As funções RANK, DENSE_RANK e ROW_NUMBER são usadas para recuperar um valor inteiro crescente. Eles começam com um valor baseado na condição imposta pela cláusula ORDER BY. Todas essas funções exigem que a cláusula ORDER BY funcione corretamente. No caso de dados particionados, o contador inteiro é redefinido para 1 para cada partição.
Neste artigo, estudaremos detalhadamente as funções RANK, DENSE_RANK e ROW_NUMBER, mas antes disso, vamos criar dados fictícios nos quais essas funções podem ser usadas, a menos que seu banco de dados tenha um backup completo.
Preparando dados fictícios
Execute o seguinte script para criar um banco de dados chamado ShowRoom e contendo uma tabela chamada Cars (que contém 15 registros aleatórios de carros):
CREATE Database ShowRoom; GO USE ShowRoom; CREATE TABLE Cars ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) USE ShowRoom INSERT INTO Cars VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 1500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 5000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200), (11, 'Atlas', 'Volkswagen', 5000), (12, '110', 'Bugatti', 8000), (13, 'Landcruiser', 'Toyota', 3000), (14, 'Civic', 'Honda', 1800), (15, 'Accord', 'Honda', 2000)
Função RANK
A função RANK é usada para recuperar linhas classificadas com base na condição da cláusula ORDER BY. Por exemplo, se você quiser encontrar o nome do carro com a terceira maior potência, você pode usar a função RANK.
Vamos ver a função RANK em ação:
SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS PowerRank FROM Cars
O script acima encontra e classifica todos os registros na tabela Carros e os ordena em ordem decrescente de potência. A saída fica assim:
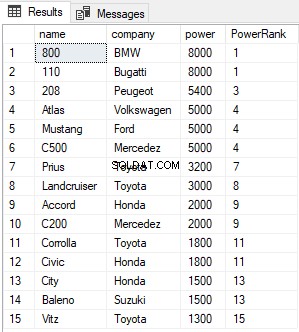
A coluna PowerRank na tabela acima contém o RANK dos carros ordenados por ordem decrescente de sua potência. Uma coisa interessante sobre a função RANK é que se houver empate entre N registros anteriores para o valor na coluna ORDER BY, as funções RANK pularão as próximas N-1 posições antes de incrementar o contador. Por exemplo, no resultado acima, há um empate para os valores na coluna de potência entre a 1ª e a 2ª linha, portanto a função RANK pula o próximo (2-1 =1) um registro e pula diretamente para a 3ª linha.
A função RANK pode ser usada em combinação com a cláusula PARTITION BY. Nesse caso, a classificação será redefinida para cada nova partição. Dê uma olhada no script a seguir:
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
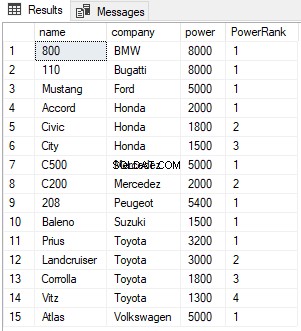
No script acima, particionamos os resultados por coluna da empresa. Agora, para cada empresa, o RANK será redefinido para 1, conforme mostrado abaixo:
Função DENSE_RANK
A função DENSE_RANK é semelhante à função RANK, porém a função DENSE_RANK não ignora nenhuma classificação se houver um empate entre as classificações dos registros anteriores. Dê uma olhada no script a seguir.
SELECT name,company, power, RANK() OVER(PARTITION BY company ORDER BY power DESC) AS PowerRank FROM Cars
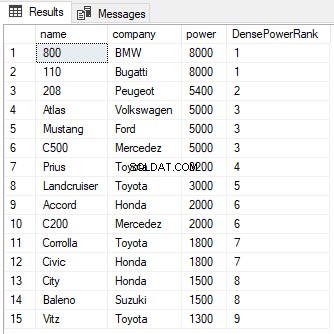
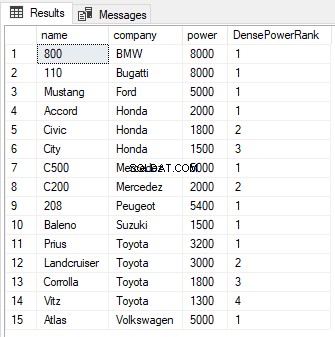
Você pode ver na saída que, apesar de haver um empate entre as classificações das duas primeiras linhas, a próxima classificação não é ignorada e recebeu um valor de 2 em vez de 3. Assim como na função RANK, a cláusula PARTITION BY pode também ser usado com a função DENSE_RANK conforme mostrado abaixo:
SELECT name,company, power, DENSE_RANK() OVER(PARTITION BY company ORDER BY power DESC) AS DensePowerRank FROM Cars
Função ROW_NUMBER
Ao contrário das funções RANK e DENSE_RANK, a função ROW_NUMBER simplesmente retorna o número da linha dos registros classificados começando com 1. Por exemplo, se as funções RANK e DENSE_RANK dos dois primeiros registros na coluna ORDER BY forem iguais, ambos receberão 1 como seu RANK e DENSE_RANK. No entanto, a função ROW_NUMBER atribuirá os valores 1 e 2 a essas linhas sem levar em consideração o fato de que elas são igualmente consideradas. Execute o script a seguir para ver a função ROW_NUMBER em ação.
SELECT name,company, power, ROW_NUMBER() OVER(ORDER BY power DESC) AS RowRank FROM Cars
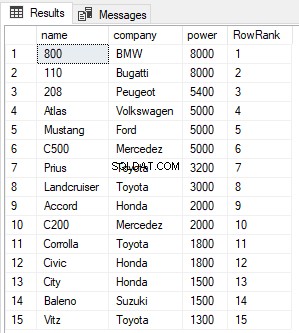
A partir da saída, você pode ver que a função ROW_NUMBER simplesmente atribui um novo número de linha a cada registro, independentemente de seu valor.
A cláusula PARTITION BY também pode ser usada com a função ROW_NUMBER, conforme mostrado abaixo:
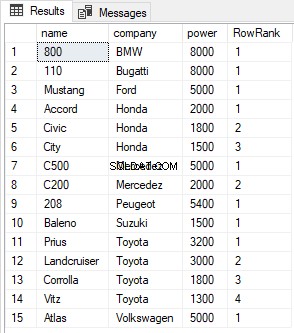
SELECT name, company, power, ROW_NUMBER() OVER(PARTITION BY company ORDER BY power DESC) AS RowRank FROM Cars
A saída fica assim:
Semelhanças entre as funções RANK, DENSE_RANK e ROW_NUMBER
As funções RANK, DENSE_RANK e ROW_NUMBER possuem as seguintes semelhanças:
1- Todas elas requerem uma cláusula order by.
2- Todas elas retornam um inteiro crescente com valor base 1.
3- Quando combinadas com uma cláusula PARTITION BY, todas essas funções redefinem o valor inteiro retornado para 1 como vimos.
4- Se não houver valores duplicados na coluna usada pela cláusula ORDER BY, estes as funções retornam a mesma saída.
Para ilustrar o último ponto, vamos criar uma nova tabela Car1 no banco de dados ShowRoom sem valores duplicados na coluna de energia. Execute o seguinte script:
USE ShowRoom; CREATE TABLE Cars1 ( id INT, name VARCHAR(50) NOT NULL, company VARCHAR(50) NOT NULL, power INT NOT NULL ) INSERT INTO Cars1 VALUES (1, 'Corrolla', 'Toyota', 1800), (2, 'City', 'Honda', 1500), (3, 'C200', 'Mercedez', 2000), (4, 'Vitz', 'Toyota', 1300), (5, 'Baleno', 'Suzuki', 2500), (6, 'C500', 'Mercedez', 5000), (7, '800', 'BMW', 8000), (8, 'Mustang', 'Ford', 4000), (9, '208', 'Peugeot', 5400), (10, 'Prius', 'Toyota', 3200) The cars1 table has no duplicate values. Now let’s execute the RANK, DENSE_RANK and ROW_NUMBER functions on the Cars1 table ORDER BY power column. Execute the following script: SELECT name,company, power, RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars1
A saída fica assim:
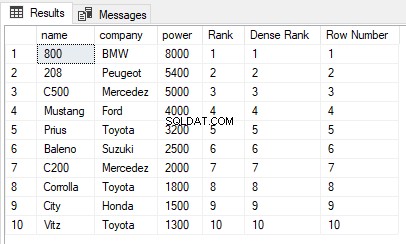
Você pode ver que não há valores duplicados na coluna de energia que está sendo usada na cláusula ORDER BY, portanto, a saída das funções RANK, DENSE_RANK e ROW_NUMBER é a mesma.
Diferença entre as funções RANK, DENSE_RANK e ROW_NUMBER
A única diferença entre as funções RANK, DENSE_RANK e ROW_NUMBER é quando há valores duplicados na coluna que está sendo usada na cláusula ORDER BY.
Se você voltar para a tabela Cars no banco de dados ShowRoom, você pode ver que ela contém muitos valores duplicados. Vamos tentar encontrar o RANK, DENSE_RANK e ROW_NUMBER da tabela Cars1 ordenada por potência. Execute o seguinte script:
SELECT name,company, power,
RANK() OVER(ORDER BY power DESC) AS [Rank], DENSE_RANK() OVER(ORDER BY power DESC) AS [Dense Rank], ROW_NUMBER() OVER(ORDER BY power DESC) AS [Row Number] FROM Cars
A saída fica assim:
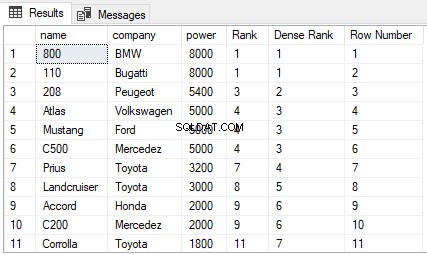
A partir da saída, você pode ver que a função RANK pula as próximas N-1 classificações se houver um empate entre as N classificações anteriores. Por outro lado, a função DENSE_RANK não pula ranks se houver empate entre ranks. Por fim, a função ROW_NUMBER não se preocupa com a classificação. Ele simplesmente retorna o número da linha dos registros classificados. Mesmo que haja registros duplicados na coluna usada na cláusula ORDER BY, a função ROW_NUMBER não retornará valores duplicados. Em vez disso, ele continuará a aumentar independentemente dos valores duplicados.
Links úteis:
Para saber mais sobre as funções ROW_NUMBER(), RANK() e DENSE_RANK(), leia o fantástico artigo de Ahmad Yaseen:
Métodos para classificar linhas no SQL Server:ROW_NUMBER(), RANK(), DENSE_RANK() e NTILE()