O agrupamento é um recurso importante que ajuda a organizar e organizar os dados. Há muitas maneiras de fazer isso, e um dos métodos mais eficazes é a cláusula SQL GROUP BY.
Você pode usar SQL GROUP BY para dividir linhas em resultados em grupos com uma função de agregação . Parece fácil somar, calcular a média ou contar registros com ele.
Mas você está fazendo certo?
“Certo” pode ser subjetivo. Quando é executado sem erros críticos com uma saída correta, é considerado bom. No entanto, também precisa ser rápido.
Neste artigo, a velocidade também será considerada. Você verá muita análise de consultas usando leituras lógicas e planos de execução em todos os pontos.
Vamos começar.
1. Filtrar antecipadamente
Se você está confuso sobre quando usar WHERE e HAVING, este é para você. Porque dependendo da condição que você fornecer, ambos podem dar o mesmo resultado.
Mas são diferentes.
HAVING filtra os grupos usando as colunas na cláusula SQL GROUP BY. WHERE filtra as linhas antes que ocorram agrupamentos e agregações. Portanto, se você filtrar usando a cláusula HAVING, o agrupamento ocorrerá para todos linhas retornadas.
E isso é ruim.
Por quê? A resposta curta é:é lento. Vamos provar isso com 2 consultas. Confira o código abaixo. Antes de executá-lo no SQL Server Management Studio, pressione Ctrl-M primeiro.
SET STATISTICS IO ON
GO
-- using WHERE
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
ORDER BY Product, OrderYear, OrderMonth;
-- using HAVING
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
HAVING YEAR(soh.OrderDate) = 2012
ORDER BY Product, OrderYear, OrderMonth;
SET STATISTICS IO OFF
GO
Análise
As 2 instruções SELECT acima retornarão as mesmas linhas. Ambos estão corretos em devolver pedidos de produtos por mês no ano de 2012. Mas o primeiro SELECT demorou 136ms. para rodar no meu laptop, enquanto outro levou 764ms.!
Por quê?
Vamos verificar primeiro as leituras lógicas na Figura 1. O STATISTICS IO retornou esses resultados. Em seguida, colei-o em StatisticsParser.com para obter a saída formatada.
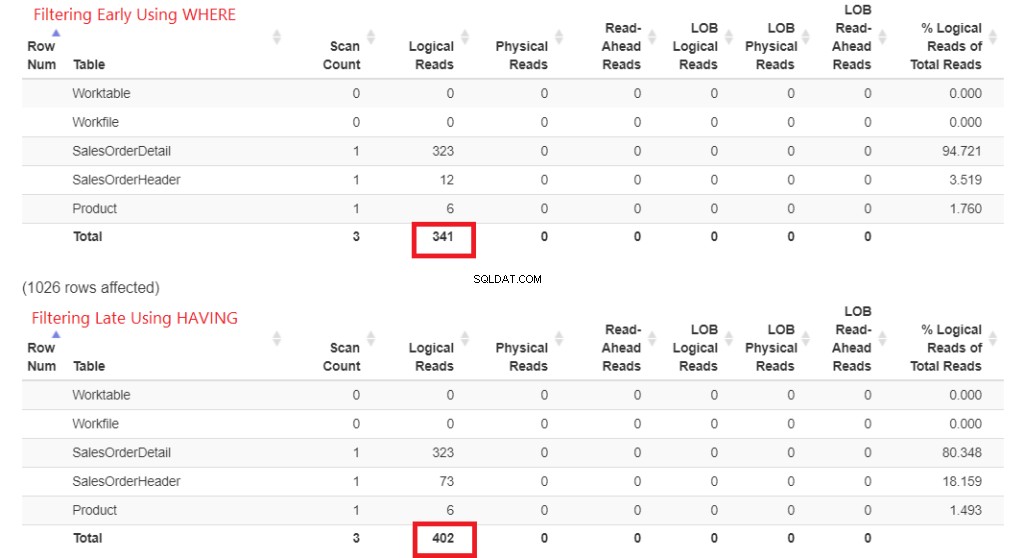
Figura 1 . Leituras lógicas de filtragem antecipada usando WHERE vs. filtragem tardia usando HAVING.
Veja o total de leituras lógicas de cada um. Para entender esses números, quanto mais leituras lógicas forem necessárias, mais lenta será a consulta. Então, isso prova que usar HAVING é mais lento, e filtrar antecipadamente com WHERE é mais rápido.
Claro, isso não significa que TER seja inútil. Uma exceção é ao usar HAVING com um agregado como HAVING SUM(sod.Linetotal)> 100000 . Você pode combinar uma cláusula WHERE e uma cláusula HAVING em uma consulta.
Veja o plano de execução na Figura 2.
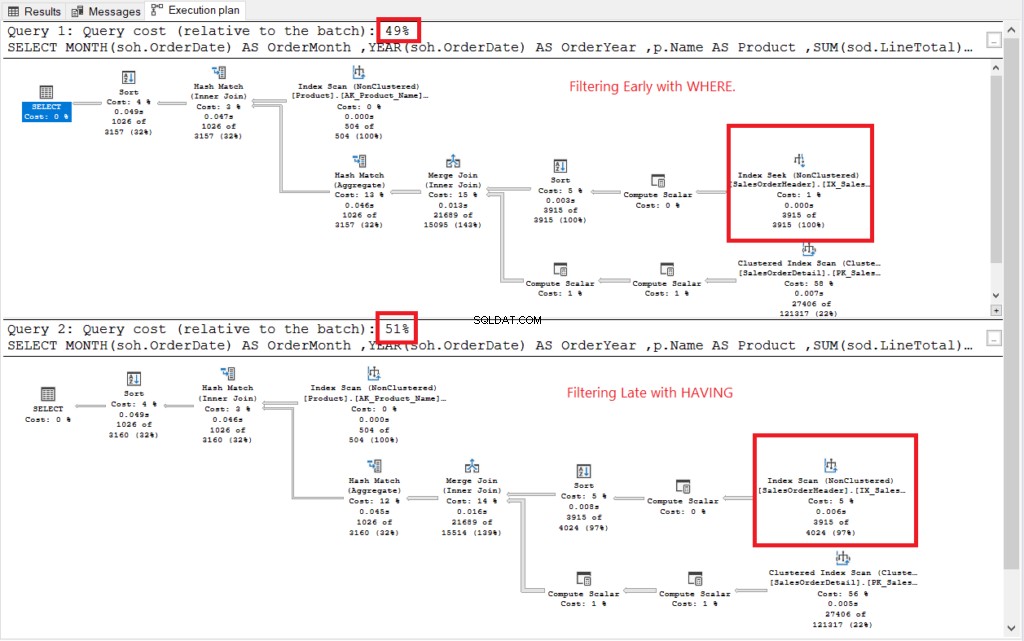
Figura 2 . Planos de execução de filtragem antecipada versus filtragem tardia.
Ambos os planos de execução pareciam semelhantes, exceto os marcados em vermelho. A filtragem inicial usava o operador Index Seek enquanto outro usava Index Scan. As buscas são mais rápidas do que as varreduras em tabelas grandes.
Não te: Filtrar cedo tem menos custo do que filtrar tarde. Portanto, o resultado final é filtrar as linhas antecipadamente para melhorar o desempenho.
2. Agrupe primeiro, junte-se depois
Unir algumas das tabelas necessárias posteriormente também pode melhorar o desempenho.
Digamos que você queira ter vendas mensais de produtos. Você também precisa obter o nome, o número e a subcategoria do produto na mesma consulta. Essas colunas estão em outra tabela. E todos eles precisam ser adicionados na cláusula GROUP BY para ter uma execução bem sucedida. Aqui está o código.
SET STATISTICS IO ON
GO
SELECT
p.Name AS Product
,p.ProductNumber
,ps.Name AS ProductSubcategory
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.name, p.ProductNumber, ps.Name
ORDER BY Product
SET STATISTICS IO OFF
GO
Isso vai correr bem. Mas há uma maneira melhor e mais rápida. Isso não exigirá que você adicione as 3 colunas para nome do produto, número e subcategoria na cláusula GROUP BY. No entanto, isso exigirá um pouco mais de pressionamentos de tecla. Aqui está.
SET STATISTICS IO ON
GO
;WITH Orders2012 AS
(
SELECT
sod.ProductID
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY sod.ProductID
)
SELECT
P.Name AS Product
,P.ProductNumber
,ps.Name AS ProductSubcategory
,o.ProductSales
FROM Orders2012 o
INNER JOIN Production.Product p ON o.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
ORDER BY Product;
SET STATISTICS IO OFF
GO
Análise
Por que isso é mais rápido? As junções ao Produto e ProductSubcategory são feitos posteriormente. Ambos não estão envolvidos na cláusula GROUP BY. Vamos provar isso por números no STATISTICS IO. Consulte a Figura 4.
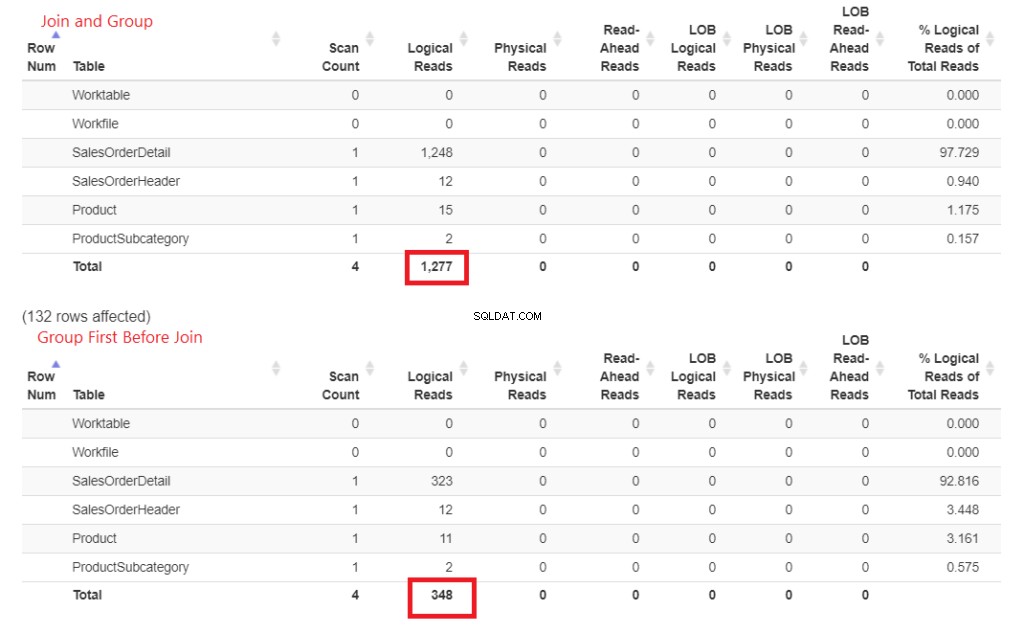
Figura 3 . A união antecipada e o agrupamento consumiam mais leituras lógicas do que as uniões posteriores.
Veja essas leituras lógicas? A diferença é grande, e o vencedor é óbvio.
Vamos comparar o plano de execução das 2 consultas para ver o motivo dos números acima. Primeiro, veja a Figura 4 para ver o plano de execução da consulta com todas as tabelas unidas quando agrupadas.
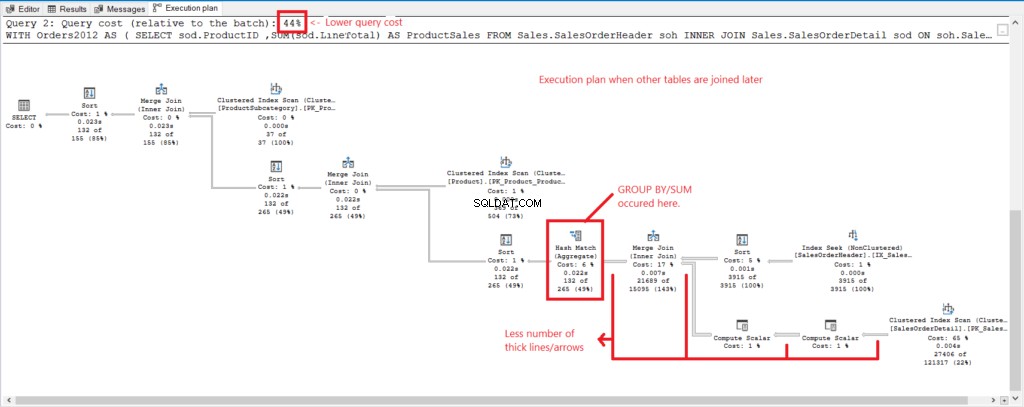
Figura 4 . Plano de execução quando todas as tabelas são unidas.
E temos as seguintes observações:
- GROUP BY e SUM foram feitos no final do processo após a junção de todas as tabelas.
- Muitas linhas e setas mais grossas – isso explica as 1.277 leituras lógicas.
- As 2 consultas combinadas formam 100% do custo da consulta. Mas o plano desta consulta tem um custo de consulta mais alto (56%).
Agora, aqui está um plano de execução quando agrupamos primeiro e nos juntamos ao Produto e ProductSubcategory mesas mais tarde. Confira a Figura 5.
Figura 5 . Plano de execução quando o grupo primeiro, ingressar depois é concluído.
E temos as seguintes observações na Figura 5.
- GROUP BY e SUM terminaram mais cedo.
- Menor número de linhas grossas e setas – isso explica apenas as 348 leituras lógicas.
- Menor custo de consulta (44%).
3. Agrupar uma coluna indexada
Sempre que SQL GROUP BY é feito em uma coluna, essa coluna deve ter um índice. Você aumentará a velocidade de execução assim que agrupar a coluna com um índice. Vamos modificar a consulta anterior e usar a data de envio em vez da data do pedido. A coluna de data de envio não tem índice em SalesOrderHeader .
SET STATISTICS IO ON
GO
SELECT
MONTH(soh.ShipDate) AS ShipMonth
,YEAR(soh.ShipDate) AS ShipYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.ShipDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.ShipDate), MONTH(soh.ShipDate)
ORDER BY Product, ShipYear, ShipMonth;
SET STATISTICS IO OFF
GO
Pressione Ctrl-M e execute a consulta acima no SSMS. Em seguida, crie um índice não clusterizado em ShipDate coluna. Observe as leituras lógicas e o plano de execução. Por fim, execute novamente a consulta acima em outra guia de consulta. Observe as diferenças nas leituras lógicas e nos planos de execução.
Aqui está a comparação das leituras lógicas na Figura 6.
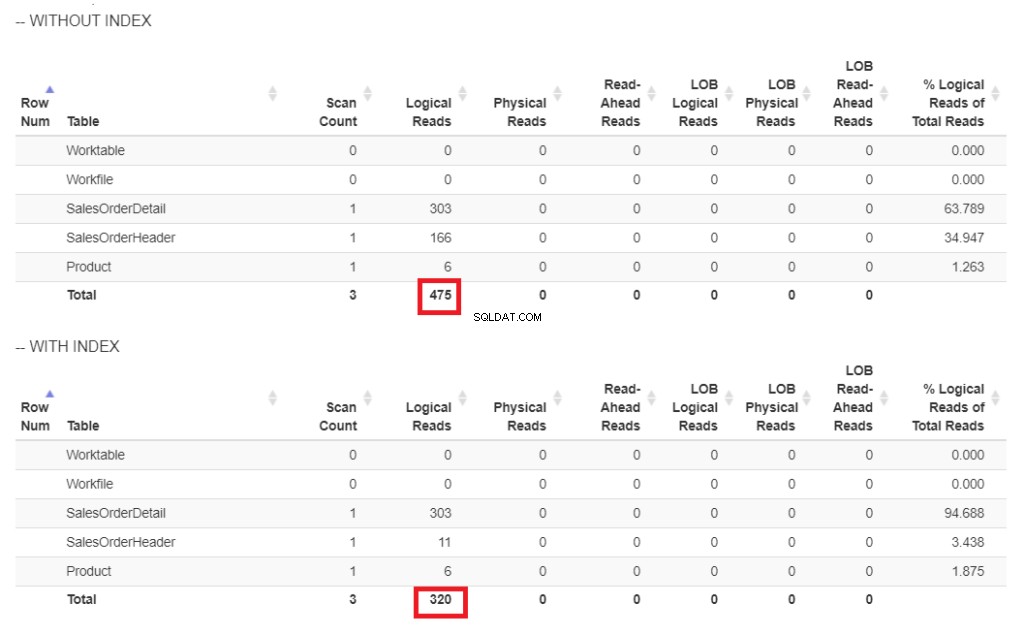
Figura 6 . Leituras lógicas do nosso exemplo de consulta com e sem índice em ShipDate.
Na Figura 6, há leituras lógicas mais altas da consulta sem um índice em ShipDate .
Agora vamos ter o plano de execução quando não houver índice em ShipDate existe na Figura 7.
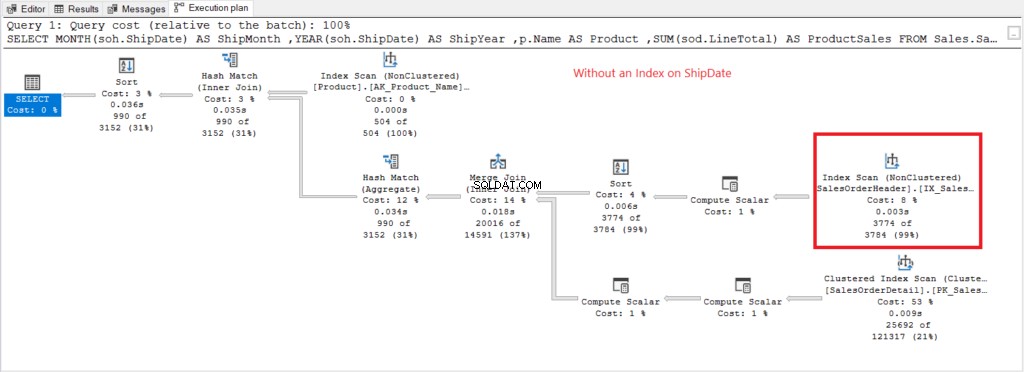
Figura 7 . Plano de execução ao usar GROUP BY em ShipDate não indexado.
A Verificação de Índice O operador usado no plano da Figura 7 explica as leituras lógicas mais altas (475). Aqui está um plano de execução após indexar o ShipDate coluna.
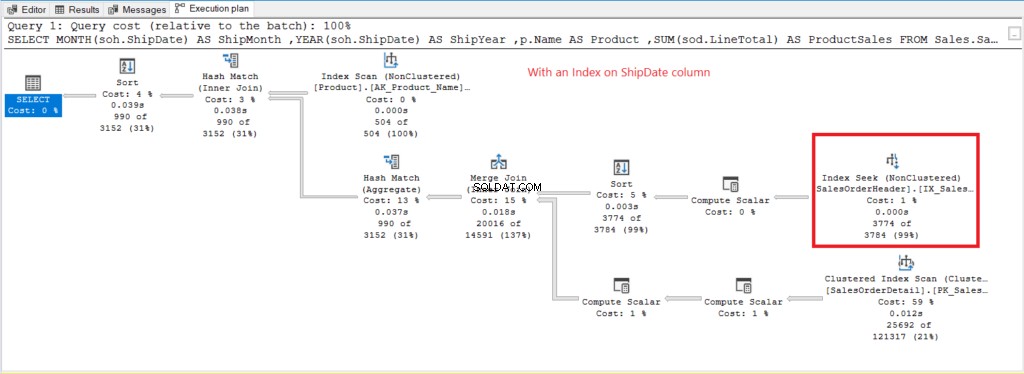
Figura 8 . Plano de execução ao usar GROUP BY em ShipDate indexado.
Em vez de Index Scan, um Index Seek é usado após indexar o ShipDate coluna. Isso explica as leituras lógicas inferiores na Figura 6.
Portanto, para melhorar o desempenho ao usar GROUP BY, considere indexar as colunas que você usou para agrupar.
Apreciações no uso do SQL GROUP BY
SQL GROUP BY é fácil de usar. Mas você precisa dar o próximo passo para ir além de resumir os dados para relatórios. Aqui estão os pontos novamente:
- Filtrar com antecedência . Remova as linhas que você não precisa resumir usando a cláusula WHERE em vez da cláusula HAVING.
- Agrupe primeiro, participe depois . Às vezes, haverá colunas que você precisa adicionar além das colunas que você está agrupando. Em vez de incluí-los na cláusula GROUP BY, divida a consulta com um CTE e junte outras tabelas posteriormente.
- Use GROUP BY com colunas indexadas . Essa coisa básica pode ser útil quando o banco de dados é tão rápido quanto um caracol.
Espero que isso ajude você a melhorar seu jogo nos resultados de agrupamento.
Se você gostou deste post, compartilhe-o em suas redes sociais favoritas.