O serializável o nível de isolamento fornece proteção completa dos efeitos de simultaneidade que podem ameaçar a integridade dos dados e levar a resultados de consulta incorretos. Usar o isolamento serializável significa que, se uma transação que pode ser mostrada para produzir resultados corretos sem atividade simultânea, ela continuará a ser executada corretamente ao competir com qualquer combinação de transações simultâneas.
Esta é uma garantia muito poderosa , e um que provavelmente corresponde às expectativas intuitivas de isolamento de transação de muitos programadores T-SQL (embora, na verdade, relativamente poucos deles usem rotineiramente o isolamento serializável na produção).
O padrão SQL define três níveis de isolamento adicionais que oferecem um ACID muito mais fraco garantias de isolamento do que serializáveis, em troca de simultaneidade potencialmente mais alta e menos efeitos colaterais potenciais, como bloqueio, impasse e abortos no tempo de confirmação.
Ao contrário do isolamento serializável, os outros níveis de isolamento são definidos apenas em termos de certos fenômenos de simultaneidade que podem ser observados. O próximo nível de isolamento padrão mais forte após serializável é chamado de leitura repetível . O padrão SQL especifica que as transações neste nível permitem um único fenômeno de simultaneidade conhecido como fantasma .
Assim como vimos anteriormente diferenças importantes entre o significado intuitivo comum das propriedades da transação ACID e a realidade, o fenômeno fantasma abrange uma gama mais ampla de comportamentos do que geralmente é apreciado.
Esta postagem da série analisa as garantias reais fornecidas pela leitura repetível nível de isolamento e mostra alguns dos comportamentos relacionados a fantasmas que podem ser encontrados. Para ilustrar alguns pontos, vamos nos referir ao seguinte exemplo de consulta simples, onde a tarefa simples é contar o número total de linhas em uma tabela:
SELECT COUNT_BIG(*) FROM dbo.SomeTable;
Leitura repetível
Uma coisa estranha sobre o nível de isolamento de leitura repetível é que ele não realmente garantir que as leituras sejam repetíveis , pelo menos em um sentido comumente entendido. Este é outro exemplo em que o significado intuitivo por si só pode ser enganoso. Executar a mesma consulta duas vezes na mesma transação de leitura repetível pode, de fato, retornar resultados diferentes.
Além disso, a implementação de leitura repetível do SQL Server significa que uma única leitura de um conjunto de dados pode perder algumas linhas que logicamente deve ser considerado no resultado da consulta. Embora inegavelmente específico da implementação, esse comportamento está totalmente alinhado com a definição de leitura repetível contida no padrão SQL.
A última coisa que quero observar rapidamente antes de entrar em detalhes é que a leitura repetível no SQL Server não fornecer uma visão pontual dos dados.
Leituras não repetíveis
O nível de isolamento de leitura repetível fornece uma garantia de que os dados não serão alterados durante a vida da transação depois de lida pela primeira vez.
Há algumas sutilezas contidas nessa definição. Primeiro, ele permite que os dados mudem depois a transação começa, mas antes que os dados sejam primeiros acessado. Em segundo lugar, não há garantia de que a transação realmente encontrará todos os dados que se qualificam logicamente. Veremos exemplos de ambos em breve.
Há uma outra preliminar que precisamos resolver rapidamente, que tem a ver com a consulta de exemplo que usaremos. Para ser justo, a semântica dessa consulta é um pouco confusa. Correndo o risco de soar um pouco filosófico, o que isso significa contar o número de linhas na tabela? O resultado deve refletir o estado da tabela como estava em algum momento específico? Esse momento deve ser o início ou o fim da transação, ou outra coisa?
Isso pode parecer um pouco exigente, mas a pergunta é válida em qualquer banco de dados que suporte leituras e modificações de dados simultâneas. A execução de nossa consulta de exemplo pode levar um período de tempo arbitrariamente longo (dada uma tabela grande o suficiente ou restrições de recursos, por exemplo), portanto, alterações simultâneas não são apenas possíveis, elas podem ser inevitáveis .
A questão fundamental aqui é o potencial para o fenômeno de simultaneidade chamado de fantasma no padrão SQL. Enquanto estamos contando linhas na tabela, outra transação simultânea pode inserir novas linhas em um local que já verificamos ou alterar uma linha que ainda não verificamos de forma que ela se mova para um local que já procuramos. As pessoas costumam pensar em fantasmas como linhas que podem aparecer magicamente quando lidas pela segunda vez, em uma declaração separada, mas os efeitos podem ser muito mais sutis do que isso.
Exemplo de inserção simultânea
Este primeiro exemplo mostra como as inserções simultâneas podem produzir um não repetível ler e/ou resultar em linhas sendo ignoradas. Imagine que nossa tabela de teste contém inicialmente cinco linhas com os valores abaixo:

Agora definimos o nível de isolamento para leitura repetível, iniciamos uma transação e executamos nossa consulta de contagem. Como seria de esperar, o resultado é cinco . Nenhum grande mistério até agora.
Ainda executando dentro da mesma transação de leitura repetível , executamos a consulta de contagem novamente, mas desta vez enquanto uma segunda transação simultânea está inserindo novas linhas na mesma tabela. O diagrama abaixo mostra a sequência de eventos, com a segunda transação adicionando linhas com os valores 2 e 6 (você deve ter notado que esses valores se destacaram pela ausência logo acima):
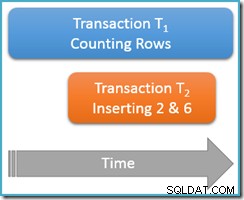
Se nossa consulta de contagem estivesse sendo executada no serializável nível de isolamento, seria garantido contar cinco ou sete linhas (consulte o artigo anterior desta série se precisar de uma atualização sobre por que esse é o caso). Como funciona a execução no menos isolado nível de leitura repetível afetam as coisas?
Bem, leitura repetível O isolamento garante que a segunda execução da consulta de contagem verá todas as linhas lidas anteriormente e elas estarão no mesmo estado de antes. O problema é que o isolamento de leitura repetível não diz nada sobre como a transação deve tratar as novas linhas (os fantasmas).
Imagine que nossa transação de contagem de linhas (T1 ) tem uma estratégia de execução física em que as linhas são pesquisadas em ordem crescente de índice. Este é um caso comum, por exemplo, quando uma varredura de índice de árvore b com ordem direta é empregada pelo mecanismo de execução. Agora, logo após a transação T1 conta as linhas 1 e 3 em ordem crescente, transação T2 pode entrar, inserir novas linhas 2 e 6 e, em seguida, confirmar sua transação.
Embora estejamos pensando principalmente em comportamentos lógicos neste momento, devo mencionar que não há nada na implementação de bloqueio do SQL Server de leitura repetível para evitar transação T2 de fazer isso. Bloqueios compartilhados obtidos pela transação T1 em linhas lidas anteriormente impedem que essas linhas sejam alteradas, mas não impedem novas linhas de ser inserido no intervalo de valores testados por nossa consulta de contagem (diferentemente dos bloqueios de intervalo de chaves no isolamento serializável de bloqueio).
De qualquer forma, com as duas novas linhas confirmadas, a transação T1 continua sua busca em ordem crescente, eventualmente encontrando as linhas 4, 5, 6 e 7. Observe que T1 vê a nova linha 6 neste cenário, mas não nova linha 2 (devido à busca ordenada e sua posição quando ocorreu a inserção).
O resultado é que a leitura repetível a consulta de contagem informa que a tabela contém seis linhas (valores 1, 3, 4, 5, 6 e 7). Este resultado é inconsistente com o resultado anterior de cinco linhas obtido dentro da mesma transação . A segunda leitura contou a linha fantasma 6, mas perdeu a linha fantasma 2. Tanto para o significado intuitivo de uma leitura repetível!
Exemplo de atualização simultânea
Uma situação semelhante pode surgir com uma atualização simultânea em vez de uma inserção. Imagine que nossa tabela de teste seja redefinida para conter as mesmas cinco linhas de antes:

Desta vez, só executaremos nossa consulta de contagem uma vez na leitura repetível nível de isolamento, enquanto uma segunda transação simultânea atualiza a linha com o valor 5 para ter um valor de 2:
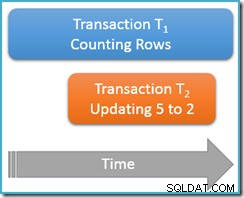
Transação T1 novamente começa a contar as linhas, (em ordem crescente) encontrando as linhas 1 e 3 primeiro. Agora, a transação T2 entra, altera o valor da linha 5 para 2 e confirma:

Eu mostrei a linha atualizada na mesma posição de antes para deixar a mudança clara, mas o índice b-tree que estamos verificando mantém os dados em ordem lógica, então a imagem real está mais próxima disso:

A questão é que a transação T1 está varrendo simultaneamente essa mesma estrutura em ordem direta, sendo atualmente posicionada logo depois a entrada para o valor 3. A consulta de contagem continua varrendo a partir desse ponto, encontrando as linhas 4 e 7 (mas não a linha 5, é claro).
Para resumir, a consulta de contagem viu as linhas 1, 3, 4 e 7 neste cenário. Ele relata uma contagem de quatro linhas – o que é estranho, porque a tabela parece conter cinco linhas ao longo!
Uma segunda execução da consulta de contagem na mesma transação de leitura repetível reportaria cinco linhas, por razões semelhantes às anteriores. Como nota final, caso você esteja se perguntando, exclusões simultâneas não oferecem uma oportunidade para uma anomalia baseada em fantasma sob isolamento de leitura repetível.
Considerações finais
Os exemplos anteriores usaram varreduras em ordem crescente de uma estrutura de índice para apresentar uma visão simples do tipo de efeitos que os fantasmas podem ter em uma leitura repetida inquerir. É importante entender que essas ilustrações não dependem de maneira importante da direção da varredura ou do fato de que um índice b-tree foi usado. Por favor, não formam a visão de que as varreduras ordenadas são de alguma forma responsáveis e, portanto, devem ser evitadas!
Os mesmos efeitos de simultaneidade podem ser vistos com uma varredura em ordem decrescente de uma estrutura de índice ou em vários outros cenários de acesso físico a dados. O ponto geral é que os fenômenos fantasmas são especificamente permitidos (embora não exigidos) pelo padrão SQL para transações no nível de isolamento de leitura repetível.
Nem todas as transações exigem a garantia de isolamento completo fornecida pelo isolamento serializável e poucos sistemas poderiam tolerar os efeitos colaterais se o fizessem. No entanto, vale a pena ter uma boa compreensão de exatamente quais garantias os vários níveis de isolamento fornecem.
Próxima vez
A próxima parte desta série analisa as garantias de isolamento ainda mais fracas oferecidas pelo nível de isolamento padrão do SQL Server, leitura confirmada .
[ Veja o índice para toda a série ]



