No início deste mês, publiquei uma dica sobre algo que provavelmente todos gostaríamos de não ter que fazer:classificar ou remover duplicatas de strings delimitadas, geralmente envolvendo funções definidas pelo usuário (UDFs). Às vezes, você precisa remontar a lista (sem as duplicatas) em ordem alfabética e, às vezes, pode precisar manter a ordem original (pode ser a lista de colunas-chave em um índice incorreto, por exemplo).
Para minha solução, que aborda os dois cenários, usei uma tabela de números, juntamente com um par de funções definidas pelo usuário (UDFs) – uma para dividir a string e outra para remontá-la. Você pode ver essa dica aqui:
- Removendo duplicatas de strings no SQL Server
Claro, existem várias maneiras de resolver esse problema; Eu estava apenas fornecendo um método para tentar se você estiver preso a esses dados de estrutura. O @Phil_Factor da Red-Gate seguiu com um post rápido mostrando sua abordagem, que evita as funções e a tabela de números, optando pela manipulação de XML inline. Ele diz que prefere ter consultas de instrução única e evitar funções e processamento linha por linha:
- Desduplicando listas delimitadas no SQL Server
Então um leitor, Steve Mangiameli, postou uma solução em loop como um comentário na dica. Seu raciocínio era que o uso de uma tabela de números parecia super-engenharia para ele.
Nós três falhamos em abordar um aspecto disso que geralmente será muito importante se você estiver executando a tarefa com frequência suficiente ou em qualquer nível de escala:desempenho .
Teste
Curioso para ver o desempenho das abordagens XML inline e de looping em comparação com minha solução baseada em tabela de números, construí uma tabela fictícia para realizar alguns testes; meu objetivo era 5.000 linhas, com um comprimento médio de string maior que 250 caracteres e pelo menos 10 elementos em cada string. Com um ciclo muito curto de experimentos, consegui algo muito próximo disso com o seguinte código:
CREATE TABLE dbo.SourceTable
(
[RowID] int IDENTITY(1,1) PRIMARY KEY CLUSTERED,
DelimitedString varchar(8000)
);
GO
;WITH s(s) AS
(
SELECT TOP (250) o.name + REPLACE(REPLACE(REPLACE(REPLACE(REPLACE(
(
SELECT N'/column_' + c.name
FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
ORDER BY NEWID()
FOR XML PATH(N''), TYPE).value(N'.[1]', N'nvarchar(max)'
),
-- make fake duplicates using 5 most common column names:
N'/column_name/', N'/name/name/foo/name/name/id/name/'),
N'/column_status/', N'/id/status/blat/status/foo/status/name/'),
N'/column_type/', N'/type/id/name/type/id/name/status/id/type/'),
N'/column_object_id/', N'/object_id/blat/object_id/status/type/name/'),
N'/column_pdw_node_id/', N'/pdw_node_id/name/pdw_node_id/name/type/name/')
FROM sys.all_objects AS o
WHERE EXISTS
(
SELECT 1 FROM sys.all_columns AS c
WHERE c.[object_id] = o.[object_id]
)
ORDER BY NEWID()
)
INSERT dbo.SourceTable(DelimitedString)
SELECT s FROM s;
GO 20 Isso produziu uma tabela com linhas de amostra assim (valores truncados):
RowID DelimitedString ----- --------------- 1 master_files/column_redo_target_fork_guid/.../column_differential_base_lsn/... 2 allocation_units/column_used_pages/.../column_data_space_id/type/id/name/type/... 3 foreign_key_columns/column_parent_object_id/column_constraint_object_id/...
Os dados como um todo tinham o seguinte perfil, que deve ser bom o suficiente para descobrir possíveis problemas de desempenho:
;WITH cte([Length], ElementCount) AS
(
SELECT 1.0*LEN(DelimitedString),
1.0*LEN(REPLACE(DelimitedString,'/',''))
FROM dbo.SourceTable
)
SELECT row_count = COUNT(*),
avg_size = AVG([Length]),
max_size = MAX([Length]),
avg_elements = AVG(1 + [Length]-[ElementCount]),
sum_elements = SUM(1 + [Length]-[ElementCount])
FROM cte;
EXEC sys.sp_spaceused N'dbo.SourceTable';
/* results (numbers may vary slightly, depending on SQL Server version the user objects in your database):
row_count avg_size max_size avg_elements sum_elements
--------- ---------- -------- ------------ ------------
5000 299.559000 2905.0 17.650000 88250.0
reserved data index_size unused
-------- ------- ---------- ------
1672 KB 1648 KB 16 KB 8 KB
*/ Observe que mudei para
varchar aqui de nvarchar no artigo original, porque as amostras que Phil e Steve forneceram assumiram varchar , strings com limite de apenas 255 ou 8.000 caracteres, delimitadores de caractere único etc. Aprendi minha lição da maneira mais difícil, que se você pegar a função de alguém e incluí-la em comparações de desempenho, você mudará tão pouco quanto possível – idealmente nada. Na realidade, eu sempre usaria nvarchar e não assumir nada sobre a string mais longa possível. Nesse caso, eu sabia que não estava perdendo nenhum dado porque a string mais longa tem apenas 2.905 caracteres e, nesse banco de dados, não tenho tabelas ou colunas que usam caracteres Unicode. Em seguida, criei minhas funções (que exigem uma tabela de números). Um leitor detectou um problema na função na minha dica, onde eu assumi que o delimitador seria sempre um único caractere, e corrigi isso aqui. Eu também converti quase tudo para
varchar(8000) para nivelar o campo de jogo em termos de tipos e comprimentos de cordas. DECLARE @UpperLimit INT = 1000000;
;WITH n(rn) AS
(
SELECT ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_columns AS s1
CROSS JOIN sys.all_columns AS s2
)
SELECT [Number] = rn
INTO dbo.Numbers FROM n
WHERE rn <= @UpperLimit;
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers([Number]);
GO
CREATE FUNCTION [dbo].[SplitString] -- inline TVF
(
@List varchar(8000),
@Delim varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT
rn,
vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn),
[Value]
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS x
);
GO
CREATE FUNCTION [dbo].[ReassembleString] -- scalar UDF
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS varchar(8000)
WITH SCHEMABINDING
AS
BEGIN
RETURN
(
SELECT newval = STUFF((
SELECT @Delim + x.[Value]
FROM dbo.SplitString(@List, @Delim) AS x
WHERE (x.vn = 1) -- filter out duplicates
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(SQL_VARIANT, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
END
GO Em seguida, criei uma única função inline com valor de tabela que combinava as duas funções acima, algo que agora gostaria de ter feito no artigo original, para evitar completamente a função escalar. (Embora seja verdade que nem todos funções escalares são terríveis em escala, há muito poucas exceções.)
CREATE FUNCTION [dbo].[RebuildString]
(
@List varchar(8000),
@Delim varchar(32),
@Sort varchar(32)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT [Output] = STUFF((
SELECT @Delim + x.[Value]
FROM
(
SELECT rn, [Value], vn = ROW_NUMBER() OVER (PARTITION BY [Value] ORDER BY rn)
FROM
(
SELECT rn = ROW_NUMBER() OVER (ORDER BY CHARINDEX(@Delim, @List + @Delim)),
[Value] = LTRIM(RTRIM(SUBSTRING(@List, [Number],
CHARINDEX(@Delim, @List + @Delim, [Number]) - [Number])))
FROM dbo.Numbers
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delim + @List, [Number], LEN(@Delim)) = @Delim
) AS y
) AS x
WHERE (x.vn = 1)
ORDER BY CASE @Sort
WHEN 'OriginalOrder' THEN CONVERT(int, x.rn)
WHEN 'Alphabetical' THEN CONVERT(varchar(8000), x.[Value])
ELSE CONVERT(sql_variant, NULL) END
FOR XML PATH(''), TYPE).value(N'(./text())[1]',N'varchar(8000)'),1,LEN(@Delim),'')
);
GO Também criei versões separadas do TVF inline que foram dedicadas a cada uma das duas opções de classificação, a fim de evitar a volatilidade do
CASE expressão, mas acabou não tendo um impacto dramático. Então criei as duas funções de Steve:
CREATE FUNCTION [dbo].[gfn_ParseList] -- multi-statement TVF
(@strToPars VARCHAR(8000), @parseChar CHAR(1))
RETURNS @parsedIDs TABLE
(ParsedValue VARCHAR(255), PositionID INT IDENTITY)
AS
BEGIN
DECLARE
@startPos INT = 0
, @strLen INT = 0
WHILE LEN(@strToPars) >= @startPos
BEGIN
IF (SELECT CHARINDEX(@parseChar,@strToPars,(@startPos+1))) > @startPos
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
ELSE
BEGIN
SET @strLen = LEN(@strToPars) - (@startPos -1)
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
BREAK
END
SELECT @strLen = CHARINDEX(@parseChar,@strToPars,(@startPos+1)) - @startPos
INSERT @parsedIDs
SELECT RTRIM(LTRIM(SUBSTRING(@strToPars,@startPos, @strLen)))
SET @startPos = @startPos+@strLen+1
END
RETURN
END
GO
CREATE FUNCTION [dbo].[ufn_DedupeString] -- scalar UDF
(
@dupeStr VARCHAR(MAX), @strDelimiter CHAR(1), @maintainOrder BIT
)
-- can't possibly return nvarchar, but I'm not touching it
RETURNS NVARCHAR(MAX)
AS
BEGIN
DECLARE @tblStr2Tbl TABLE (ParsedValue VARCHAR(255), PositionID INT);
DECLARE @tblDeDupeMe TABLE (ParsedValue VARCHAR(255), PositionID INT);
INSERT @tblStr2Tbl
SELECT DISTINCT ParsedValue, PositionID FROM dbo.gfn_ParseList(@dupeStr,@strDelimiter);
WITH cteUniqueValues
AS
(
SELECT DISTINCT ParsedValue
FROM @tblStr2Tbl
)
INSERT @tblDeDupeMe
SELECT d.ParsedValue
, CASE @maintainOrder
WHEN 1 THEN MIN(d.PositionID)
ELSE ROW_NUMBER() OVER (ORDER BY d.ParsedValue)
END AS PositionID
FROM cteUniqueValues u
JOIN @tblStr2Tbl d ON d.ParsedValue=u.ParsedValue
GROUP BY d.ParsedValue
ORDER BY d.ParsedValue
DECLARE
@valCount INT
, @curValue VARCHAR(255) =''
, @posValue INT=0
, @dedupedStr VARCHAR(4000)='';
SELECT @valCount = COUNT(1) FROM @tblDeDupeMe;
WHILE @valCount > 0
BEGIN
SELECT @posValue=a.minPos, @curValue=d.ParsedValue
FROM (SELECT MIN(PositionID) minPos FROM @tblDeDupeMe WHERE PositionID > @posValue) a
JOIN @tblDeDupeMe d ON d.PositionID=a.minPos;
SET @dedupedStr+=@curValue;
SET @valCount-=1;
IF @valCount > 0
SET @dedupedStr+='/';
END
RETURN @dedupedStr;
END
GO Em seguida, coloco as consultas diretas de Phil em meu equipamento de teste (observe que as consultas dele codificam
< como < para protegê-los de erros de análise de XML, mas eles não codificam > ou & – Adicionei espaços reservados caso você precise se proteger contra strings que podem conter esses caracteres problemáticos):-- Phil's query for maintaining original order
SELECT /*the re-assembled list*/
stuff(
(SELECT '/'+TheValue FROM
(SELECT x.y.value('.','varchar(20)') AS Thevalue,
row_number() OVER (ORDER BY (SELECT 1)) AS TheOrder
FROM XMLList.nodes('/list/i/text()') AS x ( y )
)Nodes(Thevalue,TheOrder)
GROUP BY TheValue
ORDER BY min(TheOrder)
FOR XML PATH('')
),1,1,'')
as Deduplicated
FROM (/*XML version of the original list*/
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT DelimitedString FROM dbo.SourceTable
)XMLlist(AsciiList)
)lists(XMLlist);
-- Phil's query for alpha
SELECT
stuff( (SELECT DISTINCT '/'+x.y.value('.','varchar(20)')
FROM XMLList.nodes('/list/i/text()') AS x ( y )
FOR XML PATH('')),1,1,'') as Deduplicated
FROM (
SELECT convert(XML,'<list><i>'
--+replace(replace(
+replace(replace(ASCIIList,'<','<') --,'>','>'),'&','&')
,'/','</i><i>')+'</i></list>')
FROM (SELECT AsciiList FROM
(SELECT DelimitedString FROM dbo.SourceTable)ListsWithDuplicates(AsciiList)
)XMLlist(AsciiList)
)lists(XMLlist); O equipamento de teste era basicamente essas duas consultas e também as seguintes chamadas de função. Depois de validar que todos retornaram os mesmos dados, intercalei o script com
DATEDIFF output e registrei em uma tabela:-- Maintain original order
-- My UDF/TVF pair from the original article
SELECT UDF_Original = dbo.ReassembleString(DelimitedString, '/', 'OriginalOrder')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Original = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'OriginalOrder') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Original = dbo.ufn_DedupeString(DelimitedString, '/', 1)
FROM dbo.SourceTable;
-- Phil's first query from above
-- Reassemble in alphabetical order
-- My UDF/TVF pair from the original article
SELECT UDF_Alpha = dbo.ReassembleString(DelimitedString, '/', 'Alphabetical')
FROM dbo.SourceTable ORDER BY RowID;
-- My inline TVF based on the original article
SELECT TVF_Alpha = f.[Output] FROM dbo.SourceTable AS t
CROSS APPLY dbo.RebuildString(t.DelimitedString, '/', 'Alphabetical') AS f
ORDER BY t.RowID;
-- Steve's UDF/TVF pair:
SELECT Steve_Alpha = dbo.ufn_DedupeString(DelimitedString, '/', 0)
FROM dbo.SourceTable;
-- Phil's second query from above E, em seguida, executei testes de desempenho em dois sistemas diferentes (um quad core com 8 GB e uma VM de 8 núcleos com 32 GB) e, em cada caso, no SQL Server 2012 e no SQL Server 2016 CTP 3.2 (13.0.900.73).
Resultados
Os resultados que observei estão resumidos no gráfico a seguir, que mostra a duração em milissegundos de cada tipo de consulta, em média sobre a ordem alfabética e original, as quatro combinações de servidor/versão e uma série de 15 execuções para cada permutação. Clique para ampliar:
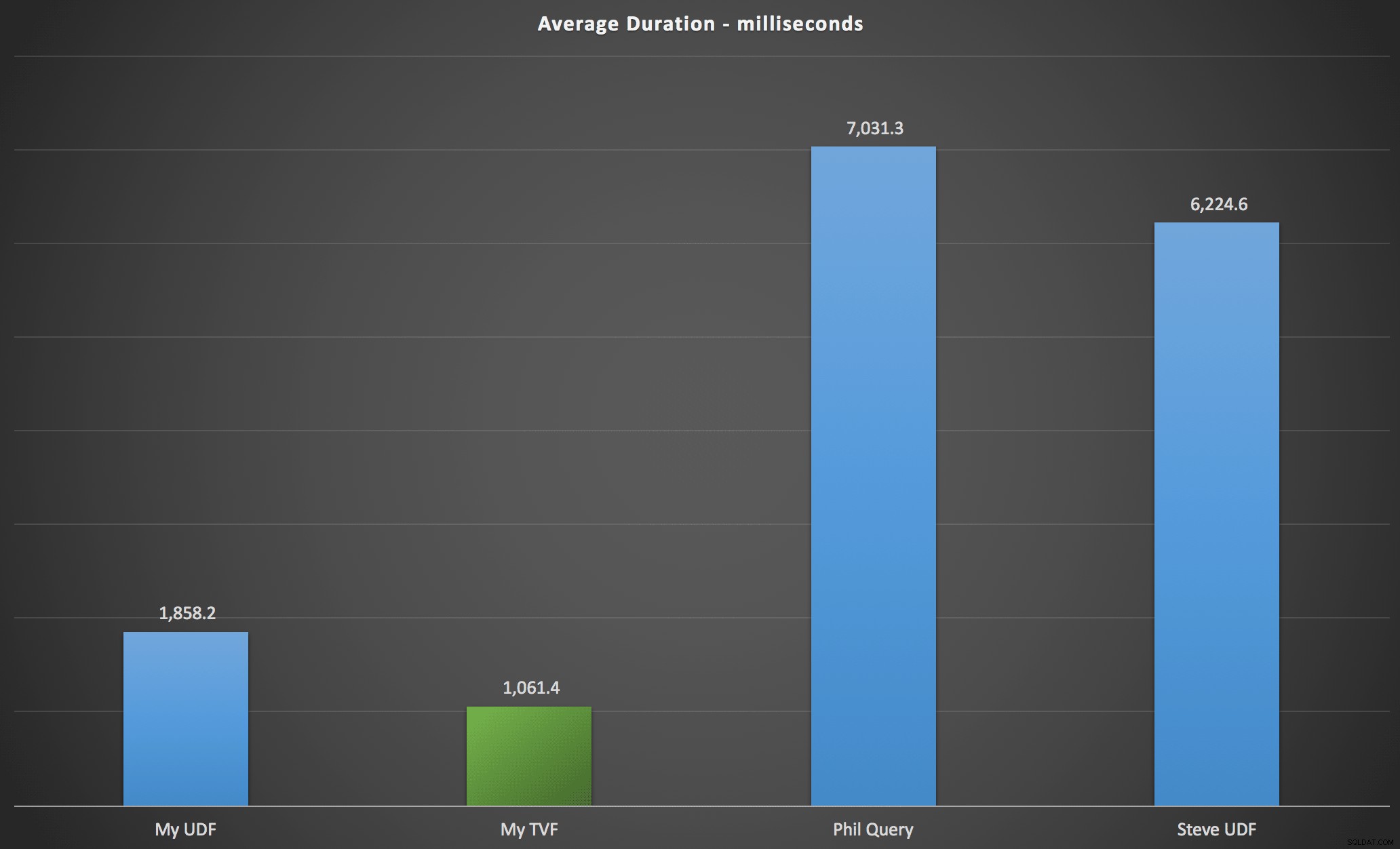
Isso mostra que a tabela de números, embora considerada com engenharia excessiva, na verdade rendeu a solução mais eficiente (pelo menos em termos de duração). Isso foi melhor, é claro, com o único TVF que implementei mais recentemente do que com as funções aninhadas do artigo original, mas ambas as soluções circulam em torno das duas alternativas.
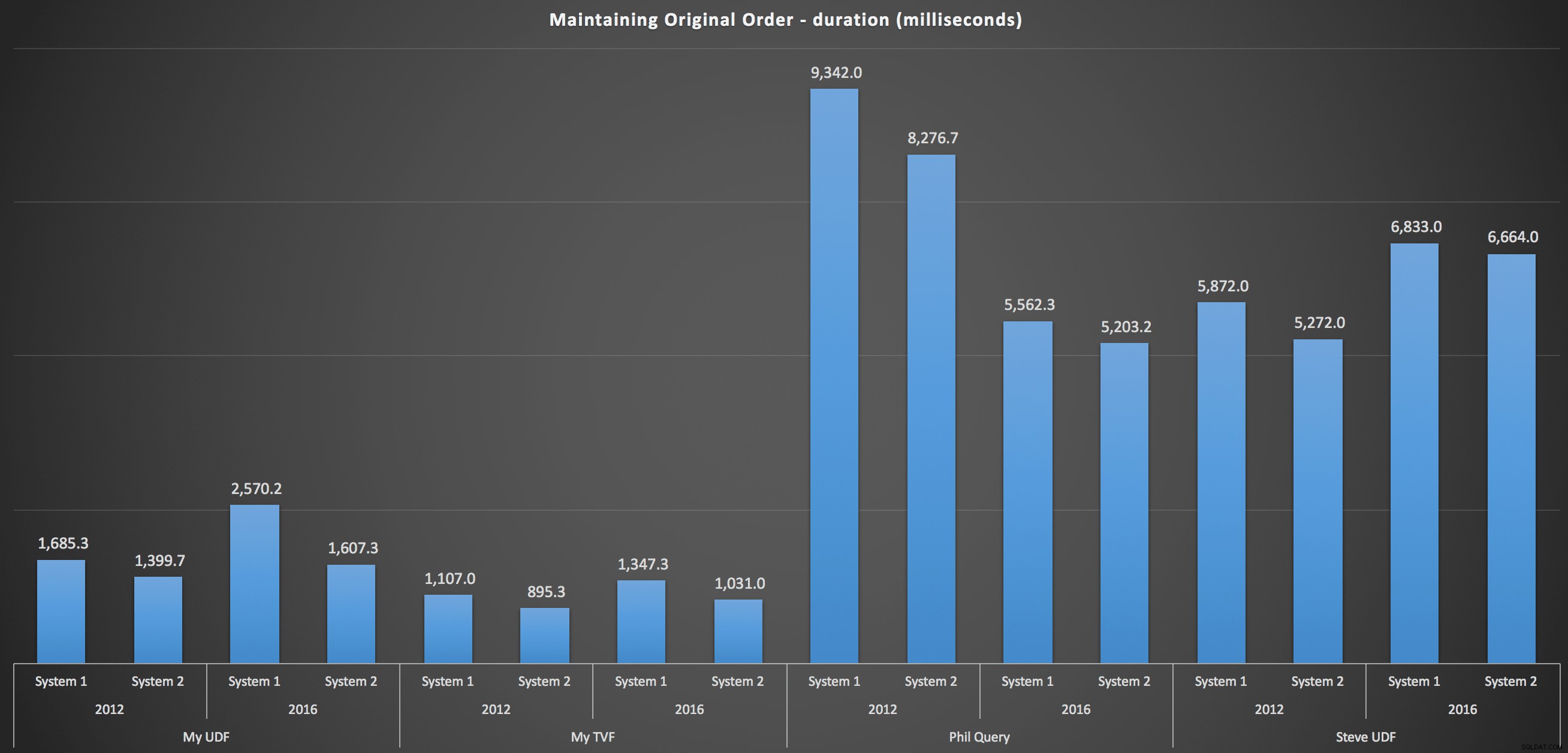
Para entrar em mais detalhes, aqui estão os detalhamentos para cada máquina, versão e tipo de consulta, para manter o pedido original:
…e para remontar a lista em ordem alfabética:
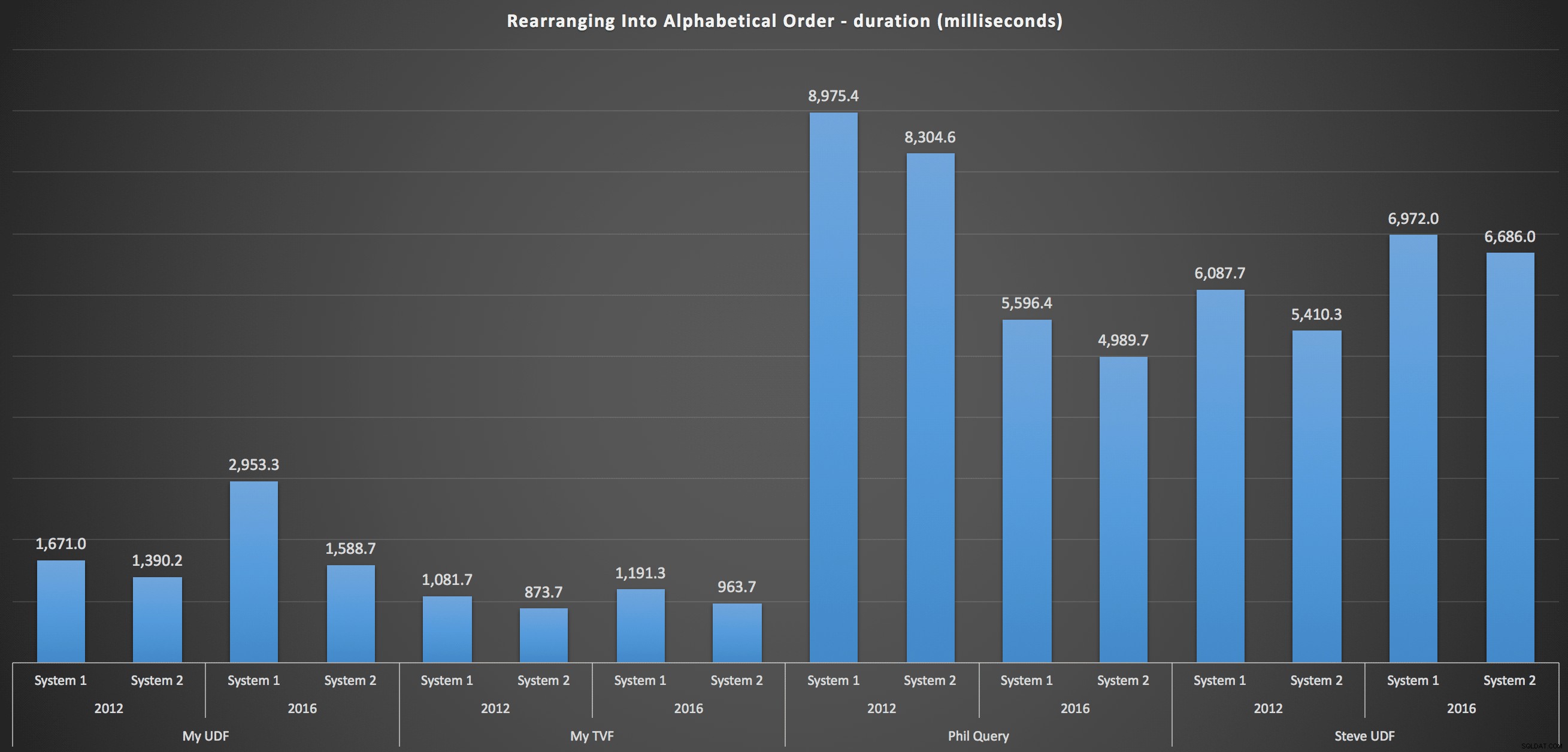
Isso mostra que a escolha de classificação teve pouco impacto no resultado – ambos os gráficos são praticamente idênticos. E isso faz sentido porque, dada a forma dos dados de entrada, não há índice que eu possa imaginar que tornaria a classificação mais eficiente – é uma abordagem iterativa, não importa como você os divide ou como retorna os dados. Mas está claro que algumas abordagens iterativas podem ser geralmente piores que outras, e não é necessariamente o uso de uma UDF (ou uma tabela de números) que as torna assim.
Conclusão
Até que tenhamos a funcionalidade de divisão e concatenação nativa no SQL Server, usaremos todos os tipos de métodos não intuitivos para realizar o trabalho, incluindo funções definidas pelo usuário. Se você estiver manipulando uma única string por vez, não verá muita diferença. Mas à medida que seus dados aumentam, valerá a pena testar várias abordagens (e não estou sugerindo que os métodos acima sejam os melhores que você encontrará - eu nem olhei para o CLR, por exemplo, ou outras abordagens T-SQL desta série).