Na primeira parte deste blog, abordamos um passo a passo de implantação do MySQL InnoDB Cluster com um exemplo de como os aplicativos podem se conectar ao cluster por meio de uma porta dedicada de leitura/gravação.
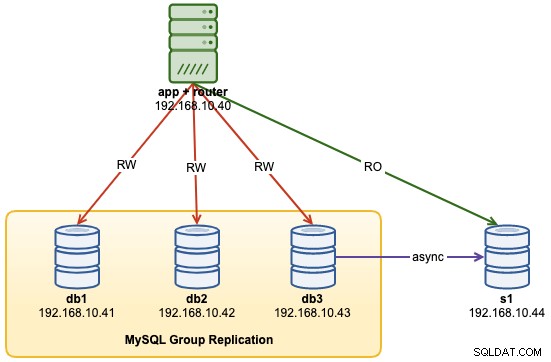
Neste passo a passo da operação, mostraremos exemplos de como monitorar, gerenciar e dimensionar o InnoDB Cluster como parte das operações contínuas de manutenção do cluster. Usaremos o mesmo cluster que implantamos na primeira parte do blog. O diagrama a seguir mostra nossa arquitetura:
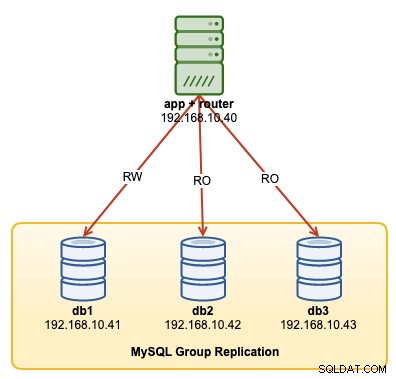
Temos uma Replicação de Grupo MySQL de três nós e um servidor de aplicativos rodando com roteador MySQL. Todos os servidores estão rodando no Ubuntu 18.04 Bionic.
Opções de comando de cluster MySQL InnoDB
Antes de prosseguirmos com alguns exemplos e explicações, é bom saber que você pode obter uma explicação de cada função no cluster MySQL para o componente de cluster usando a função help(), conforme mostrado abaixo:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.help()A lista a seguir mostra as funções disponíveis no MySQL Shell 8.0.18, para MySQL Community Server 8.0.18:
- addInstance(instance[, options])- Adiciona uma instância ao cluster.
- checkInstanceState(instance)- verifica o estado gtid da instância em relação ao cluster.
- describe()- Descreva a estrutura do cluster.
- disconnect()- Desconecta todas as sessões internas usadas pelo objeto de cluster.
- dissolve([options])- Desativa a replicação e cancela o registro dos ReplicaSets do cluster.
- forceQuorumUsingPartitionOf(instance[, password])- Restaura o cluster da perda de quorum.
- getName()- Recupera o nome do cluster.
- help([member])- Fornece ajuda sobre esta turma e seus membros
- options([options])- Lista as opções de configuração do cluster.
- rejoinInstance(instance[, options])- reintegra uma instância ao cluster.
- removeInstance(instance[, options])- remove uma instância do cluster.
- rescan([options])- examina novamente o cluster.
- resetRecoveryAccountsPassword(options)- Redefinir a senha das contas de recuperação do cluster.
- setInstanceOption(instance, option, value)- Altera o valor de uma opção de configuração em um membro do cluster.
- setOption(option, value)- Altera o valor de uma opção de configuração para todo o cluster.
- setPrimaryInstance(instance)- Elege um membro de cluster específico como o novo primário.
- status([options])- Descreva o status do cluster.
- switchToMultiPrimaryMode()- Alterna o cluster para o modo multiprimário.
- switchToSinglePrimaryMode([instance])- Alterna o cluster para o modo primário único.
Vamos analisar a maioria das funções disponíveis para nos ajudar a monitorar, gerenciar e dimensionar o cluster.
Monitorando as operações do cluster MySQL InnoDB
Status do cluster
Para verificar o status do cluster, primeiro use a linha de comando do shell do MySQL e, em seguida, conecte-se como example@sqldat.com{one-of-the-db-nodes}:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");Em seguida, crie um objeto chamado "cluster" e declare-o como objeto global "dba" que fornece acesso às funções de administração do cluster InnoDB usando o AdminAPI (confira a documentação da API do MySQL Shell):
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>Então, podemos usar o nome do objeto para chamar as funções da API para o objeto "dba":
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db1:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.061918",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.447804",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db1:3306"
}A saída é bem longa, mas podemos filtrá-la usando a estrutura do mapa. Por exemplo, se quisermos ver o atraso de replicação apenas para db3, podemos fazer o seguinte:
MySQL|db1:3306 ssl|JS> cluster.status().defaultReplicaSet.topology["db3:3306"].replicationLag
00:00:09.447804Observe que o atraso de replicação é algo que acontecerá na replicação de grupo, dependendo da intensidade de gravação do membro primário no conjunto de réplicas e das variáveis group_replication_flow_control_*. Não vamos abordar este tópico em detalhes aqui. Confira esta postagem no blog para entender melhor o desempenho da replicação de grupo e o controle de fluxo.
Outra função semelhante é a função describe(), mas esta é um pouco mais simples. Ele descreve a estrutura do cluster incluindo todas as suas informações, ReplicaSets e Instances:
MySQL|db1:3306 ssl|JS> cluster.describe(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"topology": [
{
"address": "db1:3306",
"label": "db1:3306",
"role": "HA"
},
{
"address": "db2:3306",
"label": "db2:3306",
"role": "HA"
},
{
"address": "db3:3306",
"label": "db3:3306",
"role": "HA"
}
],
"topologyMode": "Single-Primary"
}
}Da mesma forma, podemos filtrar a saída JSON usando a estrutura do mapa:
MySQL|db1:3306 ssl|JS> cluster.describe().defaultReplicaSet.topologyMode
Single-PrimaryQuando o nó primário ficou inativo (neste caso, é db1), a saída retornou o seguinte:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures. 1 member is not active",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"shellConnectError": "MySQL Error 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 104",
"status": "(MISSING)"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Preste atenção ao status OK_NO_TOLERANCE, onde o cluster ainda está em execução, mas não pode tolerar mais falhas depois que um sobre três nós não estiver disponível. A função primária foi assumida pelo db2 automaticamente e as conexões de banco de dados do aplicativo serão roteadas novamente para o nó correto se elas se conectarem por meio do MySQL Router. Quando o db1 estiver online novamente, devemos ver o seguinte status:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Ele mostra que o db1 agora está disponível, mas serviu como secundário com somente leitura habilitado. A função primária ainda é atribuída ao db2 até que algo dê errado no nó, onde será feito automaticamente o failover para o próximo nó disponível.
Verificar estado da instância
Podemos verificar o estado de um nó MySQL antes de planejar adicioná-lo ao cluster usando a função checkInstanceState(). Ele analisa os GTIDs executados por instância com os GTIDs executados/purgados no cluster para determinar se a instância é válida para o cluster.
A seguir, mostra o estado da instância do db3 quando estava no modo autônomo, antes de fazer parte do cluster:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' is a standalone instance but is part of a different InnoDB Cluster (metadata exists, instance does not belong to that metadata, and Group Replication is not active).Se o nó já fizer parte do cluster, você deverá obter o seguinte:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' already belongs to the ReplicaSet: 'default'.Monitorar qualquer estado "consultável"
Com o MySQL Shell, agora podemos usar o comando interno \show e \watch para monitorar qualquer consulta administrativa em tempo real. Por exemplo, podemos obter o valor em tempo real das threads conectadas usando:
MySQL|db1:3306 ssl|JS> \show query SHOW STATUS LIKE '%thread%';Ou obtenha a lista de processos atual do MySQL:
MySQL|db1:3306 ssl|JS> \show query SHOW FULL PROCESSLISTPodemos então usar o comando \watch para executar um relatório da mesma forma que o comando \show, mas ele atualiza os resultados em intervalos regulares até que você cancele o comando usando Ctrl + C. Conforme mostrado em os seguintes exemplos:
MySQL|db1:3306 ssl|JS> \watch query SHOW STATUS LIKE '%thread%';
MySQL|db1:3306 ssl|JS> \watch query --interval=1 SHOW FULL PROCESSLISTO intervalo de atualização padrão é de 2 segundos. Você pode alterar o valor usando o sinalizador --interval e especificou um valor de 0,1 a 86400.
Operações de gerenciamento de cluster MySQL InnoDB
Alternância primária
A instância primária é o nó que pode ser considerado o líder em um grupo de replicação, que tem a capacidade de realizar operações de leitura e gravação. Apenas uma instância primária por cluster é permitida no modo de topologia primária única. Essa topologia também é conhecida como conjunto de réplicas e é o modo de topologia recomendado para replicação de grupo com proteção contra conflitos de bloqueio.
Para realizar a alternância da instância primária, efetue login em um dos nós do banco de dados como o usuário clusteradmin e especifique o nó do banco de dados que deseja promover usando a função setPrimaryInstance():
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster.setPrimaryInstance("db1:3306");
Setting instance 'db1:3306' as the primary instance of cluster 'my_innodb_cluster'...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' remains SECONDARY.
Instance 'db1:3306' was switched from SECONDARY to PRIMARY.
WARNING: The cluster internal session is not the primary member anymore. For cluster management operations please obtain a fresh cluster handle using <Dba>.getCluster().
The instance 'db1:3306' was successfully elected as primary.Acabamos de promover o db1 como o novo componente primário, substituindo o db2 enquanto o db3 permanece como o nó secundário.
Encerrando o cluster
A melhor maneira de encerrar o cluster normalmente interrompendo o serviço do MySQL Router primeiro (se estiver em execução) no servidor de aplicativos:
$ myrouter/stop.shA etapa acima fornece proteção de cluster contra gravações acidentais dos aplicativos. Em seguida, desligue um nó de banco de dados por vez usando o comando padrão de parada do MySQL ou execute o desligamento do sistema conforme desejar:
$ systemctl stop mysqlIniciando o cluster após um desligamento
Se seu cluster sofrer uma interrupção completa ou você quiser iniciar o cluster após um encerramento limpo, você pode garantir que ele seja reconfigurado corretamente usando a função dba.rebootClusterFromCompleteOutage(). Ele simplesmente traz um cluster de volta ONLINE quando todos os membros estão OFFLINE. No caso de um cluster ter parado completamente, as instâncias devem ser iniciadas e só então o cluster pode ser iniciado.
Assim, certifique-se de que todos os servidores MySQL estejam iniciados e funcionando. Em cada nó do banco de dados, veja se o processo mysqld está rodando:
$ ps -ef | grep -i mysqlEm seguida, escolha um servidor de banco de dados para ser o nó principal e conecte-se a ele via shell MySQL:
MySQL|JS> shell.connect("example@sqldat.com:3306");Execute o seguinte comando desse host para iniciá-los:
MySQL|db1:3306 ssl|JS> cluster = dba.rebootClusterFromCompleteOutage()Serão apresentadas as seguintes perguntas:
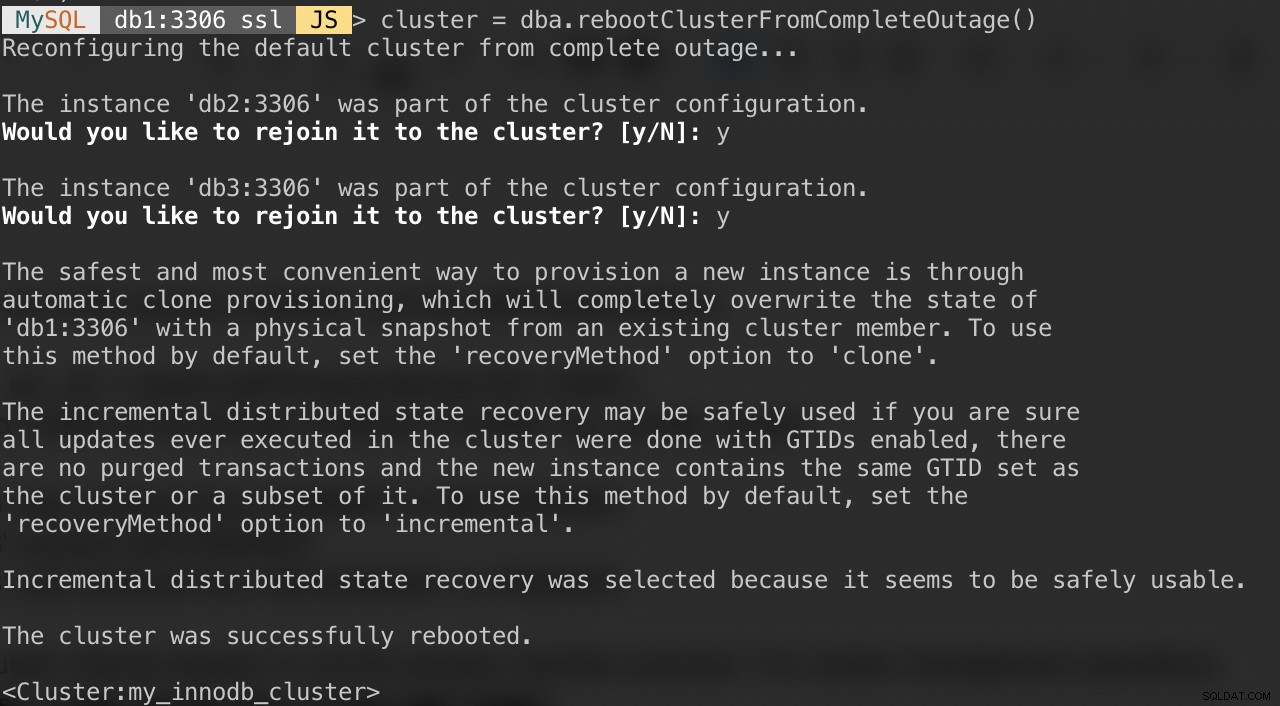
Após a conclusão acima, você pode verificar o status do cluster:
MySQL|db1:3306 ssl|JS> cluster.status()Neste ponto, db1 é o nó primário e o gravador. Os demais serão os membros secundários. Se desejar iniciar o cluster com db2 ou db3 como primário, você poderá usar a função shell.connect() para conectar-se ao nó correspondente e executar rebootClusterFromCompleteOutage() a partir desse nó específico.
Você pode então iniciar o serviço do MySQL Router (se não for iniciado) e deixar o aplicativo se conectar ao cluster novamente.
Definindo opções de membro e cluster
Para obter as opções em todo o cluster, basta executar:
MySQL|db1:3306 ssl|JS> cluster.options()A lista acima listará as opções globais para o conjunto de réplicas e também as opções individuais por membro no cluster. Esta função altera uma opção de configuração do InnoDB Cluster em todos os membros do cluster. As opções suportadas são:
- clusterName:valor da string para definir o nome do cluster.
- exitStateAction:valor da string que indica a ação do estado de saída da replicação do grupo.
- memberWeight:valor inteiro com um peso percentual para eleição primária automática em failover.
- failoverConsistency:valor da string que indica as garantias de consistência que o cluster oferece.
- consistência: valor da string que indica as garantias de consistência que o cluster oferece.
- expelTimeout:valor inteiro para definir o período de tempo em segundos que os membros do cluster devem esperar por um membro que não responde antes de removê-lo do cluster.
- autoRejoinTries:valor inteiro para definir o número de vezes que uma instância tentará ingressar novamente no cluster após ser expulsa.
- disableClone:valor booleano usado para desabilitar o uso do clone no cluster.
Semelhante a outra função, a saída pode ser filtrada na estrutura do mapa. O comando a seguir listará apenas as opções para db2:
MySQL|db1:3306 ssl|JS> cluster.options().defaultReplicaSet.topology["db2:3306"]Você também pode obter a lista acima usando a função help():
MySQL|db1:3306 ssl|JS> cluster.help("setOption")O comando a seguir mostra um exemplo para definir uma opção chamada memberWeight para 60 (de 50) em todos os membros:
MySQL|db1:3306 ssl|JS> cluster.setOption("memberWeight", 60)
Setting the value of 'memberWeight' to '60' in all ReplicaSet members ...
Successfully set the value of 'memberWeight' to '60' in the 'default' ReplicaSet.Também podemos executar o gerenciamento de configuração automaticamente via MySQL Shell usando a função setInstanceOption() e passar o host do banco de dados, o nome da opção e o valor de acordo:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.setInstanceOption("db1:3306", "memberWeight", 90)As opções suportadas são:
- exitStateAction: valor da string que indica a ação do estado de saída da replicação do grupo.
- memberWeight:valor inteiro com um peso percentual para eleição primária automática em failover.
- autoRejoinTries:valor inteiro para definir o número de vezes que uma instância tentará ingressar novamente no cluster após ser expulsa.
- rotule um identificador de string da instância.
Mudando para o modo multiprimário/único primário
Por padrão, o InnoDB Cluster é configurado com primário único, apenas um membro capaz de realizar leituras e gravações em um determinado momento. Essa é a maneira mais segura e recomendada de executar o cluster e adequada para a maioria das cargas de trabalho.
No entanto, se a lógica do aplicativo puder lidar com gravações distribuídas, provavelmente é uma boa ideia alternar para o modo multiprimário, onde todos os membros do cluster podem processar leituras e gravações ao mesmo tempo. Para alternar do modo primário único para o modo multiprimário, basta usar a função switchToMultiPrimaryMode():
MySQL|db1:3306 ssl|JS> cluster.switchToMultiPrimaryMode()
Switching cluster 'my_innodb_cluster' to Multi-Primary mode...
Instance 'db2:3306' was switched from SECONDARY to PRIMARY.
Instance 'db3:3306' was switched from SECONDARY to PRIMARY.
Instance 'db1:3306' remains PRIMARY.
The cluster successfully switched to Multi-Primary mode.Verifique com:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Multi-Primary"
},
"groupInformationSourceMember": "db1:3306"
}No modo multiprimário, todos os nós são primários e capazes de processar leituras e gravações. Ao enviar uma nova conexão via MySQL Router na porta single-writer (6446), a conexão será enviada para apenas um nó, como neste exemplo, db1:
(app-server)$ for i in {1..3}; do mysql -usbtest -p -h192.168.10.40 -P6446 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Se o aplicativo se conectar à porta multi-writer (6447), a conexão será balanceada por meio do algoritmo round robin para todos os membros:
(app-server)$ for i in {1..3}; do mysql -usbtest -ppassword -h192.168.10.40 -P6447 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db2 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db3 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Como você pode ver na saída acima, todos os nós são capazes de processar leituras e gravações com read_only =OFF. Você pode distribuir gravações seguras para todos os membros conectando-se à porta de vários gravadores (6447) e enviar as gravações conflitantes ou pesadas para a porta de gravador único (6446).
Para voltar ao modo primário único, use a função switchToSinglePrimaryMode() e especifique um membro como o nó primário. Neste exemplo, escolhemos db1:
MySQL|db1:3306 ssl|JS> cluster.switchToSinglePrimaryMode("db1:3306");
Switching cluster 'my_innodb_cluster' to Single-Primary mode...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' was switched from PRIMARY to SECONDARY.
Instance 'db1:3306' remains PRIMARY.
WARNING: Existing connections that expected a R/W connection must be disconnected, i.e. instances that became SECONDARY.
The cluster successfully switched to Single-Primary mode.Neste ponto, db1 agora é o nó primário configurado com somente leitura desabilitado e o restante será configurado como secundário com somente leitura habilitado.
Operações de dimensionamento de cluster MySQL InnoDB
Escalando (Adicionando um novo nó de banco de dados)
Ao adicionar uma nova instância, um nó deve ser provisionado primeiro antes de poder participar do grupo de replicação. O processo de provisionamento será tratado automaticamente pelo MySQL. Além disso, você pode verificar primeiro o estado da instância se o nó é válido para ingressar no cluster usando a função checkInstanceState() conforme explicado anteriormente.
Para adicionar um novo nó de banco de dados, use a função addInstances() e especifique o host:
MySQL|db1:3306 ssl|JS> cluster.addInstance("db3:3306")Veja a seguir o que você obteria ao adicionar uma nova instância:
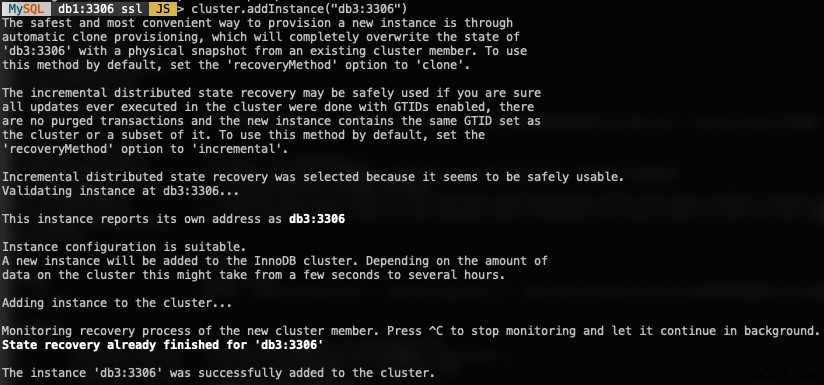
Verifique o novo tamanho do cluster com:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()O MySQL Router incluirá automaticamente o nó adicionado, db3, no conjunto de balanceamento de carga.
Diminuindo a escala (removendo um nó)
Para remover um nó, conecte-se a qualquer um dos nós do banco de dados, exceto aquele que vamos remover e use a função removeInstance() com o nome da instância do banco de dados:
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.removeInstance("db3:3306")O seguinte é o que você obteria ao remover uma instância:
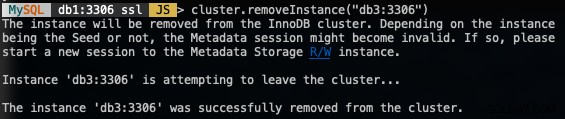
Verifique o novo tamanho do cluster com:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()O MySQL Router excluirá automaticamente o nó removido, db3, do conjunto de balanceamento de carga.
Adicionando um novo escravo de replicação
Podemos dimensionar o InnoDB Cluster com réplicas de escravos de replicação assíncrona de qualquer um dos nós do cluster. Um escravo é levemente acoplado ao cluster e será capaz de lidar com uma carga pesada sem afetar o desempenho do cluster. O escravo também pode ser uma cópia ativa do banco de dados para fins de recuperação de desastres. No modo multiprimário, você pode usar o escravo como o processador dedicado somente leitura do MySQL para dimensionar a carga de trabalho de leituras, realizar operações de análise ou como um servidor de backup dedicado.
No servidor escravo, baixe o pacote de configuração APT mais recente, instale-o (escolha MySQL 8.0 no assistente de configuração), instale a chave APT, atualize o repolist e instale o servidor MySQL.
$ wget https://repo.mysql.com/apt/ubuntu/pool/mysql-apt-config/m/mysql-apt-config/mysql-apt-config_0.8.14-1_all.deb
$ dpkg -i mysql-apt-config_0.8.14-1_all.deb
$ apt-key adv --recv-keys --keyserver ha.pool.sks-keyservers.net 5072E1F5
$ apt-get update
$ apt-get -y install mysql-server mysql-shellModifique o arquivo de configuração do MySQL para preparar o servidor para o escravo de replicação. Abra o arquivo de configuração através do editor de texto:
$ vim /etc/mysql/mysql.conf.d/mysqld.cnfE acrescente as seguintes linhas:
server-id = 1044 # must be unique across all nodes
gtid-mode = ON
enforce-gtid-consistency = ON
log-slave-updates = OFF
read-only = ON
super-read-only = ON
expire-logs-days = 7Reinicie o servidor MySQL no escravo para aplicar as alterações:
$ systemctl restart mysqlEm um dos servidores do InnoDB Cluster (escolhemos db3), crie um usuário escravo de replicação e, em seguida, um dump MySQL completo:
$ mysql -uroot -p
mysql> CREATE USER 'repl_user'@'192.168.0.44' IDENTIFIED BY 'password';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'192.168.0.44';
mysql> exit
$ mysqldump -uroot -p --single-transaction --master-data=1 --all-databases --triggers --routines --events > dump.sqlTransfira o arquivo dump do db3 para o escravo:
$ scp dump.sql example@sqldat.com:~E execute a restauração no escravo:
$ mysql -uroot -p < dump.sqlCom master-data=1, nosso arquivo de despejo MySQL configurará automaticamente o valor GTID executado e purgado. Podemos verificá-lo com a seguinte declaração no servidor escravo após a restauração:
$ mysql -uroot -p
mysql> show global variables like '%gtid_%';
+----------------------------------+----------------------------------------------+
| Variable_name | Value |
+----------------------------------+----------------------------------------------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
+----------------------------------+----------------------------------------------+Parece bom. Podemos então configurar o link de replicação e iniciar os threads de replicação no escravo:
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.10.43', MASTER_USER = 'repl_user', MASTER_PASSWORD = 'password', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Verifique o estado de replicação e certifique-se de que o seguinte status retorne 'Sim':
mysql> show slave status\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
...Neste ponto, nossa arquitetura agora está assim:
Problemas comuns com clusters MySQL InnoDB
Esgotamento da memória
Ao usar o MySQL Shell com o MySQL 8.0, recebíamos constantemente o seguinte erro quando as instâncias eram configuradas com 1 GB de RAM:
Can't create a new thread (errno 11); if you are not out of available memory, you can consult the manual for a possible OS-dependent bug (MySQL Error 1135)Atualizar a RAM de cada host para 2 GB de RAM resolveu o problema. Aparentemente, os componentes do MySQL 8.0 requerem mais RAM para operar com eficiência.
Conexão perdida com o servidor MySQL
Caso o nó primário fique inativo, você provavelmente verá o "erro de conexão perdida com o servidor MySQL" ao tentar consultar algo na sessão atual:
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: Lost connection to MySQL server during query (MySQL Error 2013)
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: MySQL server has gone away (MySQL Error 2006)The solution is to re-declare the object once more:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.status()At this point, it will connect to the newly promoted primary node to retrieve the cluster status.
Node Eviction and Expelled
In an event where communication between nodes is interrupted, the problematic node will be evicted from the cluster without any delay, which is not good if you are running on a non-stable network. This is what it looks like on db2 (the problematic node):
2019-11-14T07:07:59.344888Z 0 [ERROR] [MY-011505] [Repl] Plugin group_replication reported: 'Member was expelled from the group due to network failures, changing member status to ERROR.'
2019-11-14T07:07:59.371966Z 0 [ERROR] [MY-011712] [Repl] Plugin group_replication reported: 'The server was automatically set into read only mode after an error was detected.'Meanwhile from db1, it saw db2 was offline:
2019-11-14T07:07:44.086021Z 0 [Warning] [MY-011493] [Repl] Plugin group_replication reported: 'Member with address db2:3306 has become unreachable.'
2019-11-14T07:07:46.087216Z 0 [Warning] [MY-011499] [Repl] Plugin group_replication reported: 'Members removed from the group: db2:3306'
To tolerate a bit of delay on node eviction, we can set a higher timeout value before a node is being expelled from the group. The default value is 0, which means expel immediately. Use the setOption() function to set the expelTimeout value:
Thanks to Frédéric Descamps from Oracle who pointed this out:
Instead of relying on expelTimeout, it's recommended to set the autoRejoinTries option instead. The value represents the number of times an instance will attempt to rejoin the cluster after being expelled. A good number to start is 3, which means, the expelled member will try to rejoin the cluster for 3 times, which after an unsuccessful auto-rejoin attempt, the member waits 5 minutes before the next try.
To set this value cluster-wide, we can use the setOption() function:
MySQL|db1:3306 ssl|JS> cluster.setOption("autoRejoinTries", 3)
WARNING: Each cluster member will only proceed according to its exitStateAction if auto-rejoin fails (i.e. all retry attempts are exhausted).
Setting the value of 'autoRejoinTries' to '3' in all ReplicaSet members ...
Successfully set the value of 'autoRejoinTries' to '3' in the 'default' ReplicaSet.Conclusão
For MySQL InnoDB Cluster, most of the management and monitoring operations can be performed directly via MySQL Shell (only available from MySQL 5.7.21 and later).