Em nossas postagens anteriores desta série, discutimos o caso do pool de conexões e apresentamos o PgBouncer. Neste post, discutiremos sua alternativa mais popular – Pgpool-II.
Pgpool-II é o canivete suíço do middleware PostgreSQL. Ele suporta alta disponibilidade, fornece balanceamento de carga automatizado e tem a inteligência para equilibrar a carga entre mestres e escravos, de modo que as cargas de gravação sejam sempre direcionadas aos mestres, enquanto as cargas de leitura são direcionadas aos escravos. O Pgpool-II também fornece replicação lógica. Embora seu uso e importância tenham diminuído à medida que as opções de replicação incorporadas melhoraram no lado do servidor PostgreSQL, isso ainda continua sendo uma opção valiosa para versões mais antigas do PostgreSQL. Além de tudo isso, ele também fornece pool de conexões!
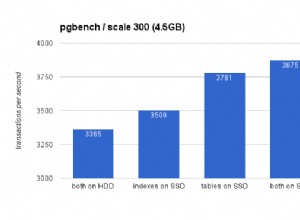
De relance | ||||||
|---|---|---|---|---|---|---|
|



Configurando o Pgpool-II
Os binários do Pgpool-II são distribuídos pelos repositórios do Pgpool-II – você pode ler mais sobre instalação neste documento de ajuda. Uma vez instalado, devemos configurar o Pgpool-II para habilitar os serviços que desejamos e conectar ao servidor PostgreSQL. Você pode ler mais sobre isso aqui.
Para obter uma configuração de pool mínima, você deve fornecer o seguinte:
- O nome de usuário e a senha criptografada em md5 do(s) usuário(s) que se conectarão ao Pgpool-II – isso deve ser definido em um arquivo separado, que pode ser facilmente gerado usando o utilitário pg_md5.
- Interfaces/endereços IP e número da porta para ouvir as conexões de entrada – isso deve ser definido no arquivo de configuração.
- O nome do host do(s) servidor(es) de back-end [Mais de um servidor é especificado apenas se desejarmos usar replicação e/ou balanceamento de carga].
- Os serviços que você deseja habilitar. Por padrão, o pool de conexões está ativado e outros serviços estão desativados no arquivo de configuração instalado com os binários.
E é isso – estamos prontos para começar! Embora as configurações disponíveis com o Pgpool-II possam ser mais assustadoras à primeira vista, o pessoal por trás do Pgpool-II realmente facilitou para nós!
Como funciona
O Pgpool-II tem uma arquitetura mais envolvente que o PgBouncer para suportar todos os recursos que ele oferece. No entanto, nesta seção, nos limitaremos a descrever como o pool de conexões funciona.
O processo pai do Pgpool-II bifurca 32 processos filhos por padrão – estes estão disponíveis para conexão. A arquitetura é semelhante ao servidor PostgreSQL:um processo =uma conexão. Ele também bifurca o 'processo pcp' que é usado para tarefas administrativas e além do escopo deste post. As 32 crianças estão agora prontas para aceitar conexões. Como o PgBouncer, eles também emulam um servidor PostgreSQL – os clientes podem se conectar exatamente com a mesma string de conexão que fariam com um servidor PostgreSQL normal.

O kernel direciona as conexões de entrada para um dos processos filhos registrados como ouvintes. Nem o processo Pgpool-II principal nem os usuários finais têm controle sobre qual processo filho responde a uma solicitação recebida. Qualquer criança ociosa pode pegar o pedido. Se nenhum filho ocioso for encontrado, a solicitação de conexão será enfileirada no lado do kernel – isso pode fazer com que aplicativos como o pgbench travem, aguardando conexões do cliente.
Uma vez que um filho Pgpool-II ocioso recebe uma solicitação de conexão, ele:
- Verifica o nome de usuário em seu arquivo de senha. Se não for encontrado, ele rejeita a conexão.
- Se o nome de usuário for encontrado, ele verifica a senha fornecida em relação ao hash md5 armazenado neste arquivo.
- Quando a autenticação for bem-sucedida, ela verificará se já possui uma conexão em cache para esta combinação de banco de dados+usuário.
- Se isso acontecer, ele retornará a conexão com o cliente. Caso contrário, ele abre uma nova conexão.
- Todas as solicitações e respostas passam pelo Pgpool-II enquanto ele aguarda a desconexão do cliente.
- Uma vez que o cliente se desconecta, o Pgpool-II precisa decidir se a conexão será armazenada em cache:
- Se tiver um slot vazio, ele o armazenará em cache.
- Se não tiver um slot vazio (ou seja, o armazenamento em cache dessa conexão excederia o max_pool_size permitido), ele decidirá com base em um algoritmo interno.
- Se decidir armazenar a conexão em cache, ele executará a consulta de redefinição pré-configurada para limpar todos os detalhes da sessão e torná-la segura para reutilização por um cliente diferente.
- Agora o processo filho está livre para obter mais conexões.

|

O que o Pgpool-II não faz?
Infelizmente, para aqueles que se concentram apenas no pool de conexões, o que o Pgpool-II não faz muito bem é o pool de conexões, especialmente para um pequeno número de clientes. Como cada processo filho tem seu próprio pool e não há como controlar qual cliente se conecta a qual processo filho, muita coisa é deixada de lado quando se trata de reutilizar conexões.
Como você pode ver, Pgpool e PgBouncer têm pontos fortes bastante diferentes – em nosso post final da série, faremos um teste direto , e comparação de recursos! Fique atento!
Série de pool de conexões PostgreSQL
|
|---|