Acho que todo mundo já conhece minhas opiniões sobre
MERGE e por que eu fico longe disso. Mas aqui está outro (anti-) padrão que vejo em todo lugar quando as pessoas querem executar um upsert (atualizar uma linha se existir e inseri-la se não existir):IF EXISTS (SELECT 1 FROM dbo.t WHERE [key] = @key) BEGIN UPDATE dbo.t SET val = @val WHERE [key] = @key; END ELSE BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END
Isso parece um fluxo bastante lógico que reflete como pensamos sobre isso na vida real:
- Já existe uma linha para esta chave?
- SIM :OK, atualize essa linha.
- NÃO :OK, adicione-o.
Mas isso é um desperdício.
Localizar a linha para confirmar que ela existe, apenas para ter que localizá-la novamente para atualizá-la, está fazendo duas vezes o trabalho por nada. Mesmo que a chave seja indexada (o que espero que seja sempre o caso). Se eu colocar essa lógica em um fluxograma e associar, a cada passo, o tipo de operação que teria que acontecer dentro do banco de dados, eu teria isso:
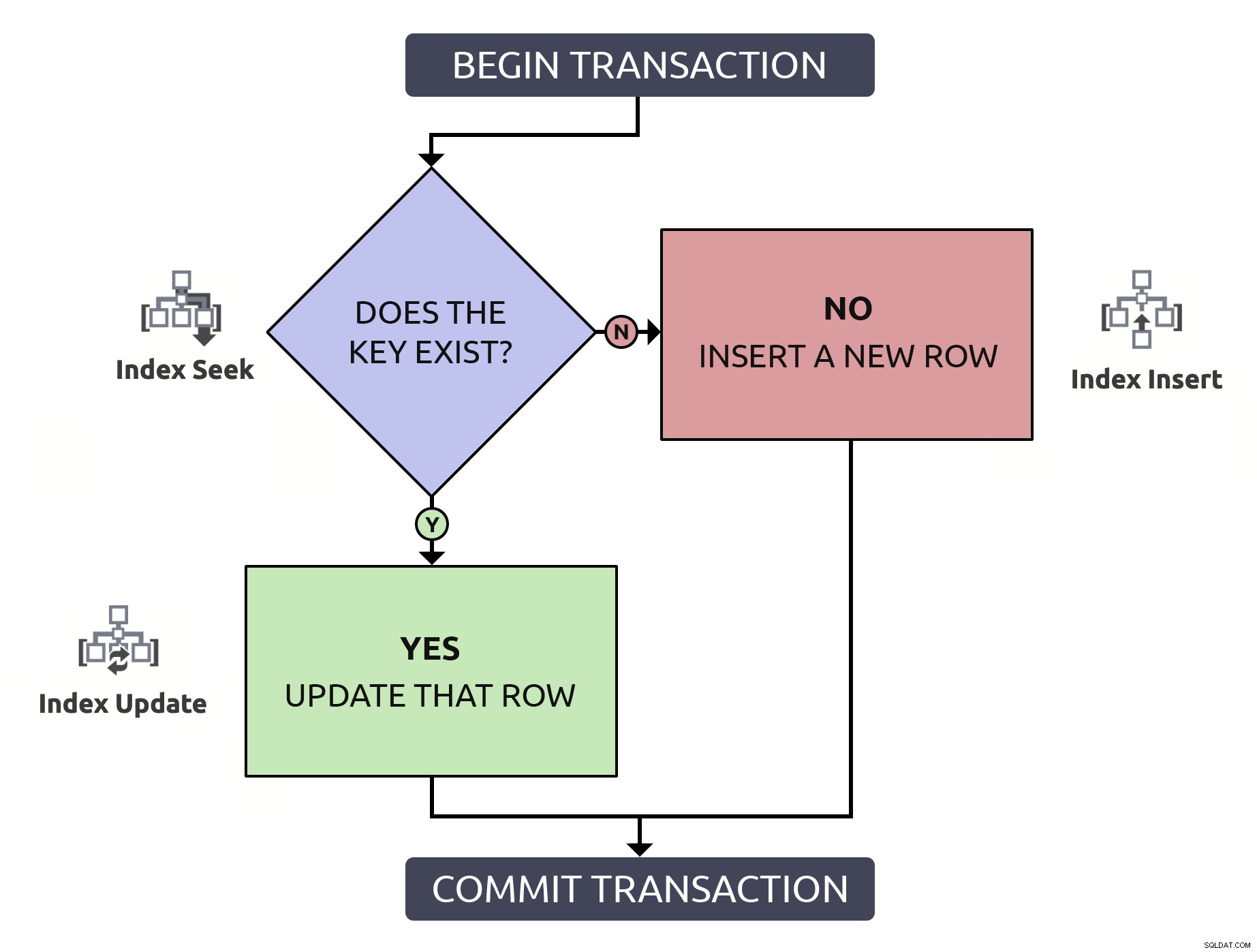 Observe que todos os caminhos incorrerão em duas operações de índice.
Observe que todos os caminhos incorrerão em duas operações de índice. Mais importante, além do desempenho, a menos que você use uma transação explícita e eleve o nível de isolamento, várias coisas podem dar errado quando a linha ainda não existe:
- Se a chave existir e duas sessões tentarem atualizar simultaneamente, elas ambas serão atualizadas com sucesso (um vai "ganhar"; o "perdedor" seguirá com a mudança que fica, levando a uma "atualização perdida"). Isso não é um problema por si só, e é assim que devemos esperar que um sistema com simultaneidade funcione. Paul White fala sobre a mecânica interna com mais detalhes aqui, e Martin Smith fala sobre algumas outras nuances aqui.
- Se a chave não existir, mas ambas as sessões passarem na verificação de existência da mesma forma, tudo pode acontecer quando ambas tentarem inserir:
- bloqueio devido a bloqueios incompatíveis;
- gerar erros de violação de chave isso não deveria ter acontecido; ou,
- inserir valores de chave duplicados se essa coluna não estiver adequadamente restrita.
Esse último é o pior, IMHO, porque é o que potencialmente corrompe dados . Deadlocks e exceções podem ser tratados facilmente com coisas como tratamento de erros,
XACT_ABORT e tente novamente a lógica, dependendo da frequência com que você espera colisões. Mas se você se sentir seguro de que o IF EXISTS check protege você de duplicatas (ou violações de chave), que é uma surpresa esperando para acontecer. Se você espera que uma coluna funcione como uma chave, torne-a oficial e adicione uma restrição. "Muitas pessoas estão dizendo..."
Dan Guzman falou sobre condições de corrida há mais de uma década em Conditional INSERT/UPDATE Race Condition e mais tarde em "UPSERT" Race Condition With MERGE.
Michael Swart também tratou desse assunto várias vezes:
- Remoção de mitos:soluções de atualização/inserção simultâneas – onde ele reconheceu que deixar a lógica inicial em vigor e apenas elevar o nível de isolamento apenas alterava as violações de chave para impasses;
- Tenha cuidado com a declaração de mesclagem - onde ele verificou seu entusiasmo sobre
MERGE; e, - O que evitar se você quiser usar MERGE – onde ele confirmou mais uma vez que ainda existem muitas razões válidas para continuar evitando
MERGE.
Certifique-se de ler todos os comentários em todas as três postagens também.
A solução
Corrigi muitos deadlocks em minha carreira simplesmente ajustando o seguinte padrão (abandone a verificação redundante, envolva a sequência em uma transação e proteja o primeiro acesso à tabela com o bloqueio apropriado):
BEGIN TRANSACTION; UPDATE dbo.t WITH (UPDLOCK, SERIALIZABLE) SET val = @val WHERE [key] = @key; IF @@ROWCOUNT = 0 BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END COMMIT TRANSACTION;
Por que precisamos de duas dicas? Não é
UPDLOCK suficiente? UPDLOCKé usado para proteger contra impasses de conversão na instrução nível (deixe outra sessão esperar em vez de encorajar a vítima a tentar novamente).SERIALIZABLEé usado para proteger contra alterações nos dados subjacentes em toda a transação (garantir que uma linha que não existe continue a não existir).
É um pouco mais de código, mas é 1000% mais seguro, e mesmo nos piores case (a linha ainda não existe), ele executa o mesmo que o antipadrão. Na melhor das hipóteses, se você estiver atualizando uma linha que já existe, será mais eficiente localizar essa linha apenas uma vez. Combinando essa lógica com as operações de alto nível que teriam que acontecer no banco de dados, é um pouco mais simples:
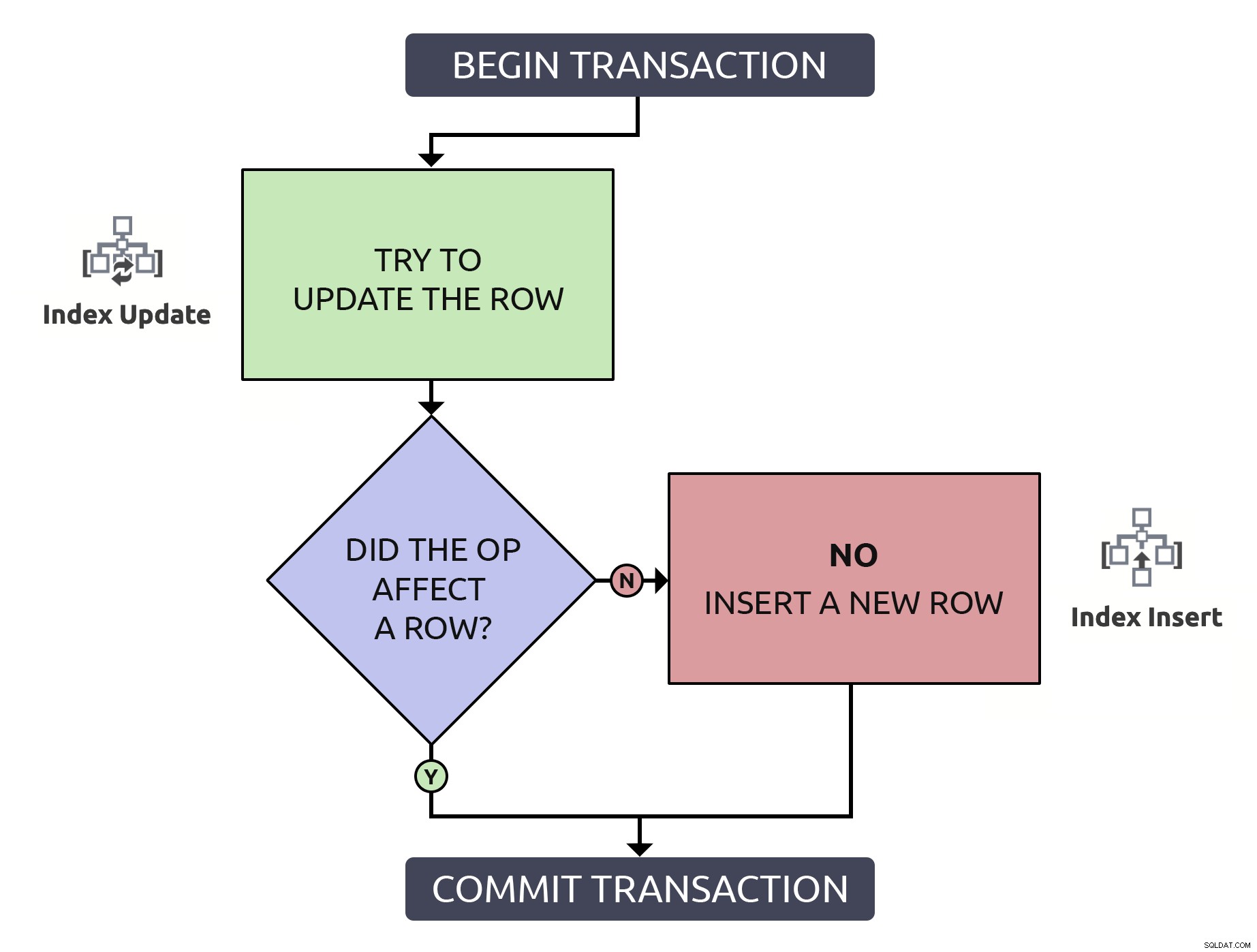 Neste caso, um caminho incorre apenas em uma única operação de índice.
Neste caso, um caminho incorre apenas em uma única operação de índice. Mas, novamente, desempenho de lado:
- Se a chave existir e duas sessões tentarem atualizá-la ao mesmo tempo, elas se revezarão e atualizarão a linha com sucesso , como antes.
- Se a chave não existir, uma sessão "vencerá" e inserirá a linha . O outro terá que esperar até que os bloqueios sejam liberados para verificar a existência e serem forçados a atualizar.
Em ambos os casos, o escritor que ganhou a corrida perde seus dados para qualquer coisa que o "perdedor" atualizou depois deles.
Observe que a taxa de transferência geral em um sistema altamente simultâneo pode sofrer, mas essa é uma troca que você deve estar disposto a fazer. Que você está recebendo muitas vítimas de deadlock ou erros de violação de chave, mas eles estão acontecendo rapidamente, não é uma boa métrica de desempenho. Algumas pessoas adorariam ver todos os bloqueios removidos de todos os cenários, mas alguns deles estão bloqueando o que você absolutamente deseja para a integridade dos dados.
Mas e se uma atualização for menos provável?
É claro que a solução acima otimiza para atualizações e pressupõe que uma chave na qual você está tentando gravar já existirá na tabela com a mesma frequência que não existe. Se você preferir otimizar para inserções, sabendo ou adivinhando que as inserções serão mais prováveis do que as atualizações, você pode inverter a lógica e ainda ter uma operação de upsert segura:
BEGIN TRANSACTION;
INSERT dbo.t([key], val)
SELECT @key, @val
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.t WITH (UPDLOCK, SERIALIZABLE)
WHERE [key] = @key
);
IF @@ROWCOUNT = 0
BEGIN
UPDATE dbo.t SET val = @val WHERE [key] = @key;
END
COMMIT TRANSACTION; Há também a abordagem "just do it", onde você insere cegamente e permite que as colisões gerem exceções para o chamador:
BEGIN TRANSACTION; BEGIN TRY INSERT dbo.t([key], val) VALUES(@key, @val); END TRY BEGIN CATCH UPDATE dbo.t SET val = @val WHERE [key] = @key; END CATCH COMMIT TRANSACTION;
O custo dessas exceções geralmente supera o custo de verificar primeiro; você terá que experimentá-lo com um palpite mais ou menos preciso da taxa de acertos/erros. Escrevi sobre isso aqui e aqui.
E o upser de várias linhas?
O acima lida com decisões de inserção/atualização de singleton, mas Justin Pealing perguntou o que fazer quando você está processando várias linhas sem saber qual delas já existe?
Supondo que você esteja enviando um conjunto de linhas usando algo como um parâmetro com valor de tabela, você atualizaria usando uma junção e inseriria usando NOT EXISTS, mas o padrão ainda seria equivalente à primeira abordagem acima:
CREATE PROCEDURE dbo.UpsertTheThings
@tvp dbo.TableType READONLY
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE t WITH (UPDLOCK, SERIALIZABLE)
SET val = tvp.val
FROM dbo.t AS t
INNER JOIN @tvp AS tvp
ON t.[key] = tvp.[key];
INSERT dbo.t([key], val)
SELECT [key], val FROM @tvp AS tvp
WHERE NOT EXISTS (SELECT 1 FROM dbo.t WHERE [key] = tvp.[key]);
COMMIT TRANSACTION;
END Se você estiver juntando várias linhas de alguma outra maneira que não seja um TVP (XML, lista separada por vírgulas, vodu), coloque-as em um formulário de tabela primeiro e junte-as ao que quer que seja. Tenha cuidado para não otimizar primeiro para inserções neste cenário, caso contrário, você potencialmente atualizará algumas linhas duas vezes.
Conclusão
Esses padrões de upsert são superiores aos que vejo com muita frequência, e espero que você comece a usá-los. Vou apontar para este post toda vez que encontrar o
IF EXISTS padrão em estado selvagem. E, ei, outro salve para Paul White (sql.kiwi | @SQK_Kiwi), porque ele é excelente em tornar conceitos difíceis fáceis de entender e, por sua vez, explicar. E se você achar que precisa use
MERGE , por favor, não me @; ou você tem um bom motivo (talvez você precise de algum MERGE obscuro -somente funcionalidade), ou você não levou os links acima a sério.