Recentemente, estive envolvido no desenvolvimento da funcionalidade que exigia uma transferência rápida e frequente de grandes volumes de dados para o disco. Além disso, esses dados deveriam ser lidos do disco de tempos em tempos. Portanto, eu estava destinado a descobrir o local, a forma e os meios para armazenar esses dados. Neste artigo, revisarei brevemente a tarefa, além de investigar e comparar soluções para a conclusão desta tarefa.
Contexto da tarefa :Trabalho em uma equipe que desenvolve ferramentas para desenvolvimento de banco de dados relativo (SQL Server, MySQL, Oracle). A gama de ferramentas inclui ferramentas independentes e suplementos para MS SSMS.
Tarefa :Restaurando documentos que foram abertos no momento do fechamento do IDE no próximo início do IDE.
Caso de uso :Para fechar o IDE rapidamente antes de sair do escritório sem pensar em quais documentos foram salvos e quais não foram. No próximo início do IDE, precisamos obter o mesmo ambiente que estava no momento do fechamento e continuar o trabalho. Todos os resultados do trabalho devem ser salvos no momento do fechamento desordenado, por ex. durante a falha de um programa ou sistema operacional, ou durante o desligamento.
Análise de tarefas :O recurso semelhante está presente em navegadores da web. No entanto, os navegadores armazenam apenas URLs que consistem em aproximadamente 100 símbolos. No nosso caso, precisamos armazenar todo o conteúdo do documento. Portanto, precisamos de um local para salvar e armazenar os documentos do usuário. Além disso, às vezes os usuários trabalham com SQL de maneira diferente do que com outras linguagens. Por exemplo, se eu escrever uma classe C# com mais de 1000 linhas, dificilmente será aceitável. Enquanto, no universo SQL, juntamente com consultas de 10 a 20 linhas, existem os despejos de banco de dados monstruosos. Esses despejos dificilmente são editáveis, o que significa que os usuários preferem manter suas edições seguras.
Requisitos para um armazenamento:
- Deve ser uma solução incorporada leve.
- Deve ter alta velocidade de gravação.
- Deve ter a opção de acesso multiprocessamento. Esse requisito não é crítico, pois podemos garantir o acesso com a ajuda dos objetos de sincronização, mas ainda assim, seria bom ter essa opção.
Candidatos
O primeiro candidato é bastante desajeitado, ou seja, armazenar tudo em uma pasta, em algum lugar do AppData.
O segundo candidato é óbvio – SQLite, um padrão de bancos de dados embutidos. Candidato muito sólido e popular.
O terceiro candidato é o banco de dados LiteDB. É o primeiro resultado para a consulta de “banco de dados incorporado para .net” no Google.
Primeira vista
Sistema de arquivo. Arquivos são arquivos, eles exigem manutenção e nomenclatura adequada. Além do conteúdo do arquivo, precisaremos armazenar um pequeno conjunto de propriedades (caminho original no disco, string de conexão, versão do IDE, em que foi aberto). Isso significa que teremos que criar dois arquivos para um documento ou inventar um formato que separe as propriedades do conteúdo.
SQLite é um banco de dados relacional clássico. O banco de dados é representado por um arquivo em disco. Este arquivo está sendo vinculado ao esquema do banco de dados, após o qual devemos interagir com ele com a ajuda dos meios SQL. Poderemos criar 2 tabelas, uma para propriedades e outra para conteúdo, caso precisemos usar propriedades ou conteúdo separadamente.
LiteDB é um banco de dados não relacional. Semelhante ao SQLite, o banco de dados é representado por um único arquivo. Está inteiramente escrito em С#. Tem uma simplicidade de uso cativante:basta dar um objeto à biblioteca, enquanto a serialização será realizada por meios próprios.
Teste de desempenho
Antes de fornecer o código, gostaria de explicar a concepção geral e fornecer resultados de comparação.
A concepção geral é comparar a velocidade de gravação de grande quantidade de arquivos pequenos no banco de dados, quantidade média de arquivos médios e uma pequena quantidade de arquivos grandes. O caso com arquivos médios é mais próximo do caso real, enquanto os casos com arquivos pequenos e grandes são casos limítrofes, que também devem ser levados em consideração.
Eu estava escrevendo conteúdo em um arquivo com a ajuda do FileStream com o tamanho padrão do buffer.
Havia uma nuance no SQLite que eu gostaria de mencionar. Não foi possível colocar todo o conteúdo do documento (como mencionei acima, eles podem ser muito grandes) em uma célula do banco de dados. O problema é que, para fins de otimização, armazenamos o texto do documento linha por linha. Isso significa que, para colocar texto em uma única célula, precisamos colocar todos os documentos em uma única linha, o que duplicaria a quantidade de memória operacional usada. O outro lado do problema se revelaria durante a leitura de dados do banco de dados. Por isso, havia uma tabela separada no SQLite, onde os dados eram armazenados linha por linha e os dados eram vinculados com a ajuda de chave estrangeira com a tabela contendo apenas as propriedades do arquivo. Além disso, consegui acelerar o banco de dados com inserção de dados em lote (várias mil linhas por vez) no modo de sincronização OFF sem log e dentro de uma transação.
O LiteDB recebeu um objeto com List entre suas propriedades e a biblioteca o salvou em disco por conta própria.
Durante o desenvolvimento do aplicativo de teste, entendi que prefiro o LiteDB. A coisa é que o código de teste para SQLite leva mais de 120 linhas, enquanto o código, que resolve o mesmo problema no LiteDb, leva apenas 20 linhas.
Geração de dados de teste
FileStrings.cs
internal class FileStrings { private static readonly Random random =new Random(); public List Strings { get; definir; } =new Lista(); public int SomeInfo { get; definir; } public FileStrings() { } public FileStrings(int id, int minLines, decimal lineIncrement) { SomeInfo =id; int linhas =minLines + (int)(id * lineIncrement); for (int i =0; i new FileStrings(f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (decimal)NUM_FILES)) .ToList();
SQLite
private static void SaveToDb(List files) { using (var connection =new SQLiteConnection()) { connection.ConnectionString =@"Data Source=data\database.db;FailIfMissing=False;"; conexão.Abrir(); comando var =connection.CreateCommand(); command.CommandText =@"CREATE TABLE files( id INTEGER PRIMARY KEY, file_name TEXT);CREATE TABLE strings( id INTEGER PRIMARY KEY, string TEXT, file_id INTEGER, line_number INTEGER);CREATE UNIQUE INDEX strings_file_id_line_number_uindex ON strings(file_id,line_number); PRAGMA síncrono =OFF; PRAGMA journal_mode =OFF"; command.ExecuteNonQuery(); var insertFilecommand =connection.CreateCommand(); insertFilecommand.CommandText ="INSERT INTO files(file_name) VALUES(?); SELECT last_insert_rowid();"; insertFilecommand.Parameters.Add(insertFilecommand.CreateParameter()); insertFilecommand.Prepare(); var insertLineCommand =connection.CreateCommand(); insertLineCommand.CommandText ="INSERT INTO strings(string, file_id, line_number) VALUES(?, ?, ?);"; insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Prepare(); foreach (var item nos arquivos) { using (var tr =connection.BeginTransaction()) { SaveToDb(item, insertFilecommand, insertLineCommand); tr.Commit(); } } } } private static void SaveToDb(FileStrings item, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) { string fileName =Path.Combine("data", item.SomeInfo + ".sql"); insertFileCommand.Parameters[0].Value =fileName; var fileId =insertFileCommand.ExecuteScalar(); int lineIndex =0; foreach (var line in item.Strings) { insertLinesCommand.Parameters[0].Value =line; insertLinesCommand.Parameters[1].Value =fileId; insertLinesCommand.Parameters[2].Value =lineIndex++; insertLinesCommand.ExecuteNonQuery(); } }
LiteDB
private static void SaveToNoSql(List item) { using (var db =new LiteDatabase("data\\litedb.db")) { var data =db.GetCollection("files"); data.EnsureIndex(f => f.SomeInfo); dados.Inserir(item); } }
A tabela a seguir mostra os resultados médios para várias execuções do código de teste. Durante as modificações, o desvio estatístico foi bastante imperceptível.
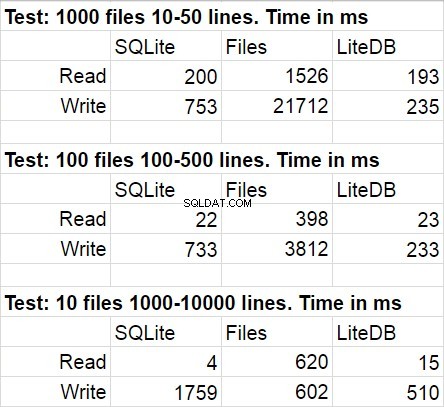
Não fiquei surpreso que o LiteDB tenha vencido nesta comparação. No entanto, fiquei chocado com a vitória do LiteDB sobre os arquivos. Após um breve estudo do repositório da biblioteca, descobri que a gravação paginada em disco foi implementada de maneira muito meticulosa, mas tenho certeza de que esse é apenas um dos muitos truques de desempenho usados lá. Mais uma coisa que eu gostaria de salientar é uma velocidade rápida de acesso ao sistema de arquivos diminuir quando a quantidade de arquivos na pasta se torna muito grande.
Selecionamos o LiteDB para o desenvolvimento do nosso recurso e dificilmente nos arrependemos dessa escolha. O fato é que a biblioteca é escrita em C# nativo para todos, e se algo não ficou claro, sempre poderíamos nos referir ao código-fonte.
Contras
Além dos prós mencionados acima do LiteDB em comparação com seus concorrentes, começamos a notar desvantagens durante o desenvolvimento. A maioria desses contras pode ser explicada pela 'juventude' da biblioteca. Tendo começado a usar a biblioteca um pouco além dos limites do cenário "padrão", descobrimos vários problemas (#419, #420, #483, #496). O autor da biblioteca respondeu às perguntas com bastante rapidez, e a maioria dos problemas foi resolvida rapidamente. Agora, resta apenas uma tarefa (não confunda com o status Fechado). Esta é uma questão do acesso competitivo. Parece que uma condição de corrida muito desagradável está escondida em algum lugar no fundo da biblioteca. Passamos por cima deste bug de uma forma bastante original (pretendo escrever um artigo separado sobre este assunto).
Gostaria também de mencionar a ausência de editor e visualizador puros. Existe o LiteDBShell, mas é apenas para verdadeiros fãs de console.
Resumo
Construímos uma funcionalidade grande e importante sobre o LiteDB, e agora estamos trabalhando em outro grande recurso onde também usaremos essa biblioteca. Para quem procura um banco de dados em processo, sugiro prestar atenção ao LiteDB e à forma como ele se mostrará no contexto de sua tarefa, pois, como você sabe, se algo tivesse dado certo para uma tarefa, não necessariamente trabalhar para outra tarefa.