Neste artigo, explicarei como mover uma tabela do grupo de arquivos primário para o grupo de arquivos secundário. Primeiro, vamos entender o que são arquivos de dados, grupos de arquivos e tipos de grupos de arquivos.
Arquivos de banco de dados e grupos de arquivos
Quando o SQL Server é instalado em qualquer servidor, ele cria um arquivo de dados primário e um arquivo de log para armazenar dados. O arquivo de dados primário armazena dados e objetos de banco de dados como tabelas, índices, procedimentos armazenados, etc. Os arquivos de log armazenam as informações necessárias para recuperar transações. Os arquivos de dados podem ser agrupados em grupos de arquivos.
SQL Server tem três tipos de arquivos
- Arquivo principal :Ele é criado quando o SQL Server está sendo instalado e contém os metadados e informações do banco de dados. Dados do usuário, objetos podem ser armazenados nos arquivos de dados primários. O arquivo principal tem a extensão .mdf.
- Arquivo secundário :Os arquivos secundários são definidos pelo usuário. Eles armazenam dados do usuário, objetos criados por um usuário. Eles têm a extensão .ndf.
- Arquivo de registro de transações s:Os arquivos T-Logs registram todas as transações realizadas para recuperar o banco de dados. A extensão do arquivo de log em .ldf.
Como mencionei acima, os arquivos de dados podem ser agrupados em um grupo de arquivos. Enquanto o SQL Server está sendo instalado, ele cria o grupo de arquivos Primário que possui um arquivo de dados primário. Os grupos de arquivos secundários são definidos pelo usuário. Eles têm arquivos de dados secundários. Quando criamos um novo banco de dados, podemos criar arquivos de dados e grupos de arquivos secundários. Adicionar arquivos de dados secundários ajuda a melhorar o desempenho. Ele pode ser criado em diferentes unidades de disco ou partições de disco separadas que reduzem a espera de E/S e a latência de leitura/gravação.
Recomenda-se manter tabelas e índices em grupos de arquivos separados. Além disso, manter tabelas grandes em arquivos separados melhora o desempenho.
Existem três tipos de grupos de arquivos:
- Grupo de arquivos de linha :O grupo de arquivos de linha, também conhecido como grupo de arquivos primário, contém um arquivo de dados primário. Objeto SQL, dados, tabelas de sistema são alocados para o grupo de arquivos primário.
- Grupo de arquivos otimizado para memória :o grupo de arquivos com otimização de memória contém tabelas e dados com otimização de memória. Para habilitar o OLTP na memória, precisamos criar um grupo de arquivos com otimização de memória.
- FileStream :O grupo de arquivos de fluxo de arquivos contém dados de fluxo de arquivos como Imagens, Documentos, arquivos executáveis etc. O grupo de arquivos Primário não pode conter dados de fluxo de arquivos, precisamos criar um grupo de arquivos FileStream. Ele contém os dados do FileStream.
Configuração de demonstração
Nesta demonstração, criei “DemoDatabase” na instância do SQL Server 2017. As abas “Records” e “PatientData” foram criadas no banco de dados. A chave primária “PK_CIDX_Records_ID” foi criada na tabela “Records” e o índice clusterizado “CIDX_PatientData_ID” foi criado na tabela “PatientData”. Nesta demonstração, vou mover as tabelas “Records” e “PatientData” do grupo de arquivos primário para o grupo de arquivos secundário.
Para isso, precisamos fazer o seguinte:
- Crie um grupo de arquivos secundário.
- Adicione arquivos de dados ao grupo de arquivos secundário.
- Mova a tabela para o grupo de arquivos secundário movendo o índice clusterizado com a restrição de chave primária.
- Mova as tabelas para o grupo de arquivos secundário movendo o índice clusterizado sem a chave primária.
Criar grupo de arquivos secundário
Um grupo de arquivos secundário pode ser criado usando T-SQL OU usando o assistente Adicionar arquivo do SQL Server Management Studio. Para adicionar um grupo de arquivos usando o SSMS, abra o SSMS e selecione um banco de dados onde um grupo de arquivos precisa ser criado. Clique com o botão direito do mouse no banco de dados selecione “Propriedades ”>> selecione “Grupos de arquivos ” e clique em “Adicionar grupo de arquivos ” como mostrado na imagem a seguir:
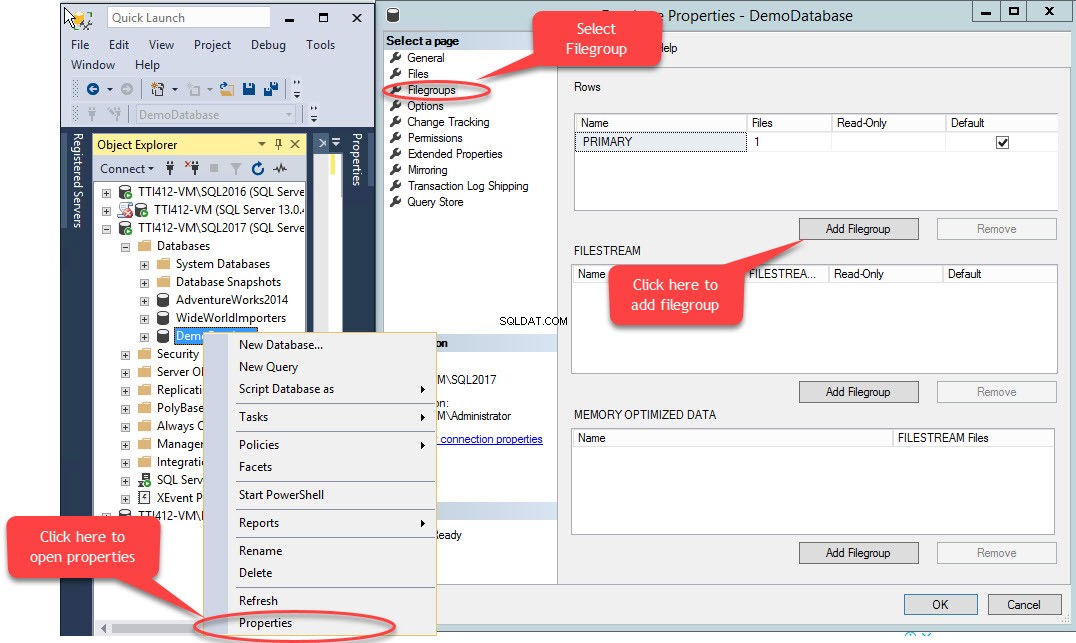
Quando clicamos no botão “Adicionar grupo de arquivos ”, uma linha será adicionada em “Linhas " rede. Nas “Linhas ”, forneça o nome do grupo de arquivos apropriado em “Nome ” coluna. O grupo de arquivos não é somente leitura nem padrão; portanto, mantenha o Somente leitura e Padrão caixas de seleção desmarcadas para novo grupo de arquivos. Veja a seguinte imagem:
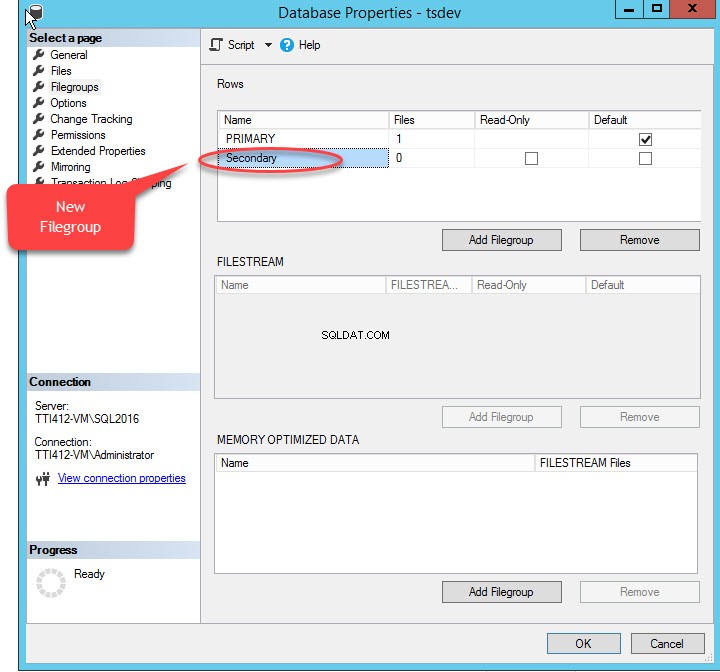
Clique em OK para fechar a caixa de diálogo.
Para criar um grupo de arquivos usando o script T-SQL, execute o script a seguir.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILEGROUP [Secondary ] GO
Adicionando arquivos ao grupo de arquivos
Para adicionar arquivos em um grupo de arquivos, abra as propriedades do banco de dados, selecione “arquivos” e clique em “Adicionar”. Conforme mostrado na imagem a seguir:
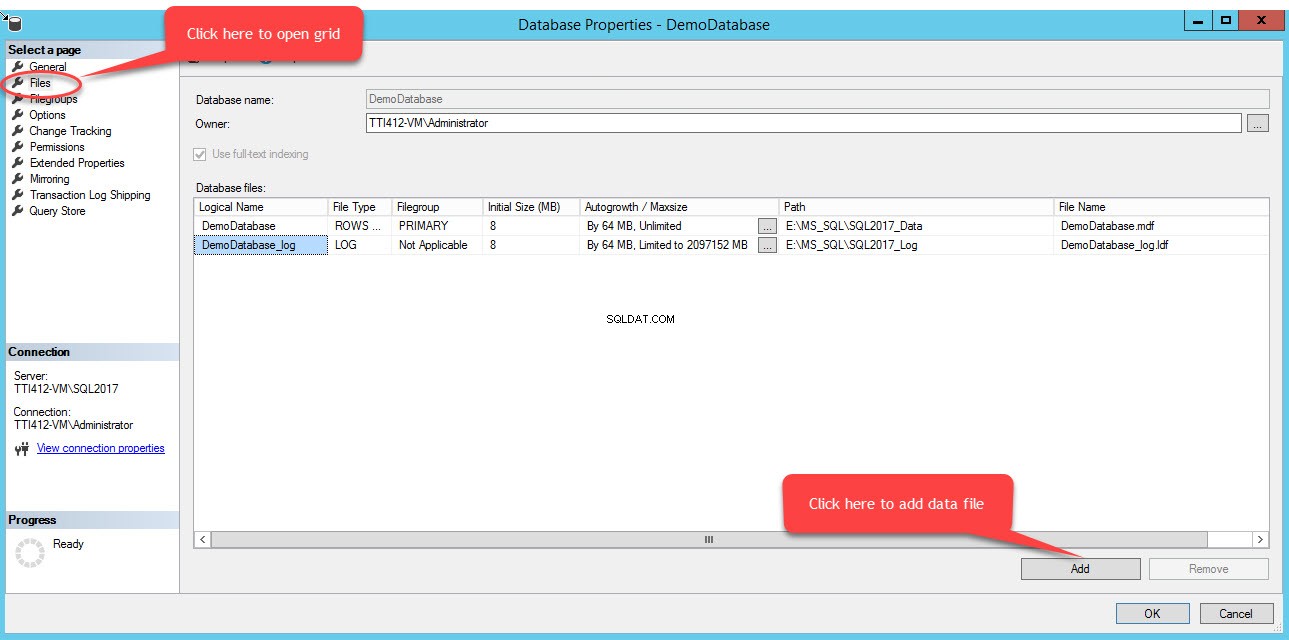
Uma linha vazia será adicionada aos Arquivos de banco de dados visualização em grade. Na exibição em Grade, forneça o nome lógico apropriado no Nome lógico coluna, selecione Dados de linhas do Tipo de arquivo caixa suspensa, selecione secundário do grupo de arquivos caixa suspensa, defina o tamanho inicial do arquivo em Tamanho inicial colunas, defina o parâmetro de crescimento automático e tamanho máximo em aumento automático/tamanho máximo coluna, forneça a localização física do arquivo de dados secundário no Caminho coluna e forneça o nome de arquivo apropriado em Nome do arquivo coluna. Veja a seguinte imagem:
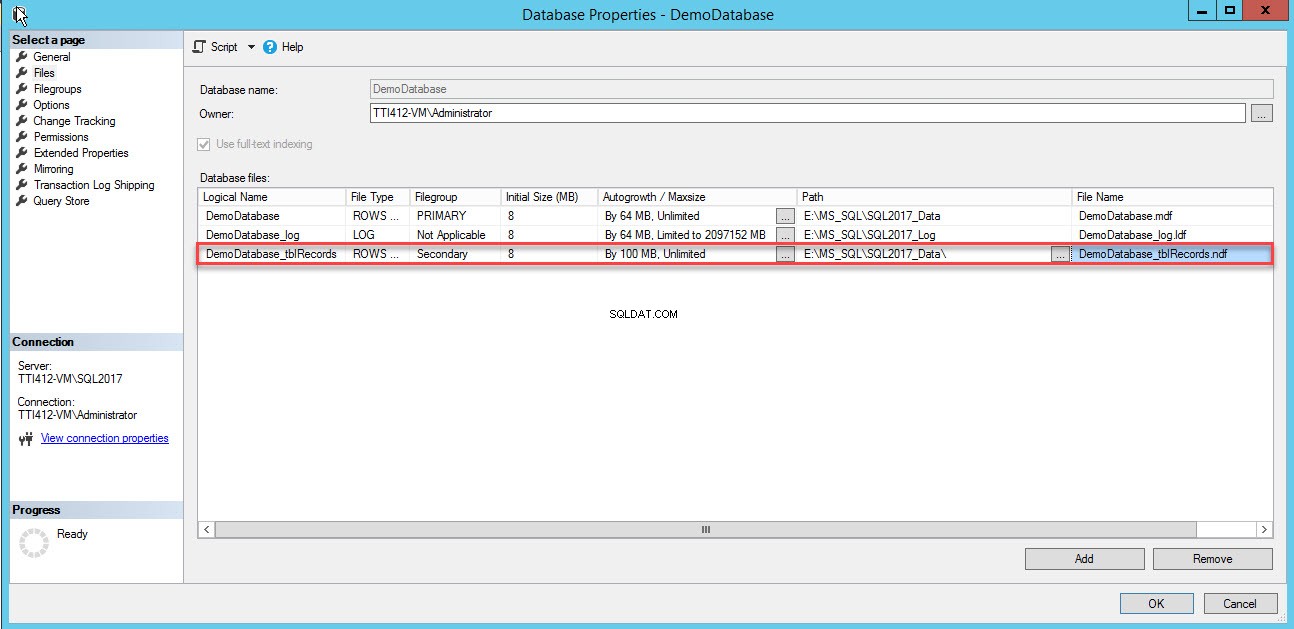
Use o script T-SQL a seguir para criar um arquivo de dados secundário.
USE [master] GO ALTER DATABASE [DemoDatabase] ADD FILE ( NAME = N'DemoDatabase_tblRecords', FILENAME = N'E:\MS_SQL\SQL2017_Data\DemoDatabase_tblRecords.ndf' , SIZE = 8192KB , FILEGROWTH = 102400KB ) TO FILEGROUP [Secondary] GO
O arquivo de dados secundário foi criado. Veja a seguinte imagem:
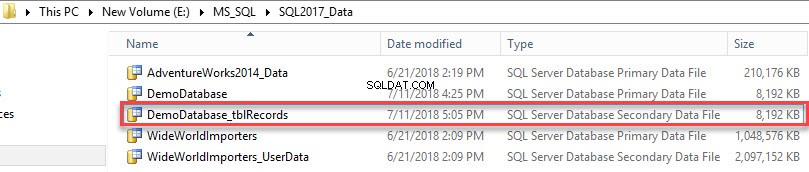
Para visualizar uma lista de grupos de arquivos criados no banco de dados, execute a seguinte consulta.
use DemoDatabase go select a.Name as 'File group Name', type_desc as 'Filegroup Type', case when is_default=1 then 'Yes' else 'No' end as 'Is filegroup default?', b.filename as 'File Location', b.name 'Logical Name', Convert(numeric(10,3),Convert(numeric(10,3),(size/128))/1024) as 'File Size in MB' from sys.filegroups a inner join sys.sysfiles b on a.data_space_id=b.groupid
Abaixo está uma saída da consulta.

Transferindo a tabela existente do grupo de arquivos primário para o grupo de arquivos secundário
Podemos mover uma tabela existente para outro grupo de arquivos movendo o índice clusterizado para outro grupo de arquivos. Como sabemos, um nó folha do índice clusterizado possui dados reais; portanto, mover o índice clusterizado pode mover a tabela inteira para outro grupo de arquivos. A movimentação do índice tem uma limitação:se o índice for uma chave primária ou restrição exclusiva, você não poderá mover o índice usando o SQL Server Management Studio. Para mover esses índices, precisamos usar o criar índice declaração e com o DROP_Existing=ON opção.
Movendo o índice clusterizado com restrição de chave primária.
A chave primária impõe valores exclusivos, portanto, crie o índice clusterizado exclusivo. A coluna chave é PRN. Para criá-lo no grupo de arquivos secundário, defina o DROP_EXISTING=ON opção e o grupo de arquivos deve ser secundário. Execute o script a seguir.
USE [DemoDatabas] GO Create Unique Clustered index [PK_CIDX_Records_ID] ON [Records] (ID asc) WITH (DROP_EXISTING=ON) ON [Secondary]
Depois que o comando for executado com êxito, verifique se o índice foi criado no grupo de arquivos secundário. Para isso, clique com o botão direito do mouse em Armazenamento opção nas Propriedades do Índice caixa de diálogo. Para abrir as propriedades do índice, expanda o DemoDatabase banco de dados>> expandir Tabelas>> expandir Índices . Clique com o botão direito do mouse em PK_CIDX_Records_ID , conforme mostrado na imagem a seguir:
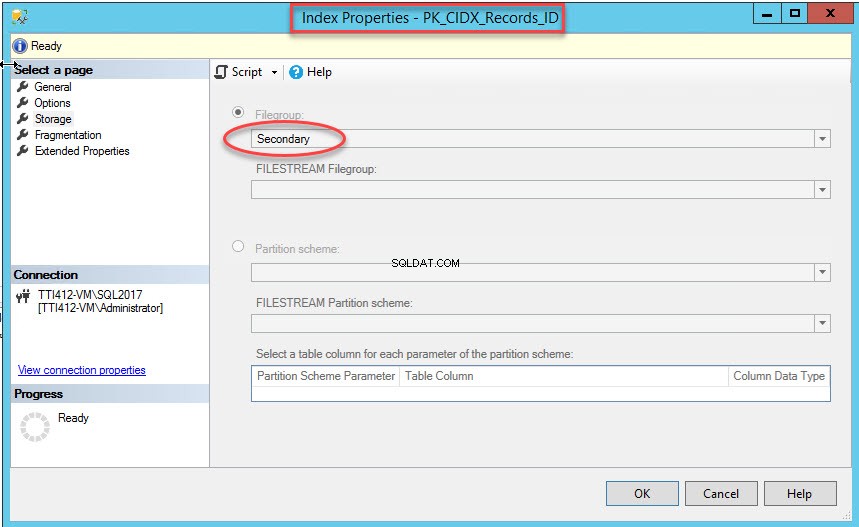
Como mencionei, assim que o índice clusterizado for movido para um grupo de arquivos secundário, a tabela será movida para o grupo de arquivos secundário. Para verificá-lo, clique com o botão direito do mouse em Armazenamento opção nas Propriedades da Tabela caixa de diálogo. Para abrir as propriedades do índice, expanda o DemoDatabase banco de dados>> expandir Tabela s>> clique com o botão direito do mouse em Registros, e selecione armazenamento, como mostrado na imagem a seguir:
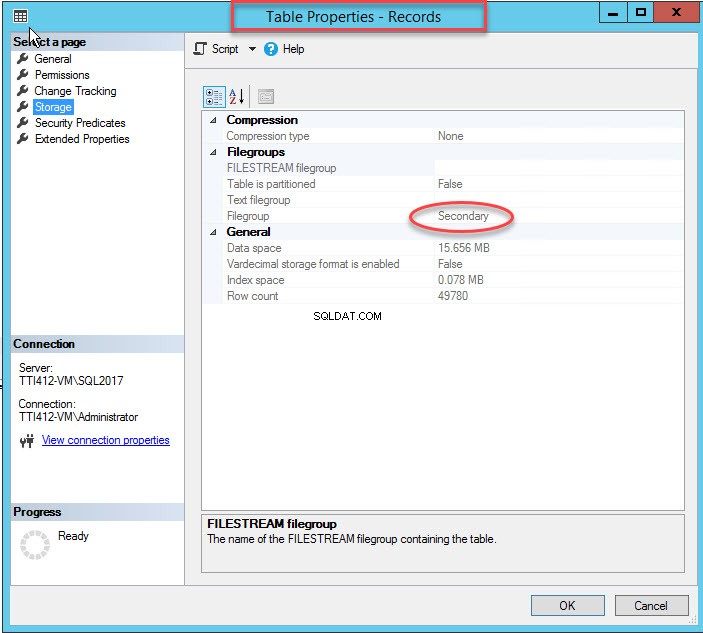
Movendo o índice clusterizado sem chave primária
Podemos mover o índice clusterizado sem chave primária usando o SQL Server Management Studio. Para fazer isso, expanda o DemoDatabase banco de dados>> expandir Tabelas>> expandir Índice s>> clique com o botão direito do mouse em CIDX_PatientData_ID indexe e selecione Propriedades, como mostrado na imagem a seguir:
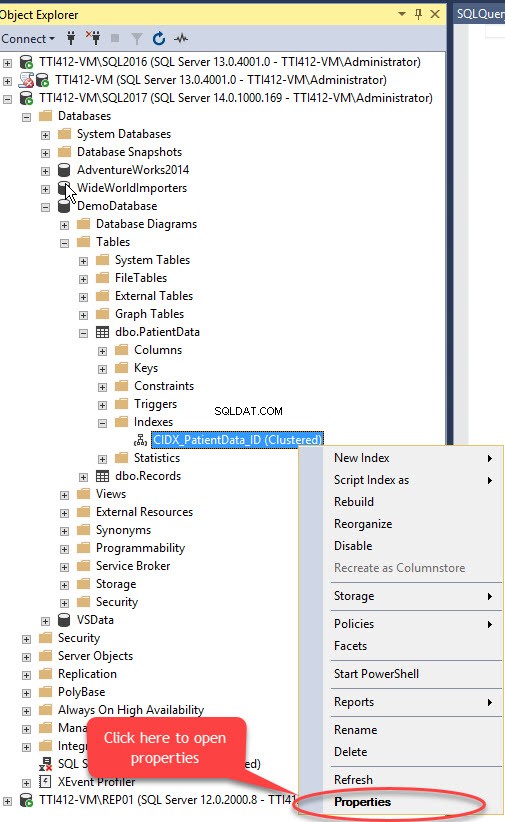
As Propriedades do Índice caixa de diálogo é aberta. Na caixa de diálogo, selecione Armazenamento, e na janela Armazenamento, clique no Grupo de arquivos caixa suspensa, selecione Secundário grupo de arquivos e clique em OK, como mostrado na imagem a seguir:
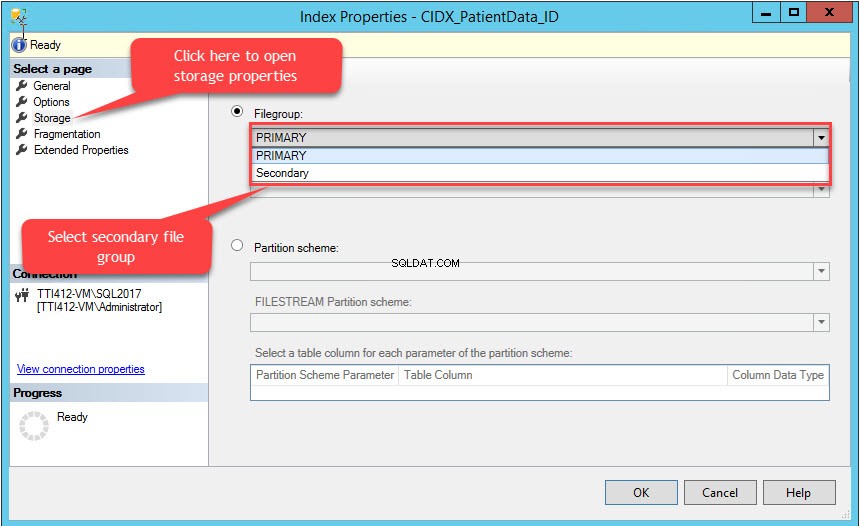
A alteração do grupo de arquivos de índice recriará todo o índice. Depois que o índice for recriado, abra Propriedades da tabela e selecione um armazenamento.
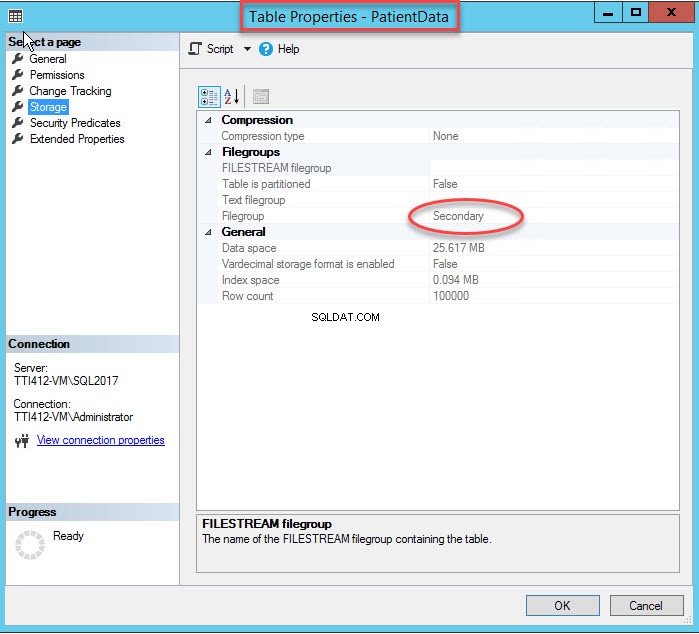
Como você pode ver na imagem acima, junto com a movimentação do CIDX_PatientData_ID índice clusterizado para o grupo de arquivos secundário, o PatientData tabela também é movida para o Secundário grupo de arquivos.
Ao executar a seguinte consulta, você pode encontrar a lista de objetos criados para diferentes grupos de arquivos:
SELECT obj.[name] as [Table Name],
obj.[type] as [Object Type],
Indx.[name] as [Index Name],
fG.[name] as [Filegroup Name]
FROM sys.indexes INDX
INNER JOIN sys.filegroups FG
ON INDX.data_space_id = fG.data_space_id
INNER JOIN sys.all_objects Obj
ON INDX.[object_id] = obj.[object_id]
WHERE INDX.data_space_id = fG.data_space_id
And obj.type='U'
go Abaixo está a saída da consulta:
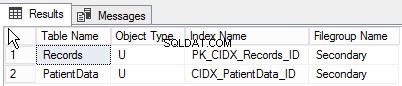
Resumo
Neste artigo, expliquei
-
- Noções básicas de arquivos de dados e grupos de arquivos.
- Como criar um grupo de arquivos secundário e adicionar um arquivo de dados secundário nele.
- Mova a tabela para o grupo de arquivos secundário movendo:
- Chave primária.
- Índice agrupado.