação do índice clusterizado leva duas vezes mais (26 ms) que as outras duas no meu sistema.
A classificação extra no plano sugerido é provavelmente inofensiva neste exemplo simples porque é improvável que seja derramado no disco, mas muitas pessoas preferirão o plano UNION ALL de qualquer maneira porque não é bloqueante, evita uma concessão de memória e não requer um dica de consulta.
Conclusão
Vimos que a sintaxe de consulta pode afetar o plano de execução escolhido pelo otimizador, mesmo que as consultas especifiquem logicamente exatamente o mesmo conjunto de resultados. A mesma reescrita (por exemplo, UNION ALL) às vezes resultará em uma melhoria e às vezes fará com que um plano pior seja selecionado.
Reescrever consultas e tentar sintaxe alternativa é uma técnica de ajuste válida, mas é necessário algum cuidado. Um risco é que alterações futuras no produto possam fazer com que o formulário de consulta diferente pare de produzir o melhor plano de repente, mas pode-se argumentar que é sempre um risco e mitigado por testes de pré-atualização ou pelo uso de guias de plano.
Há também o risco de se deixar levar por essa técnica: o uso de construções de consulta 'estranhas' ou 'incomuns' para obter um plano de melhor desempenho geralmente é um sinal de que uma linha foi ultrapassada. Exatamente onde está a distinção entre sintaxe alternativa válida e 'incomum/estranho' é provavelmente bastante subjetivo; meu próprio guia pessoal é trabalhar com formulários de consulta relacionais equivalentes e manter as coisas o mais simples possível.