Saber por qual das colunas você deseja agrupar e como deseja agrupá-las, primeiro, é importante. Você precisará saber disso para configurar a
CASE STATEMENT vamos escrever como uma coluna em nossa instrução select. No nosso caso, em um grupo de e-mails que estão acessando nosso site, queremos saber quantos cliques cada provedor de e-mail está contabilizando desde o início de agosto. Também gostaríamos de comparar um provedor de serviços de e-mail individual com os demais. Para este exemplo, usaremos o Gmail como nosso provedor de serviços. Em nosso
SELECT declaração, precisaremos do DATE , o PROVEDOR e a SOMA dos CLIQUES ao nosso site. Podemos obtê-los no TEST E MAILS tabela em nossa fonte de dados. A
DATA coluna é bastante simples:"Test E Mails"."Created_Date" AS "DATE
E como estamos procurando o
SUM dos CLIQUES , precisaremos converter um SUM função sobre os CLICKS coluna. SUM("Test E Mails"."Clicks") AS "CLICKS"
Isso nos leva ao nosso
CASE STATEMENT . Sabemos pela Documentação do PostgreSQL que uma CASE STATEMENT, ou uma instrução condicional, precisa ser organizada da seguinte maneira:CASE
WHEN condition THEN result
[WHEN ...]
[ELSE result]
END
Nossa primeira e, neste caso apenas, condição é que queremos saber que todos os endereços de e-mail fornecidos pelo Gmail sejam separados de todos os outros provedores de e-mail. Portanto, o único
QUANDO é:WHEN "Test E Mails"."Provider" = 'Gmail' THEN 'Gmail'
E, a instrução else seria 'Outro' para todos os outros provedores de endereço de e-mail. A tabela resultante desta
CASE STATEMENT apenas com os e-mails correspondentes. Ficaria assim: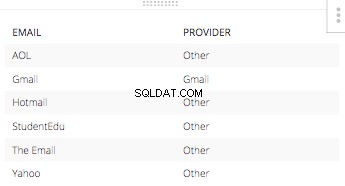
Quando você divide todas essas três colunas para um
SELECT STATEMENT e jogue o resto das peças necessárias para construir uma consulta SQL, tudo toma forma abaixo. 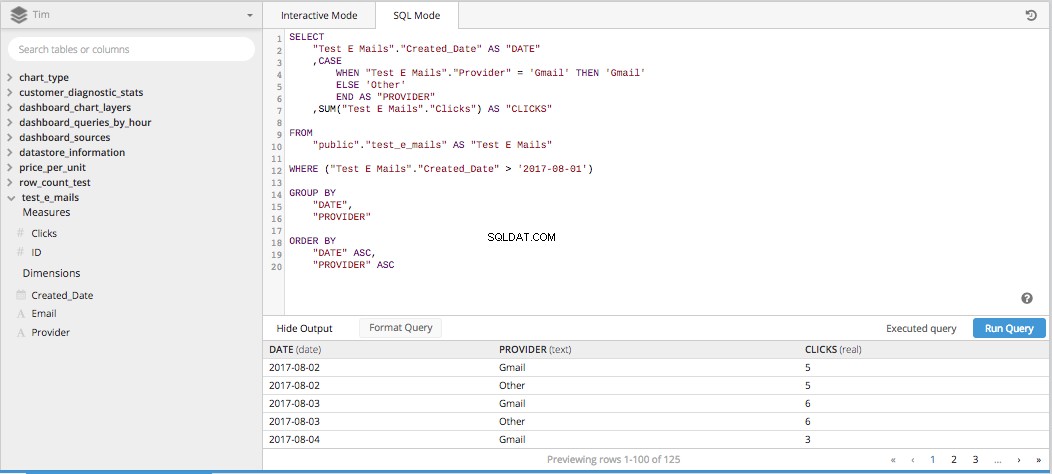
Então, depois de adicionar um
PIVOT DATA entrar no pipeline de dados, obteremos uma tabela devidamente organizada no formato adequado para configurar um gráfico de linhas mostrando como os cliques são comparados ao longo do tempo. 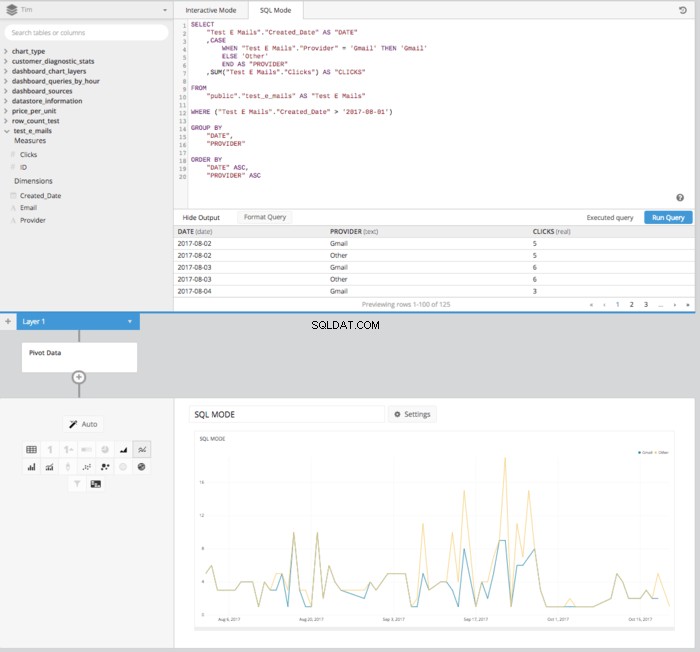
Ao usar o Chartio, podemos fazer tudo isso sem escrever nenhum SQL, mas aproveitando os recursos do Data Explorer e do Data Pipeline. Depois de construir nossa consulta subjacente para extrair todas as colunas, precisaremos de
SOMA DE CLIQUES , DATA e ENDEREÇO DE E-MAIL podemos usar o Data Pipeline para manipular esses dados pós-SQL. Primeiro, vamos construir a consulta. Arraste a "Coluna de cliques" para a caixa de medidas e agregue-a por
SOMA TOTAL dos cliques da coluna e, em seguida, rotule novamente como "CLICKS". 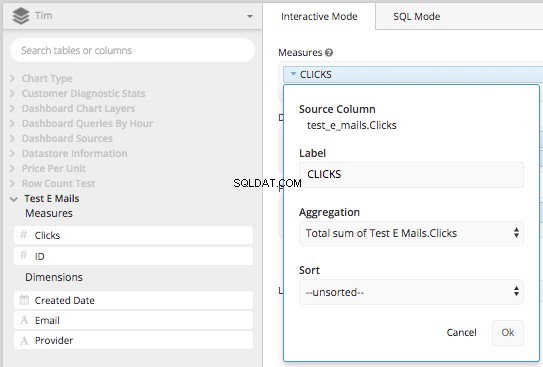
Em seguida, arraste 'Data de criação' e 'Provedor' para a caixa de dimensões e rotule-os novamente como 'Data' e 'Provedor de e-mail'.>ONDE cláusula) para ser tudo depois de 2017-08-01. Isso construirá efetivamente tudo o que precisamos em uma consulta subjacente para criar a
CASE STATEMENT fizemos acima, no Data Pipeline do Chartio. Adicionando uma
CASE STATEMENT etapa de pipeline nos permite definir as condições para o WHEN e o ELSE exatamente como fizemos antes, sem ter que digitar toda a sintaxe SQL. 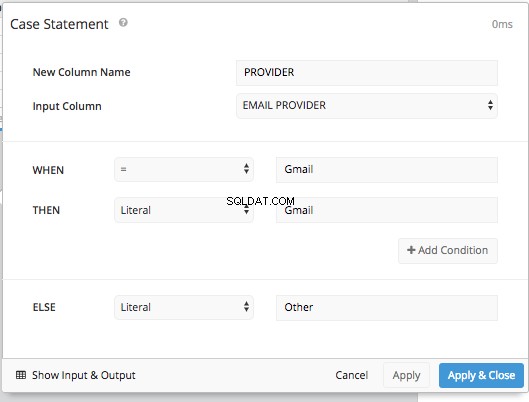
Então, depois de ocultar a coluna 'Provider' original e usar um
REORDER COLUMNS step e um PIVOT DATA passo, obteremos o mesmo arranjo de tabelas que obtivemos no modo SQL e podemos apresentar a mesma tabela que fizemos no modo SQL. 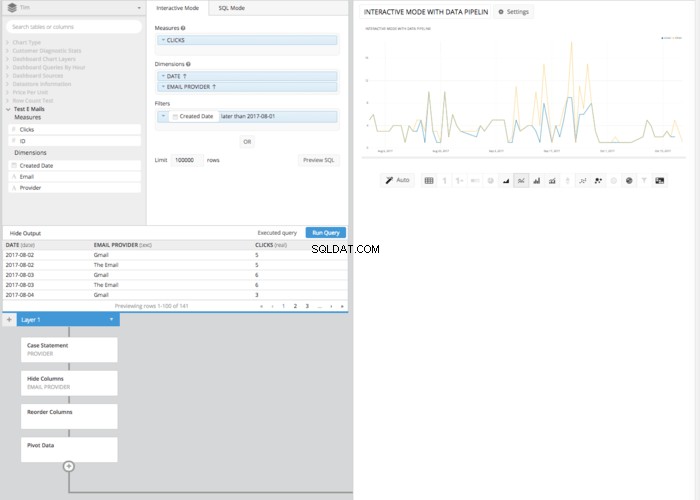
Embora possa levar alguns cliques e etapas a mais do que no modo SQL, o gráfico de linhas resultante feito no modo interativo não requer conhecimento de sintaxe SQL. Em vez disso, basta uma compreensão básica dos princípios envolvidos. Este é outro exemplo de como o Chartio está ajudando a colocar o poder dos dados nas mãos de todos, independentemente do conhecimento de SQL.