Quase um ano atrás, postei minha solução para paginação no SQL Server, que envolvia usar um CTE para localizar apenas os valores de chave para o conjunto de linhas em questão e, em seguida, unir novamente do CTE à tabela de origem para recuperar as outras colunas apenas para essa "página" de linhas. Isso provou ser mais benéfico quando havia um índice estreito que suportava a ordenação solicitada pelo usuário, ou quando a ordenação era baseada na chave de cluster, mas ainda funcionava um pouco melhor sem um índice para suportar a ordenação necessária.
Desde então, tenho me perguntado se os índices ColumnStore (clusterizados e não clusterizados) podem ajudar em qualquer um desses cenários. TL;DR :Com base neste experimento isolado, a resposta para o título desta postagem é um retumbante NÃO . Se você não quiser ver a configuração do teste, código, planos de execução ou gráficos, sinta-se à vontade para pular para o meu resumo, tendo em mente que minha análise é baseada em um caso de uso muito específico.
Configuração
Em uma nova VM com o SQL Server 2016 CTP 3.2 (13.0.900.73) instalado, executei aproximadamente a mesma configuração de antes, só que desta vez com três tabelas. Primeiro, uma tabela tradicional com uma chave de cluster estreita e vários índices de suporte:
CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); -- to support "PhoneBook" sorting (order by Last,First) CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Em seguida, uma tabela com um índice ColumnStore clusterizado:
CREATE TABLE [dbo].[Customers_CCI] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_CustomersCCI] PRIMARY KEY NONCLUSTERED ([CustomerID]) ); CREATE CLUSTERED COLUMNSTORE INDEX [Customers_CCI] ON [dbo].[Customers_CCI];
E, finalmente, uma tabela com um índice ColumnStore não clusterizado cobrindo todas as colunas:
CREATE TABLE [dbo].[Customers_NCCI]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_CustomersNCCI] PRIMARY KEY CLUSTERED
([CustomerID])
);
CREATE NONCLUSTERED COLUMNSTORE INDEX [Customers_NCCI]
ON [dbo].[Customers_NCCI]
(
[CustomerID],
[FirstName],
[LastName],
[EMail],
[Active],
[Created],
[Updated]
); Observe que, para ambas as tabelas com índices ColumnStore, deixei de fora o índice que daria suporte a buscas mais rápidas na classificação "PhoneBook" (sobrenome, nome).
Dados de teste
Em seguida, preenchi a primeira tabela com 1.000.000 de linhas aleatórias, com base em um script que reutilizei de postagens anteriores:
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (2000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name+c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn; Em seguida, usei essa tabela para preencher as outras duas com exatamente os mesmos dados e reconstruí todos os índices:
INSERT dbo.Customers_CCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; INSERT dbo.Customers_NCCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; ALTER INDEX ALL ON dbo.Customers REBUILD; ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
O tamanho total de cada tabela:
| Tabela | Reservado | Dados | Índice |
|---|---|---|---|
| Clientes | 463.200 KB | 154.344 KB | 308.576 KB |
| Clientes_CCI | 117.280 KB | 30.288 KB | 86.536 KB |
| Clientes_NCCI | 349.480 KB | 154.344 KB | 194.976 KB |
E a contagem de linhas / contagem de páginas dos índices relevantes (o índice exclusivo no e-mail estava lá mais para mim para cuidar do meu próprio script de geração de dados do que qualquer outra coisa):
| Tabela | Índice | Linhas | Páginas |
|---|---|---|---|
| Clientes | PK_Clientes | 1.000.000 | 19.377 |
| Clientes | PhoneBook_Customers | 1.000.000 | 17.209 |
| Clientes | Clientes_ativos | 808.012 | 13.977 |
| Clientes_CCI | PK_CustomersCCI | 1.000.000 | 2.737 |
| Clientes_CCI | Clientes_CCI | 1.000.000 | 3.826 |
| Clientes_NCCI | PK_CustomersNCCI | 1.000.000 | 19.377 |
| Clientes_NCCI | Clientes_NCCI | 1.000.000 | 16.971 |
Procedimentos
Então, para ver se os índices ColumnStore iriam se aproximar e melhorar qualquer um dos cenários, executei o mesmo conjunto de consultas de antes, mas agora nas três tabelas. Fiquei pelo menos um pouco mais esperto e fiz dois procedimentos armazenados com SQL dinâmico para aceitar a origem da tabela e a ordem de classificação. (Eu estou bem ciente da injeção de SQL; isso não é o que eu faria na produção se essas strings fossem provenientes de um usuário final, então por favor não tome isso como uma recomendação para fazê-lo. Eu confio em mim o suficiente em meu ambiente fechado que não é uma preocupação para esses testes.)
CREATE PROCEDURE dbo.P_Old
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N'
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
CREATE PROCEDURE dbo.P_CTE
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
;WITH pg AS
(
SELECT CustomerID
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.' + QUOTENAME(@Table) + N' AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO Então eu preparei um SQL mais dinâmico para gerar todas as combinações de chamadas que eu precisaria fazer para chamar os procedimentos armazenados antigos e novos, em todas as três ordens de classificação desejadas e em números de página diferentes (para simular a necessidade de uma página perto do início, meio e fim da ordem de classificação). Para que eu pudesse copiar
PRINT output e cole-o no SQL Sentry Plan Explorer para obter métricas de tempo de execução, executei este lote duas vezes, uma vez com os procedures CTE usando P_Old , e novamente usando P_CTE . DECLARE @sql NVARCHAR(MAX) = N''; ;WITH [tables](name) AS ( SELECT N'Customers' UNION ALL SELECT N'Customers_CCI' UNION ALL SELECT N'Customers_NCCI' ), sorts(sort) AS ( SELECT 'Key' UNION ALL SELECT 'PhoneBook' UNION ALL SELECT 'Unsupported' ), pages(pagenumber) AS ( SELECT 1 UNION ALL SELECT 500 UNION ALL SELECT 5000 UNION ALL SELECT 9999 ), procedures(name) AS ( SELECT N'P_CTE' -- N'P_Old' ) SELECT @sql += N' EXEC dbo.' + p.name + N' @Table = N' + CHAR(39) + t.name + CHAR(39) + N', @Sort = N' + CHAR(39) + s.sort + CHAR(39) + N', @PageNumber = ' + CONVERT(NVARCHAR(11), pg.pagenumber) + N';' FROM tables AS t CROSS JOIN sorts AS s CROSS JOIN pages AS pg CROSS JOIN procedures AS p ORDER BY t.name, s.sort, pg.pagenumber; PRINT @sql;
Isso produziu uma saída como esta (36 chamadas ao todo para o método antigo (
P_Old ) e 36 chamadas para o novo método (P_CTE )):EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 1; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 500; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 5000; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Unsupported', @PageNumber = 9999;
Eu sei, tudo isso é muito complicado; estamos chegando ao final em breve, eu prometo.
Resultados
Peguei esses dois conjuntos de 36 instruções e iniciei duas novas sessões no Plan Explorer, executando cada conjunto várias vezes para garantir que estávamos obtendo dados de um cache quente e obtendo médias (eu poderia comparar cache frio e quente também, mas acho que há variáveis suficientes aqui).
Eu posso te dizer logo de cara alguns fatos simples sem nem mesmo mostrar gráficos ou planos de apoio:
- Em nenhum cenário o método "antigo" superou o novo método CTE Eu promovi no meu post anterior, não importa que tipo de índices estavam presentes. Isso facilita praticamente ignorar metade dos resultados, pelo menos em termos de duração (que é a métrica com a qual os usuários finais mais se preocupam).
- Nenhum índice ColumnStore se saiu bem ao paginar até o final do resultado – eles só forneceram benefícios no início, e apenas em alguns casos.
- Ao classificar pela chave primária (agrupados ou não), a presença de índices ColumnStore não ajudou – novamente, em termos de duração.
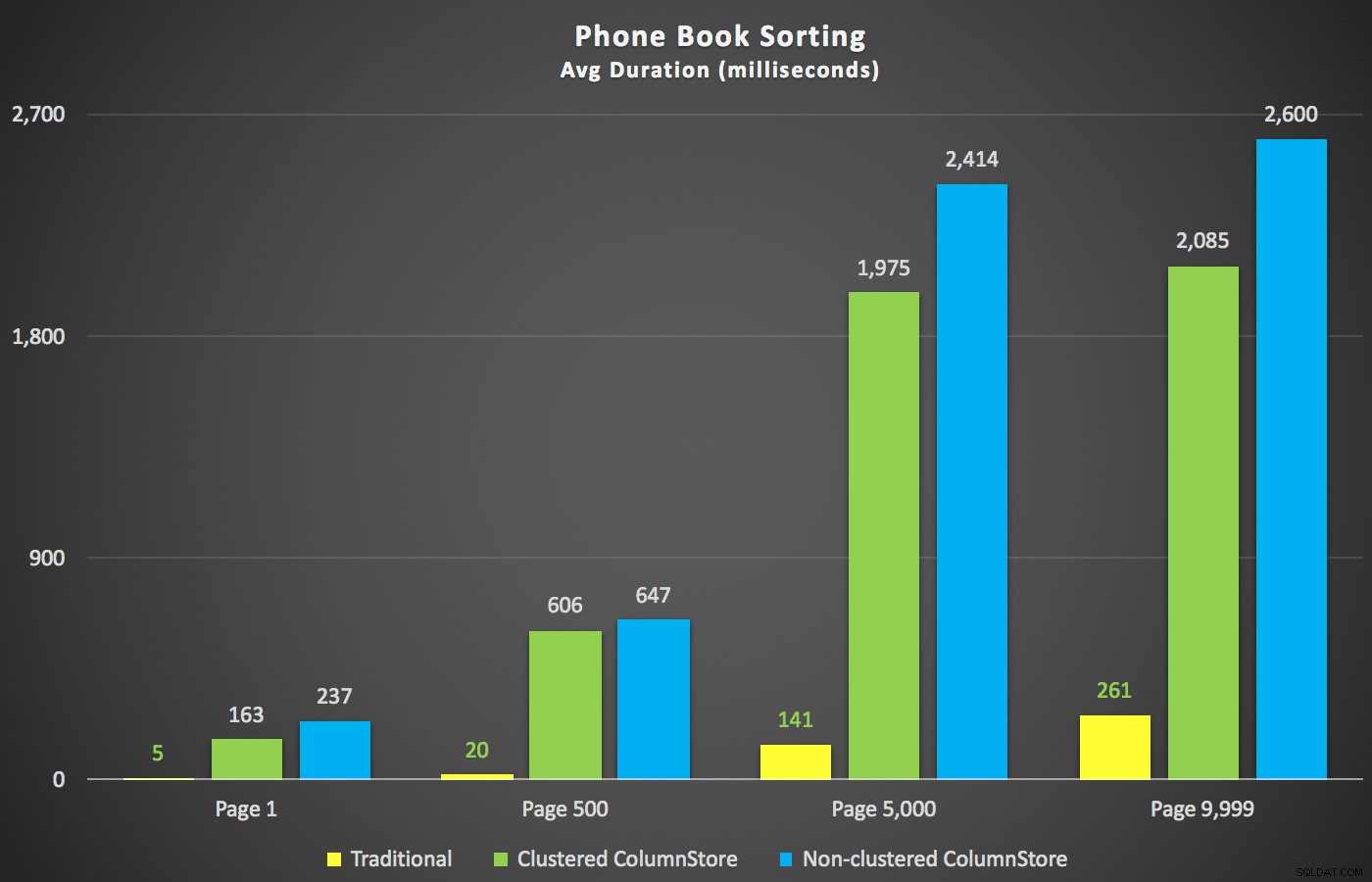
Com esses resumos fora do caminho, vamos dar uma olhada em algumas seções cruzadas dos dados de duração. Primeiro, os resultados da consulta ordenados por primeiro nome descendente, depois e-mail, sem esperança de usar um índice existente para classificação. Como você pode ver no gráfico, o desempenho foi inconsistente – em números de página mais baixos, o ColumnStore não agrupado se saiu melhor; em números de página mais altos, o índice tradicional sempre ganhava:
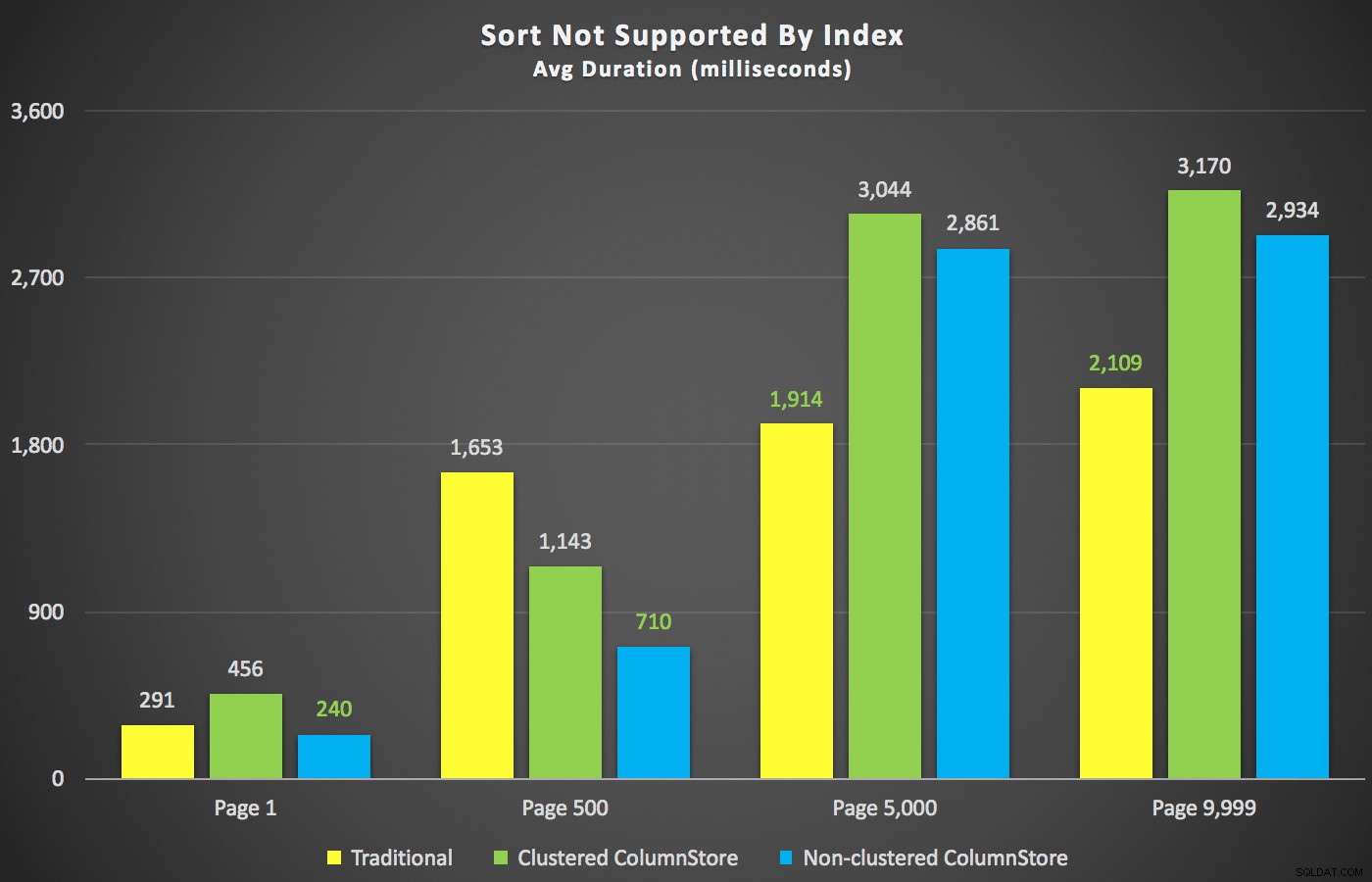 Duração (milissegundos) para diferentes números de página e diferentes tipos de índice
Duração (milissegundos) para diferentes números de página e diferentes tipos de índice E então os três planos que representam os três diferentes tipos de índices (com tons de cinza adicionados pelo Photoshop para destacar as principais diferenças entre os planos):
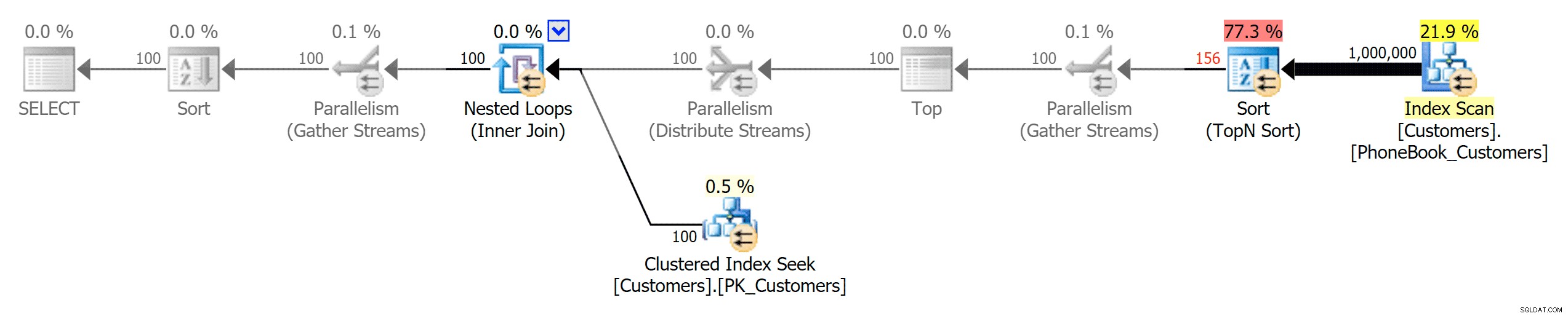 Planejar o índice tradicional
Planejar o índice tradicional  Planejar o índice ColumnStore clusterizado
Planejar o índice ColumnStore clusterizado  Planejar índice ColumnStore não clusterizado
Planejar índice ColumnStore não clusterizado Um cenário em que eu estava mais interessado, mesmo antes de começar a testar, era a abordagem de classificação de lista telefônica (sobrenome, nome). Nesse caso, os índices ColumnStore foram bastante prejudiciais para o desempenho do resultado:
Os planos ColumnStore aqui estão próximos das imagens espelhadas dos dois planos ColumnStore mostrados acima para a classificação não suportada. O motivo é o mesmo em ambos os casos:varreduras ou classificações caras devido à falta de um índice de suporte à classificação.
Então, em seguida, criei índices "PhoneBook" de suporte nas tabelas com os índices ColumnStore também, para ver se eu poderia persuadir um plano diferente e/ou tempos de execução mais rápidos em qualquer um desses cenários. Eu criei esses dois índices e reconstruí novamente:
CREATE NONCLUSTERED INDEX [PhoneBook_CustomersCCI] ON [dbo].[Customers_CCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; CREATE NONCLUSTERED INDEX [PhoneBook_CustomersNCCI] ON [dbo].[Customers_NCCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Aqui estavam as novas durações:
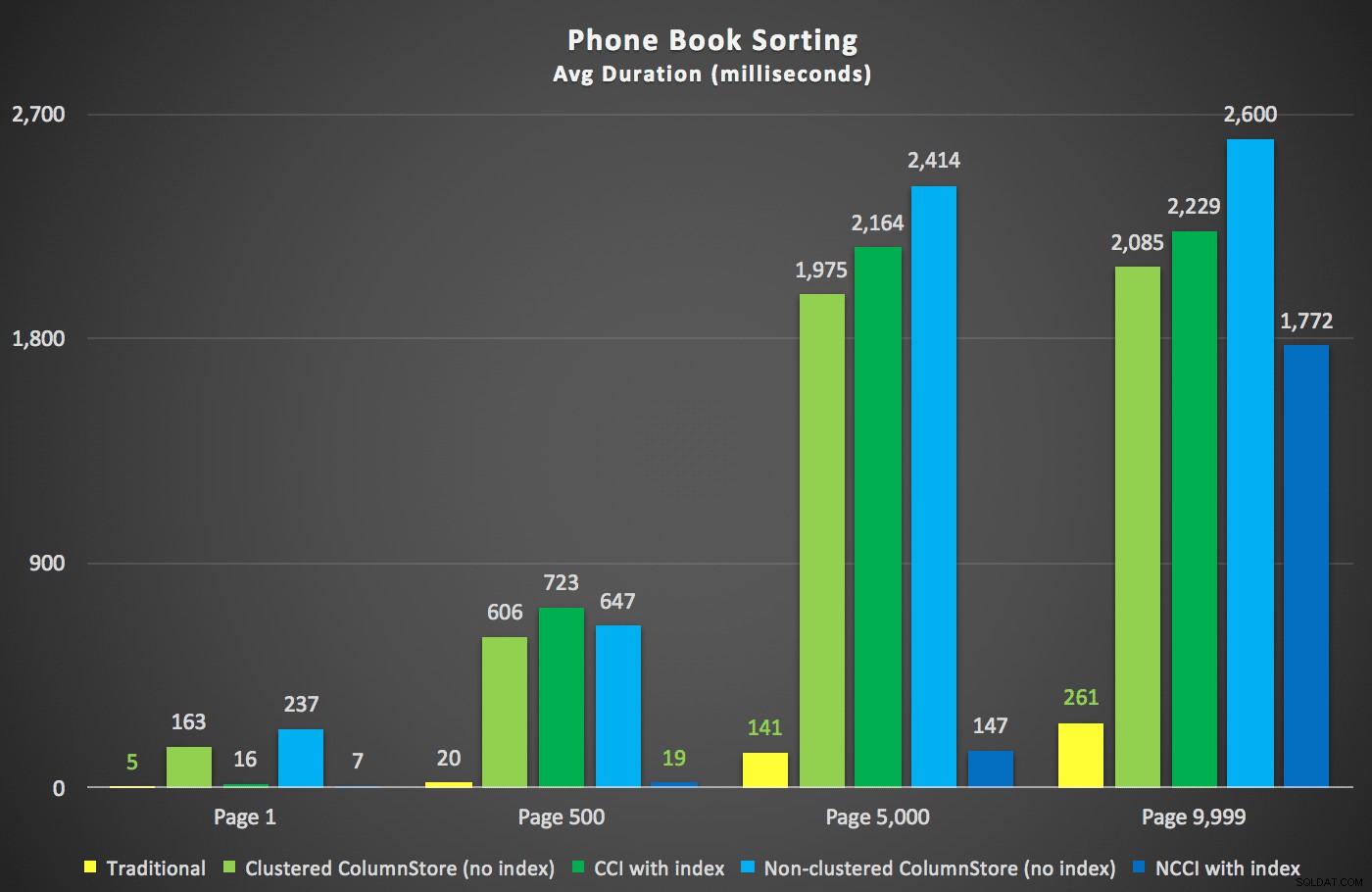
O mais interessante aqui é que agora a consulta de paginação na tabela com o índice ColumnStore não agrupado parece estar acompanhando o índice tradicional, até chegarmos além do meio da tabela. Observando os planos, podemos ver que na página 5.000, uma varredura de índice tradicional é usada e o índice ColumnStore é completamente ignorado:
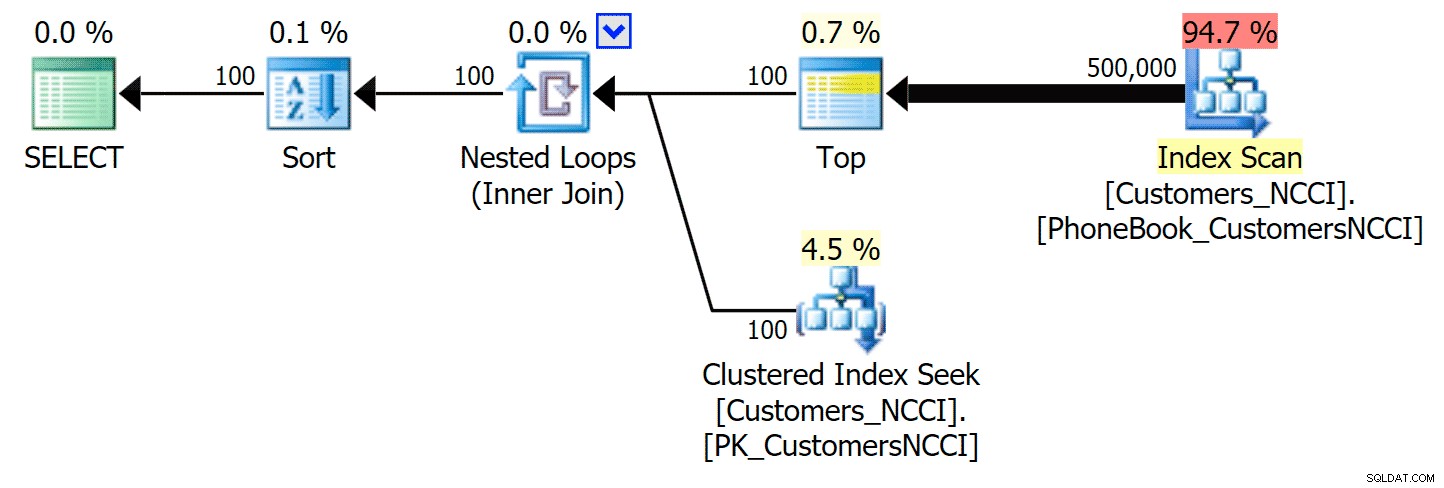 Plano de lista telefônica ignorando o índice ColumnStore não clusterizado
Plano de lista telefônica ignorando o índice ColumnStore não clusterizado Mas em algum lugar entre o ponto médio de 5.000 páginas e o "fim" da tabela em 9.999 páginas, o otimizador atingiu uma espécie de ponto de inflexão e - para exatamente a mesma consulta - agora está optando por verificar o índice ColumnStore não clusterizado :
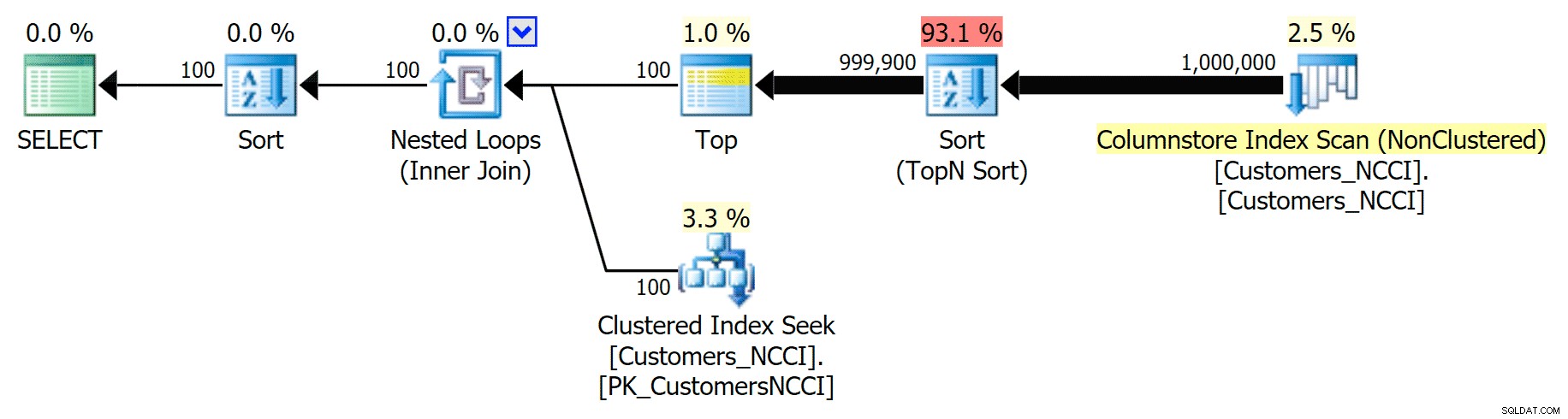 Dicas do plano de lista telefônica e usa o índice ColumnStore
Dicas do plano de lista telefônica e usa o índice ColumnStore Isso acaba sendo uma decisão não tão boa do otimizador, principalmente devido ao custo da operação de classificação. Você pode ver o quanto a duração fica melhor se você sugerir o índice regular:
-- ...
;WITH pg AS
(
SELECT CustomerID
FROM dbo.[Customers_NCCI] WITH (INDEX(PhoneBook_CustomersNCCI)) -- hint here
ORDER BY LastName, FirstName OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
-- ... Isso produz o seguinte plano, quase idêntico ao primeiro plano acima (um custo um pouco mais alto para a varredura, simplesmente porque há mais saída):
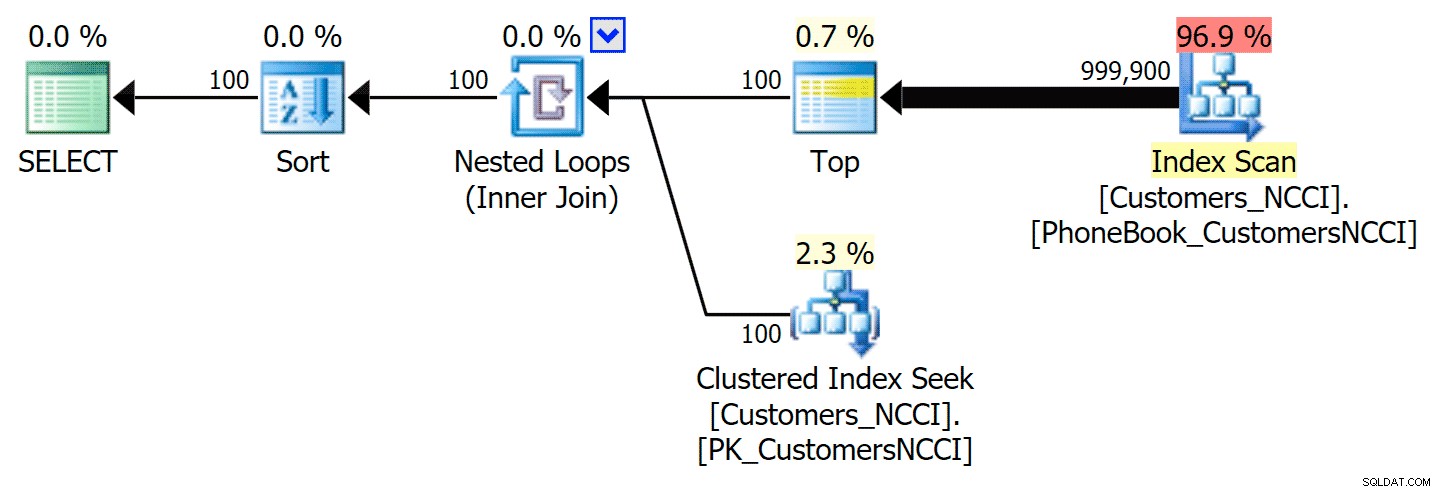 Plano de lista telefônica com índice sugerido
Plano de lista telefônica com índice sugerido Você pode conseguir o mesmo usando OPTION (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) em vez da dica de índice explícita. Apenas tenha em mente que isso é o mesmo que não ter o índice ColumnStore lá em primeiro lugar.
Conclusão
Embora existam alguns casos extremos acima em que um índice ColumnStore pode (quase) valer a pena, não me parece que eles sejam adequados para esse cenário de paginação específico. Acho que, o mais importante, embora o ColumnStore demonstre economia de espaço significativa devido à compactação, o desempenho do tempo de execução não é fantástico devido aos requisitos de classificação (mesmo que esses tipos sejam executados em modo de lote, uma nova otimização para SQL Server 2016).
Em geral, isso poderia significar muito mais tempo gasto em pesquisa e testes; pegando carona em artigos anteriores, eu queria mudar o mínimo possível. Eu adoraria encontrar esse ponto de inflexão, por exemplo, e também gostaria de reconhecer que esses não são exatamente testes em grande escala (devido ao tamanho da VM e às limitações de memória), e que deixei você adivinhando muitos as métricas de tempo de execução (principalmente por brevidade, mas não sei se um gráfico de leituras que nem sempre são proporcionais à duração realmente diria a você). Esses testes também assumem os luxos de SSDs, memória suficiente, um cache sempre aquecido e um ambiente de usuário único. Eu realmente gostaria de realizar uma bateria maior de testes contra mais dados, em servidores maiores com discos mais lentos e instâncias com menos memória, tudo isso com simultaneidade simulada.
Dito isso, esse também pode ser apenas um cenário que o ColumnStore não foi projetado para ajudar a resolver em primeiro lugar, pois a solução subjacente com índices tradicionais já é bastante eficiente em extrair um conjunto estreito de linhas – não exatamente a casa do leme do ColumnStore. Talvez outra variável a ser adicionada à matriz seja o tamanho da página – todos os testes acima extraem 100 linhas por vez, mas e se estivermos atrás de 10.000 ou 100.000 linhas por vez, independentemente do tamanho da tabela subjacente?
Você tem uma situação em que sua carga de trabalho OLTP foi aprimorada simplesmente pela adição de índices ColumnStore? Eu sei que eles são projetados para cargas de trabalho no estilo de data warehouse, mas se você viu benefícios em outros lugares, adoraria ouvir sobre seu cenário e ver se posso incorporar algum diferenciador em meu equipamento de teste.