Autor convidado:Michael J Swart (@MJSwart)
Eu gasto muito tempo traduzindo requisitos de software em esquemas e consultas. Esses requisitos às vezes são fáceis de implementar, mas muitas vezes são difíceis. Quero falar sobre escolhas de design de interface do usuário que levam a padrões de acesso a dados que são difíceis de implementar usando o SQL Server.
Classificar por coluna
Classificar por coluna é um padrão tão familiar que podemos tomá-lo como garantido. Toda vez que interagimos com um software que exibe uma tabela, podemos esperar que as colunas sejam classificáveis assim:
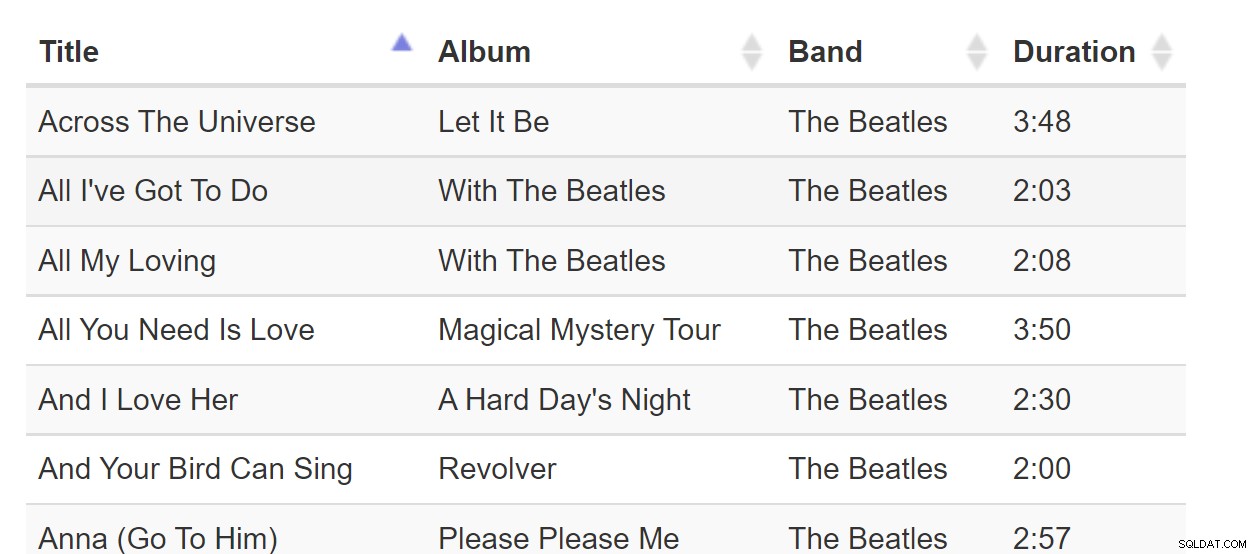
Sort-By-Colunn é um ótimo padrão quando todos os dados podem caber no navegador. Mas se o conjunto de dados tiver bilhões de linhas, isso pode ser complicado, mesmo que a página da Web exija apenas uma página de dados. Considere esta tabela de músicas:
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band); E considere estas quatro consultas classificadas por cada coluna:
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
Mesmo para uma consulta tão simples, existem diferentes planos de consulta. As duas primeiras consultas usam índices de cobertura:
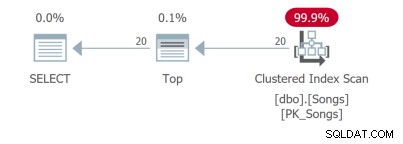
A terceira consulta precisa fazer uma pesquisa de chave que não é ideal:
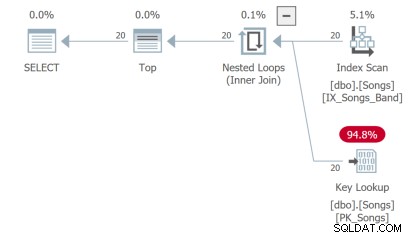
Mas o pior é a quarta consulta que precisa escanear toda a tabela e fazer uma ordenação para retornar as primeiras 20 linhas:
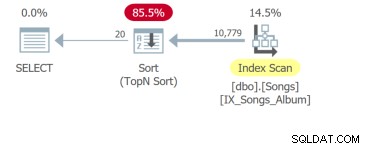
A questão é que, embora a única diferença seja a cláusula ORDER BY, essas consultas precisam ser analisadas separadamente. A unidade básica de ajuste de SQL é a consulta. Portanto, se você me mostrar os requisitos de interface do usuário com dez colunas classificáveis, mostrarei dez consultas para analisar.
Quando isso fica estranho?
O recurso Classificar por coluna é um ótimo padrão de interface do usuário, mas pode ficar estranho se os dados vierem de uma enorme tabela crescente com muitas e muitas colunas. Pode ser tentador criar índices de cobertura em cada coluna, mas isso tem outras vantagens. Os índices Columnstore podem ajudar em algumas circunstâncias, mas isso introduz outro nível de constrangimento. Nem sempre há uma alternativa fácil.
Resultados paginados
Usar resultados paginados é uma boa maneira de não sobrecarregar o usuário com muitas informações de uma só vez. Também é uma boa maneira de não sobrecarregar os servidores de banco de dados… normalmente.
Considere este projeto:

Os dados por trás deste exemplo requerem a contagem e o processamento de todo o conjunto de dados para relatar o número de resultados. A consulta para este exemplo pode usar uma sintaxe como esta:
... ORDER BY LastModifiedTime OFFSET @N ROWS FETCH NEXT 25 ROWS ONLY;
É uma sintaxe conveniente e a consulta produz apenas 25 linhas. Mas só porque o conjunto de resultados é pequeno, não significa necessariamente que seja barato. Assim como vimos com o padrão Sort-By-Column, um operador TOP só é barato se não precisar classificar muitos dados primeiro.
Solicitações de página assíncrona
À medida que um usuário navega de uma página de resultados para outra, as solicitações da Web envolvidas podem ser separadas por segundos ou minutos. Isso leva a problemas que se parecem muito com as armadilhas que são vistas ao usar o NOLOCK. Por exemplo:
SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY; -- wait a little bit SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 25 ROWS FETCH NEXT 25 ROWS ONLY;
Quando uma linha é adicionada entre as duas solicitações, o usuário pode ver a mesma linha duas vezes. E se uma linha for removida, o usuário poderá perder uma linha enquanto navega pelas páginas. Este padrão de Resultados Paginados é equivalente a “Dê-me as linhas 26-50”. Quando a verdadeira pergunta deveria ser “Dê-me as próximas 25 linhas”. A diferença é sutil.
Melhores padrões
Com os resultados paginados, esse “OFFSET @N ROWS” pode demorar cada vez mais à medida que @N cresce. Em vez disso, considere os botões Load-More ou Infinite-Scrolling. Com a paginação Load-More, há pelo menos uma chance de fazer uso eficiente de um índice. A consulta seria algo como:
SELECT [Some Columns] FROM [Some Table] WHERE [Sort Value] > @Bookmark ORDER BY [Sort Value] FETCH NEXT 25 ROWS ONLY;
Ele ainda sofre com algumas das armadilhas das solicitações de páginas assíncronas, mas por causa do marcador, o usuário continuará de onde parou.
Pesquisando texto para substring
A pesquisa está em toda parte na internet. Mas qual solução deve ser usada no back-end? Quero alertar contra a pesquisa de uma substring usando o filtro LIKE do SQL Server com curingas como este:
SELECT Title, Category FROM MyContent WHERE Title LIKE '%' + @SearchTerm + '%';
Isso pode levar a resultados estranhos como este:
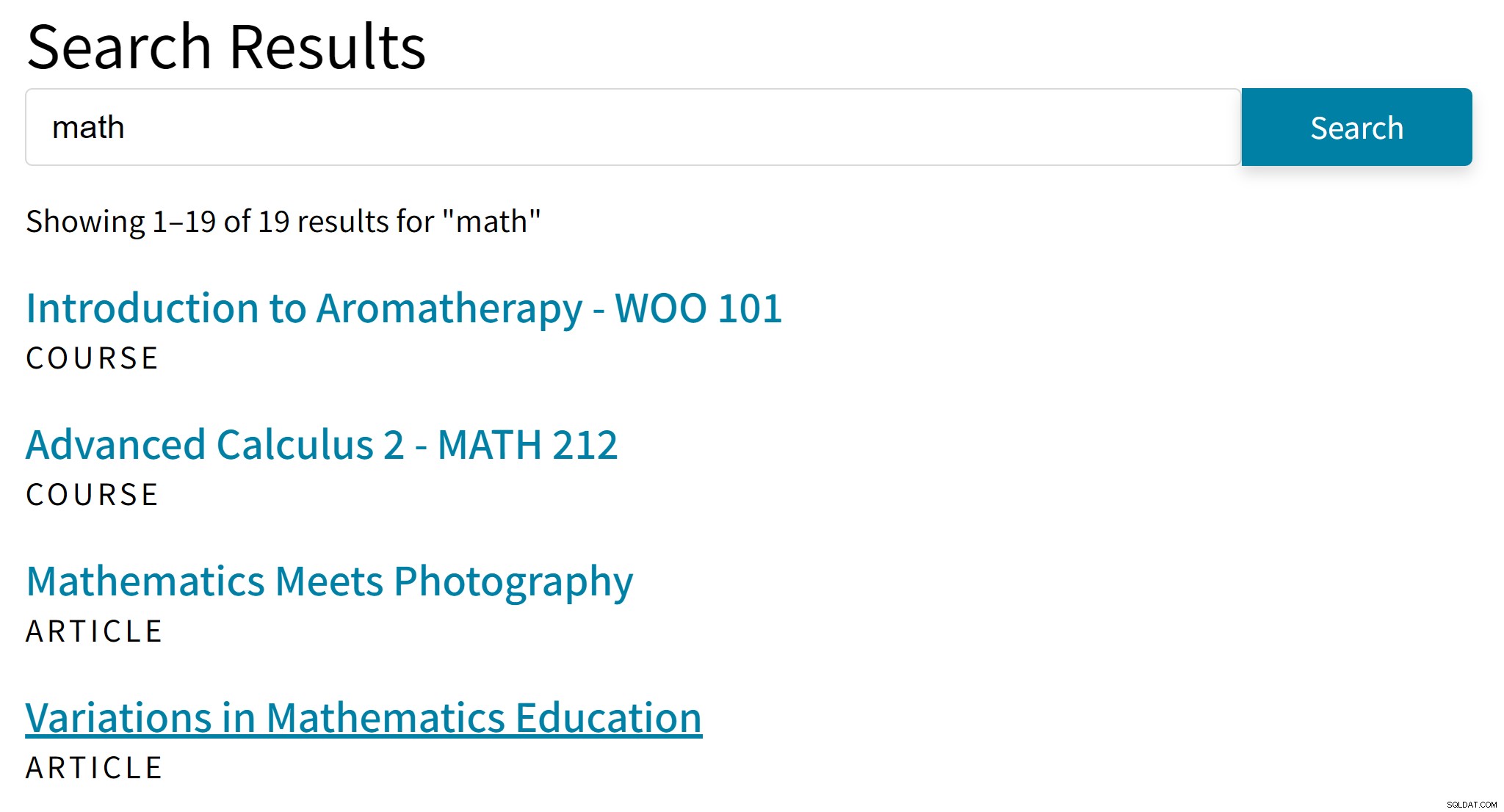
“Aromaterapia” provavelmente não é um bom sucesso para o termo de pesquisa “matemática”. Enquanto isso, os resultados da pesquisa estão faltando artigos que mencionam apenas Álgebra ou Trigonometria.
Também pode ser muito difícil conseguir com eficiência usando o SQL Server. Não existe um índice direto que suporte esse tipo de pesquisa. Paul White deu uma solução complicada com Trigram Wildcard String Search no SQL Server. Há também dificuldades que podem ocorrer com agrupamentos e Unicode. Pode se tornar uma solução cara para uma experiência de usuário não tão boa.
O que usar em vez disso
A pesquisa de texto completo do SQL Server parece que pode ajudar, mas eu pessoalmente nunca a usei. Na prática, só vi sucesso em soluções fora do SQL Server (por exemplo, Elasticsearch).
Conclusão
Na minha experiência, descobri que os designers de software geralmente são muito receptivos ao feedback de que seus projetos às vezes serão difíceis de implementar. Quando não são, achei útil destacar as armadilhas, os custos e o tempo de entrega. Esse tipo de feedback é necessário para ajudar a criar soluções escaláveis e sustentáveis.
Sobre o autor
 Michael J Swart é um profissional de banco de dados e blogueiro apaixonado que se concentra em desenvolvimento de banco de dados e arquitetura de software. Ele gosta de falar sobre qualquer assunto relacionado a dados, contribuindo para projetos comunitários. Michael escreve como "Database Whisperer" em michaeljswart.com.
Michael J Swart é um profissional de banco de dados e blogueiro apaixonado que se concentra em desenvolvimento de banco de dados e arquitetura de software. Ele gosta de falar sobre qualquer assunto relacionado a dados, contribuindo para projetos comunitários. Michael escreve como "Database Whisperer" em michaeljswart.com.