Este artigo é a sétima parte de uma série sobre expressões de tabelas nomeadas. Na Parte 5 e na Parte 6, abordei os aspectos conceituais das expressões de tabela comum (CTEs). Este mês e no próximo meu foco se volta para considerações de otimização de CTEs.
Começarei revisitando rapidamente o conceito de desaninhamento de expressões de tabelas nomeadas e demonstrarei sua aplicabilidade a CTEs. Em seguida, voltarei meu foco para considerações de persistência. Falarei sobre aspectos de persistência de CTEs recursivos e não recursivos. Vou explicar quando faz sentido manter CTEs versus quando realmente faz mais sentido trabalhar com tabelas temporárias.
Em meus exemplos, continuarei usando os bancos de dados de exemplo TSQLV5 e PerformanceV5. Você pode encontrar o script que cria e preenche o TSQLV5 aqui e seu diagrama ER aqui. Você pode encontrar o script que cria e preenche o PerformanceV5 aqui.
Substituição/desaninhamento
Na Parte 4 da série, que se concentrou na otimização de tabelas derivadas, descrevi um processo de desaninhamento/substituição de expressões de tabela. Expliquei que quando o SQL Server otimiza uma consulta envolvendo tabelas derivadas, ele aplica regras de transformação à árvore inicial de operadores lógicos produzidos pelo analisador, possivelmente deslocando as coisas entre o que eram originalmente os limites da expressão da tabela. Isso acontece a um ponto que, quando você compara um plano para uma consulta usando tabelas derivadas com um plano para uma consulta que vai diretamente contra as tabelas base subjacentes nas quais você mesmo aplicou a lógica de desaninhamento, eles têm a mesma aparência. Também descrevi uma técnica para evitar o desaninhamento usando o filtro TOP com um número muito grande de linhas como entrada. Demonstrei alguns casos em que essa técnica era bastante útil — um em que o objetivo era evitar erros e outro por motivos de otimização.
A versão TL;DR de substituição/desaninhamento de CTEs é que o processo é o mesmo que com tabelas derivadas. Se você estiver satisfeito com esta declaração, sinta-se à vontade para pular esta seção e pular direto para a próxima seção sobre Persistência. Você não perderá nada importante que não tenha lido antes. No entanto, se você é como eu, provavelmente quer uma prova de que esse é realmente o caso. Em seguida, você provavelmente desejará continuar lendo esta seção e testar o código que uso ao revisitar os principais exemplos de desaninhamento que demonstrei anteriormente com tabelas derivadas e convertê-los para usar CTEs.
Na Parte 4 demonstrei a seguinte consulta (chamaremos de Consulta 1):
USE TSQLV5; SELECT orderid, orderdate FROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101') AS D1 WHERE orderdate>='20180201') AS D2 WHERE orderdate>='20180301') AS D3 WHERE orderdate>='20180401';
A consulta envolve três níveis de aninhamento de tabelas derivadas, além de uma consulta externa. Cada nível filtra um intervalo diferente de datas de pedidos. O plano para a Consulta 1 é mostrado na Figura 1.
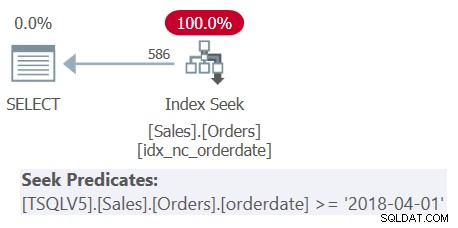 Figura 1:Plano de execução para a consulta 1
Figura 1:Plano de execução para a consulta 1 O plano na Figura 1 mostra claramente que ocorreu o desaninhamento das tabelas derivadas, pois todos os predicados de filtro foram mesclados em um único predicado de filtro abrangente.
Expliquei que você pode evitar o processo de desaninhamento usando um filtro TOP significativo (em oposição a TOP 100 PERCENT) com um número muito grande de linhas como entrada, como mostra a consulta a seguir (chamaremos de Consulta 2):
SELECT orderid, orderdate FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM Sales.Orders WHERE orderdate>='20180101') AS D1 WHERE 20180201' ) AS D2 WHERE orderdate>='20180301' ) AS D3 WHERE orderdate>='20180401';
O plano para a Consulta 2 é mostrado na Figura 2.
 Figura 2:Plano de execução para a consulta 2
Figura 2:Plano de execução para a consulta 2 O plano mostra claramente que o desaninhamento não ocorreu, pois você pode ver efetivamente os limites da tabela derivada.
Vamos tentar os mesmos exemplos usando CTEs. Aqui está a Consulta 1 convertida para usar CTEs:
WITH C1 AS ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ), C2 AS ( SELECT * FROM C1 WHERE orderdate>='20180201' ), C3 AS ( SELECT * FROM C2 WHERE orderdate>=' 20180301' ) SELECT orderid, orderdate FROM C3 WHERE orderdate>='20180401';
Você obtém exatamente o mesmo plano mostrado anteriormente na Figura 1, onde você pode ver que o desaninhamento ocorreu.
Aqui está a consulta 2 convertida para usar CTEs:
WITH C1 AS ( SELECT TOP (9223372036854775807) * FROM Sales.Orders WHERE orderdate>='20180101' ), C2 AS ( SELECT TOP (9223372036854775807) * FROM C1 WHERE orderdate>='20180201' ), C3 AS (SELECT TOP (9223372036854775807) * FROM C2 WHERE orderdate>='20180301' ) SELECT orderid, orderdate FROM C3 WHERE orderdate>='20180401';
Você obtém o mesmo plano mostrado anteriormente na Figura 2, onde pode ver que o desaninhamento não ocorreu.
Em seguida, vamos revisitar os dois exemplos que usei para demonstrar a praticidade da técnica para evitar o desaninhamento – só que desta vez usando CTEs.
Vamos começar com a consulta errada. A consulta a seguir tenta retornar linhas de pedido com um desconto maior que o desconto mínimo e onde a recíproca do desconto é maior que 10:
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE desconto> (SELECT MIN(desconto) FROM Sales.OrderDetails) AND 1,0 / desconto> 10,0;
O desconto mínimo não pode ser negativo, mas sim zero ou superior. Então, você provavelmente está pensando que se uma linha tem um desconto zero, o primeiro predicado deve ser avaliado como falso, e que um curto-circuito deve impedir a tentativa de avaliar o segundo predicado, evitando assim um erro. No entanto, quando você executa este código, obtém um erro de divisão por zero:
Msg 8134, Level 16, State 1, Line 99 Erro de divisão por zero encontrado.
O problema é que, embora o SQL Server dê suporte a um conceito de curto-circuito no nível de processamento físico, não há garantia de que ele avaliará os predicados de filtro em ordem escrita da esquerda para a direita. Uma tentativa comum de evitar esses erros é usar uma expressão de tabela nomeada que trata a parte da lógica de filtragem que você deseja que seja avaliada primeiro e fazer com que a consulta externa trate da lógica de filtragem que você deseja que seja avaliada em segundo lugar. Aqui está a solução tentada usando um CTE:
WITH C AS ( SELECT * FROM Sales.OrderDetails WHERE desconto> (SELECT MIN(desconto) FROM Sales.OrderDetails) ) SELECT orderid, productid, discount FROM C WHERE 1.0 / discount> 10.0;
Infelizmente, porém, o desaninhamento da expressão de tabela resulta em um equivalente lógico à consulta de solução original e, quando você tenta executar esse código, obtém um erro de divisão por zero novamente:
Msg 8134, Level 16, State 1, Line 108 Erro de divisão por zero encontrado.
Usando nosso truque com o filtro TOP na consulta interna, você evita o desaninhamento da expressão da tabela, assim:
WITH C AS ( SELECT TOP (9223372036854775807) * FROM Sales.OrderDetails WHERE desconto> (SELECT MIN(desconto) FROM Sales.OrderDetails) ) SELECT orderid, productid, discount FROM C WHERE 1.0 / discount> 10.0;
Desta vez, o código é executado com sucesso sem erros.
Vamos prosseguir para o exemplo em que você usa a técnica para evitar o desaninhamento por motivos de otimização. O código a seguir retorna apenas remetentes com uma data máxima de pedido em ou após 1º de janeiro de 2018:
USE PerformanceV5; WITH C AS ( SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) SELECT shipperid, maxod FROM C WHERE maxod> ='20180101';
Se você está se perguntando por que não usar uma solução muito mais simples com uma consulta agrupada e um filtro HAVING, isso tem a ver com a densidade da coluna shipperid. A tabela Pedidos tem 1.000.000 de pedidos, e os envios desses pedidos foram atendidos por cinco remetentes, o que significa que, em média, cada remetente atendeu 20% dos pedidos. O plano para uma consulta agrupada computando a data máxima do pedido por remetente examinaria todas as 1.000.000 linhas, resultando em milhares de leituras de página. De fato, se você destacar apenas a consulta interna do CTE (chamaremos de Consulta 3) computando a data máxima do pedido por remetente e verificar seu plano de execução, você obterá o plano mostrado na Figura 3.
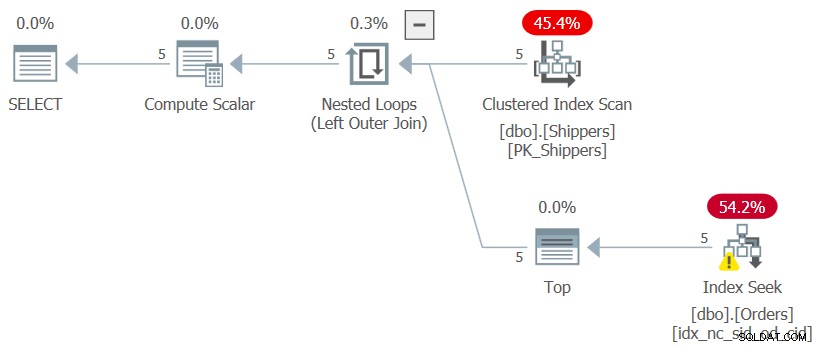 Figura 3:Plano de execução para a consulta 3
Figura 3:Plano de execução para a consulta 3 O plano verifica cinco linhas no índice clusterizado em Transportadores. Por remetente, o plano aplica uma busca em um índice de cobertura em Pedidos, onde (shipperid, orderdate) são as chaves principais do índice, indo direto para a última linha em cada seção do remetente no nível da folha para extrair a data máxima do pedido para o atual remetente. Como temos apenas cinco embarcadores, existem apenas cinco operações de index seek, resultando em um plano muito eficiente. Aqui estão as medidas de desempenho que obtive quando executei a consulta interna do CTE:
duração:0 ms, CPU:0 ms, leituras:15
No entanto, quando você executa a solução completa (chamaremos de Consulta 4), você obtém um plano completamente diferente, conforme mostrado na Figura 4.
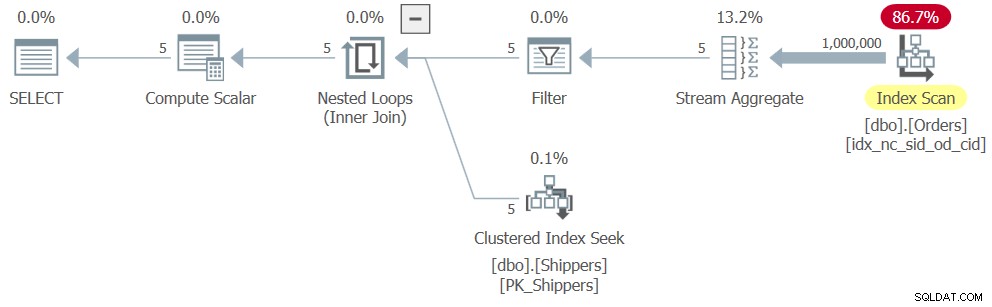 Figura 4:Plano de execução para a consulta 4
Figura 4:Plano de execução para a consulta 4 O que aconteceu é que o SQL Server desaninha a expressão da tabela, convertendo a solução em um equivalente lógico de uma consulta agrupada, resultando em uma verificação completa do índice em Pedidos. Aqui estão os números de desempenho que obtive para esta solução:
duração:316 ms, CPU:281 ms, leituras:3854
O que precisamos aqui é impedir que ocorra o desaninhamento da expressão de tabela, para que a consulta interna seja otimizada com buscas no índice em Pedidos e para que a consulta externa resulte apenas na adição de um operador Filtro no plano. Você consegue isso usando nosso truque adicionando um filtro TOP à consulta interna, assim (chamaremos essa solução de Consulta 5):
WITH C AS ( SELECT TOP (9223372036854775807) S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) SELECT shipperid , maxod FROM C WHERE maxod>='20180101';
O plano para esta solução é mostrado na Figura 5.
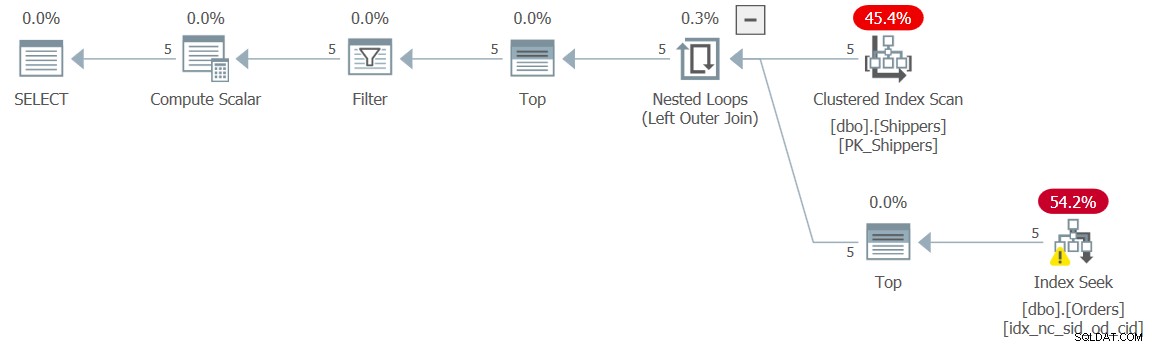 Figura 5:Plano de execução para a consulta 5
Figura 5:Plano de execução para a consulta 5 O plano mostra que o efeito desejado foi alcançado e, portanto, os números de desempenho confirmam isso:
duração:0 ms, CPU:0 ms, leituras:15
Portanto, nossos testes confirmam que o SQL Server trata a substituição/desaninhamento de CTEs da mesma forma que faz para tabelas derivadas. Isso significa que você não deve preferir um ao outro por motivos de otimização, mas sim por diferenças conceituais que são importantes para você, conforme discutido na Parte 5.
Persistência
Um equívoco comum sobre CTEs e expressões de tabelas nomeadas em geral é que elas servem como algum tipo de veículo de persistência. Alguns pensam que o SQL Server mantém o conjunto de resultados da consulta interna em uma tabela de trabalho e que a consulta externa realmente interage com essa tabela de trabalho. Na prática, CTEs não recursivos regulares e tabelas derivadas não são persistentes. Descrevi a lógica de desaninhamento que o SQL Server aplica ao otimizar uma consulta envolvendo expressões de tabela, resultando em um plano que interage diretamente com as tabelas base subjacentes. Observe que o otimizador pode optar por usar tabelas de trabalho para persistir conjuntos de resultados intermediários se fizer sentido fazê-lo por motivos de desempenho ou outros, como proteção de Halloween. Ao fazer isso, você verá os operadores Spool ou Index Spool no plano. No entanto, essas escolhas não estão relacionadas ao uso de expressões de tabela na consulta.
CTEs recursivos
Existem algumas exceções nas quais o SQL Server persiste os dados da expressão de tabela. Uma delas é o uso de exibições indexadas. Se você criar um índice clusterizado em uma exibição, o SQL Server persistirá o conjunto de resultados da consulta interna no índice clusterizado da exibição e o manterá sincronizado com quaisquer alterações nas tabelas base subjacentes. A outra exceção é quando você usa consultas recursivas. O SQL Server precisa persistir os conjuntos de resultados intermediários das consultas âncora e recursivas em um spool para que ele possa acessar o conjunto de resultados da última rodada representado pela referência recursiva ao nome CTE toda vez que o membro recursivo for executado.
Para demonstrar isso, usarei uma das consultas recursivas da Parte 6 da série.
Use o código a seguir para criar a tabela Employees no banco de dados tempdb, preenchê-la com dados de exemplo e criar um índice de suporte:
SET NOCOUNT ON; USE tempdb; DROP TABLE SE EXISTE dbo.Employees; GO CREATE TABLE dbo.Employees ( empid INT NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, mgrid INT NULL CONSTRAINT FK_Employees_Employees REFERENCES dbo.Employees, empname VARCHAR(25) NOT NULL, salário MONEY NOT NULL, CHECK (empid <> mgrid) ); INSERT INTO dbo.Employees(empid, mgrid, empname, salário) VALUES(1, NULL, 'David' , $10000.00), (2, 1, 'Eitan' , $7000.00), (3, 1, 'Ina' , $7500.00) , (4, 2, 'Seraph' , $ 5.000,00), (5, 2, 'Jiru' , $ 5.500,00), (6, 2, 'Steve' , $4.500,00), (7, 3, 'Aaron', $5.000,00), ( 8, 5, 'Lilach' , $3.500,00), (9, 7, 'Rita', $3.000,00), (10, 5, 'Sean', $3.000,00), (11, 7, 'Gabriel', $3.000,00), (12, 9, 'Emilia' , $ 2.000,00), (13, 9, 'Michael', $ 2.000,00), (14, 9, 'Didi', $ 1.500,00); CRIAR ÍNDICE ÚNICO idx_unc_mgrid_empid ON dbo.Employees(mgrid, empid) INCLUDE(empname, salario); IR
Eu usei o seguinte CTE recursivo para retornar todos os subordinados de um gerenciador raiz de subárvore de entrada, usando o funcionário 3 como o gerenciador de entrada neste exemplo:
DECLARE @root AS INT =3; WITH C AS ( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid ) SELECT empid, mgrid, empname FROM C;
O plano para esta consulta (chamaremos de Consulta 6) é mostrado na Figura 6.
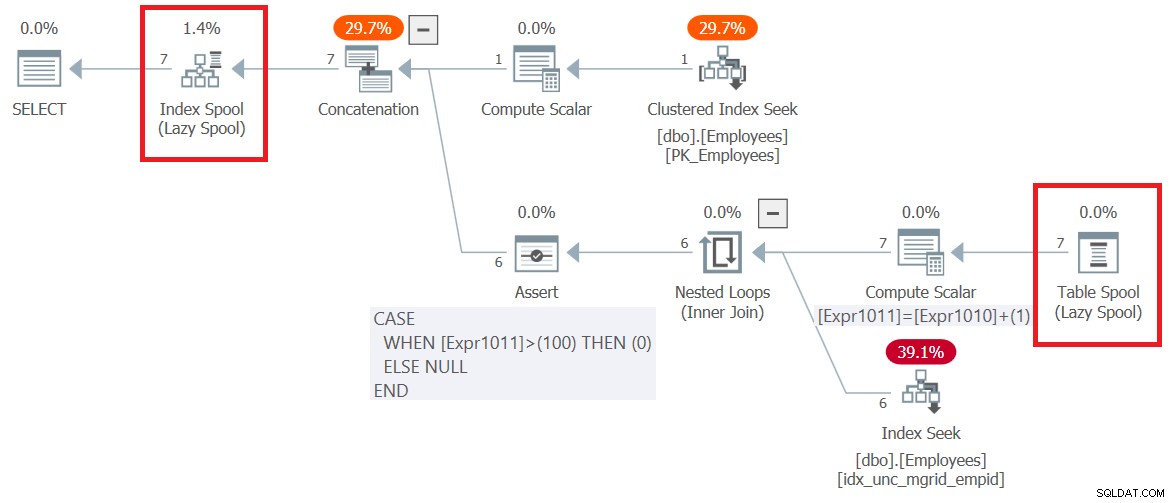 Figura 6:Plano de execução para a consulta 6
Figura 6:Plano de execução para a consulta 6 Observe que a primeira coisa que acontece no plano, à direita do nó raiz SELECT, é a criação de uma tabela de trabalho baseada em árvore B representada pelo operador Index Spool. A parte superior do plano lida com a lógica do membro âncora. Ele extrai as linhas de entrada do funcionário do índice clusterizado em Funcionários e as grava no spool. A parte inferior do plano representa a lógica do membro recursivo. Ele é executado repetidamente até retornar um conjunto de resultados vazio. A entrada externa para o operador Nested Loops obtém os gerenciadores da rodada anterior do spool (operador Table Spool). A entrada interna usa um operador Index Seek contra um índice não clusterizado criado em Employees(mgrid, empid) para obter os subordinados diretos dos gerentes da rodada anterior. O conjunto de resultados de cada execução da parte inferior do plano também é gravado no spool de índice. Observe que, ao todo, 7 linhas foram gravadas no carretel. Um retornado pelo membro âncora e mais 6 retornados por todas as execuções do membro recursivo.
Como aparte, é interessante notar como o plano trata o limite de maxrecursion padrão, que é 100. Observe que o operador Compute Scalar inferior continua aumentando um contador interno chamado Expr1011 em 1 a cada execução do membro recursivo. Em seguida, o operador Assert define um sinalizador como zero se esse contador exceder 100. Se isso acontecer, o SQL Server interrompe a execução da consulta e gera um erro.
Quando não persistir
De volta aos CTEs não recursivos, que normalmente não são persistidos, cabe a você descobrir, de uma perspectiva de otimização, quando é uma boa coisa usá-los versus ferramentas de persistência reais, como tabelas temporárias e variáveis de tabela. Vou passar por alguns exemplos para demonstrar quando cada abordagem é mais ideal.
Vamos começar com um exemplo em que CTEs se saem melhor do que tabelas temporárias. Esse é geralmente o caso quando você não tem várias avaliações do mesmo CTE, em vez disso, talvez apenas uma solução modular em que cada CTE é avaliada apenas uma vez. O código a seguir (chamaremos de Query 7) consulta a tabela Orders no banco de dados Performance, que tem 1.000.000 linhas, para retornar anos de pedidos em que mais de 70 clientes distintos fizeram pedidos:
USE PerformanceV5; WITH C1 AS ( SELECT YEAR(orderdate) AS orderyear, custid FROM dbo.Orders ), C2 AS ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts FROM C1 GROUP BY orderyear ) SELECT orderyear, numcusts FROM C2 WHERE numcusts> 70;
Essa consulta gera a seguinte saída:
números de pedidos por ano ----------- ----------- 2015 992 2017 20000 2018 20000 2019 20000 2016 20000
Executei este código usando o SQL Server 2019 Developer Edition e obtive o plano mostrado na Figura 7.
Figura 7:Plano de execução para a consulta 7
Observe que o desaninhamento do CTE resultou em um plano que extrai os dados de um índice na tabela Pedidos e não envolve nenhum spool do conjunto de resultados da consulta interna do CTE. Obtive os seguintes números de desempenho ao executar esta consulta na minha máquina:
duração:265 ms, CPU:828 ms, leituras:3970, gravações:0
Agora vamos tentar uma solução que usa tabelas temporárias em vez de CTEs (chamaremos de Solução 8), assim:
SELECT YEAR(orderdate) AS orderyear, custid INTO #T1 FROM dbo.Orders; SELECT ano do pedido, COUNT(custid DISTINTO) AS numcusts INTO #T2 FROM #T1 GROUP BY ano do pedido; SELECT pedidoano, numcusts FROM #T2 WHERE numcusts> 70; SOLTAR TABELA #T1, #T2;
Os planos para esta solução são mostrados na Figura 8.
Figura 8:planos para a solução 8
Observe os operadores Table Insert gravando os conjuntos de resultados nas tabelas temporárias #T1 e #T2. O primeiro é especialmente caro, pois grava 1.000.000 de linhas em #T1. Aqui estão os números de desempenho que obtive para esta execução:
duração:454 ms, CPU:1517 ms, leituras:14359, gravações:359
Como você pode ver, a solução com os CTEs é muito mais ideal.
Quando persistir
Então, é sempre preferível uma solução modular que envolve apenas uma avaliação de cada CTE em vez de usar tabelas temporárias? Não necessariamente. Em soluções baseadas em CTE que envolvem muitas etapas e resultam em planos elaborados em que o otimizador precisa aplicar muitas estimativas de cardinalidade em muitos pontos diferentes do plano, você pode acabar com imprecisões acumuladas que resultam em escolhas abaixo do ideal. Uma das técnicas para tentar lidar com esses casos é persistir alguns conjuntos de resultados intermediários em tabelas temporárias e até mesmo criar índices nelas, se necessário, dando ao otimizador um novo começo com novas estatísticas, aumentando a probabilidade de estimativas de cardinalidade de melhor qualidade que esperamos levar a escolhas mais ideais. Se isso é melhor do que uma solução que não usa tabelas temporárias é algo que você precisará testar. Às vezes, a compensação de custo extra para persistir conjuntos de resultados intermediários para obter estimativas de cardinalidade de melhor qualidade valerá a pena.
Outro caso típico em que o uso de tabelas temporárias é a abordagem preferida é quando a solução baseada em CTE tem várias avaliações do mesmo CTE, e a consulta interna do CTE é bastante cara. Considere a seguinte solução baseada em CTE (chamaremos de Consulta 9), que corresponde a cada ano e mês de pedido um ano e mês de pedido diferente que tenha a contagem de pedidos mais próxima:
WITH OrdCount AS ( SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth, COUNT(*) AS numorders FROM dbo.Orders GROUP BY YEAR(orderdate), MONTH(orderdate) ) SELECT O1.orderyear, O1 .ordermonth, O1.numorders, O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2, O2.numorders AS numorders2 FROM OrdCount AS O1 CROSS APPLY (SELECT TOP (1) O2.orderyear, O2.ordermonth, O2.numorders FROM OrdCount AS O2 ONDE O2.orderyear <> O1.orderyear OR O2.ordermonth <> O1.ordermonth ORDER BY ABS(O1.numorders - O2.numorders), O2.orderyear, O2.ordermonth ) AS O2;
Essa consulta gera a seguinte saída:
pedidoano pedidomês números pedidosano2 pedidomês2 números2 ----------- ----------- ----------- -------- --- ----------- ----------- 2016 1 21262 2017 3 21267 2019 1 21227 2016 5 21229 2019 2 19145 2018 2 19125 2018 4 20561 2016 9 20554 2018 5 21209 2019 5 21210 2018 6 20515 2016 11 20513 2018 7 21194 2018 10 21197 2017 9 20542 2017 11 20539 2017 10 21234 2019 3 21235 2017 11 20539 2019 4 20537 2017 12 21183 2016 8 21185 2018 1 21241 2019 7 21238 2016 2 19844 2019 12 20184 2018 3 21222 2016 10 21222 2016 4 20526 2019 9 20527 2019 4 20537 2017 11 20539 2017 5 21203 2017 8 21199 2019 6 20531 2019 9 20527 2017 7 21217 2016 7 21218 2018 8 21283 2017 3 21267 2018 10 21197 2017 8 21199 2016 11 20513 2018 6 20515 2019 11 20494 2017 4 20498 2018 0 6 3 21211 2017 6 20551 2016 9 20554 2017 8 21199 2018 10 21197 2018 9 20487 2019 11 20494 2016 10 21222 2018 3 21222 2018 11 20575 2016 6 20571 2016 12 21212 3121211 2019 12 20184 2018 920202020202020202017 212222 2017 2 19174 2019 2 19145 2017 3 21267 2016 1 21262 2017 4 20498 2019 11 20494 2016 2017 12 21183 2019 8 21189 2016 8 21185 2016 9 20554 2017 6 20551 2019 9 20527 2016 4 20526 2019 10 21254 2016 1 21262 2015 12 1018 2018 2 19125 2018 12 2125 2017 1 21223 (49 Rosteu
O plano para a Consulta 9 é mostrado na Figura 9.
Figura 9:Plano de execução para a consulta 9
A parte superior do plano corresponde à instância do OrdCount CTE que tem o alias O1. Essa referência resulta em uma avaliação do CTE OrdCount. Essa parte do plano extrai as linhas de um índice na tabela Pedidos, agrupa-as por ano e mês e agrega a contagem de pedidos por grupo, resultando em 49 linhas. A parte inferior do plano corresponde à tabela derivada correlacionada O2, que é aplicada por linha de O1, portanto, é executada 49 vezes. Cada execução consulta o OrdCount CTE e, portanto, resulta em uma avaliação separada da consulta interna do CTE. Você pode ver que a parte inferior do plano verifica todas as linhas do índice em Pedidos, agrupa e os agrega. Você basicamente obtém um total de 50 avaliações do CTE, resultando em 50 varreduras de 1.000.000 de linhas de Pedidos, agrupando-as e agregando-as. Não parece uma solução muito eficiente. Aqui estão as medidas de desempenho que obtive ao executar esta solução na minha máquina:
duração:16 segundos, CPU:56 segundos, leituras:130404, gravações:0
Dado que há apenas algumas dezenas de meses envolvidos, o que seria muito mais eficiente é usar uma tabela temporária para armazenar o resultado de uma única atividade que agrupa e agrega as linhas de Orders e, em seguida, tem as entradas externas e internas de o operador APPLY interage com a tabela temporária. Aqui está a solução (vamos chamá-la de Solução 10) usando uma tabela temporária em vez do CTE:
SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth, COUNT(*) AS numorders INTO #OrdCount FROM dbo.Orders GROUP BY YEAR(orderdate), MONTH(orderdate); SELECT O1.orderyear, O1.ordermonth, O1.numorders, O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2, O2.numorders AS numorders2 FROM #OrdCount AS O1 CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth , O2.numorders FROM #OrdCount AS O2 ONDE O2.orderyear <> O1.orderyear OR O2.ordermonth <> O1.ordermonth <> O1.ordermonth ORDER BY ABS(O1.numorders - O2.numorders), O2.orderyear, O2.ordermonth ) AS O2; DROP TABLE #OrdCount;
Aqui não há muito sentido em indexar a tabela temporária, já que o filtro TOP é baseado em um cálculo em sua especificação de ordenação e, portanto, uma classificação é inevitável. No entanto, pode ser que em outros casos, com outras soluções, também seja relevante considerar a indexação de suas tabelas temporárias. De qualquer forma, o plano para esta solução é mostrado na Figura 10.
Figura 10:Planos de execução para a Solução 10
Observe no plano superior como o trabalho pesado envolvendo a varredura de 1.000.000 de linhas, agrupando-as e agregando-as, acontece apenas uma vez. 49 linhas são gravadas na tabela temporária #OrdCount e, em seguida, o plano inferior interage com a tabela temporária para as entradas externas e internas do operador Nested Loops, que manipula a lógica do operador APPLY.
Aqui estão os números de desempenho que obtive para a execução desta solução:
duração:0,392 segundos, CPU:0,5 segundos, leituras:3636, gravações:3
É mais rápido em ordens de magnitude do que a solução baseada em CTE.
O que vem a seguir?
Neste artigo, iniciei a cobertura das considerações de otimização relacionadas a CTEs. Mostrei que o processo de desaninhamento/substituição que ocorre com tabelas derivadas funciona da mesma forma com CTEs. Também discuti o fato de que CTEs não recursivas não são persistentes e expliquei que quando a persistência é um fator importante para o desempenho de sua solução, você precisa lidar com isso usando ferramentas como tabelas temporárias e variáveis de tabela. No próximo mês, continuarei a discussão abordando aspectos adicionais da otimização de CTE.