A primeira postagem do blog neste site, em julho de 2012, falava sobre as melhores abordagens para a execução de totais. Desde então, várias vezes me perguntaram como eu abordaria o problema se os totais em execução fossem mais complexos – especificamente, se eu precisasse calcular os totais em execução para várias entidades – digamos, os pedidos de cada cliente.
O exemplo original usou um caso fictício de uma cidade emitindo multas por excesso de velocidade; o total corrente era simplesmente agregar e manter uma contagem corrente do número de multas por excesso de velocidade por dia (independentemente de para quem a multa foi emitida ou por quanto foi). Um exemplo mais complexo (mas prático) pode ser agregar o valor total das multas por excesso de velocidade, agrupadas por carteira de motorista, por dia. Vamos imaginar a seguinte tabela:
CREATE TABLE dbo.SpeedingTickets ( IncidentID INT IDENTITY(1,1) PRIMARY KEY, LicenseNumber INT NOT NULL, IncidentDate DATE NOT NULL, TicketAmount DECIMAL(7,2) NOT NULL ); CREATE UNIQUE INDEX x ON dbo.SpeedingTickets(LicenseNumber, IncidentDate) INCLUDE(TicketAmount);
Você pode perguntar,
DECIMAL(7,2) , verdade? Quão rápido essas pessoas estão indo? Bem, no Canadá, por exemplo, não é tão difícil conseguir uma multa de US$ 10.000 por excesso de velocidade. Agora, vamos preencher a tabela com alguns dados de exemplo. Não entrarei em todos os detalhes aqui, mas isso deve produzir cerca de 6.000 linhas representando vários motoristas e vários valores de ingressos durante um período de um mês:
;WITH TicketAmounts(ID,Value) AS
(
-- 10 arbitrary ticket amounts
SELECT i,p FROM
(
VALUES(1,32.75),(2,75), (3,109),(4,175),(5,295),
(6,68.50),(7,125),(8,145),(9,199),(10,250)
) AS v(i,p)
),
LicenseNumbers(LicenseNumber,[newid]) AS
(
-- 1000 random license numbers
SELECT TOP (1000) 7000000 + number, n = NEWID()
FROM [master].dbo.spt_values
WHERE number BETWEEN 1 AND 999999
ORDER BY n
),
JanuaryDates([day]) AS
(
-- every day in January 2014
SELECT TOP (31) DATEADD(DAY, number, '20140101')
FROM [master].dbo.spt_values
WHERE [type] = N'P'
ORDER BY number
),
Tickets(LicenseNumber,[day],s) AS
(
-- match *some* licenses to days they got tickets
SELECT DISTINCT l.LicenseNumber, d.[day], s = RTRIM(l.LicenseNumber)
FROM LicenseNumbers AS l CROSS JOIN JanuaryDates AS d
WHERE CHECKSUM(NEWID()) % 100 = l.LicenseNumber % 100
AND (RTRIM(l.LicenseNumber) LIKE '%' + RIGHT(CONVERT(CHAR(8), d.[day], 112),1) + '%')
OR (RTRIM(l.LicenseNumber+1) LIKE '%' + RIGHT(CONVERT(CHAR(8), d.[day], 112),1) + '%')
)
INSERT dbo.SpeedingTickets(LicenseNumber,IncidentDate,TicketAmount)
SELECT t.LicenseNumber, t.[day], ta.Value
FROM Tickets AS t
INNER JOIN TicketAmounts AS ta
ON ta.ID = CONVERT(INT,RIGHT(t.s,1))-CONVERT(INT,LEFT(RIGHT(t.s,2),1))
ORDER BY t.[day], t.LicenseNumber; Isso pode parecer um pouco complicado demais, mas um dos maiores desafios que muitas vezes tenho ao compor essas postagens de blog é construir uma quantidade adequada de dados "aleatórios" / arbitrários realistas. Se você tem um método melhor para a população de dados arbitrários, não use meus murmúrios como exemplo – eles são periféricos ao ponto deste post.
Abordagens
Existem várias maneiras de resolver esse problema em T-SQL. Aqui estão sete abordagens, juntamente com seus planos associados. Deixei de fora técnicas como cursores (porque eles serão inegavelmente mais lentos) e CTEs recursivos baseados em data (porque dependem de dias contíguos).
Subconsulta nº 1
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = TicketAmount + COALESCE(
(
SELECT SUM(TicketAmount)
FROM dbo.SpeedingTickets AS s
WHERE s.LicenseNumber = o.LicenseNumber
AND s.IncidentDate < o.IncidentDate
), 0)
FROM dbo.SpeedingTickets AS o
ORDER BY LicenseNumber, IncidentDate; 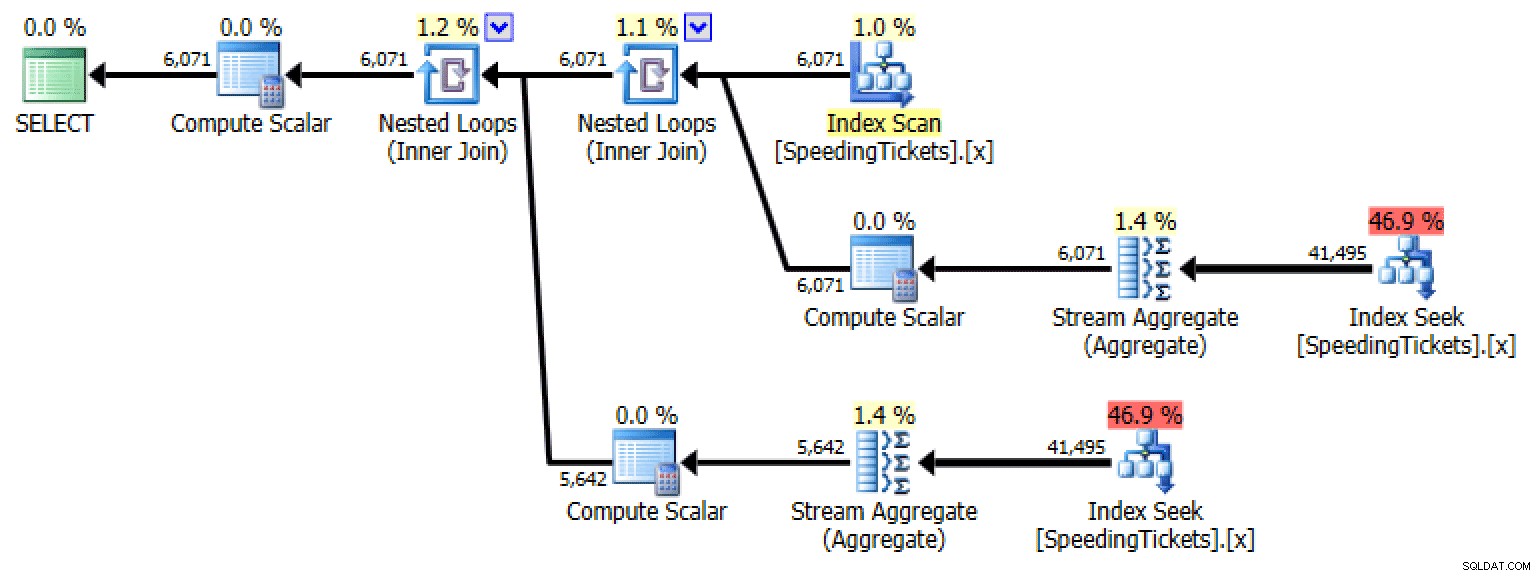
Planejar a subconsulta nº 1
Subconsulta nº 2
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal =
(
SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets
WHERE LicenseNumber = t.LicenseNumber
AND IncidentDate <= t.IncidentDate
)
FROM dbo.SpeedingTickets AS t
ORDER BY LicenseNumber, IncidentDate; 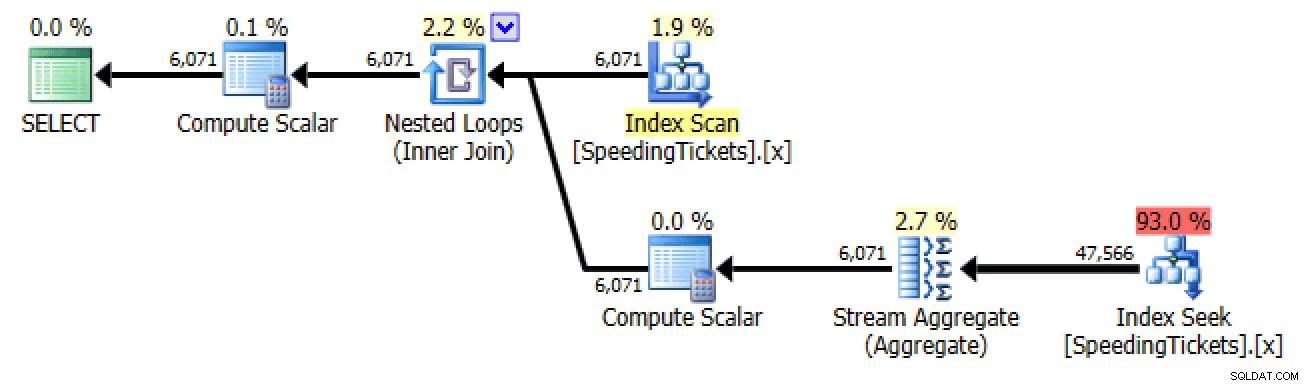
Planejar a subconsulta nº 2
Auto-inscrição
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount, RunningTotal = SUM(t2.TicketAmount) FROM dbo.SpeedingTickets AS t1 INNER JOIN dbo.SpeedingTickets AS t2 ON t1.LicenseNumber = t2.LicenseNumber AND t1.IncidentDate >= t2.IncidentDate GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount ORDER BY t1.LicenseNumber, t1.IncidentDate;
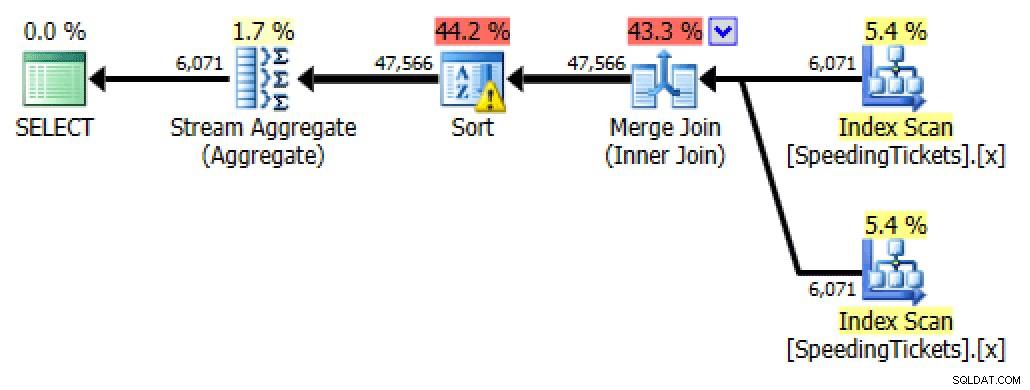
Planejar a participação automática
Aplicação externa
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
OUTER APPLY
(
SELECT TicketAmount
FROM dbo.SpeedingTickets
WHERE LicenseNumber = t1.LicenseNumber
AND IncidentDate <= t1.IncidentDate
) AS t2
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate; 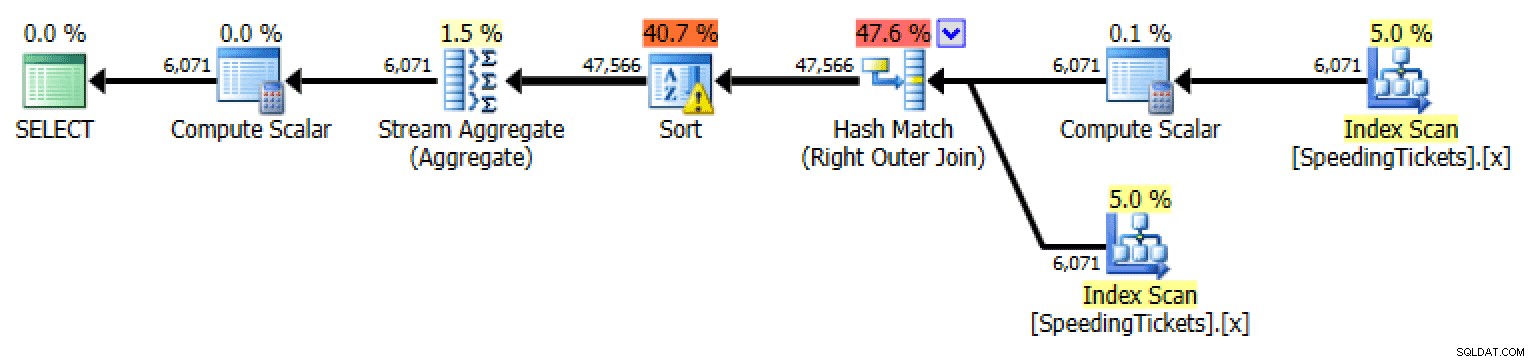
Planejar aplicação externa
SUM OVER() usando RANGE (somente 2012+)
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate RANGE UNBOUNDED PRECEDING
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate; 
Planejar SUM OVER() usando RANGE
SUM OVER() usando ROWS (somente 2012+)
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate ROWS UNBOUNDED PRECEDING
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate; 
Planejar SUM OVER() usando ROWS
Iteração baseada em conjunto
Com crédito para Hugo Kornelis (@Hugo_Kornelis) pelo Capítulo 4 no Volume 1 de Mergulhos Profundos do SQL Server MVP, essa abordagem combina uma abordagem baseada em conjunto e uma abordagem de cursor.
DECLARE @x TABLE
(
LicenseNumber INT NOT NULL,
IncidentDate DATE NOT NULL,
TicketAmount DECIMAL(7,2) NOT NULL,
RunningTotal DECIMAL(7,2) NOT NULL,
rn INT NOT NULL,
PRIMARY KEY(LicenseNumber, IncidentDate)
);
INSERT @x(LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)
SELECT LicenseNumber, IncidentDate, TicketAmount, TicketAmount,
ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate)
FROM dbo.SpeedingTickets;
DECLARE @rn INT = 1, @rc INT = 1;
WHILE @rc > 0
BEGIN
SET @rn += 1;
UPDATE [current]
SET RunningTotal = [last].RunningTotal + [current].TicketAmount
FROM @x AS [current]
INNER JOIN @x AS [last]
ON [current].LicenseNumber = [last].LicenseNumber
AND [last].rn = @rn - 1
WHERE [current].rn = @rn;
SET @rc = @@ROWCOUNT;
END
SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal
FROM @x
ORDER BY LicenseNumber, IncidentDate; Devido à sua natureza, essa abordagem produz muitos planos idênticos no processo de atualização da variável da tabela, todos semelhantes aos planos de auto-junção e aplicação externa, mas capazes de usar uma busca:
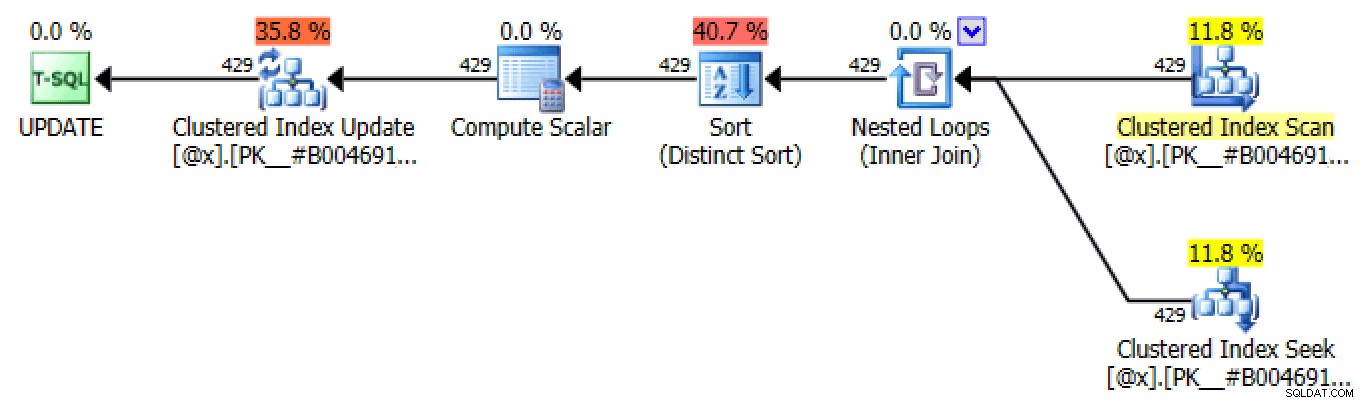
Um dos muitos planos UPDATE produzidos por meio de iteração baseada em conjunto em>
A única diferença entre cada plano em cada iteração é a contagem de linhas. A cada iteração sucessiva, o número de linhas afetadas deve permanecer o mesmo ou diminuir, pois o número de linhas afetadas em cada iteração representa o número de motoristas com multas naquele número de dias (ou, mais precisamente, o número de dias em essa "classificação").
Resultados de desempenho
Aqui está como as abordagens foram empilhadas, como mostrado pelo SQL Sentry Plan Explorer, com exceção da abordagem de iteração baseada em conjunto que, por consistir em muitas instruções individuais, não representa bem quando comparada ao resto.
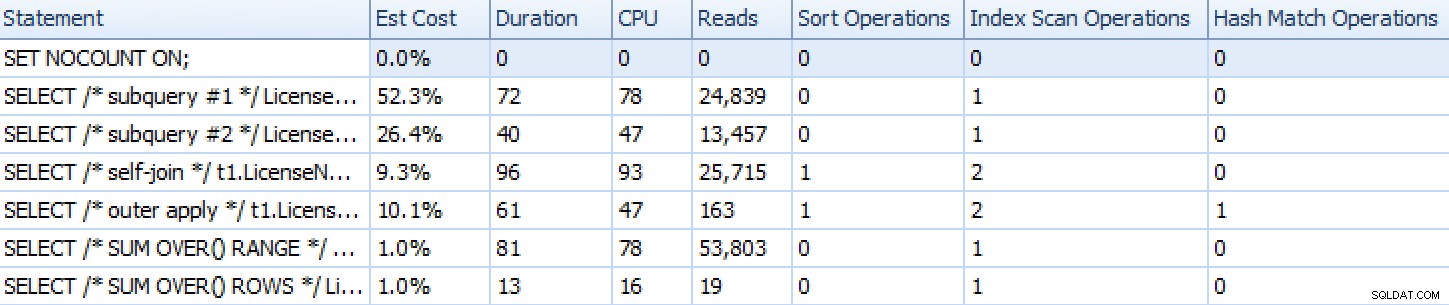
Planejar métricas de tempo de execução do Explorer para seis das sete abordagens
Além de revisar os planos e comparar as métricas de tempo de execução no Plan Explorer, também medi o tempo de execução bruto no Management Studio. Aqui estão os resultados da execução de cada consulta 10 vezes, lembrando que isso também inclui o tempo de renderização no SSMS:
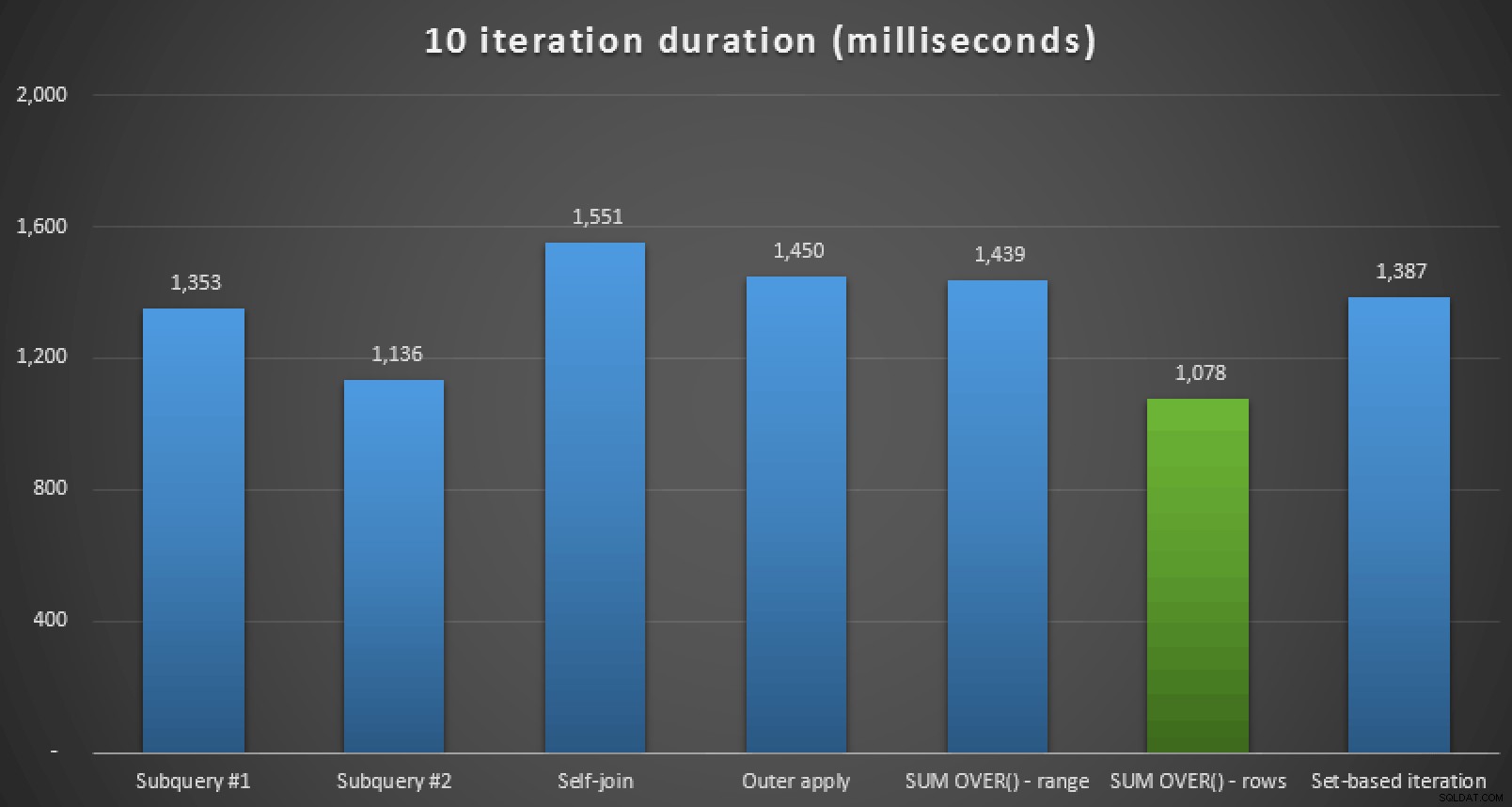
Duração do tempo de execução, em milissegundos, para todas as sete abordagens (10 iterações )
Portanto, se você estiver no SQL Server 2012 ou superior, a melhor abordagem parece ser
SUM OVER() usando ROWS UNBOUNDED PRECEDING . Se você não estiver no SQL Server 2012, a segunda abordagem de subconsulta parece ser ótima em termos de tempo de execução, apesar do alto número de leituras em comparação com, digamos, o OUTER APPLY inquerir. Em todos os casos, é claro, você deve testar essas abordagens, adaptadas ao seu esquema, em seu próprio sistema. Seus dados, índices e outros fatores podem fazer com que uma solução diferente seja a mais ideal em seu ambiente. Outras complexidades
Agora, o índice exclusivo significa que qualquer combinação LicenseNumber + IncidentDate conterá um único total cumulativo, no caso de um motorista específico receber várias passagens em um determinado dia. Essa regra de negócios ajuda a simplificar um pouco nossa lógica, evitando a necessidade de um desempate para produzir totais de execução determinísticos.
Se você tiver casos em que pode ter várias linhas para qualquer combinação LicenseNumber + IncidentDate, você pode quebrar o empate usando outra coluna que ajuda a tornar a combinação única (obviamente, a tabela de origem não teria mais uma restrição exclusiva nessas duas colunas) . Observe que isso é possível mesmo nos casos em que o
DATE coluna é na verdade DATETIME – muitas pessoas assumem que os valores de data/hora são únicos, mas isso certamente nem sempre é garantido, independentemente da granularidade. No meu caso, eu poderia usar o
IDENTITY coluna, IncidentID; aqui está como eu ajustaria cada solução (reconhecendo que pode haver maneiras melhores; apenas jogando fora ideias):/* --------- subquery #1 --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = TicketAmount + COALESCE(
(
SELECT SUM(TicketAmount)
FROM dbo.SpeedingTickets AS s
WHERE s.LicenseNumber = o.LicenseNumber
AND (s.IncidentDate < o.IncidentDate
-- added this line:
OR (s.IncidentDate = o.IncidentDate AND s.IncidentID < o.IncidentID))
), 0)
FROM dbo.SpeedingTickets AS o
ORDER BY LicenseNumber, IncidentDate;
/* --------- subquery #2 --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal =
(
SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets
WHERE LicenseNumber = t.LicenseNumber
AND IncidentDate <= t.IncidentDate
-- added this line:
AND IncidentID <= t.IncidentID
)
FROM dbo.SpeedingTickets AS t
ORDER BY LicenseNumber, IncidentDate;
/* --------- self-join --------- */
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
INNER JOIN dbo.SpeedingTickets AS t2
ON t1.LicenseNumber = t2.LicenseNumber
AND t1.IncidentDate >= t2.IncidentDate
-- added this line:
AND t1.IncidentID >= t2.IncidentID
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
/* --------- outer apply --------- */
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount,
RunningTotal = SUM(t2.TicketAmount)
FROM dbo.SpeedingTickets AS t1
OUTER APPLY
(
SELECT TicketAmount
FROM dbo.SpeedingTickets
WHERE LicenseNumber = t1.LicenseNumber
AND IncidentDate <= t1.IncidentDate
-- added this line:
AND IncidentID <= t1.IncidentID
) AS t2
GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount
ORDER BY t1.LicenseNumber, t1.IncidentDate;
/* --------- SUM() OVER using RANGE --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate, IncidentID RANGE UNBOUNDED PRECEDING
-- added this column ^^^^^^^^^^^^
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;
/* --------- SUM() OVER using ROWS --------- */
SELECT LicenseNumber, IncidentDate, TicketAmount,
RunningTotal = SUM(TicketAmount) OVER
(
PARTITION BY LicenseNumber
ORDER BY IncidentDate, IncidentID ROWS UNBOUNDED PRECEDING
-- added this column ^^^^^^^^^^^^
)
FROM dbo.SpeedingTickets
ORDER BY LicenseNumber, IncidentDate;
/* --------- set-based iteration --------- */
DECLARE @x TABLE
(
-- added this column, and made it the PK:
IncidentID INT PRIMARY KEY,
LicenseNumber INT NOT NULL,
IncidentDate DATE NOT NULL,
TicketAmount DECIMAL(7,2) NOT NULL,
RunningTotal DECIMAL(7,2) NOT NULL,
rn INT NOT NULL
);
-- added the additional column to the INSERT/SELECT:
INSERT @x(IncidentID, LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)
SELECT IncidentID, LicenseNumber, IncidentDate, TicketAmount, TicketAmount,
ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate, IncidentID)
-- and added this tie-breaker column ------------------------------^^^^^^^^^^^^
FROM dbo.SpeedingTickets;
-- the rest of the set-based iteration solution remained unchanged Outra complicação que você pode encontrar é quando você não está atrás da mesa inteira, mas sim de um subconjunto (digamos, neste caso, a primeira semana de janeiro). Você terá que fazer ajustes adicionando
WHERE cláusulas e mantenha esses predicados em mente quando também tiver subconsultas correlacionadas.