No meu último post, mostrei algumas abordagens eficientes para concatenação agrupada. Desta vez, eu queria falar sobre algumas facetas adicionais desse problema que podemos resolver facilmente com o
FOR XML PATH abordagem:ordenar a lista e remover duplicatas. Existem algumas maneiras pelas quais as pessoas desejam que a lista separada por vírgulas seja ordenada. Às vezes eles querem que o item da lista seja ordenado alfabeticamente; Já mostrei isso no post anterior. Mas às vezes eles querem que ele seja classificado por algum outro atributo que na verdade não está sendo introduzido na saída; por exemplo, talvez eu queira ordenar a lista pelo item mais recente primeiro. Vamos dar um exemplo simples, onde temos uma tabela Employees e uma tabela CoffeeOrders. Vamos apenas preencher os pedidos de uma pessoa por alguns dias:
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double'); Se usarmos a abordagem existente sem especificar um
ORDER BY , obtemos uma ordenação arbitrária (neste caso, é mais provável que você veja as linhas na ordem em que foram inseridas, mas não dependa disso com conjuntos de dados maiores, mais índices etc.):SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultados (lembre-se, você pode obter resultados *diferentes* a menos que especifique um
ORDER BY ):Nome | Pedidos
Jack | Duplo grande duplo, duplo médio duplo, Large Vanilla Latte, duplo médio duplo
Se quisermos ordenar a lista em ordem alfabética, é simples; apenas adicionamos
ORDER BY c.OrderDetails :SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDetails -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultados:
Nome | Pedidos
Jack | Grande duplo duplo, Grande Vanilla Latte, Médio duplo duplo, Médio duplo duplo
Também podemos ordenar por uma coluna que não aparece no conjunto de resultados; por exemplo, podemos pedir primeiro o pedido de café mais recente:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDate DESC -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultados:
Nome | Pedidos
Jack | Duplo médio, Grande Baunilha Latte, Duplo Médio, Duplo Grande
Outra coisa que muitas vezes queremos fazer é remover duplicatas; afinal, há poucas razões para ver "Medium double double" duas vezes. Podemos eliminar isso usando
GROUP BY :SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Agora, isso *acontece* de ordenar a saída em ordem alfabética, mas, novamente, você não pode confiar nisso:
Nome | Pedidos
Jack | Grande duplo duplo, Grande Vanilla Latte, Duplo médio duplo
Se você quiser garantir esse pedido dessa maneira, basta adicionar um ORDER BY novamente:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDetails -- added ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Os resultados são os mesmos (mas repito, neste caso é apenas uma coincidência; se quiser esta ordem, diga sempre):
Nome | Pedidos
Jack | Grande duplo duplo, Grande Vanilla Latte, Duplo médio duplo
Mas e se quisermos eliminar duplicatas *e* ordenar a lista pelo pedido de café mais recente primeiro? Sua primeira inclinação pode ser manter o
GROUP BY e apenas altere o ORDER BY , assim:SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDate DESC -- changed ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Isso não funcionará, pois o
OrderDate não é agrupado ou agregado como parte da consulta:Msg 8127, Level 16, State 1, Line 64
A coluna "dbo.CoffeeOrders.OrderDate" é inválida na cláusula ORDER BY porque não está contida em uma função agregada ou na cláusula GROUP BY.
Uma solução alternativa, que reconhecidamente torna a consulta um pouco mais feia, é agrupar os pedidos separadamente primeiro e depois pegar apenas as linhas com a data máxima para esse pedido de café por funcionário:
;WITH grouped AS ( SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate) FROM dbo.CoffeeOrders GROUP BY EmployeeID, OrderDetails ) SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails FROM grouped AS g WHERE g.EmployeeID = e.EmployeeID ORDER BY g.OrderDate DESC FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Resultados:
Nome | Pedidos
Jack | Duplo médio duplo, Grande Baunilha Latte, Grande Duplo Duplo
Isso cumpre nossos dois objetivos:eliminamos duplicatas e ordenamos a lista por algo que não está realmente na lista.
Desempenho
Você pode estar se perguntando o desempenho desses métodos em um conjunto de dados mais robusto. Vou preencher nossa tabela com 100.000 linhas, ver como eles funcionam sem nenhum índice adicional e, em seguida, executar as mesmas consultas novamente com um pouco de ajuste de índice para dar suporte às nossas consultas. Então, primeiro, obter 100.000 linhas espalhadas por 1.000 funcionários:
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c; Agora vamos apenas executar cada uma de nossas consultas duas vezes e ver como é o tempo na segunda tentativa (daremos um salto de fé aqui e assumiremos que - em um mundo ideal - estaremos trabalhando com um cache preparado ). Eu os executei no SQL Sentry Plan Explorer, já que é a maneira mais fácil que conheço de cronometrar e comparar várias consultas individuais:
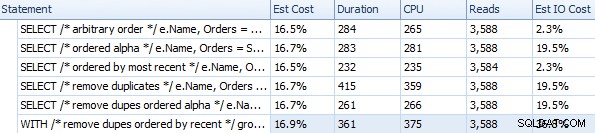 Duração e outras métricas de tempo de execução para diferentes abordagens FOR XML PATH
Duração e outras métricas de tempo de execução para diferentes abordagens FOR XML PATH Esses tempos (a duração é em milissegundos) realmente não são tão ruins assim IMHO, quando você pensa sobre o que realmente está sendo feito aqui. O plano mais complicado, pelo menos visualmente, parecia ser aquele em que removemos duplicatas e classificamos por ordem mais recente:
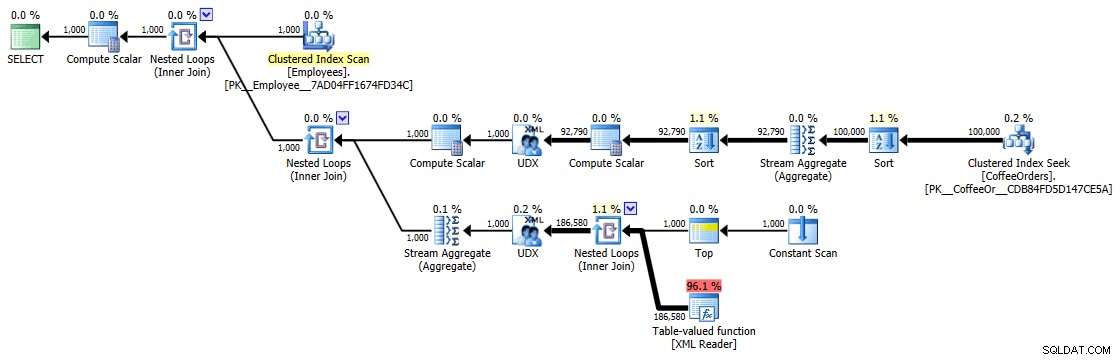 Plano de execução para consulta agrupada e classificada
Plano de execução para consulta agrupada e classificada Mas mesmo o operador mais caro aqui - a função com valor de tabela XML - parece ser todo CPU (mesmo que eu admita livremente que não tenho certeza de quanto do trabalho real é exposto nos detalhes do plano de consulta):
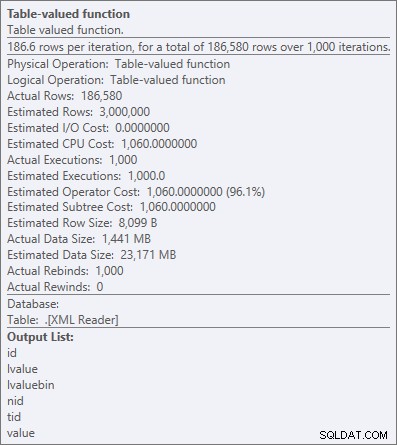 Propriedades do operador para a função com valor de tabela XML
Propriedades do operador para a função com valor de tabela XML "Toda a CPU" normalmente é aceitável, já que a maioria dos sistemas é vinculada a E/S e/ou vinculada à memória, não vinculada à CPU. Como eu digo com frequência, na maioria dos sistemas eu troco parte do meu espaço de CPU por memória ou disco em qualquer dia da semana (uma das razões pelas quais eu gosto de
OPTION (RECOMPILE) como uma solução para problemas generalizados de detecção de parâmetros). Dito isso, recomendo fortemente que você teste essas abordagens em relação a resultados semelhantes que você pode obter da abordagem GROUP_CONCAT CLR no CodePlex, bem como realizar a agregação e classificação na camada de apresentação (especialmente se você estiver mantendo os dados normalizados em algum tipo da camada de cache).