Este artigo explora alguns recursos e limitações do otimizador de consulta menos conhecidos e explica os motivos do desempenho extremamente baixo da junção de hash em um caso específico.
Dados de amostra
O script de criação de dados de exemplo a seguir depende de uma tabela de números existente. Se você ainda não possui um desses, o script abaixo pode ser usado para criar um de forma eficiente. A tabela resultante conterá uma única coluna inteira com números de um a um milhão:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
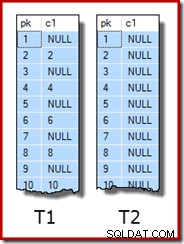
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Os dados da amostra em si consistem em duas tabelas, T1 e T2. Ambos têm uma coluna de chave primária de número inteiro sequencial denominada pk e uma segunda coluna anulável denominada c1. A Tabela T1 tem 600.000 linhas em que as linhas pares têm o mesmo valor para c1 que a coluna pk e as linhas ímpares são nulas. A tabela c2 tem 32.000 linhas em que a coluna c1 é NULL em cada linha. O script a seguir cria e preenche essas tabelas:
CREATE TABLE dbo.T1
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T1
PRIMARY KEY CLUSTERED (pk)
);
CREATE TABLE dbo.T2
(
pk integer NOT NULL,
c1 integer NULL,
CONSTRAINT PK_dbo_T2
PRIMARY KEY CLUSTERED (pk)
);
INSERT dbo.T1 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
CASE
WHEN N.n % 2 = 1 THEN NULL
ELSE N.n
END
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 600000;
INSERT dbo.T2 WITH (TABLOCKX)
(pk, c1)
SELECT
N.n,
NULL
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 32000;
UPDATE STATISTICS dbo.T1 WITH FULLSCAN;
UPDATE STATISTICS dbo.T2 WITH FULLSCAN; As primeiras dez linhas de dados de amostra em cada tabela são assim:
Juntar as duas tabelas
Este primeiro teste envolve unir as duas tabelas na coluna c1 (não a coluna pk) e retornar o valor pk da tabela T1 para as linhas que se unem:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1;
Na verdade, a consulta não retornará nenhuma linha porque a coluna c1 é NULL em todas as linhas da tabela T2, portanto, nenhuma linha pode corresponder ao predicado de junção de igualdade. Isso pode parecer uma coisa estranha de se fazer, mas tenho certeza de que é baseado em uma consulta de produção real (muito simplificada para facilitar a discussão).
Observe que esse resultado vazio não depende da configuração de ANSI_NULLS, pois isso apenas controla como as comparações com um literal nulo ou variável são tratadas. Para comparações de coluna, um predicado de igualdade sempre rejeita nulos.
O plano de execução para essa consulta de junção simples possui alguns recursos interessantes. Veremos primeiro o plano de pré-execução ('estimado') no SQL Sentry Plan Explorer:
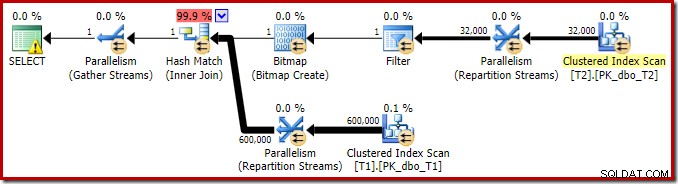
O aviso no ícone SELECT está apenas reclamando de um índice ausente na tabela T1 para a coluna c1 (com pk como uma coluna incluída). A sugestão de índice é irrelevante aqui.
O primeiro item real de interesse neste plano é o Filtro:
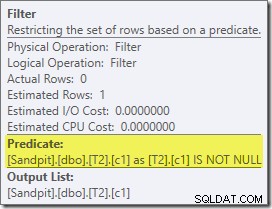
Este predicado IS NOT NULL não aparece na consulta de origem, embora esteja implícito no predicado de junção, conforme mencionado anteriormente. É interessante que ele tenha sido dividido como um operador extra explícito e colocado antes da operação de junção. Observe que, mesmo sem o Filtro, a consulta ainda produziria resultados corretos – a própria junção ainda rejeitaria os nulos.
O Filtro também é curioso por outros motivos. Ele tem um custo estimado de exatamente zero (embora seja esperado que opere em 32.000 linhas) e não foi enviado para a Verificação de índice clusterizado como um predicado residual. O otimizador normalmente está muito interessado em fazer isso.
Ambas as coisas são explicadas pelo fato deste Filtro ser introduzido em uma reescrita pós-otimização. Depois que o otimizador de consulta conclui seu processamento baseado em custo, há um número relativamente pequeno de reescritas de plano fixo que são consideradas. Um deles é responsável pela introdução do Filtro.
Podemos ver a saída da seleção de plano baseada em custo (antes da reescrita) usando sinalizadores de rastreamento não documentados 8607 e o familiar 3604 para direcionar a saída textual para o console (guia de mensagens no SSMS):
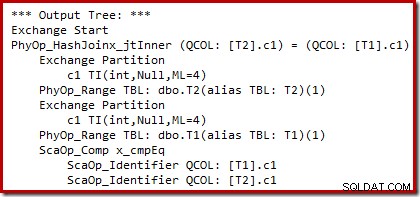
A árvore de saída mostra uma junção de hash, duas varreduras e alguns operadores de paralelismo (troca). Não há filtro de rejeição de nulo na coluna c1 da tabela T2.
A reescrita de pós-otimização específica examina exclusivamente a entrada de compilação de uma junção de hash. Dependendo de sua avaliação da situação, ele pode adicionar um filtro explícito para rejeitar linhas nulas na chave de junção. O efeito do Filtro nas contagens de linhas estimadas também é gravado no plano de execução, mas como a otimização baseada em custo já foi concluída, um custo para o Filtro não é calculado. Caso não seja óbvio, os custos de computação são um desperdício de esforço se todas as decisões baseadas em custos já tiverem sido tomadas.
O Filtro permanece diretamente na entrada de compilação em vez de ser enviado para a Verificação de Índice Agrupado porque a atividade de otimização principal foi concluída. As reescritas pós-otimização são efetivamente ajustes de última hora para um plano de execução concluído.
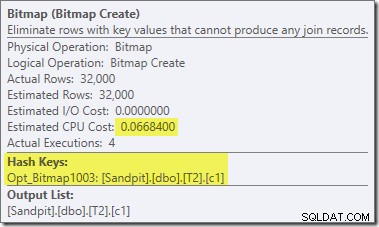
Uma segunda reescrita pós-otimização, bastante separada, é responsável pelo operador Bitmap no plano final (você deve ter notado que também estava faltando na saída 8607):
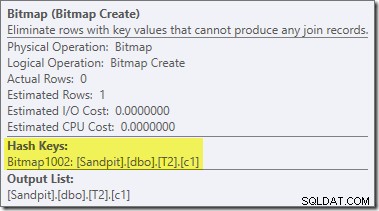
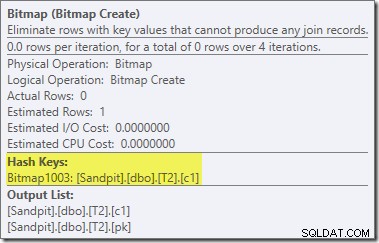
Este operador também tem um custo estimado zero para E/S e CPU. A outra coisa que o identifica como um operador introduzido por um ajuste tardio (em vez de durante a otimização baseada em custo) é que seu nome é Bitmap seguido por um número. Existem outros tipos de bitmaps introduzidos durante a otimização baseada em custo, como veremos um pouco mais adiante.
Por enquanto, o importante sobre esse bitmap é que ele registra os valores de c1 vistos durante a fase de construção da junção de hash. O bitmap concluído é enviado para o lado do teste da junção quando o hash passa da fase de construção para a fase do teste. O bitmap é usado para realizar a redução de semijunção antecipada, eliminando linhas do lado do probe que possivelmente não podem ser unidas. se você precisar de mais detalhes sobre isso, consulte meu artigo anterior sobre o assunto.
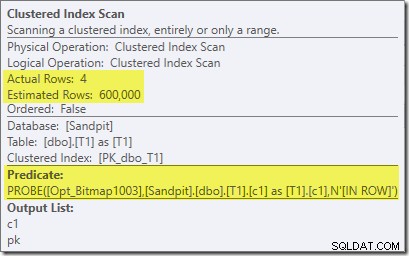
O segundo efeito do bitmap pode ser visto na varredura de índice clusterizado do lado do probe:
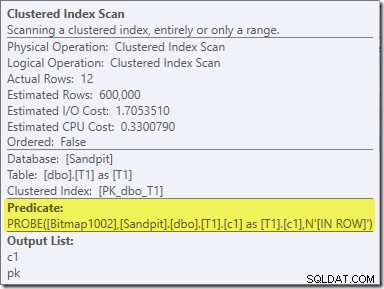
A captura de tela acima mostra o bitmap concluído sendo verificado como parte do Clustered Index Scan na tabela T1. Como a coluna de origem é um inteiro (um bigint também funcionaria), a verificação de bitmap é enviada por push até o mecanismo de armazenamento (conforme indicado pelo qualificador 'INROW') em vez de ser verificada pelo processador de consulta. De maneira mais geral, o bitmap pode ser aplicado a qualquer operador no lado da sonda, da central para baixo. Até que ponto o processador de consulta pode enviar o bitmap depende do tipo da coluna e da versão do SQL Server.
Para completar a análise das principais características deste plano de execução, precisamos olhar para o plano pós-execução ('real'):
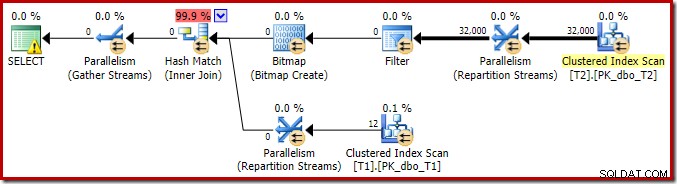
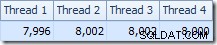
A primeira coisa a notar é a distribuição de linhas entre os encadeamentos entre a varredura T2 e a troca de Repartição Streams imediatamente acima dela. Em um teste, vi a seguinte distribuição em um sistema com quatro processadores lógicos:
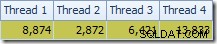
A distribuição não é particularmente uniforme, como é o caso de uma varredura paralela em um número relativamente pequeno de linhas, mas pelo menos todos os encadeamentos receberam algum trabalho. A distribuição de threads entre a mesma troca de Repartição Streams e o Filtro é muito diferente:
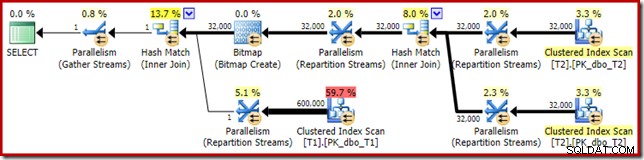
Isso mostra que todas as 32.000 linhas da tabela T2 foram processadas por um único encadeamento. Para ver por que, precisamos olhar para as propriedades de troca:

Essa troca, como a do lado de teste da junção de hash, precisa garantir que as linhas com os mesmos valores de chave de junção terminem na mesma instância da junção de hash. No DOP 4, há quatro junções de hash, cada uma com sua própria tabela de hash. Para resultados corretos, as linhas do lado da compilação e as linhas do lado da sonda com as mesmas chaves de junção devem chegar à mesma junção de hash; caso contrário, podemos verificar uma linha do lado do teste em relação à tabela de hash errada.
Em um plano paralelo de modo de linha, o SQL Server consegue isso reparticionando ambas as entradas usando a mesma função de hash nas colunas de junção. No presente caso, a junção está na coluna c1, portanto, as entradas são distribuídas entre os encadeamentos aplicando uma função de hash (tipo de particionamento:hash) à coluna de chave de junção (c1). O problema aqui é que a coluna c1 contém apenas um único valor – null – na tabela T2, então todas as 32.000 linhas recebem o mesmo valor de hash, então todas terminam no mesmo encadeamento.
A boa notícia é que nada disso realmente importa para esta consulta. O Filtro de reescrita pós-otimização elimina todas as linhas antes que muito trabalho seja feito. No meu laptop, a consulta acima é executada (não produzindo resultados, como esperado) em torno de 70 ms .
Juntar três tabelas
Para o segundo teste, adicionamos uma junção extra da tabela T2 a ela mesma em sua chave primária:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 -- New! ON T3.pk = T2.pk;
Isso não altera os resultados lógicos da consulta, mas altera o plano de execução:
Como esperado, a autojunção da tabela T2 em sua chave primária não afeta o número de linhas que se qualificam dessa tabela:
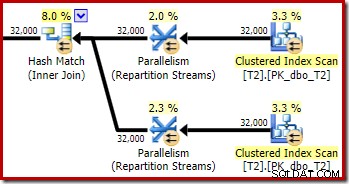
A distribuição de linhas entre os encadeamentos também é boa nesta seção de plano. Para as varreduras, é semelhante ao anterior porque a varredura paralela distribui linhas para encadeamentos sob demanda. A repartição das exchanges é baseada em um hash da chave de junção, que é a coluna pk desta vez. Dado o intervalo de diferentes valores de pk, a distribuição de threads resultante também é muito uniforme:
Voltando à seção mais interessante do plano estimado, existem algumas diferenças em relação ao teste de duas tabelas:

Mais uma vez, a troca do lado da construção acaba roteando todas as linhas para o mesmo encadeamento porque c1 é a chave de junção e, portanto, a coluna de particionamento para as trocas de Repartição Streams (lembre-se, c1 é nulo para todas as linhas na tabela T2).
Existem duas outras diferenças importantes nesta seção do plano em comparação com o teste anterior. Primeiro, não há filtro para remover linhas null-c1 do lado de compilação da junção de hash. A explicação para isso está ligada à segunda diferença – o Bitmap mudou, embora não seja óbvio na imagem acima:
Este é um Opt_Bitmap, não um Bitmap. A diferença é que esse bitmap foi introduzido durante a otimização baseada em custo, não por uma reescrita de última hora. O mecanismo que considera bitmaps otimizados está associado ao processamento de consultas de junção em estrela. A lógica de junção em estrela requer pelo menos três tabelas unidas, então isso explica por que um otimizado bitmap não foi considerado no exemplo de junção de duas tabelas.
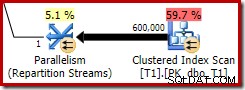
Esse bitmap otimizado tem um custo estimado de CPU diferente de zero e afeta diretamente o plano geral escolhido pelo otimizador. Seu efeito na estimativa de cardinalidade do lado da sonda pode ser visto no operador Repartition Streams:
Observe que o efeito de cardinalidade é visto na troca, mesmo que o bitmap seja eventualmente empurrado até o mecanismo de armazenamento ('INROW') assim como vimos no primeiro teste (mas observe a referência Opt_Bitmap agora):
O plano pós-execução ('real') é o seguinte:
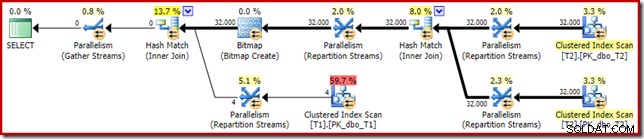
A eficácia prevista do bitmap otimizado significa que a reescrita pós-otimização separada para o filtro nulo não é aplicada. Pessoalmente, acho que isso é lamentável porque eliminar os nulos antecipadamente com um Filtro negaria a necessidade de construir o bitmap, preencher as tabelas de hash e executar a varredura aprimorada de bitmap da tabela T1. No entanto, o otimizador decide de outra forma e não há como discutir com ele neste caso.
Apesar da autojunção extra da tabela T2 e do trabalho extra associado ao filtro ausente, esse plano de execução ainda produz o resultado esperado (sem linhas) em pouco tempo. Uma execução típica no meu laptop leva cerca de 200 ms .
Alterando o tipo de dados
Para este terceiro teste, alteraremos o tipo de dados da coluna c1 em ambas as tabelas de inteiro para decimal. Não há nada de especial nessa escolha; o mesmo efeito pode ser visto com qualquer tipo numérico que não seja inteiro ou bigint.
ALTER TABLE dbo.T1 ALTER COLUMN c1 decimal(9,0) NULL; ALTER TABLE dbo.T2 ALTER COLUMN c1 decimal(9,0) NULL; ALTER INDEX PK_dbo_T1 ON dbo.T1 REBUILD WITH (MAXDOP = 1); ALTER INDEX PK_dbo_T2 ON dbo.T2 REBUILD WITH (MAXDOP = 1); UPDATE STATISTICS dbo.T1 WITH FULLSCAN; UPDATE STATISTICS dbo.T2 WITH FULLSCAN;
Reutilizando a consulta de junção de três junções:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk;
O plano de execução estimado parece muito familiar:
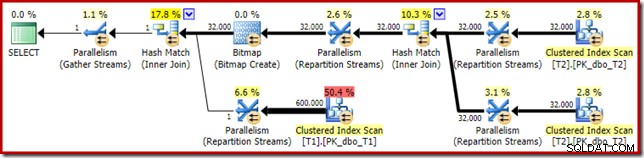
Além do fato de que o bitmap otimizado não pode mais ser aplicado 'INROW' pelo mecanismo de armazenamento devido à alteração do tipo de dados, o plano de execução é essencialmente idêntico. A captura abaixo mostra a mudança nas propriedades de varredura:
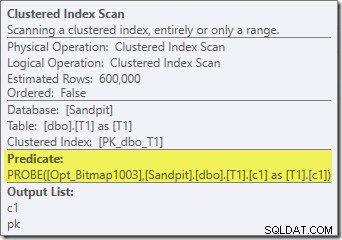
Infelizmente, o desempenho é bastante afetado. Esta consulta não é executada em 70 ms ou 200 ms, mas em cerca de 20 minutos . No teste que produziu o seguinte plano de pós-execução, o tempo de execução foi de 22 minutos e 29 segundos:

A diferença mais óbvia é que o Clustered Index Scan na tabela T1 retorna 300.000 linhas mesmo após a aplicação do filtro de bitmap otimizado. Isso faz algum sentido, pois o bitmap é construído em linhas que contêm apenas nulos na coluna c1. O bitmap remove as linhas não nulas da varredura T1, deixando apenas as 300.000 linhas com valores nulos para c1. Lembre-se, metade das linhas em T1 são nulas.
Mesmo assim, parece estranho que juntar 32.000 linhas com 300.000 linhas demore mais de 20 minutos. Caso você esteja se perguntando, um núcleo de CPU foi atrelado a 100% para toda a execução. A explicação para esse baixo desempenho e uso extremo de recursos se baseia em algumas ideias que exploramos anteriormente:
Já sabemos, por exemplo, que apesar dos ícones de execução paralela, todas as linhas de T2 acabam na mesma thread. Como lembrete, a junção de hash paralela no modo de linha requer reparticionamento nas colunas de junção (c1). Todas as linhas de T2 têm o mesmo valor – null – na coluna c1, então todas as linhas terminam no mesmo thread. Da mesma forma, todas as linhas de T1 que passam pelo filtro de bitmap também têm null na coluna c1, portanto, elas também são reparticionadas no mesmo thread. Isso explica por que um único núcleo faz todo o trabalho.
Ainda pode parecer irracional que o hash unindo 32.000 linhas com 300.000 linhas demore 20 minutos, especialmente porque as colunas de junção em ambos os lados são nulas e não serão unidas de qualquer maneira. Para entender isso, precisamos pensar em como essa junção de hash funciona.
A entrada de compilação (as 32.000 linhas) cria uma tabela de hash usando a coluna de junção, c1. Como cada linha do lado da compilação contém o mesmo valor (null) para a coluna de junção c1, isso significa que todas as 32.000 linhas terminam no mesmo bucket de hash. Quando a junção de hash alterna para sondagem de correspondências, cada linha do lado da sondagem com uma coluna c1 nula também gera hash para o mesmo bucket. A junção de hash deve verificar todas as 32.000 entradas nesse bucket para uma correspondência.
A verificação das 300.000 linhas do probe resulta em 32.000 comparações feitas 300.000 vezes. Este é o pior caso para uma junção de hash:todas as linhas laterais de compilação hash para o mesmo bucket, resultando no que é essencialmente um produto cartesiano. Isso explica o longo tempo de execução e a utilização constante de 100% do processador, pois o hash segue a longa cadeia de baldes de hash.
Esse desempenho ruim ajuda a explicar por que existe a reescrita pós-otimização para eliminar nulos na entrada de compilação para uma junção de hash. É lamentável que o Filtro não tenha sido aplicado neste caso.
Soluções alternativas
O otimizador escolhe essa forma de plano porque estima incorretamente que o bitmap otimizado filtrará todas as linhas da tabela T1. Embora essa estimativa seja mostrada nos Fluxos de Repartição em vez da Varredura de Índice Agrupado, essa ainda é a base da decisão. Como lembrete, aqui está a seção relevante do plano de pré-execução novamente:
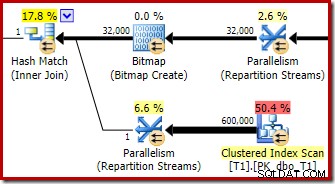
Se essa fosse uma estimativa correta, não levaria muito tempo para processar a junção de hash. É lamentável que a estimativa de seletividade para o bitmap otimizado esteja tão errada quando o tipo de dados não é um simples inteiro ou bigint. Parece que um bitmap construído em uma chave inteira ou bigint também é capaz de filtrar linhas nulas que não podem ser unidas. Se esse for realmente o caso, esse é um dos principais motivos para preferir colunas de junção inteiras ou bigint.
As soluções alternativas a seguir são amplamente baseadas na ideia de eliminar os bitmaps otimizados problemáticos.
Execução em série
Uma maneira de evitar que bitmaps otimizados sejam considerados é exigir um plano não paralelo. Operadores de bitmap de modo de linha (otimizados ou não) são vistos apenas em planos paralelos:
SELECT T1.pk
FROM
(
dbo.T2 AS T2
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
)
JOIN dbo.T1 AS T1
ON T1.c1 = T2.c1
OPTION (MAXDOP 1, FORCE ORDER); Essa consulta é expressa usando uma sintaxe ligeiramente diferente com uma dica FORCE ORDER para gerar uma forma de plano que é mais facilmente comparável com os planos paralelos anteriores. A característica essencial é a dica MAXDOP 1.
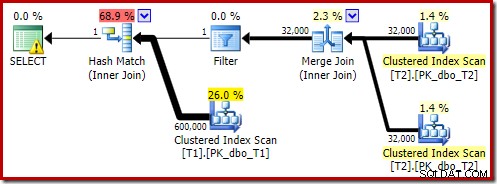
Esse plano estimado mostra o filtro de reescrita pós-otimização sendo restabelecido:
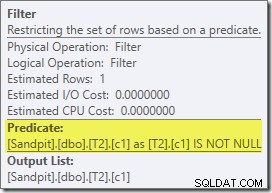
A versão pós-execução do plano mostra que ele filtra todas as linhas da entrada de compilação, o que significa que a varredura do lado do probe pode ser totalmente ignorada:
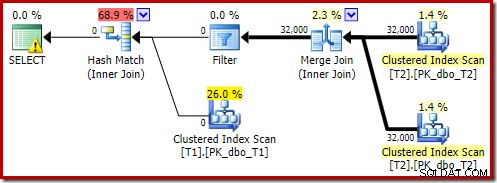
Como seria de esperar, esta versão da consulta é executada muito rapidamente – cerca de 20ms em média para mim. Podemos obter um efeito semelhante sem a dica FORCE ORDER e a reescrita da consulta:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (MAXDOP 1);
O otimizador escolhe uma forma de plano diferente neste caso, com o Filtro colocado diretamente acima da varredura de T2:
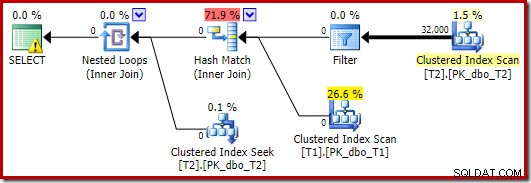
Isso é executado ainda mais rápido – em cerca de 10ms – como seria de esperar. Naturalmente, isso não seria uma boa escolha se o número de linhas presentes (e juntáveis) fosse muito maior.
Desativando bitmaps otimizados
Não há dica de consulta para desativar bitmaps otimizados, mas podemos obter o mesmo efeito usando alguns sinalizadores de rastreamento não documentados. Como sempre, isso é apenas para o valor dos juros; você não gostaria de usá-los em um sistema ou aplicativo real:
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYTRACEON 7497, QUERYTRACEON 7498);
O plano de execução resultante é:
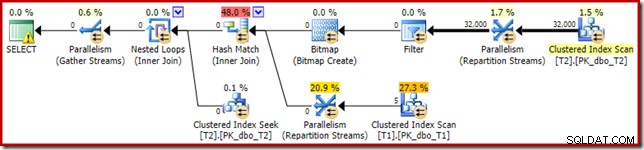
O Bitmap existe um bitmap de reescrita pós-otimização, não um bitmap otimizado:
Observe as estimativas de custo zero e o nome do Bitmap (em vez de Opt_Bitmap). sem um bitmap otimizado para distorcer as estimativas de custo, a reescrita pós-otimização para incluir um filtro de rejeição de nulo é ativada. Este plano de execução é executado em cerca de 70 ms .
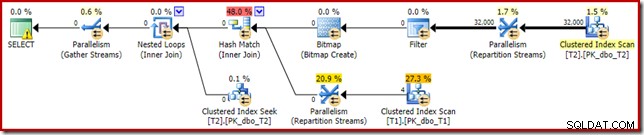
O mesmo plano de execução (com Filtro e Bitmap não otimizado) também pode ser produzido desativando a regra do otimizador responsável por gerar planos de bitmap de junção em estrela (novamente, estritamente não documentados e não para uso no mundo real):
SELECT T1.pk FROM dbo.T1 AS T1 JOIN dbo.T2 AS T2 ON T2.c1 = T1.c1 JOIN dbo.T2 AS T3 ON T3.pk = T2.pk OPTION (QUERYRULEOFF StarJoinToHashJoinsWithBitmap);
Incluindo um filtro explícito
Esta é a opção mais simples, mas só se pensaria em fazê-la se estivesse ciente das questões discutidas até agora. Agora que sabemos que precisamos eliminar nulos de T2.c1, podemos adicionar isso diretamente à consulta:
SELECT T1.pk
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON T2.c1 = T1.c1
JOIN dbo.T2 AS T3
ON T3.pk = T2.pk
WHERE
T2.c1 IS NOT NULL; -- New! O plano de execução estimado resultante talvez não seja exatamente o que você espera:
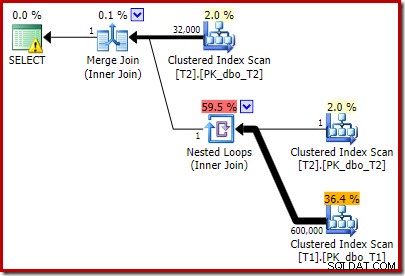
O predicado extra que adicionamos foi enviado para o meio Clustered Index Scan de T2:
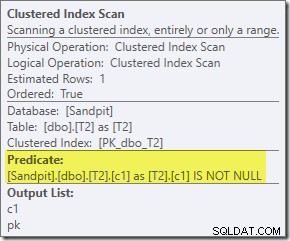
O plano pós-execução é:
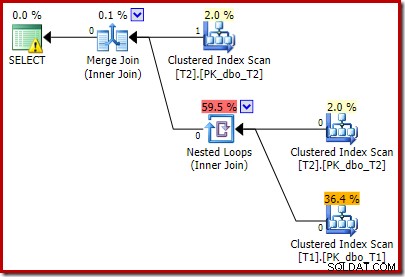
Observe que o Merge Join é encerrado após ler uma linha de sua entrada superior e, em seguida, não encontra uma linha em sua entrada inferior, devido ao efeito do predicado que adicionamos. A varredura de índice clusterizado da tabela T1 nunca é executada, porque a junção de loops aninhados nunca obtém uma linha em sua entrada de condução. Este formulário de consulta final é executado em um ou dois milissegundos.
Considerações finais
Este artigo cobriu uma boa quantidade de terreno para explorar alguns comportamentos de otimizador de consulta menos conhecidos e explicar os motivos para o desempenho extremamente ruim da junção de hash em um caso específico.
Pode ser tentador perguntar por que o otimizador não adiciona rotineiramente filtros de rejeição de nulo antes das junções de igualdade. Pode-se apenas supor que isso não seria benéfico em casos bastante comuns. A maioria das junções não deve encontrar muitas rejeições null =null, e adicionar predicados rotineiramente pode rapidamente se tornar contraproducente, principalmente se muitas colunas de junção estiverem presentes. Para a maioria das junções, rejeitar nulos dentro do operador de junção é provavelmente uma opção melhor (de uma perspectiva de modelo de custo) do que introduzir um Filtro explícito.
Parece que há um esforço para impedir que os piores casos se manifestem por meio da reescrita pós-otimização projetada para rejeitar linhas de junção nula antes que elas atinjam a entrada de compilação de uma junção de hash. Parece que existe uma interação infeliz entre o efeito de filtros de bitmap otimizados e a aplicação dessa reescrita. Também é lamentável que, quando esse problema de desempenho ocorre, é muito difícil diagnosticar apenas a partir do plano de execução.
Por enquanto, a melhor opção parece estar ciente desse possível problema de desempenho com junções de hash em colunas anuláveis e adicionar predicados explícitos de rejeição de nulo (com um comentário!) para garantir que um plano de execução eficiente seja produzido, se necessário. Usar uma dica MAXDOP 1 também pode revelar um plano alternativo com o filtro revelador presente.
Como regra geral, as consultas que se unem em colunas do tipo inteiro e procuram os dados existentes tendem a se adequar melhor ao modelo do otimizador e aos recursos do mecanismo de execução do que as alternativas.
Agradecimentos
Quero agradecer ao SQL_Sasquatch (@sqL_handLe) por sua permissão para responder ao seu artigo original com uma análise técnica. Os dados de amostra usados aqui são fortemente baseados nesse artigo.
Também quero agradecer a Rob Farley (blog | twitter) por nossas discussões técnicas ao longo dos anos, e especialmente uma em janeiro de 2015, onde discutimos as implicações de predicados extras de rejeição nula para equi-joins. Rob escreveu sobre tópicos relacionados várias vezes, inclusive em Predicados Inversos – olhe para os dois lados antes de cruzar.