O FILESTREAM foi introduzido pela Microsoft em 2008. O objetivo era armazenar e gerenciar arquivos não estruturados com mais eficiência. Antes da introdução do FILESTREAM, as seguintes abordagens eram usadas para armazenar os dados no SQL Server:
- Arquivos não estruturados podem ser armazenados na coluna VARBINARY ou IMAGE de uma tabela do SQL Server. Essa abordagem é eficaz para manter a consistência transacional e reduz a complexidade do gerenciamento de arquivos, mas quando o aplicativo cliente lê dados da tabela SQL, ele usa memória SQL, o que leva a um desempenho ruim.
- Em vez de armazenar o arquivo inteiro na tabela SQL, armazene a localização física do arquivo não estruturado na tabela SQL. Essa abordagem oferece uma grande melhoria de desempenho, mas não garante a consistência transacional, além disso, o gerenciamento de arquivos também era difícil.
O recurso FILESTREAM é muito eficaz porque permite armazenar arquivos BLOB no sistema de arquivos NT e mantém a consistência transacional. Quando um aplicativo cliente lê dados do contêiner FILESTREAM, em vez de usar a memória do buffer do SQL Server, ele usa o Nthe T cache do sistema, o que melhora o desempenho.
FILESTREAM não é um tipo de dados. É um atributo que pode ser atribuído à coluna VARBINARY(MAX). Quando a coluna VARBINARY(MAX) é atribuída ao atributo FILESTREAM, ela é chamada de coluna FILESTREAM. Os dados armazenados na coluna FILESTREAM serão armazenados no sistema NT como um arquivo em disco, e o ponteiro do arquivo será armazenado na tabela. A coluna VARBINARY(max) com o atributo FILESTREAM atribuído não tem limite de armazenamento de 2 GB na tabela. Assim, podemos armazenar arquivos enormes também.
Neste artigo, vou demonstrar o seguinte:
- Como ativar o recurso FILESTREAM.
- Como criar e configurar grupos de arquivos FILESTREAM e contêiner de dados FILESTREAM.
- Como armazenar e acessar dados das tabelas habilitadas para FILESTREAM.
Demonstração:
Nesta demonstração, vou usar:
- Servidor de banco de dados :SQL Server 2017
- Software :SQL Server Management Studio
- Banco de dados :FileStream_Demo
Configurar o acesso FILESTREAM no banco de dados SQL Server
Para configurar o FileStream no SQL Server, faça as seguintes alterações no SQL Server.
- Ative o recurso FILESTREAM no SQL Server Configuration Manager.
- Ative o nível de acesso FILESTREAM na instância do SQL Server.
- Crie um grupo de arquivos FILESTREAM e um contêiner FileStream para armazenar dados BLOB.
Ativar recurso FILESTREAM
Para habilitar o FileStream em qualquer banco de dados, primeiro habilite o recurso FileStream na instância do SQL Server. Para fazer isso, abra o gerenciador de configuração do SQL Server, clique com o botão direito do mouse em SQL Instance, selecione Propriedades , conforme mostrado na imagem a seguir:
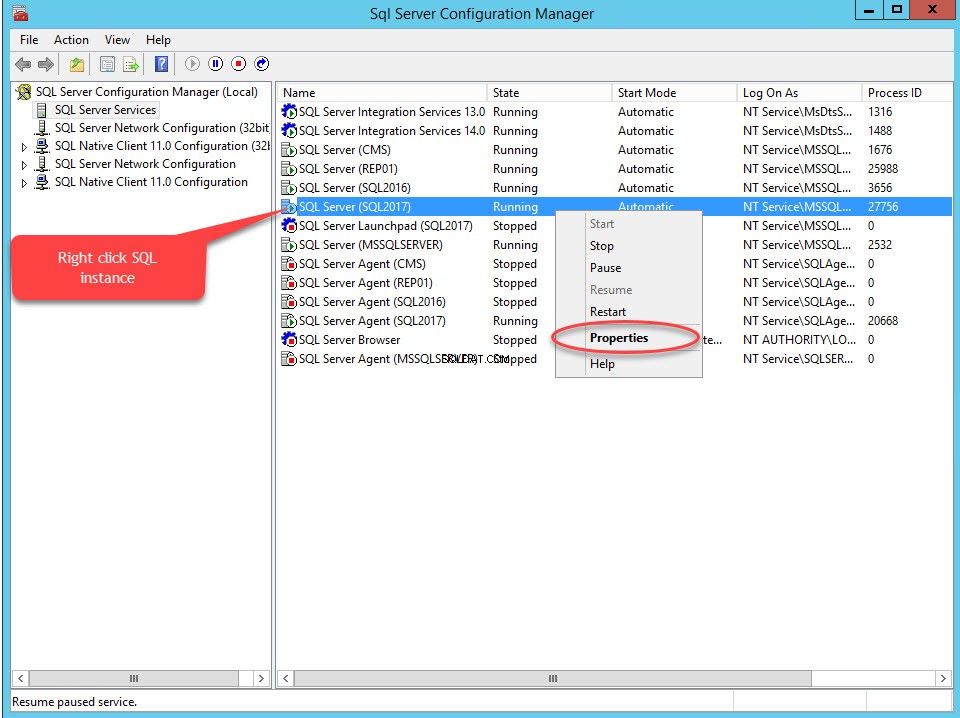
Uma caixa de diálogo para configurar as propriedades do servidor é aberta. Mude para o FILESTREAM aba. Selecione Ativar FILESTREAM para acesso T-SQL . Selecione Ativar FILESTREAM para acesso de E/S e selecione Permitir acesso de cliente remoto aos dados FILESTREAM . No nome do compartilhamento do Windows caixa de texto, forneça um nome do diretório para armazenar os arquivos. Veja a seguinte imagem:
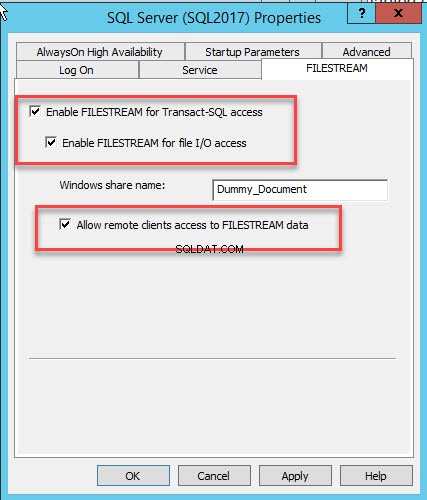
Clique em OK e reinicie o serviço SQL.
Ativar nível de acesso FILESTREAM na instância do SQL Server
Depois que o recurso FILESTREAM estiver ativado, altere o nível de acesso do FILESTREAM. Para alterar o nível de acesso do FileStream, execute a seguinte consulta:
EXEC sp_configure filestream_access_level, 2 RECONFIGURE
Na consulta acima, os parâmetros abaixo são valores válidos:
0 significa o suporte FILESTREAM para instância SQL está desabilitado.
1 significa o suporte FILESTREAM para T-SQL está habilitado.
2 meios o suporte FILESTREAM para acesso de streaming T-SQL e Win32 está habilitado.
Você pode alterar o nível de acesso FILESTREAM usando o SQL Server Management Studio. Para fazer isso, clique com o botão direito do mouse em uma conexão do SQL Server>> selecione Propriedades>> Na caixa de diálogo de propriedades do servidor, selecione FileStream Access Level na caixa suspensa e selecione Acesso total ativado , conforme mostrado na imagem a seguir:
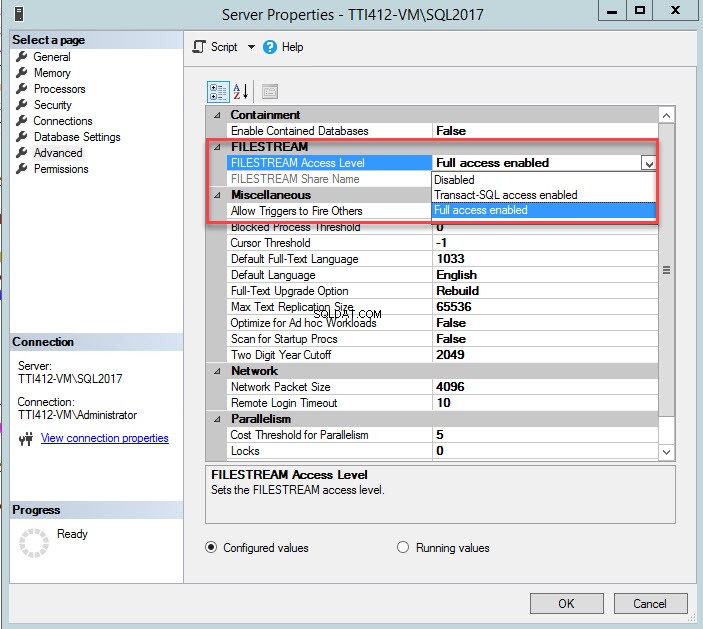
Depois que o parâmetro for alterado, reinicie os serviços do SQL Server.
Adicionar grupo de arquivos FILESTREAM e arquivos de dados
Depois que FILESTREAM estiver habilitado, adicione o grupo de arquivos FILESTREAM e o contêiner FILESTREAM.
Para fazer isso, clique com o botão direito do mouse em FileStream-Demo banco de dados>> selecione Propriedades>> Em um painel esquerdo das Propriedades do banco de dados caixa de diálogo, selecione Grupos de arquivos>> Na grade FILESTREAM, clique em Adicionar grupo de arquivos botão>> Nomeie o grupo de arquivos como Documento fictício . Veja a seguinte imagem:
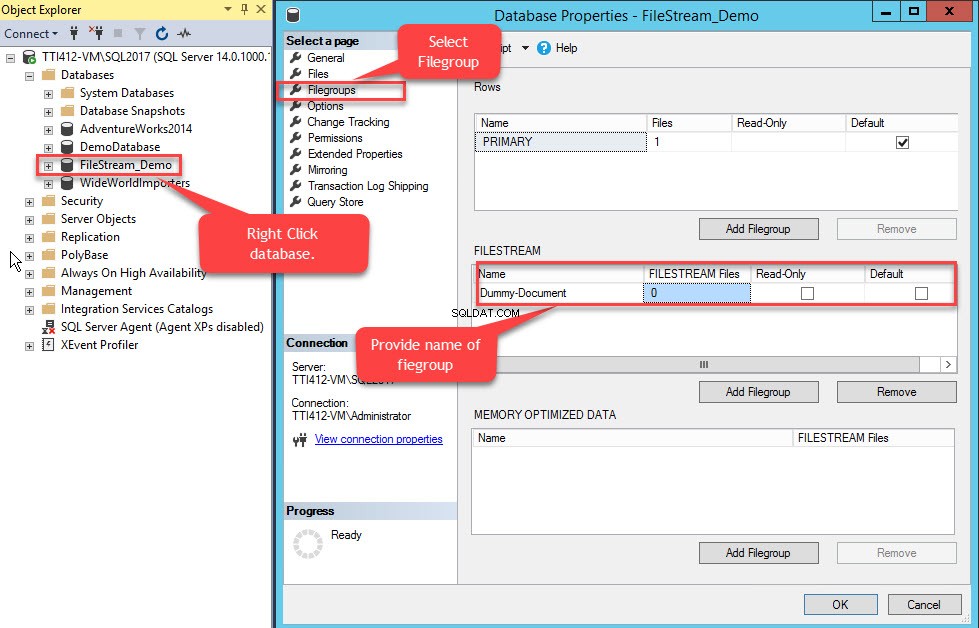
Depois que o grupo de arquivos for criado, na caixa de diálogo Propriedades do banco de dados, selecione arquivos e clique no botão Adicionar. A grade de arquivos do banco de dados é habilitada. Na coluna Logical Name, forneça o nome – Dummy-Document . Selecione Dados FILESTREAM no Tipo de arquivo caixa suspensa. Selecione Documento fictício no grupo de arquivos coluna. No Caminho coluna, forneça o local do diretório onde os arquivos serão armazenados (E:\Dummy-Documents). Veja a seguinte imagem:
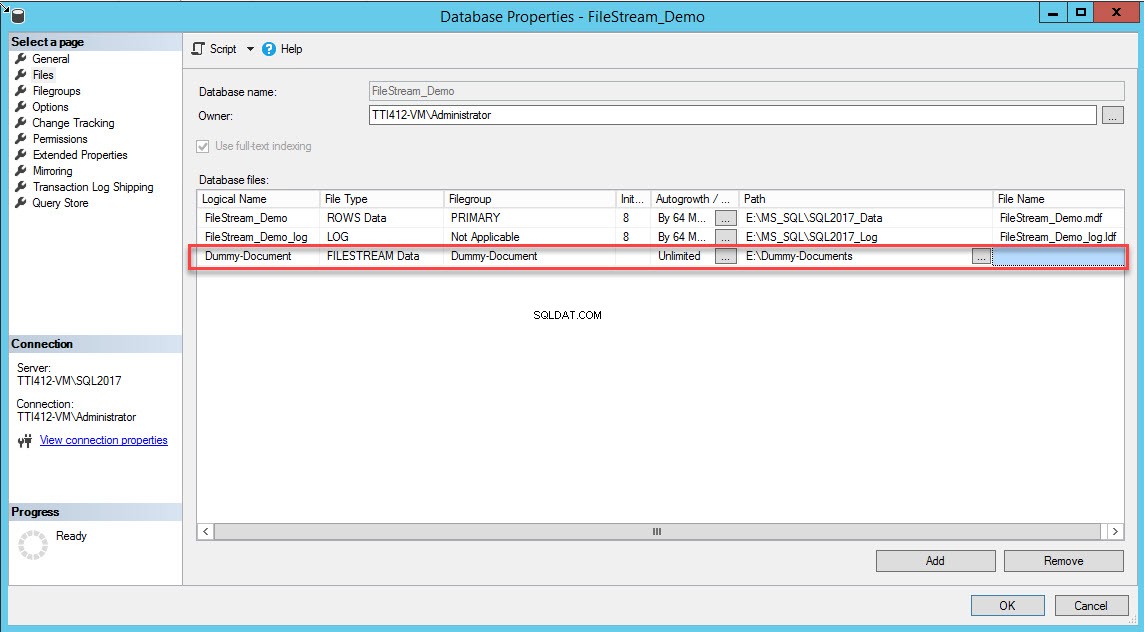
Como alternativa, você pode adicionar o grupo de arquivos e os contêineres FILESTREAM executando a seguinte consulta T-SQL:
USE [master] GO ALTER DATABASE [FileStream_Demo] ADD FILEGROUP [Dummy-Documents] CONTAINS FILESTREAM GO ALTER DATABASE [FileStream_Demo] ADD FILE ( NAME = N'Dummy-Documents', FILENAME = N'E:\Dummy-Documents' ) TO FILEGROUP [Dummy-Documents] GO
Para verificar se o contêiner FileStream foi criado, abra o Windows Explorer e navegue até o diretório “E:\Dummy-Document”.
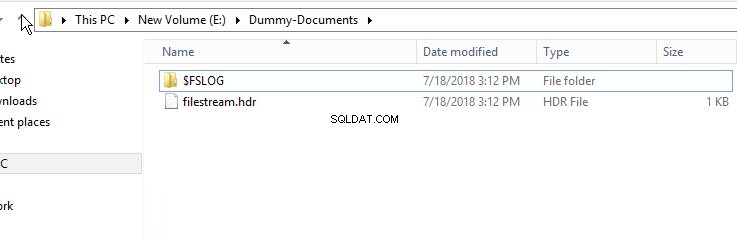
Conforme mostrado na imagem acima, o diretório $FSLOG e o filestream.hdr arquivo foi criado. $FSLOG é como o T-Log do servidor SQL e filestream.hdr contém metadados de FILESTREAM. Certifique-se de não alterar ou editar esses arquivos.
Armazenar arquivos na tabela SQL
Nesta demonstração, criaremos uma tabela para armazenar vários arquivos do computador. A tabela tem as seguintes colunas:
- O “Diretório Raiz ” para armazenar a localização do arquivo.
- O “Nome do arquivo ” para armazenar o nome do arquivo.
- O “FileAttribute ” para armazenar o atributo File (Raw/Directory.
- O “FileCreateDate ” para armazenar o tempo de criação do arquivo.
- O “Tamanho do arquivo ” para armazenar o tamanho do arquivo.
- O “FileStreamCol ” para armazenar o conteúdo do arquivo no formato binário.
Criar uma tabela SQL com uma coluna FILESTREAM
Depois que o FILESTREAM for configurado, crie uma tabela SQL com as colunas FILESTREAM para armazenar vários arquivos na tabela do servidor SQL. Como mencionei acima, FILESTREAM não é um tipo de dados. É um atributo que adicionamos à coluna varbinary(max) na tabela habilitada para FILESTREAM. Ao criar uma tabela habilitada para FILESTREAM, certifique-se de adicionar um UNIQUEIDENTIFIER coluna que tem o ROWGUIDCOL e ÚNICO atributos.
Execute o seguinte script para criar uma tabela habilitada para FILESTREAM:
Use [FileStream_Demo]
go
Create Table [DummyDocuments]
(
ID uniqueidentifier ROWGUIDCOL unique NOT NULL,
RootDirectory varchar(max),
FileName varchar(max),
FileAttribute varchar(150),
FileCreateDate datetime,
FileSize numeric(10,5),
FileStreamCol varbinary (max) FILESTREAM
) Inserir dados na tabela
Eu tenho o WorldWide_Importors.xls documento armazenado no computador no local “E:\Documents”. Use OPENROWSET(em massa) para carregar seu conteúdo do disco para o VARBINARY(max) variável. Em seguida, armazene a variável no FileStreamCol (VARBINARY(max)) coluna do DummyDocumen tabela t. Para fazer isso, execute o seguinte script:
Use [FileStream-Demo]
Go
DECLARE @Document AS VARBINARY(MAX)
-- Load the image data
SELECT @Document = CAST(bulkcolumn AS VARBINARY(MAX))
FROM OPENROWSET(
BULK
'E:\Documents\WorldWide_Importors.xls',
SINGLE_BLOB ) AS Doc
-- Insert the data to the table
INSERT INTO [DummyDocuments] (ID, RootDirectory,FileName, FileAttribute, FileCreateDate,FileSize,FileStreamCol)
SELECT NEWID(), 'E:\Documents','WorldWide_Importors.xls','Raw',getdate(),10, @Document Acessar dados FILESTREAM
Os dados FILESTREAM podem ser acessados usando T-SQL e API gerenciada. Quando a coluna FILESTREAM acessada usando a consulta T-SQL, ela usa a memória SQL para ler o conteúdo do arquivo de dados e enviar os dados para o aplicativo cliente. Quando a coluna FILESTREAM é acessada usando a API gerenciada do Win32, ela não usa a memória do SQL Server. Ele usa o recurso de streaming do sistema de arquivos NT que oferece benefícios de desempenho.
Acessar dados FILESTREAM usando T-SQL
Como mencionei no início do artigo, FILESTREAM é um atributo atribuído a uma coluna da tabela que possui o tipo de dados varbinary(max), portanto, pode ser acessado como qualquer outra coluna da tabela. Para recuperar os dados FILESTREAM junto com todas as informações da tabela, execute a consulta abaixo
Use [FileStream-Demo] go select RootDirectory,FileName,FileAttribute,FileCreateDate,FileSize,FileStreamCol from DummyDocuments
Abaixo está a saída da consulta:

Conforme mostrado na imagem acima, o documento “WorldWide_Importors.xls” foi convertido em um BLOB que é armazenado na coluna “FileStreamCol”.
Acessar dados FILESTREAM usando a API gerenciada
Embora acessar FILESTREAM usando a API Win32 ofereça desempenho e outros benefícios, mas possui sintaxes diferentes e difíceis das sintaxes T-SQL, o que dificulta o acesso aos dados. Em primeiro lugar, para localizar o arquivo no armazenamento de dados FILESTREAM, devemos identificar o caminho lógico para identificar o arquivo no armazenamento de dados FILESTREAM exclusivamente. Podemos fazer isso usando o Pathname() método da coluna FILESTREAM. É sensível a maiúsculas e minúsculas.
Após recuperar o caminho do Arquivo, para acessar, devemos obter o contexto da transação usando o Iniciar Transação método. Uma vez obtido o contexto da transação, podemos acessá-lo usando o SQLFileStream aula.
O código abaixo obtém o caminho local para o WorldWide_Importors.xls documento no armazenamento de dados FILESTREAM.
SELECT
RootDirectory,
FileName,
FileAttribute,
FileCreateDate,
FileSize,
FileStreamCol.PathName() AS FilePath
FROM DummyDocuments Saída da consulta:

Excluir arquivos do contêiner FILESTREAM
A exclusão de arquivos é simples. Você precisa executar a consulta de exclusão para remover o arquivo da tabela SQL habilitada para FILESTREAM. Mesmo que o registro tenha sido excluído das tabelas, o arquivo estará disponível fisicamente no armazenamento de dados FILSTREAM. Ele será excluído pelo Garbage Collector. O processo do Garbage Collector é executado quando ocorre o evento de ponto de verificação. Ao fornecer um ponto de verificação explícito, você pode excluí-lo imediatamente após a exclusão da tabela.
Consulta para excluir arquivos da tabela SQL:
Use [FileStream_Demo] go delete from DummyDocuments where ID='0D640ABC-8CF1-41E0-9FA8-28171047129F'
Resumo
Neste artigo, abordei:
- Introdução do FILESTREAM e quais são os benefícios.
- Como habilitar o recurso FILESTREAM na instância do SQL Server.
- Crie e configure o armazenamento de dados FILESTREAM e os grupos de arquivos.
- Execute inserir e excluir arquivos do armazenamento de dados FILESTREAM.
Em artigos futuros, vou explicar:
- Como fazer backup e restaurar o banco de dados habilitado para FILESTREAM.
- Configurando replicação e divisão de tabelas em tabelas FILESTREAM.
Fique atento!