Um dos termos mais comuns nas discussões sobre o ajuste de desempenho do SQL Server é estatísticas de espera . Isso remonta a um longo caminho, mesmo antes deste documento da Microsoft de 2006, "SQL Server 2005 Waits and Queues".
As esperas não são absolutamente tudo, e essa metodologia não é a única maneira de ajustar uma instância, muito menos uma consulta individual. Na verdade, as esperas geralmente são inúteis quando tudo o que você tem é a consulta que as sofreu e nenhum contexto circundante, especialmente muito tempo depois do fato. Isso ocorre porque, muitas vezes, o que uma consulta está esperando não é culpa dessa consulta . Como qualquer coisa, há exceções, mas se você está escolhendo uma ferramenta ou script apenas porque oferece essa funcionalidade muito específica, acho que você está fazendo um desserviço a si mesmo. Costumo seguir um conselho que Paul Randal me deu há algum tempo:
…geralmente eu recomendo começar com esperas de instância inteiras. Eu nunca começaria solução de problemas observando as esperas de consulta individuais.
Ocasionalmente, sim, você pode querer se aprofundar em uma consulta individual e ver o que ela está esperando; na verdade, a Microsoft recentemente adicionou estatísticas de espera em nível de consulta ao showplan para ajudar nessa análise. Mas esses números geralmente não ajudarão você a ajustar o desempenho de sua instância como um todo, a menos que estejam ajudando a apontar algo que também esteja afetando toda a sua carga de trabalho. Se você vir uma consulta de ontem que foi executada por 5 minutos e perceber que seu tipo de espera era
LCK_M_S , o que você vai fazer sobre isso agora? Como você vai rastrear o que estava realmente bloqueando a consulta e causando esse tipo de espera? Pode ter sido causado por uma transação que não estava sendo confirmada por algum outro motivo, mas você não pode ver isso se não puder ver o estado de todo o sistema e estiver se concentrando apenas em consultas individuais e nas esperas que elas experimentaram. Jason Hall (@SQLSaurus) mencionou algo de passagem que também foi interessante para mim. Ele disse que se as estatísticas de espera no nível de consulta fossem uma parte tão importante dos esforços de ajuste, essa metodologia teria sido incorporada ao Query Store desde o início. Ele foi adicionado recentemente (no SQL Server 2017). Mas você ainda não obtém estatísticas de espera por execução; você obtém médias ao longo do tempo, como as estatísticas de consulta e estatísticas de procedimento que você vê nos DMVs. Portanto, anomalias repentinas podem ser aparentes com base em outras métricas capturadas por execução de consulta, mas não com base nas médias de tempos de espera que são extraídas de todas execuções. Você pode personalizar as esperas de intervalo são agregadas, mas em sistemas ocupados isso ainda pode não ser granular o suficiente para fazer o que você acha que fará por você.
O objetivo deste post é discutir alguns dos tipos de espera mais comuns que vemos em nossa base de clientes e que tipo de ações você pode (e não deve) tomar quando elas acontecem. Temos um banco de dados de estatísticas de espera anônimas que coletamos de nossos clientes do Cloud Sync há algum tempo e, desde maio de 2017, mostramos a todos como elas são exibidas na biblioteca de esperas do SQLskills.
Paul fala sobre a razão por trás da biblioteca e também sobre nossa integração com este serviço gratuito. Basicamente, você procura um tipo de espera que está experimentando ou curioso, e ele explica o que isso significa e o que você pode fazer a respeito. Complementamos essas informações qualitativas com um gráfico que mostra a prevalência da espera atual entre nossa base de usuários, comparando-a com todos os outros tipos de espera que vemos, para que você possa dizer rapidamente se está lidando com um tipo de espera comum ou algo um pouco mais exótico. (Lembre-se de que o SQL Sentry não inclui as esperas benignas, em segundo plano e de fila que representam ruído e que a maioria dos scripts por aí são filtradas, como WAITFOR ou LAZYWRITER_SLEEP – essas não são apenas fontes de problemas de desempenho.)
Aqui está um gráfico de exemplo para
CXPACKET , o tipo de espera mais comum por aí: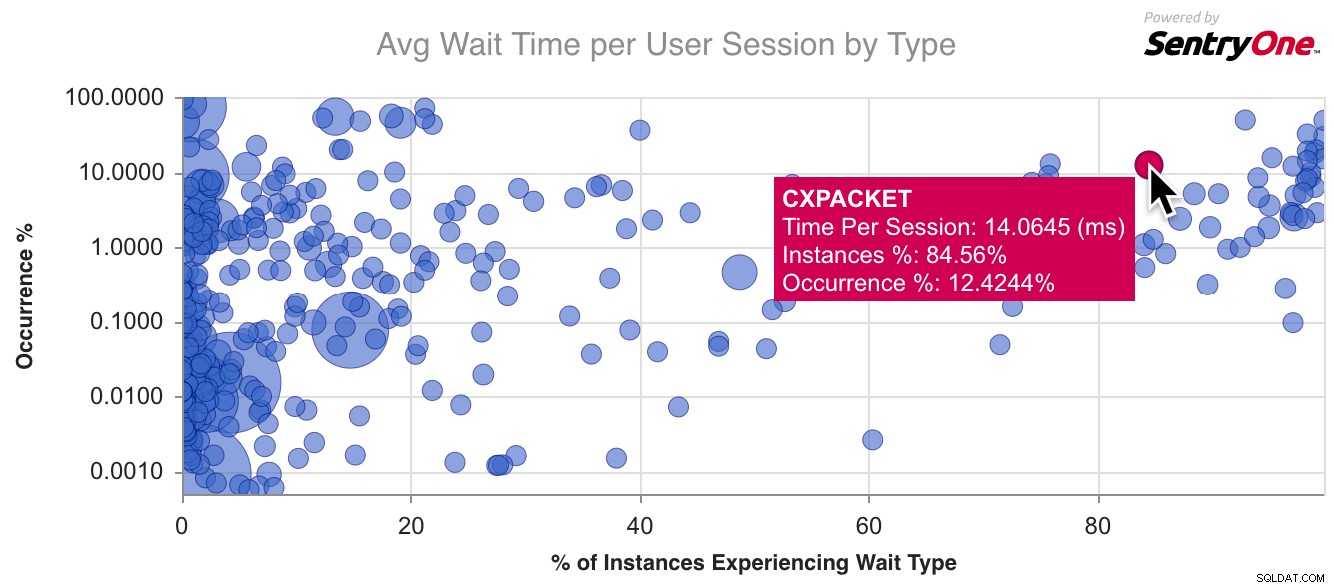
Comecei a ir um pouco além disso, mapeando alguns dos tipos de espera mais comuns e observando algumas das propriedades que eles compartilhavam. Traduzido em perguntas que um sintonizador pode ter sobre um tipo de espera que está enfrentando:
- O tipo de espera pode ser resolvido no nível da consulta?
- É provável que o sintoma principal da espera esteja afetando outras consultas?
- É provável que você precise de mais informações fora do contexto de uma única consulta e dos tipos de espera que ela enfrentou para "resolver" o problema?
Quando comecei a escrever este post, meu objetivo era apenas agrupar os tipos de espera mais comuns e, em seguida, começar a fazer anotações sobre eles relacionados às perguntas acima. Jason pegou os mais comuns da biblioteca, e então desenhei alguns arranhões de galinha em um quadro branco, que depois arrumei um pouco. Essa pesquisa inicial levou a uma palestra que Jason deu no mais recente TechOutbound SQL Cruise no Alasca. Estou meio envergonhado por ele ter feito uma palestra meses antes de eu terminar este post, então vamos continuar com isso. Aqui estão as principais esperas que vemos (que correspondem amplamente à pesquisa de Paul de 2014), minhas respostas às perguntas acima e alguns comentários sobre cada uma delas:
Para interagir com os links na tabela abaixo, visite esta página em uma tela maior.
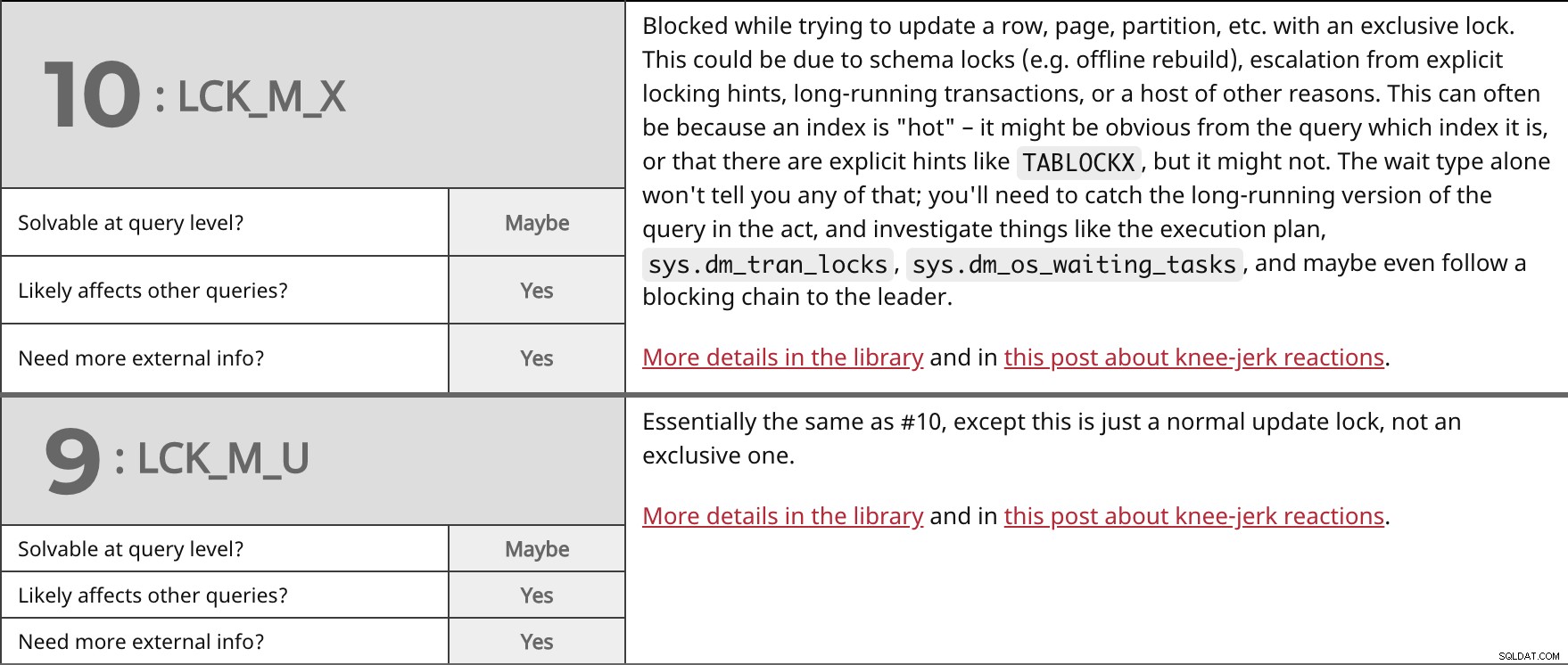
Bloqueado ao tentar atualizar uma linha, página, partição, etc. com um bloqueio exclusivo. Isso pode ser devido a bloqueios de esquema (por exemplo, reconstrução offline), escalação de dicas de bloqueio explícitas, transações de longa duração ou uma série de outros motivos. Isso geralmente ocorre porque um índice é "quente" - pode ser óbvio na consulta qual índice é, ou que existem dicas explícitas como TABLOCKX , mas talvez não. O tipo de espera sozinho não lhe dirá nada disso; você precisará capturar a versão de longa duração da consulta em ação e investigar coisas como o plano de execução, sys.dm_tran_locks , sys.dm_os_waiting_tasks , e talvez até siga uma cadeia de bloqueio até o líder. Mais detalhes na biblioteca e neste post sobre reações automáticas. | ||
| Solúvel no nível da consulta? | Talvez | |
| Sim | ||
| Precisa de mais informações externas? | Sim | |
|
Essencialmente o mesmo que #10, exceto que este é apenas um bloqueio de atualização normal, não um exclusivo. Mais detalhes na biblioteca e neste post sobre reações automáticas. | ||
| Solúvel no nível da consulta? | Talvez | |
| Sim | ||
| Precisa de mais informações externas? | Sim | |
|
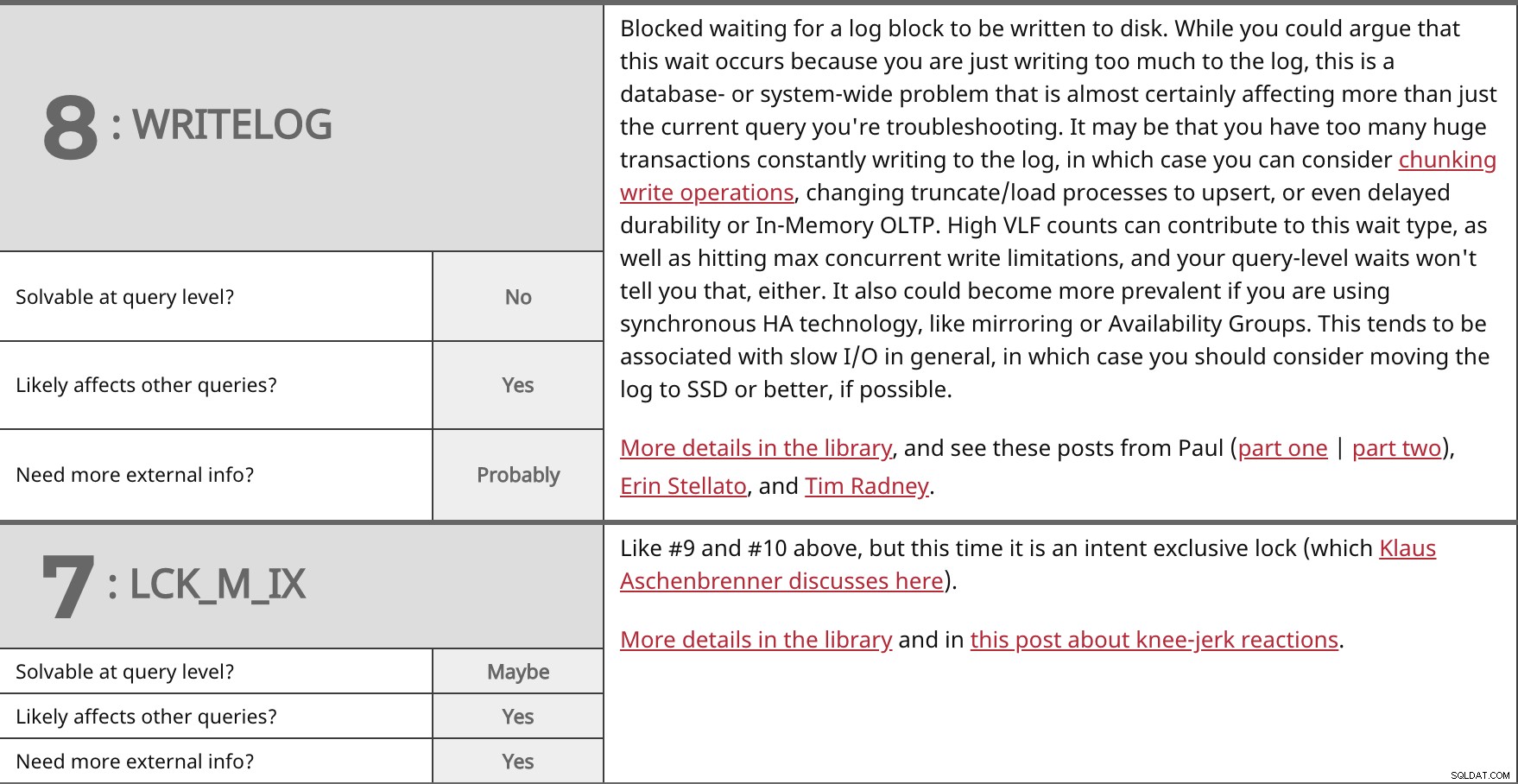
Bloqueado aguardando a gravação de um bloco de log no disco. Embora você possa argumentar que essa espera ocorre porque você está gravando demais no log, esse é um problema de banco de dados ou de todo o sistema que quase certamente está afetando mais do que apenas a consulta atual que você está solucionando. Pode ser que você tenha muitas transações enormes constantemente gravando no log; nesse caso, você pode considerar operações de gravação em partes, alterar processos de truncar/carregar para upsert ou até mesmo durabilidade atrasada ou OLTP na memória. Contagens altas de VLF podem contribuir para esse tipo de espera, além de atingir as limitações máximas de gravação simultânea, e suas esperas no nível de consulta também não informarão isso. Também pode se tornar mais prevalente se você estiver usando tecnologia de alta disponibilidade síncrona, como espelhamento ou grupos de disponibilidade. Isso tende a estar associado a E/S lenta em geral; nesse caso, você deve considerar mover o log para SSD ou melhor, se possível. Mais detalhes na biblioteca e veja essas postagens de Paul (parte um | parte dois), Erin Stellato e Tim Radney. | ||
| Solúvel no nível da consulta? | Não | |
| Sim | ||
| Precisa de mais informações externas? | Provavelmente | |
|
Como #9 e #10 acima, mas desta vez é um bloqueio exclusivo de intenção (que Klaus Aschenbrenner discute aqui). Mais detalhes na biblioteca e neste post sobre reações automáticas. | ||
| Solúvel no nível da consulta? | Talvez | |
| Sim | ||
| Precisa de mais informações externas? | Sim | |
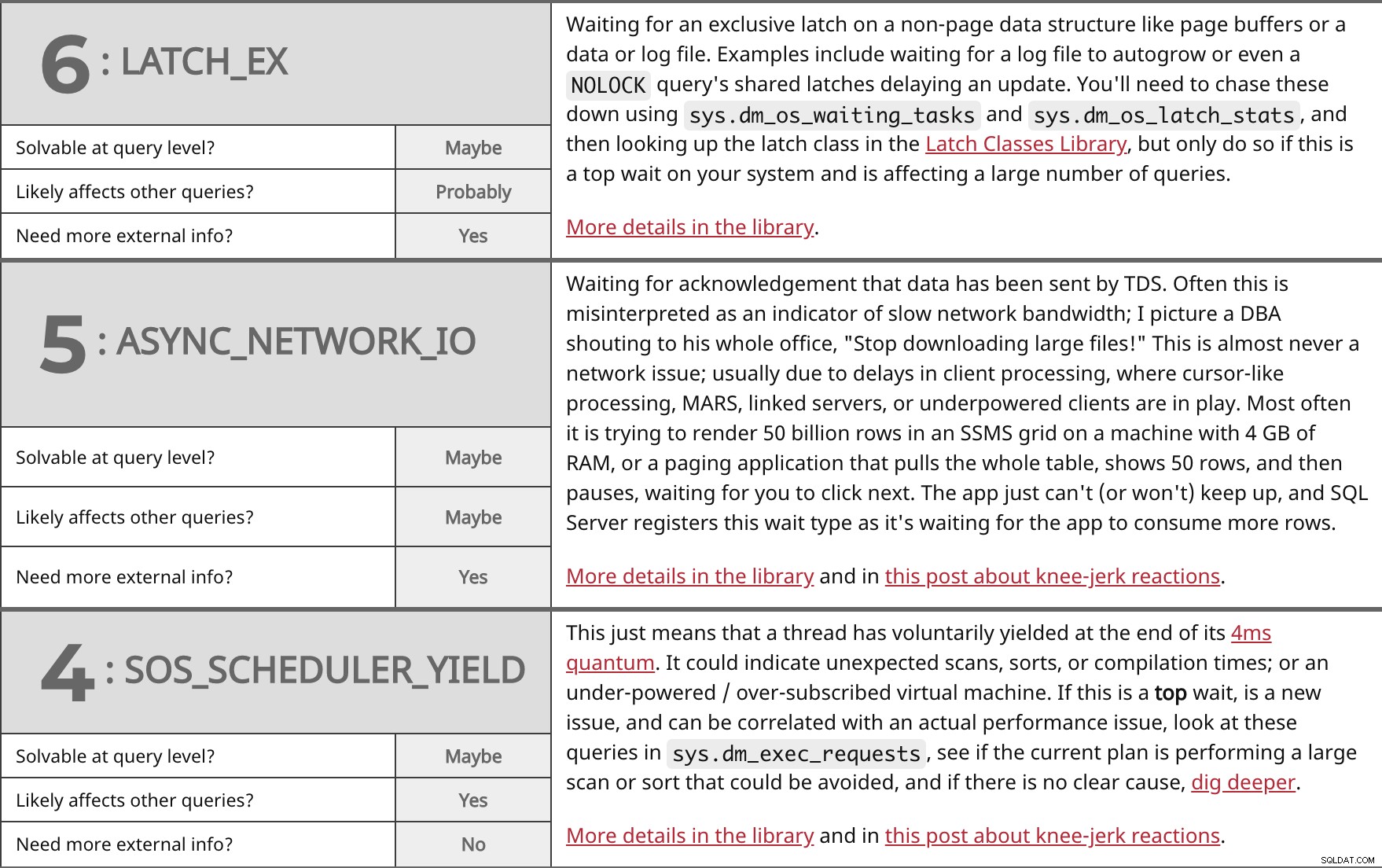
Aguardando uma trava exclusiva em uma estrutura de dados que não seja de página, como buffers de página ou um arquivo de dados ou log. Os exemplos incluem esperar que um arquivo de log cresça automaticamente ou até mesmo um NOLOCK travas compartilhadas da consulta atrasando uma atualização. Você precisará persegui-los usando sys.dm_os_waiting_tasks e sys.dm_os_latch_stats e, em seguida, procurando a classe de trava na Biblioteca de classes de trava, mas só faça isso se esta for uma espera superior em seu sistema e estiver afetando um grande número de consultas. Mais detalhes na biblioteca. | ||
| Solúvel no nível da consulta? | Talvez | |
| Provavelmente | ||
| Precisa de mais informações externas? | Sim | |
|
Aguardando confirmação de que os dados foram enviados pelo TDS. Muitas vezes, isso é mal interpretado como um indicador de largura de banda de rede lenta; Imagino um DBA gritando para todo o seu escritório:"Pare de baixar arquivos grandes!" Isso quase nunca é um problema de rede; geralmente devido a atrasos no processamento do cliente, onde o processamento tipo cursor, MARS, servidores vinculados ou clientes com pouca potência estão em jogo. Na maioria das vezes, ele está tentando renderizar 50 bilhões de linhas em uma grade SSMS em uma máquina com 4 GB de RAM ou um aplicativo de paginação que extrai a tabela inteira, mostra 50 linhas e pausa, esperando você clicar em próximo. O aplicativo simplesmente não consegue (ou não) acompanhar, e o SQL Server registra esse tipo de espera enquanto aguarda o aplicativo consumir mais linhas. Mais detalhes na biblioteca e neste post sobre reações automáticas. | ||
| Solúvel no nível da consulta? | Talvez | |
| Talvez | ||
| Precisa de mais informações externas? | Sim | |
Isso significa apenas que um thread cedeu voluntariamente ao final de seu quantum de 4ms. Pode indicar varreduras, classificações ou tempos de compilação inesperados; ou uma máquina virtual com pouca potência/com excesso de assinatura. Se este for um top espere, é um problema novo e pode ser correlacionado com um problema real de desempenho, veja essas consultas em sys.dm_exec_requests , veja se o plano atual está executando uma grande varredura ou classificação que poderia ser evitada e, se não houver uma causa clara, aprofunde-se. Mais detalhes na biblioteca e neste post sobre reações automáticas. | ||
| Solúvel no nível da consulta? | Talvez | |
| Sim | ||
| Precisa de mais informações externas? | Não | |
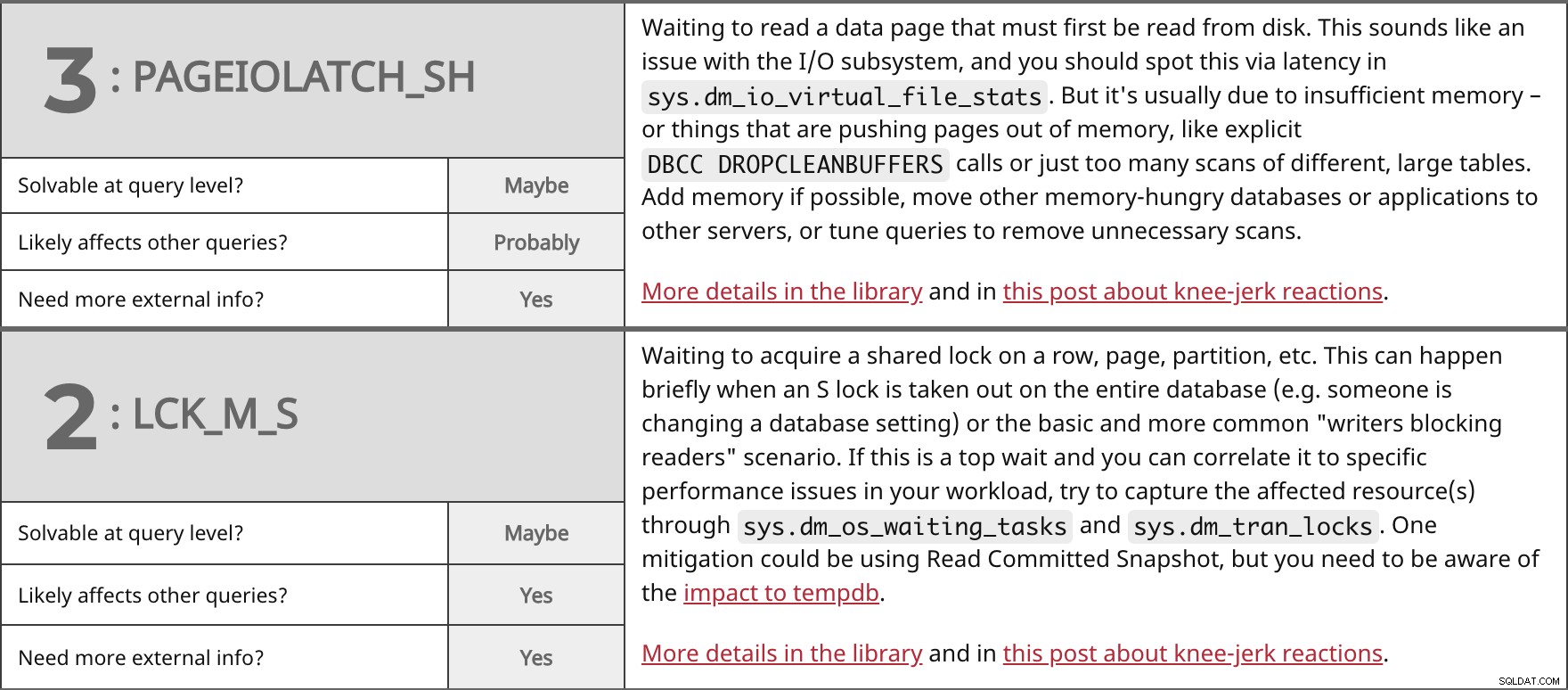
Aguardando para ler uma página de dados que deve primeiro ser lida do disco. Isso parece um problema com o subsistema de E/S, e você deve identificar isso por meio de latência em sys.dm_io_virtual_file_stats . Mas geralmente é devido à memória insuficiente - ou coisas que estão empurrando as páginas para fora da memória, como DBCC DROPCLEANBUFFERS explícito chamadas ou apenas muitas varreduras de tabelas grandes e diferentes. Adicione memória, se possível, mova outros bancos de dados ou aplicativos que consomem muita memória para outros servidores ou ajuste as consultas para remover varreduras desnecessárias. Mais detalhes na biblioteca e neste post sobre reações automáticas. | ||
| Solúvel no nível da consulta? | Talvez | |
| Provavelmente | ||
| Precisa de mais informações externas? | Sim | |
Aguardando para adquirir um bloqueio compartilhado em uma linha, página, partição, etc. Isso pode acontecer brevemente quando um bloqueio S é removido em todo o banco de dados (por exemplo, alguém está alterando uma configuração de banco de dados) ou o cenário básico e mais comum de "gravadores bloqueando leitores". Se esta for uma espera superior e você puder correlacioná-la a problemas de desempenho específicos em sua carga de trabalho, tente capturar os recursos afetados por meio de sys.dm_os_waiting_tasks e sys.dm_tran_locks . Uma mitigação pode estar usando o instantâneo de leitura confirmada, mas você precisa estar ciente do impacto no tempdb. Mais detalhes na biblioteca e neste post sobre reações automáticas. | ||
| Solúvel no nível da consulta? | Talvez | |
| Sim | ||
| Precisa de mais informações externas? | Sim | |
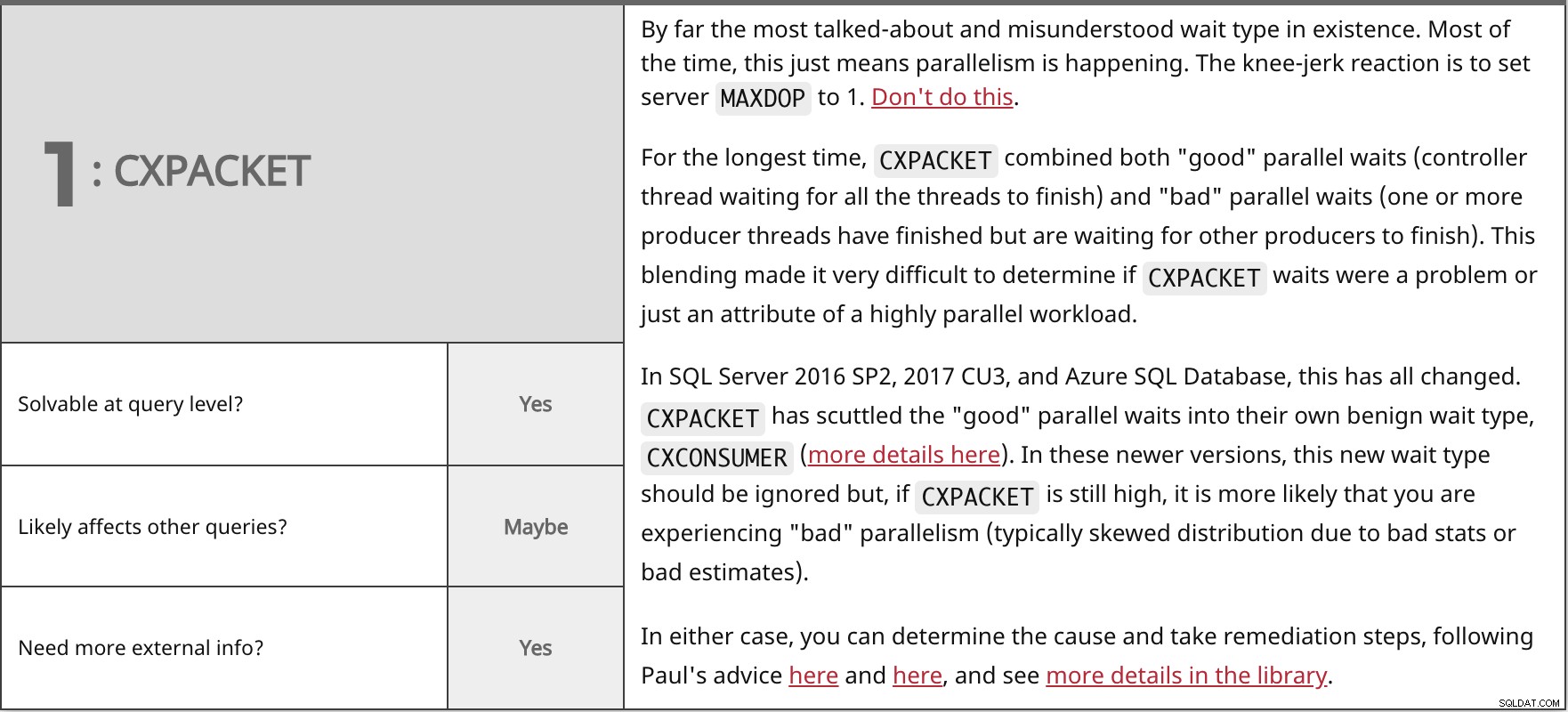
De longe o tipo de espera mais falado e incompreendido que existe. Na maioria das vezes, isso significa apenas que o paralelismo está acontecendo. A reação automática é definir o servidor MAXDOP para 1. Não faça isso. Por muito tempo, CXPACKET combinou esperas paralelas "boas" (thread do controlador esperando que todos os threads terminem) e esperas paralelas "ruins" (um ou mais threads do produtor terminaram, mas estão esperando que outros produtores terminem). Essa combinação tornou muito difícil determinar se CXPACKET esperas eram um problema ou apenas um atributo de uma carga de trabalho altamente paralela. No SQL Server 2016 SP2, 2017 CU3 e no Banco de Dados SQL do Azure, tudo isso mudou. CXPACKET afundou as "boas" esperas paralelas em seu próprio tipo de espera benigno, CXCONSUMER (mais detalhes aqui). Nestas versões mais recentes, este novo tipo de espera deve ser ignorado, mas se CXPACKET ainda for alto, é mais provável que você esteja enfrentando um paralelismo "ruim" (normalmente distribuição distorcida devido a estatísticas ruins ou estimativas ruins). Em ambos os casos, você pode determinar a causa e tomar medidas de correção, seguindo os conselhos de Paul aqui e aqui, e ver mais detalhes na biblioteca. | ||
| Solúvel no nível da consulta? | Sim | |
| Talvez | ||
| Precisa de mais informações externas? | Sim | |
Resumo
Na maioria desses casos, é melhor observar as esperas no nível da instância e apenas aprimorar as esperas no nível da consulta quando você estiver solucionando problemas de consultas específicas que apresentam problemas de desempenho, independentemente do tipo de espera. Essas são coisas que surgem por outros motivos, como longa duração, alta CPU ou alta E/S, e não podem ser explicadas por coisas mais simples (como uma verificação de índice clusterizado quando você esperava uma busca).
Mesmo no nível da instância, não persiga cada espera que se torne a principal espera em seu sistema - você SEMPRE tenha uma espera superior, e você nunca será capaz de parar de persegui-la. Certifique-se de ignorar esperas benignas (Paul mantém uma lista) e se preocupe apenas com esperas que você possa associar a um problema real de desempenho que esteja enfrentando. Se
CXPACKET esperas são altas, e daí? Existem outros sintomas além desse número ser "alto" ou estar no topo da lista? Tudo se resume ao motivo pelo qual você está solucionando problemas em primeiro lugar. Um único usuário está reclamando sobre uma única instância de uma consulta não autorizada? Seu servidor está de joelhos? Algo no meio? No primeiro caso, é claro, saber por que uma consulta é lenta pode ser útil, mas é muito caro rastrear (não importa manter indefinidamente) todas as esperas associadas a cada consulta, o dia todo, todos os dias, com a chance de você quer voltar e revisá-los mais tarde. Se for um problema generalizado isolado para essa consulta, você poderá determinar o que está tornando essa consulta lenta executando-a novamente e coletando o plano de execução, o tempo de compilação e outras métricas de tempo de execução. Se foi uma coisa única que aconteceu na terça-feira passada, se você espera por essa única instância da consulta ou não, talvez não consiga resolver o problema sem mais contexto. Talvez tenha havido um bloqueio, mas você não saberá por quê, ou talvez tenha havido um pico de E/S, mas você terá que rastrear esse problema separadamente. O tipo de espera por si só geralmente não fornece informações suficientes, exceto, na melhor das hipóteses, um ponteiro para outra coisa.
Claro, eu preciso ganhar meu sustento, aqui também. Nosso principal produto, SQL Sentry, adota uma abordagem holística ao monitoramento. Coletamos estatísticas de espera em toda a instância, as categorizamos para você e as grafamos em nosso painel:
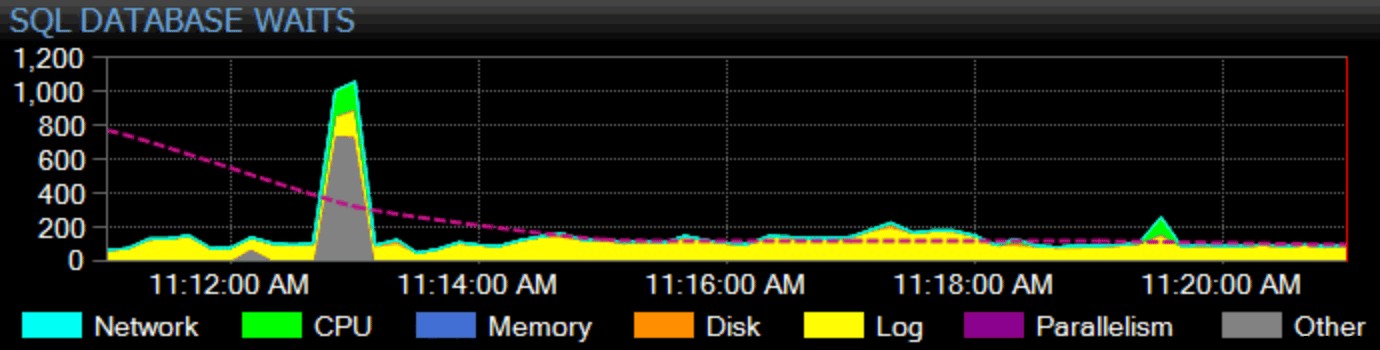
Você pode personalizar como qualquer espera individual é categorizada e se essa categoria aparece ou não no painel. Você pode comparar as estatísticas de espera atuais com linhas de base integradas ou personalizadas e até configurar alertas ou ações quando excederem algum desvio definido da linha de base. E, talvez o mais importante, você pode examinar um ponto de dados do passado e sincronizar todo o painel com esse ponto no tempo, para capturar todo o contexto ao redor e qualquer outra situação que possa ter influenciado o problema. Quando você encontra coisas mais granulares para se concentrar, como bloqueio, alta latência de disco ou consultas com alta E/S ou longa duração, pode detalhar essas métricas e chegar à raiz do problema rapidamente.
Para obter mais informações sobre as abordagens gerais de estatísticas de espera e nossa solução especificamente, consulte o white paper de Kevin Kline, Troubleshooting SQL Server Wait Stats, e baixe um webinar de duas partes apresentado por Paul Randal, Andy Yun (@SQLBek), e Andy Mallon (@AMtwo):
- Parte 1:Solução de problemas de desempenho usando estatísticas de espera
- Parte 2:Análise rápida de estatísticas de espera com o SentryOne
E se você quiser experimentar a Plataforma SentryOne, pode começar aqui com uma oferta por tempo limitado:
Baixe um teste gratuito de 15 dias