Observação:esta postagem foi publicada originalmente apenas em nosso eBook, Técnicas de alto desempenho para SQL Server, Volume 4. Você pode descobrir mais sobre nossos eBooks aqui.
Recebo regularmente a pergunta:"Por onde começo quando se trata de tentar ajustar uma instância do SQL Server?" Minha primeira resposta é perguntar a eles sobre a configuração de sua instância. Se certas coisas não estiverem configuradas corretamente, começar a olhar para consultas de longa duração ou de alto custo imediatamente pode ser um esforço desperdiçado.
Eu escrevi sobre coisas comuns que os administradores perdem, onde compartilho muitas das configurações que os administradores devem alterar de uma instalação padrão do SQL Server. Para itens relacionados ao desempenho, digo a eles que devem verificar o seguinte:
- Configurações de memória
- Atualizando estatísticas
- Manutenção do índice
- MAXDOP e limite de custo para paralelismo
- práticas recomendadas do tempdb
- Otimize para cargas de trabalho ad hoc
Depois de passar pelos itens de configuração, pergunto se eles examinaram as estatísticas de arquivo e espera, bem como consultas de alto custo. Na maioria das vezes, a resposta é “não” – com uma explicação de que eles não têm certeza de como encontrar essa informação.
Normalmente, a conformidade comum quando alguém afirma que precisa ajustar um SQL Server é que ele está lento. O que significa lento? É um determinado relatório, uma aplicação específica, ou tudo? Começou a acontecer ou piorou com o tempo? Começo fazendo as perguntas usuais de triagem sobre o que a memória, a CPU e a utilização do disco são comparadas a quando as coisas estão normais, o problema começou a acontecer e o que mudou recentemente. A menos que o cliente esteja capturando uma linha de base, ele não tem métricas para comparar para saber se as estatísticas atuais são anormais.
Quase todo SQL Server em que trabalho hospeda mais de um banco de dados de usuário. Quando um cliente relata que o SQL Server está lento, na maioria das vezes ele está preocupado com um aplicativo específico que está causando problemas para seus clientes. Uma reação automática é focar imediatamente nesse banco de dados específico, mas muitas vezes outro processo pode estar consumindo recursos valiosos e o banco de dados do aplicativo está sendo afetado. Por exemplo, se você tem um grande banco de dados de relatórios e alguém iniciou um grande relatório que satura o disco, aumenta a CPU e libera o cache do plano, pode apostar que os outros bancos de dados do usuário ficariam lentos enquanto esse relatório estivesse sendo gerado.
Eu sempre gosto de começar olhando as estatísticas do arquivo. Para SQL Server 2005 e superior, você pode consultar a DMV sys.dm_io_virtual_file_stats para obter estatísticas de E/S para cada arquivo de dados e log. Este DMV substituiu a função fn_virtualfilestats. Para capturar as estatísticas do arquivo, gosto de usar um script que Paul Randal montou:capturando latências de E/S por um período de tempo. Este script capturará uma linha de base e, 30 minutos depois (a menos que você altere a duração na seção WAITFOR DELAY), capturará as estatísticas e calculará os deltas entre elas. O script de Paul também faz um pouco de matemática para determinar as latências de leitura e gravação, o que torna muito mais fácil para nós ler e entender.
No meu laptop, restaurei uma cópia do banco de dados AdventureWorks2014 em uma unidade USB para que eu tivesse velocidades de disco mais lentas; Em seguida, iniciei um processo para gerar uma carga contra ele. Você pode ver os resultados abaixo, onde minha latência de gravação para meu arquivo de dados é de 240ms e a latência de gravação para meu arquivo de log é de 46ms. Latências tão altas são problemáticas.
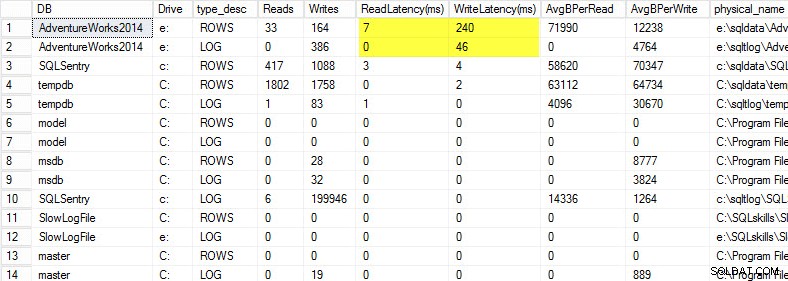
Qualquer coisa acima de 20ms deve ser considerada ruim, como compartilhei em um post anterior:monitorando a latência de leitura/gravação. Minha latência de leitura é decente, mas o banco de dados AdventureWorks2014 está sofrendo com gravações lentas. Nesse caso, eu investigaria o que está gerando as gravações, além de investigar o desempenho do meu subsistema de E/S. Se isso fosse latências de leitura excessivamente altas, eu começaria a investigar o desempenho da consulta (por que está fazendo tantas leituras, por exemplo, de índices ausentes), bem como o desempenho geral do subsistema de E/S.
É importante conhecer o desempenho geral do seu subsistema de E/S, e a melhor maneira de saber do que ele é capaz é comparando-o. Glenn Berry fala sobre isso em seu artigo analisando o desempenho de E/S para SQL Server. Glenn explica latência, IOPS e taxa de transferência e mostra o CrystalDiskMark, que é uma ferramenta gratuita que você pode usar para basear seu armazenamento.
Depois de descobrir o desempenho das estatísticas do arquivo, gosto de ver as estatísticas de espera usando o DMV sys.dm_os_wait_stats, que retorna informações sobre todas as esperas que ocorreram. Para isso, recorro a outro script que Paul Randal fornece em sua captura de estatísticas de espera por um período de tempo no blog. O roteiro de Paul faz um pouco de matemática para nós novamente, mas, mais importante, exclui muitas das esperas benignas com as quais normalmente não nos importamos. Este script também tem um WAITFOR DELAY e está definido para 30 minutos. Ler as estatísticas de espera pode ser um pouco mais complicado:você pode ter esperas que parecem altas com base na porcentagem, mas a espera média é tão baixa que não é nada para se preocupar.
Iniciei o mesmo processo de carregamento e capturei minhas estatísticas de espera, que mostrei abaixo. Para obter explicações sobre muitos desses tipos de espera, você pode ler outra das postagens do blog de Paul, estatísticas de espera ou, por favor, me diga onde dói, além de algumas de suas postagens neste blog.
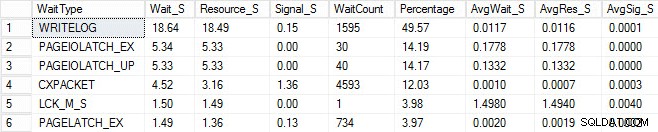
Nesta saída artificial, as esperas PAGEIOLATCH podem estar indicando um gargalo com meu subsistema de E/S, mas também podem ser um problema de memória, buscas por varreduras de tabela ou uma série de outros problemas. No meu caso, sabemos que é um problema de disco, pois estou armazenando o banco de dados em um pendrive. O tempo de espera LCK_M_S é muito alto, porém há apenas uma instância da espera. Meu WRITELOG também está mais alto do que eu gostaria de ver, mas é compreensível sabendo dos problemas de latência com o pendrive. Isso também mostra as esperas do CXPACKET, e seria fácil ter uma reação automática e pensar que você tem um problema de paralelismo/MAXDOP, no entanto, o contador AvgWait_S está muito baixo. Tenha cuidado ao usar esperas para solução de problemas. Deixe-o ser um guia para lhe dizer coisas que não são o problema, além de lhe dar uma direção de onde procurar por problemas. A solução de problemas adequada é correlacionar comportamentos de várias áreas para diminuir o problema.
Depois de examinar o arquivo e esperar as estatísticas, começo a investigar as consultas de alto custo com base nos problemas que encontrei. Para isso, recorro às Consultas de Informações de Diagnóstico de Glenn Berry. Esses conjuntos de consultas são os scripts que muitos consultores usam. Glenn e a comunidade estão constantemente fornecendo atualizações para torná-las o mais informativas e robustas possível. Uma das minhas consultas favoritas são as principais consultas em cache por contagem de execução. Adoro encontrar consultas ou procedimentos armazenados que tenham alta execução_contagem juntamente com alto total_leituras_lógicas. Se essas consultas tiverem oportunidades de ajuste, você poderá fazer uma grande diferença para o servidor rapidamente. Também estão incluídos nos scripts os principais SPs em cache por total de leituras lógicas e os principais SPs em cache por total de leituras físicas. Ambos são bons para procurar altas leituras com altas contagens de execução, para que você possa reduzir o número de E/Ss.
Além dos scripts de Glenn, gosto de usar o sp_whoisactive de Adam Machanic para ver o que está sendo executado no momento.
Há muito mais no ajuste de desempenho do que apenas olhar para estatísticas de arquivo e espera e consultas de alto custo, mas é por aí que gosto de começar. É uma maneira de fazer uma triagem rápida de um ambiente para começar a determinar o que está causando o problema. Não existe uma maneira totalmente infalível de ajustar:o que todo DBA de produção precisa é de uma lista de verificação de coisas a serem eliminadas e uma coleção realmente boa de scripts a serem executados para analisar a integridade do sistema. Ter uma linha de base é a chave para descartar rapidamente o comportamento normal versus anormal. Minha boa amiga Erin Stellato tem um curso inteiro sobre Pluralsight chamado SQL Server:Benchmarking and Baselining se você precisar de ajuda para configurar e capturar sua linha de base.
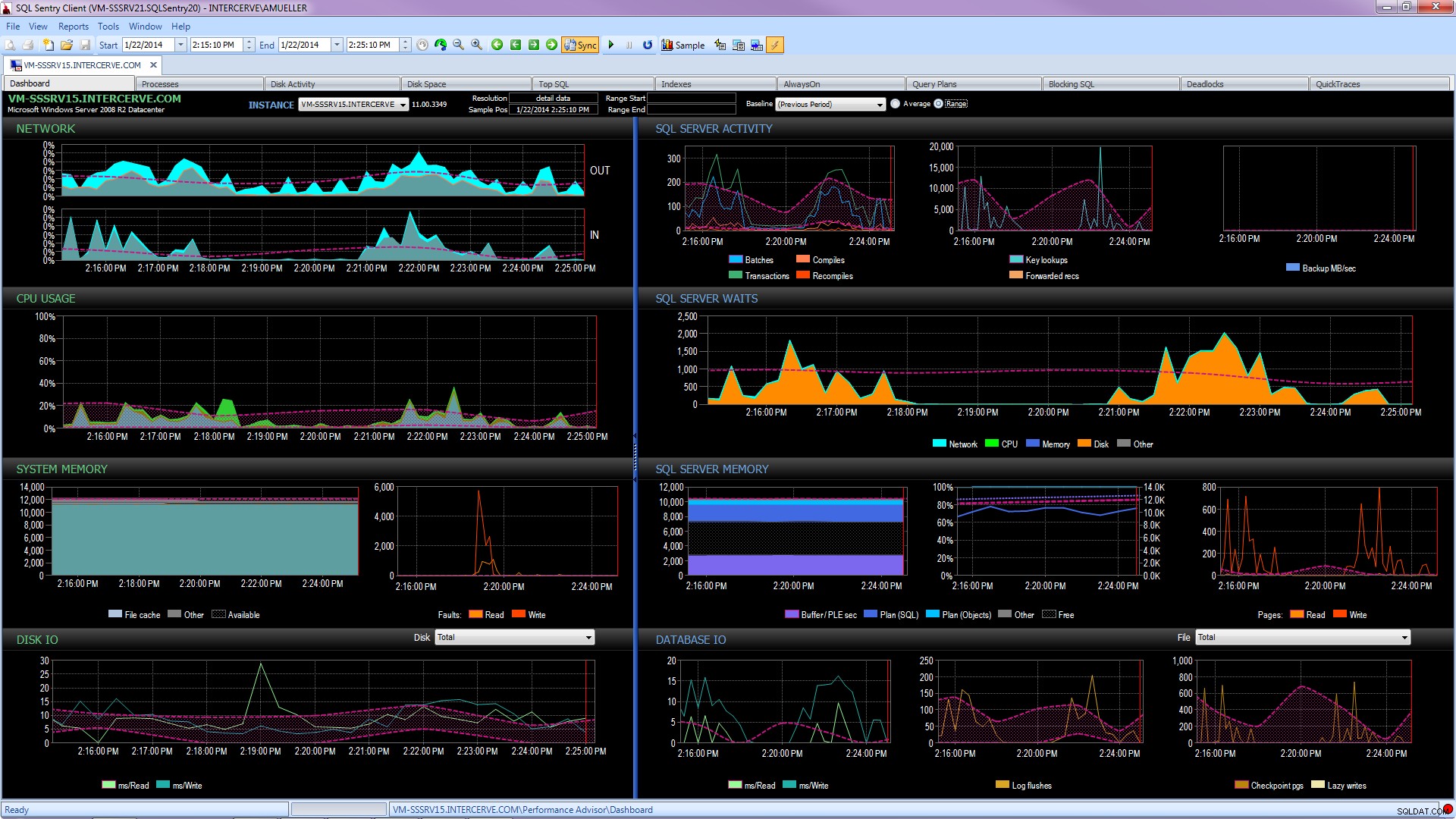
Melhor ainda, obtenha uma ferramenta de última geração, como o SQL Sentry Performance Advisor, que não apenas coletará e armazenará informações históricas para criação de perfil e tendências, e dará acesso fácil a todos os detalhes mencionados acima e muito mais, mas também fornecerá a capacidade de comparar a atividade com linhas de base embutidas ou definidas pelo usuário, manter índices com eficiência sem levantar um dedo e alertar ou automatizar respostas com base em uma arquitetura de condições personalizadas muito robusta. A captura de tela a seguir mostra a exibição histórica do painel do Performance Advisor, com esperas de disco em laranja, E/S de banco de dados no canto inferior direito e linhas de base comparando o período atual e anterior em cada gráfico (clique para ampliar):
As ferramentas de monitoramento de qualidade não são gratuitas, mas fornecem muitas funcionalidades e suporte que permitem que você se concentre nos problemas de desempenho em seus servidores, em vez de se concentrar em consultas, trabalhos e alertas que podem permitem que você se concentre em seus problemas de desempenho - mas apenas quando você os acertar. Muitas vezes há um grande valor em não reinventar a roda.