No mês passado eu cobri um desafio de Ilhas Especiais. A tarefa era identificar períodos de atividade para cada ID de serviço, tolerando um intervalo de até um número de entrada de segundos (
@allowedgap ). A ressalva era que a solução tinha que ser compatível com pré-2012, então você não poderia usar funções como LAG e LEAD, ou agregar funções de janela com um quadro. Eu tenho várias soluções muito interessantes postadas nos comentários de Toby Ovod-Everett, Peter Larsson e Kamil Kosno. Certifique-se de revisar suas soluções, pois todas são bastante criativas. Curiosamente, várias soluções ficaram mais lentas com o índice recomendado do que sem ele. Neste artigo, proponho uma explicação para isso.
Apesar de todas as soluções serem interessantes, aqui eu queria focar na solução de Kamil Kosno, que é desenvolvedor de ETL com Zopa. Em sua solução, Kamil usou uma técnica muito criativa para emular LAG e LEAD sem LAG e LEAD. Você provavelmente achará a técnica útil se precisar realizar cálculos semelhantes a LAG/LEAD usando código compatível com pré-2012.
Por que algumas soluções são mais rápidas sem o índice recomendado?
Como lembrete, sugeri usar o índice a seguir para apoiar as soluções para o desafio:
CRIAR ÍNDICE idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Minha solução compatível com pré-2012 foi a seguinte:
DECLARE @allowedgap AS INT =66; -- em segundos WITH C1 AS( SELECT logid, serviceid, logtime AS s, -- importante, 's'> 'e', para ordenação posterior DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog),C2 AS( SELECT logid, serviceid, logtime, eventtype, counteach, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth FROM C1 UNPIVOT(logtime FOR eventtype IN (s, e)) AS U),C3 AS( SELECT serviceid, eventtype, logtime, (ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp FROM C2 CROSS APPLY ( VALUES( CASE WHEN eventtype ='s' THEN counteach - (countboth - counteach) WHEN eventtype ='e' THEN (countboth - counteach) - counteach END ) ) AS A(countactive) WHERE ( eventtype ='s' AND countactive =1) OR (eventtype ='e' AND countactive =0))SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtimeFROM C3 PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P;
A Figura 1 tem o plano para minha solução com o índice recomendado em vigor.
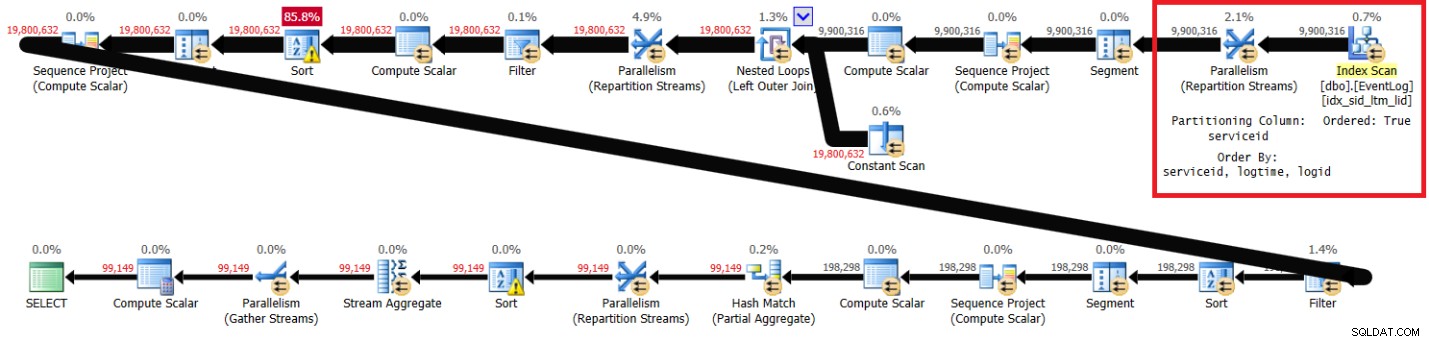 Figura 1:planejar a solução de Itzik com índice recomendado
Figura 1:planejar a solução de Itzik com índice recomendado Observe que o plano verifica o índice recomendado na ordem de chave (a propriedade Ordered é True), particiona os fluxos por serviceid usando uma troca de preservação de ordem e, em seguida, aplica o cálculo inicial de números de linha com base na ordem do índice sem a necessidade de classificação. A seguir estão as estatísticas de desempenho que obtive para esta execução de consulta no meu laptop (tempo decorrido, tempo de CPU e espera superior expressos em segundos):
decorrido:43, CPU:60, leituras lógicas:144.120, espera superior:CXPACKET:166
Em seguida, larguei o índice recomendado e executei novamente a solução:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
Eu tenho o plano mostrado na Figura 2.
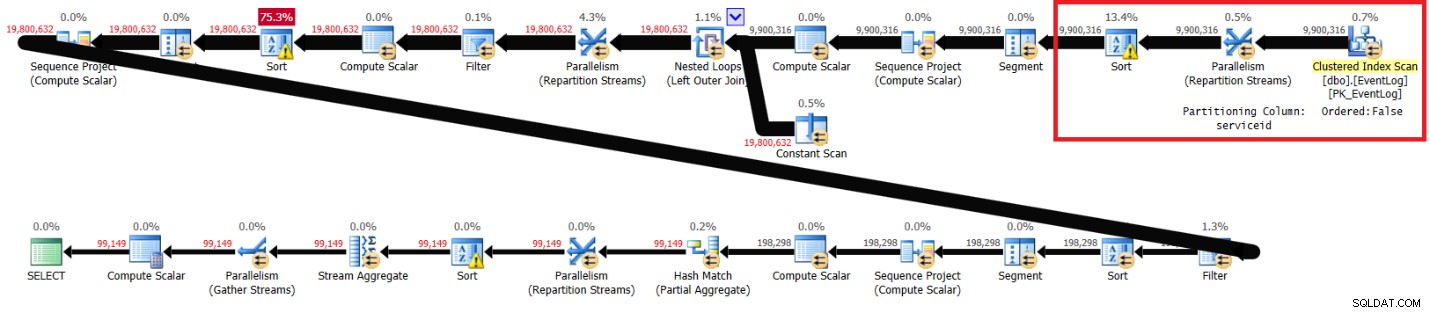 Figura 2:planejar a solução de Itzik sem índice recomendado
Figura 2:planejar a solução de Itzik sem índice recomendado As seções destacadas nos dois planos mostram a diferença. O plano sem o índice recomendado executa uma varredura não ordenada do índice clusterizado, particiona os fluxos por serviceid usando uma troca que não preserva a ordem e, em seguida, classifica as linhas como a função de janela precisa (por serviceid, logtime, logid). O resto do trabalho parece ser o mesmo em ambos os planos. Você pensaria que o plano sem o índice recomendado deve ser mais lento, pois possui uma classificação extra que o outro plano não possui. Mas aqui estão as estatísticas de desempenho que obtive para este plano no meu laptop:
decorrido:31, CPU:89, leituras lógicas:172.598, esperas de CXPACKET:84
Há mais tempo de CPU envolvido, o que em parte se deve à classificação extra; há mais E/S envolvidos, provavelmente devido a vazamentos de classificação adicionais; no entanto, o tempo decorrido é cerca de 30% mais rápido. O que poderia explicar isso? Uma maneira de tentar descobrir isso é executar a consulta no SSMS com a opção Live Query Statistics habilitada. Quando fiz isso, o operador Parallelism (Repartition Streams) mais à direita terminou em 6 segundos sem o índice recomendado e em 35 segundos com o índice recomendado. A principal diferença é que o primeiro obtém os dados pré-ordenados de um índice e é uma troca que preserva a ordem. O último obtém os dados desordenados e não é uma troca que preserva a ordem. As trocas que preservam a ordem tendem a ser mais caras do que as que não preservam a ordem. Além disso, pelo menos na parte mais à direita do plano até a primeira classificação, o primeiro entrega as linhas na mesma ordem que a coluna de particionamento de troca, para que você não faça com que todos os threads realmente processem as linhas em paralelo. O último entrega as linhas não ordenadas, para que você faça com que todos os encadeamentos processem linhas verdadeiramente em paralelo. Você pode ver que a espera superior em ambos os planos é CXPACKET, mas no primeiro caso o tempo de espera é o dobro do último, informando que o tratamento de paralelismo no último caso é mais ideal. Pode haver alguns outros fatores em jogo nos quais não estou pensando. Se você tiver ideias adicionais que possam explicar a surpreendente diferença de desempenho, compartilhe.
No meu laptop, isso resultou na execução sem o índice recomendado ser mais rápido do que aquele com o índice recomendado. Ainda assim, em outra máquina de teste, foi o contrário. Afinal, você tem um tipo extra, com potencial de derramamento.
Por curiosidade, testei uma execução serial (com a opção MAXDOP 1) com o índice recomendado e obtive as seguintes estatísticas de desempenho no meu laptop:
decorrido:42, CPU:40, leituras lógicas:143.519
Como você pode ver, o tempo de execução é semelhante ao tempo de execução da execução paralela com o índice recomendado em vigor. Eu tenho apenas 4 CPUs lógicas no meu laptop. Claro, sua milhagem pode variar com hardware diferente. A questão é que vale a pena testar diferentes alternativas, inclusive com e sem a indexação que você acha que deve ajudar. Os resultados às vezes são surpreendentes e contra-intuitivos.
Solução de Kamil
Fiquei realmente intrigado com a solução de Kamil e gostei especialmente da maneira como ele emulou LAG e LEAD com uma técnica compatível pré-2012.
Aqui está o código que implementa a primeira etapa da solução:
SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_timeFROM dbo.EventLog;
Este código gera a seguinte saída (mostrando apenas dados para serviceid 1):
serviceid logtime end_time start_time---------- -------------------- --------- ---- -------1 2018-09-12 08:00:00 1 01 2018-09-12 08:01:01 2 11 2018-09-12 08:01:59 3 21 2018-09-12 08 :03:00 4 31 2018-09-12 08:05:00 5 41 2018-09-12 08:06:02 6 5...
Esta etapa calcula dois números de linha separados por um para cada linha, particionados por serviceid e ordenados por logtime. O número da linha atual representa o horário de término (chame-o end_time), e o número da linha atual menos um representa o horário de início (chame-o start_time).
O código a seguir implementa a segunda etapa da solução:
WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT * FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U;
Esta etapa gera a seguinte saída:
serviceid logtime rownum time_type---------- ------------------------ ------- ------ -----1 2018-09-12 08:00:00 0 start_time1 2018-09-12 08:00:00 1 end_time1 2018-09-12 08:01:01 1 start_time1 2018-09-12 08:01 :01 2 end_time1 2018-09-12 08:01:59 2 start_time1 2018-09-12 08:01:59 3 end_time1 2018-09-12 08:03:00 3 start_time1 2018-09-12 08:03:00 4 end_time1 2018-09-12 08:05:00 4 start_time1 2018-09-12 08:05:00 5 end_time1 2018-09-12 08:06:02 5 start_time1 2018-09-12 08:06:02 6 end_time ...
Esta etapa desarticula cada linha em duas linhas, duplicando cada entrada de log — uma para time type start_time e outra para end_time. Como você pode ver, além dos números de linha mínimo e máximo, cada número de linha aparece duas vezes - uma com a hora de log do evento atual (start_time) e outra com a hora de log do evento anterior (end_time).
O código a seguir implementa a terceira etapa na solução:
WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT * FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P;
Este código gera a seguinte saída:
serviceid rownum start_time end_time----------- ------------------------ ------------ --------------- ---------------------------1 0 2018-09-12 08 :00:00 NULL1 1 12-09-2018 08:01:01 12-09-2018 08:00:001 2 12-09-2018 08:01:59 12-09-2018 08:01:011 3 2018- 09-12 08:03:00 2018-09-12 08:01:591 4 2018-09-12 08:05:00 2018-09-12 08:03:001 5 2018-09-12 08:06:02 2018-09-12 08:05:001 6 NULL 2018-09-12 08:06:02...
Esta etapa dinamiza os dados, agrupando pares de linhas com o mesmo número de linha e retornando uma coluna para a hora atual do log de eventos (start_time) e outra para a hora anterior do log de eventos (end_time). Esta parte emula efetivamente uma função LAG.
O código a seguir implementa a quarta etapa da solução:
DECLARE @allowedgap AS INT =66; WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grpFROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U PIVOT( MAX(logtime) FOR time_type IN(start_time, end_time)) AS PWHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap;
Este código gera a seguinte saída:
serviceid rownum start_time end_time start_time_grp end_time_grp---------- ------- -------------------- ---- ---------------- --------------- -------------1 0 2018-09- 12 08:00:00 NULL 1 01 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 11 6 NULL 2018-09-12 08:06:02 3 2...
Esta etapa filtra pares em que a diferença entre o horário de término anterior e o horário de início atual é maior que o intervalo permitido e linhas com apenas um evento. Agora você precisa conectar a hora de início de cada linha atual com a hora de término da próxima linha. Isso requer um cálculo semelhante ao LEAD. Para conseguir isso, o código, novamente, cria números de linha separados por um, só que desta vez o número da linha atual representa a hora de início (start_time_grp ) e o número da linha atual menos um representa a hora de término (end_time_grp).
Como antes, o próximo passo (número 5) é desarticular as linhas. Aqui está o código que implementa esta etapa:
DECLARE @allowedgap AS INT =66; WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog),Ranges as ( SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time) ) AS U PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap)SELECT *FROM Ranges UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS U;
Saída:
serviceid rownum start_time end_time grp grp_type---------- ------- -------------------- ---- ---------------- ---- ---------------1 0 12-09-2018 08:00:00 NULL 0 end_time_grp1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp1 0 2018-09-12 08:00:00 NULL 1 start_time_grp1 6 NULL 2018-09-12 08:06:02 2 end_time_grp1 4 12-09-2018 08:05:00 12-09-2018 08:03:00 2 start_time_grp1 6 NULL 12-09-2018 08:06:02 3 start_time_grp...
Como você pode ver, a coluna grp é exclusiva para cada ilha dentro de um ID de serviço.
A etapa 6 é a etapa final da solução. Aqui está o código que implementa esta etapa, que também é o código completo da solução:
DECLARE @allowedgap AS INT =66; WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog),Ranges as ( SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time) ) AS U PIVOT(MAX(logtime) FOR time_type IN(start_time, end_time)) AS P WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap)SELECT serviceid, MIN(start_time) AS start_time , MAX(end_time) AS end_timeFROM Intervalos UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS UGROUP BY serviceid, grpHAVING (MIN(start_time) IS NOT NULL AND MAX(end_time) IS NOT NULL);
Esta etapa gera a seguinte saída:
serviceid start_time end_time----------- --------------------------- ------ ---------------------1 2018-09-12 08:00:00 2018-09-12 08:03:001 2018-09-12 08:05 :00 12-09-2018 08:06:02...
Esta etapa agrupa as linhas por serviceid e grp, filtra apenas os grupos relevantes e retorna o start_time mínimo como o início da ilha e o tempo de término máximo como o final da ilha.
A Figura 3 tem o plano que obtive para esta solução com o índice recomendado:
CRIAR ÍNDICE idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Plano com índice recomendado na Figura 3.
Figura 3:planejar a solução da Kamil com índice recomendado
Aqui estão as estatísticas de desempenho que obtive para esta execução no meu laptop:
decorrido:44, CPU:66, leituras lógicas:72979, espera superior:CXPACKET:148
Em seguida, larguei o índice recomendado e executei novamente a solução:
DROP INDEX idx_sid_ltm_lid ON dbo.EventLog;
Eu obtive o plano mostrado na Figura 4 para a execução sem o índice recomendado.
Figura 4:planejar a solução da Kamil sem índice recomendado
Aqui estão as estatísticas de desempenho que obtive para esta execução:
decorrido:30, CPU:85, leituras lógicas:94813, espera superior:CXPACKET:70
Os tempos de execução, os tempos de CPU e os tempos de espera do CXPACKET são muito semelhantes à minha solução, embora as leituras lógicas sejam menores. A solução de Kamil também roda mais rápido no meu laptop sem o índice recomendado, e parece que é por motivos semelhantes.
Conclusão
Anomalias são uma coisa boa. Eles deixam você curioso e fazem com que você pesquise a causa raiz do problema e, como resultado, aprenda coisas novas. É interessante ver que algumas consultas, em determinadas máquinas, são executadas mais rapidamente sem a indexação recomendada.
Obrigado novamente a Toby, Peter e Kamil por suas soluções. Neste artigo, abordei a solução de Kamil, com sua técnica criativa para emular LAG e LEAD com números de linha, unpivoting e pivoting. Você achará essa técnica útil ao precisar de cálculos semelhantes a LAG e LEAD que precisam ser suportados em ambientes anteriores a 2012.



