Considerando o grande caso de uso atual de um banco de dados para recuperar dados, torna-se muito importante que seu desempenho seja muito alto e isso só pode ser alcançado se os dados forem buscados da maneira mais eficiente possível do armazenamento. Houve muitas invenções e implementações bem-sucedidas feitas para alcançar o mesmo. Uma das abordagens bem conhecidas adotadas pela maioria dos bancos de dados é ter um índice na tabela.
O que é um índice de banco de dados?
Índice de banco de dados, como o nome sugere, mantém um índice para os dados reais e, portanto, melhora o desempenho para recuperar dados da tabela real. Em uma terminologia mais de banco de dados, o índice permite buscar a página contendo dados indexados em uma travessia mínima, pois os dados são classificados em uma ordem específica. O benefício do índice vem ao custo de espaço de armazenamento adicional para gravar dados adicionais. Os índices são específicos da tabela subjacente e consistem em uma ou mais chaves (ou seja, uma ou mais colunas da tabela especificada). Existem basicamente dois tipos de arquitetura de índice
- Índice clusterizado – os dados do índice são armazenados junto com outras partes dos dados e os dados são classificados com base na chave do índice. No máximo, pode haver apenas um índice nesta categoria para uma tabela especificada.
- Índice não agrupado – os dados do índice são armazenados separadamente e possuem um ponteiro para o armazenamento onde a outra parte dos dados é armazenada. Isso também é conhecido como índice secundário. Pode haver quantos índices dessa categoria você quiser em uma tabela especificada.
Existem várias estruturas de dados usadas para implementação de índices, algumas das amplamente adotadas pela maioria dos bancos de dados são B-Tree e Hash.
O que é um índice PostgreSQL?
O PostgreSQL suporta apenas índices não clusterizados. Isso significa dados de índice e dados completos (aqui referidos como dados de heap ) são armazenados em um armazenamento separado. Índices não agrupados são como “Tabela de Conteúdo” em qualquer documento, em que primeiro verificamos o número da página e depois verificamos esses números de página para ler todo o conteúdo. Para obter os dados completos com base em um índice, ele mantém um ponteiro para os dados de heap correspondentes. É o mesmo que depois de saber o número da página, ele precisa ir até essa página e obter o conteúdo real da página.
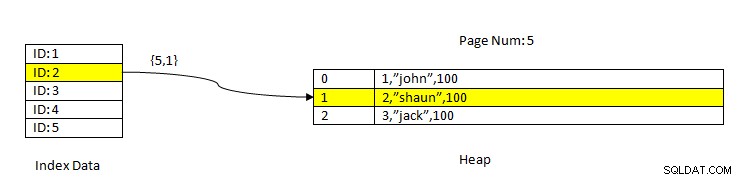 PostgreSQL:Dados lidos usando Index
PostgreSQL:Dados lidos usando Index Por exemplo, considere uma tabela com três colunas e um índice na coluna ID . Para LER os dados com base na chave ID=2, primeiro, os dados indexados com o valor de ID 2 são pesquisados. Ele contém um ponteiro (chamado de Item Pointer) em termos do número da página (ou seja, número do bloco) e deslocamento dos dados nessa página. No exemplo atual, o índice aponta para a página número 5 e o segundo item de linha na página que, por sua vez, mantém o deslocamento para todos os dados (2,"Shaun",100). Observe que os dados inteiros também contêm os dados indexados, o que significa que os mesmos dados são repetidos em dois armazenamentos.
Como o INDEX ajuda a melhorar o desempenho? Bem, para selecionar qualquer registro INDEX, ele não varre todas as páginas sequencialmente, apenas precisa varrer parcialmente algumas das páginas usando a estrutura de dados Index subjacente. Mas há uma reviravolta, já que cada registro encontrado a partir de dados de índice, ele precisa procurar dados inteiros em dados de heap, o que causa muitas E/S aleatórias e é considerado um desempenho mais lento que E/S sequencial. Portanto, somente se uma pequena porcentagem de registros estiver sendo selecionada (o que foi decidido com base no custo do otimizador do PostgreSQL), somente o PostgreSQL escolherá o Index Scan, caso contrário, mesmo que haja um índice na tabela, ele continuará usando o Sequence Scan.
Em resumo, embora a criação do índice acelere o desempenho, ele deve ser escolhido com cuidado, pois tem sobrecarga em termos de armazenamento e desempenho INSERT degradado.
Agora podemos nos perguntar, caso precisemos apenas da parte do índice dos dados, podemos buscar apenas na página de armazenamento do índice? Bem, a resposta para isso está diretamente relacionada a como o MVCC funciona no armazenamento de índice, conforme explicado a seguir.
Usando MVCC para indexação
Assim como as páginas Heap, a página de índice mantém várias versões da tupla de índice, mas não mantém as informações de visibilidade. Conforme explicado no meu MVCC anterior blog, para decidir a versão visível adequada das tuplas, é necessário comparar a transação. A transação que inseriu/atualizou/excluiu a tupla é mantida junto com a tupla de heap, mas a mesma não é mantida com a tupla de índice. Isso é feito puramente para economizar armazenamento e é uma troca entre espaço e desempenho.
Agora voltando à pergunta original, já que as informações de visibilidade na tupla Index não estão lá, é necessário consultar a tupla heap correspondente para ver se os dados selecionados estão visíveis. Portanto, mesmo que outras partes dos dados da tupla de heap não sejam necessárias, ainda é necessário acessar as páginas de heap para verificar a visibilidade. Mas, novamente, há uma torção no caso de todas as tuplas em uma determinada página (página apontada pelo índice, ou seja, ItemPointer) serem visíveis, então não é necessário consultar cada item da página Heap para "verificação de visibilidade" e, portanto, os dados podem ser retornados apenas da página Índice. Este caso especial é chamado de “Varredura somente de índice”. Para dar suporte a isso, o PostgreSQL mantém um mapa de visibilidade para cada página para verificar a visibilidade no nível da página.
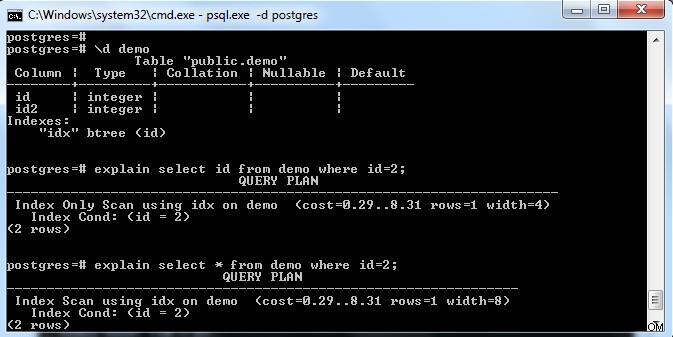
Conforme mostrado na imagem acima, há um índice na tabela “demo” com uma chave na coluna “id”. Se tentarmos selecionar apenas o campo de índice (ou seja, id), ele escolheu o “Index Only Scan” (considerando a página de referência totalmente visível).
Índice agrupado
Não há suporte de índice clusterizado direto no PostgreSQL, mas há uma maneira indireta de obter o mesmo parcialmente. Isso é obtido pelos comandos SQL abaixo:
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]O primeiro comando instrui o banco de dados a agrupar uma tabela (ou seja, classificar a tabela) usando o índice fornecido. Este índice já deveria ter sido criado. Este agrupamento é apenas uma operação e seu impacto não permanece após a operação subsequente nesta tabela, ou seja, se mais registros forem inseridos/atualizados, a tabela pode não permanecer ordenada. Se o usuário ainda precisar manter a tabela agrupada (ordenada), ele poderá usar o primeiro comando sem fornecer um nome de índice.
O segundo comando é útil apenas para reagrupar a tabela (ou seja, a tabela que já foi agrupada usando algum índice). Este comando agrupa novamente todas as tabelas no banco de dados atual visíveis para o usuário conectado atual.
Por exemplo, na figura abaixo, o primeiro SELECT retorna registros em ordem não classificada, pois não há índice clusterizado. Mesmo que já exista um índice não clusterizado, os registros são selecionados na área de heap onde os registros não são classificados.
O segundo SELECT retorna os registros ordenados pela coluna “id” conforme foi agrupado usando o índice contendo a coluna “id”.
O terceiro SELECT retorna registros parciais em ordem de classificação, mas os registros recém-inseridos não são classificados. O quarto SELECT retorna novamente todos os registros em ordem de classificação, pois a tabela foi agrupada novamente
 Comando de cluster PostgreSQL
Comando de cluster PostgreSQL Tipo de índice
O PostgreSQL fornece vários tipos de índices como abaixo:
- Árvore B
- Hash
- GIST
- GIN
- BRIN
Cada tipo de índice implementa diferentes tipos de estrutura de dados subjacente, que é mais adequada para diferentes tipos de consultas. Por padrão, o índice B-Tree é criado, que é um índice amplamente utilizado. Os detalhes de cada tipo de índice serão abordados em um blog futuro.
Diversos:índice parcial e de expressão
Discutimos apenas sobre índices em uma ou mais colunas de uma tabela, mas existem outras duas maneiras de criar índices no PostgreSQL
- Índice parcial: Índice parcial é um índice construído usando o subconjunto de uma coluna de chave para uma tabela específica. O subconjunto é definido pela expressão condicional fornecida durante a criação do índice. Assim, com o índice parcial, o espaço de armazenamento para armazenar dados de índice é salvo. Portanto, o usuário deve escolher a condição de tal forma que esses valores não sejam muito comuns, pois para valores mais frequentes (comuns) de qualquer maneira, a varredura de índice não será escolhida. O restante da funcionalidade permanece o mesmo de um índice normal. Exemplo:índice parcial
- Índice de expressão: Os índices de expressão oferecem outro tipo de flexibilidade no PostgreSQL. Todos os índices discutidos até agora, incluindo índices parciais, estão em um conjunto específico de colunas. Mas e se uma consulta envolver o acesso de uma tabela baseada na expressão (expressão envolvendo uma ou mais colunas), sem um índice de expressão ela não escolherá varredura de índice. Portanto, para acessar rapidamente esse tipo de consulta, o PostgreSQL permite criar um índice em uma expressão. O restante da funcionalidade permanece o mesmo de um índice normal.
 Exemplo:índice de expressão
Exemplo:índice de expressão
Armazenamento de índice no InnoDB
O uso e a funcionalidade do Index são basicamente os mesmos do PostgreSQL, com uma grande diferença em termos de Clustered Index.
O InnoDB suporta duas categorias de índices:
- Índice agrupado
- Índice secundário
Índice agrupado
Clustered Index é um tipo especial de índice no InnoDB. Aqui, os dados indexados não são armazenados separadamente, mas fazem parte de todos os dados da linha. Em outras palavras, o índice clusterizado apenas força os dados da tabela a serem classificados fisicamente usando a coluna chave do índice. Pode ser considerado como “Dicionário”, onde os dados são classificados com base no alfabeto.
Como o índice clusterizado classifica as linhas usando uma chave de índice, pode haver apenas um índice clusterizado. Além disso, deve haver um índice clusterizado, pois o InnoDB o usa para manipular dados de maneira otimizada durante várias operações de dados.
O índice clusterizado é criado automaticamente (como parte da criação da tabela) usando uma das colunas da tabela conforme a prioridade abaixo:
- Usar a chave primária se a chave primária for mencionada como parte da criação da tabela.
- Escolhe qualquer coluna exclusiva em que todas as colunas-chave NÃO sejam NULL.
- Caso contrário, gera internamente um índice clusterizado oculto em uma coluna do sistema que contém o ID de cada linha.
Ao contrário do índice não clusterizado do PostgreSQL, o InnoDB acessa uma linha usando o índice clusterizado mais rapidamente porque a pesquisa do índice leva diretamente à página com todos os dados da linha e, portanto, evita E/S aleatória.
Também obter os dados da tabela em ordem de classificação usando o índice clusterizado é muito rápido, pois todos os dados já estão classificados e também os dados inteiros estão disponíveis.
Índice secundário
O índice criado explicitamente no InnoDB é considerado um índice Secundário, que é semelhante ao índice não clusterizado do PostgreSQL. Cada registro no armazenamento de índice secundário contém colunas de chave primária das linhas (que foram usadas para criar o índice clusterizado) e também as colunas especificadas para criar um índice secundário.
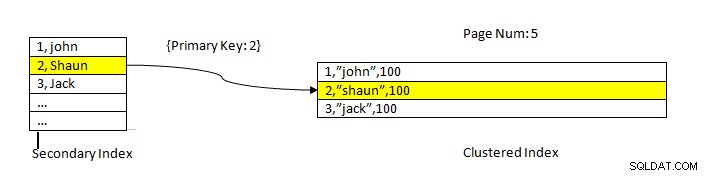 InnoDB:Dados lidos usando índice
InnoDB:Dados lidos usando índice A busca de dados usando um índice secundário é semelhante ao caso do PostgreSQL, exceto que a pesquisa de índice secundário do InnoDB fornece uma chave primária como um ponteiro para buscar os dados restantes do índice clusterizado.
Por exemplo, conforme mostrado na imagem acima, o índice clusterizado está na coluna ID, então os dados da tabela são classificados pelo mesmo. O índice secundário está na coluna “nome ”, então, como podemos ver, o índice secundário tem valor de ID e nome. Depois de pesquisar usando o índice secundário, ele encontra o slot apropriado com o valor da chave correspondente. Em seguida, a chave primária correspondente é usada para se referir à parte restante dos dados do índice clusterizado.
MVCC para Índice
O índice clusterizado MVCC usa o tradicional InnoDB Undo Model (na verdade o mesmo que o MVCC de dados inteiros, pois o índice clusterizado nada mais é do que dados inteiros).
Mas o uso do índice MVCC secundário é um pouco diferente para manter o MVCC. Na atualização do índice secundário, a entrada do índice antigo é marcada para exclusão e novos registros são inseridos no mesmo armazenamento, ou seja, UPDATE não está no local. Finalmente, as entradas de índice antigas são limpas. Até agora você deve ter notado que o índice secundário MVCC do InnoDB é quase o mesmo que o modelo MVCC do PostgreSQL.
Tipo de índice
O InnoDB suporta apenas o tipo de índice B-Tree e, portanto, não precisa ser especificado durante a criação do índice.
Diversos:índices de hash adaptáveis
Como mencionado na seção anterior, apenas o índice do tipo B-Tree é suportado pelo InnoDB, mas há uma reviravolta. O InnoDB tem a funcionalidade de detectar automaticamente se a consulta pode se beneficiar da construção de um índice de hash e também dados inteiros da tabela podem caber na memória, então ele o faz automaticamente.
O índice de hash é construído usando o índice B-Tree existente, dependendo da consulta. Se houver vários índices B-Tree secundários, ele escolherá aquele que se qualifica de acordo com a consulta. O índice de hash criado não está completo, apenas cria um índice parcial de acordo com o padrão de uso de dados.
Este é um dos recursos realmente poderosos para melhorar dinamicamente o desempenho da consulta.
Conclusão
O uso de qualquer índice em qualquer banco de dados é realmente útil para melhorar o desempenho de READ, mas ao mesmo tempo degrada o desempenho de INSERT/UPDATE, pois precisa gravar dados adicionais. Portanto, o índice deve ser escolhido com muita sabedoria e deve ser criado somente se as chaves de índice estiverem sendo usadas como predicado para buscar dados.
O InnoDB fornece um recurso muito bom em termos de índice clusterizado, que pode ser muito útil dependendo dos casos de uso. Além disso, sua indexação de hash adaptável é muito poderosa.
Enquanto o PostgreSQL fornece vários tipos de índices, que podem realmente dar opções de alcance de recursos e um ou todos podem ser usados dependendo do caso de uso do negócio. Também os índices parciais e de expressão são bastante úteis dependendo do caso de uso.



