Esta é a parte final de uma série de cinco partes que se aprofunda na maneira como os planos paralelos do modo de linha do SQL Server começam a ser executados. A parte 1 inicializou o contexto de execução zero para a tarefa pai e a parte 2 criou a árvore de verificação de consulta. A parte 3 iniciou a verificação de consulta, executou algumas fase inicial processamento e iniciou as primeiras tarefas paralelas adicionais na ramificação C. A Parte 4 descreveu a sincronização de troca e o início das ramificações do plano paralelo C &D.
Início das tarefas paralelas da Filial B
Um lembrete dos ramos neste plano paralelo (clique para ampliar):
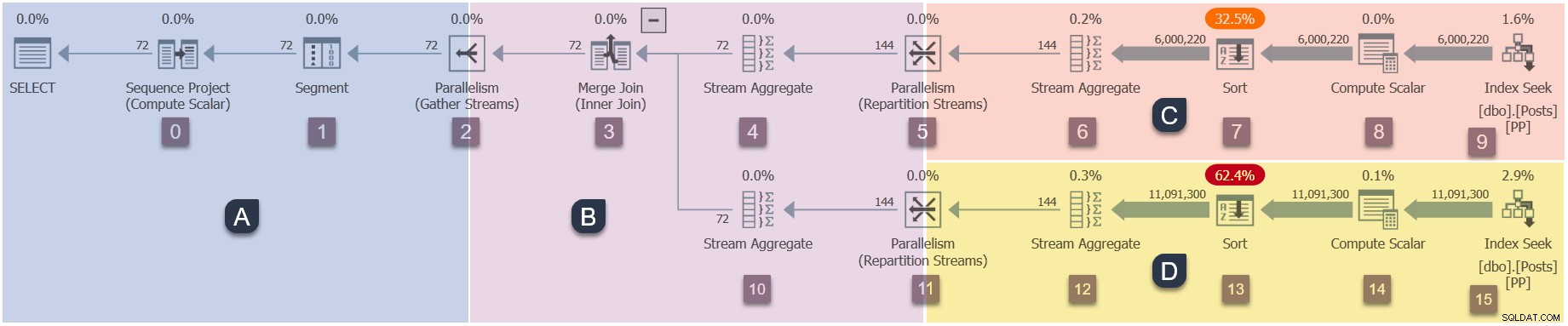
Este é o quarto estágio na sequência de execução:
- Ramo A (tarefa pai).
- Ramo C (tarefas paralelas adicionais).
- Ramo D (tarefas paralelas adicionais).
- Ramo B (tarefas paralelas adicionais).
O único encadeamento ativo no momento (não suspenso em
CXPACKET ) é a tarefa pai , que está no lado do consumidor da troca de fluxos de repartição no nó 11 na Filial B: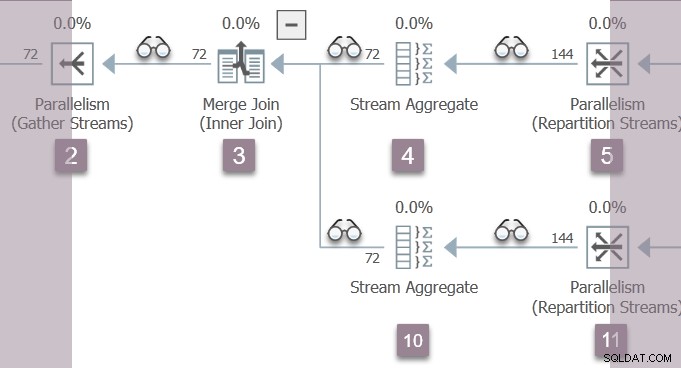
A tarefa pai agora retorna das fases iniciais aninhadas chamadas, definindo os tempos decorridos e de CPU em profilers à medida que avança. O primeiro e o último horário ativo não atualizado durante o processamento da fase inicial. Lembre-se de que esses números estão sendo registrados no contexto de execução zero — as tarefas paralelas da Filial B ainda não existem.
A tarefa principal ascende a árvore do nó 11, através do agregado de fluxo no nó 10 e a junção de mesclagem no nó 3, de volta à troca de fluxos de coleta no nó 2.
O processamento da fase inicial está concluído .
Com as
EarlyPhases originais chame no nó 2 reúna fluxos troca finalmente concluída, a tarefa pai volta a abrir essa troca (você pode se lembrar dessa chamada logo no início desta série). O método aberto no nó 2 agora chama CQScanExchangeNew::StartAllProducers para criar as tarefas paralelas para Filial B. A tarefa principal agora aguarda em
CXPACKET no consumidor lado do nó 2 reúna fluxos intercâmbio. Essa espera continuará até que as tarefas da Filial B recém-criadas tenham concluído seu Open aninhado chamadas e retornou para concluir a abertura do lado do produtor da troca de fluxos de coleta. Tarefas paralelas da filial B abertas
As duas novas tarefas paralelas na Filial B começam no produtor lado do nó 2 reúna fluxos intercâmbio. Seguindo o modelo usual de execução iterativa do modo de linha, eles chamam:
CQScanXProducerNew::Open(lado do produtor do nó 2 aberto).CQScanProfileNew::Open(profiler para o nó 3).CQScanMergeJoinNew::Open(junção de mesclagem do nó 3).CQScanProfileNew::Open(profiler para o nó 4).CQScanStreamAggregateNew::Open(agregado de fluxo do nó 4).CQScanProfileNew::Open(profiler para o nó 5).CQScanExchangeNew::Open(troca de fluxos de partição).
As tarefas paralelas seguem a entrada externa (superior) para a junção de mesclagem, assim como o processamento da fase inicial.
Concluindo a troca
Quando as tarefas da Filial B chegam ao consumidor lado da troca de fluxos de repartição no nó 5, cada tarefa:
- Registros com a porta de troca (
CXPort). - Cria os pipes (
CXPipe) que conectam essa tarefa a uma ou mais tarefas do lado do produtor (dependendo do tipo de troca). A troca atual é um fluxo de repartição, portanto, cada tarefa do consumidor tem dois pipes (no DOP 2). Cada consumidor pode receber linhas de qualquer um dos dois produtores. - Adiciona um
CXPipeMergepara mesclar linhas de vários pipes (já que esta é uma troca que preserva a ordem). - Cria pacotes de linha (confusamente chamado
CXPacket) usado para controle de fluxo e para armazenar linhas nos tubos de troca. Eles são alocados da memória de consulta concedida anteriormente.
Depois que ambas as tarefas paralelas do lado do consumidor concluírem esse trabalho, a troca do nó 5 está pronta para ser executada. Os dois consumidores (na Filial B) e os dois produtores (na Filial C) abriram a porta de troca, então o nó 5
CXPACKET aguarda o fim . Ponto de verificação
Como as coisas estão:
- A tarefa pai no Ramo A está esperando em
CXPACKETno lado do consumidor do nó 2 reúnem troca de fluxos. Essa espera continuará até que os dois produtores do nó 2 retornem e abram a troca. - As duas tarefas paralelas no Ramo B são executáveis . Eles acabaram de abrir o lado do consumidor da troca de fluxos de repartição no nó 5.
- As duas tarefas paralelas no ramo C acabaram de ser liberados de seu
CXPACKETesperam e agora são executáveis . Os dois agregados de fluxo no nó 6 (um por tarefa paralela) podem começar a agregar linhas das duas classificações no nó 7. Lembre-se de que as buscas de índice no nó 9 foram fechadas há algum tempo, quando as classificações concluíram sua fase de entrada. - As duas tarefas paralelas no Ramo D estão esperando em
CXPACKETno lado produtor da troca de fluxos de repartição no nó 11. Eles estão esperando que o lado consumidor do nó 11 seja aberto pelas duas tarefas paralelas na Filial B. As buscas de índice foram encerradas e as classificações estão prontas para fazer a transição para sua fase de saída.
Vários ramos ativos
Esta é a primeira vez que temos várias filiais (B e C) ativas ao mesmo tempo, o que pode ser um desafio para discutir. Felizmente, o design da consulta de demonstração é tal que as agregações de fluxo no Ramo C produzirão apenas algumas linhas. O pequeno número de linhas de saída estreitas caberá facilmente nos buffers do pacote de linhas na troca de fluxos de repartição do nó 5. As tarefas da Filial C podem, portanto, continuar com seu trabalho (e eventualmente encerrar) sem esperar que o lado do consumidor dos fluxos de repartição do nó 5 busque quaisquer linhas.
Convenientemente, isso significa que podemos deixar as duas tarefas paralelas do Branch C serem executadas em segundo plano sem nos preocuparmos com elas. Precisamos apenas nos preocupar com o que as duas tarefas paralelas da Filial B estão fazendo.
Abertura da filial B concluída
Um lembrete da Filial B:
Os dois trabalhadores paralelos na Filial B retornam de seu
Open chamadas na troca de fluxos de repartição do nó 5. Isso os leva de volta pela agregação de fluxo no nó 4, para a junção de mesclagem no nó 3. Porque estamos ascendendo a árvore no
Open método, os criadores de perfil acima do nó 5 e do nó 4 estão gravando o último ativo tempo, bem como acumular os tempos decorridos e de CPU (por tarefa). Não estamos executando as fases iniciais na tarefa pai agora, portanto, os números registrados para o contexto de execução zero não são afetados. Na junção de mesclagem, as duas tarefas paralelas da Filial B começam decrescente a entrada interna (inferior), levando-os através do agregado de fluxo no nó 10 (e alguns criadores de perfil) para o lado do consumidor da troca de fluxos de repartição no nó 11.
A ramificação D retoma a execução
Uma repetição dos eventos da Filial C no nó 5 agora ocorre nos fluxos de repartição do nó 11. O lado do consumidor da troca do nó 11 é concluído e aberto. Os dois produtores na Filial D encerram seu
CXPACKET espera, tornando-se executável novamente. Vamos deixar as tarefas da Filial D serem executadas em segundo plano, colocando seus resultados em buffers de troca. 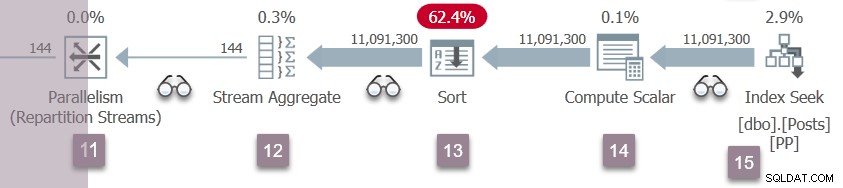
Agora existem seis tarefas paralelas (dois cada nos ramos B, C e D) compartilhando cooperativamente o tempo nos dois agendadores atribuídos a tarefas paralelas adicionais nesta consulta.
Abertura da Filial A concluída
As duas tarefas paralelas na Filial B retornam de seu
Open chamadas na troca de fluxos de repartição do nó 11, passando pelo agregado de fluxo do nó 10, por meio da junção de mesclagem no nó 3 e de volta ao lado do produtor dos reunir fluxos no nó 2. Profiler último ativo e os tempos de CPU e decorridos acumulados são atualizados à medida que subimos na árvore em Open aninhado métodos. No produtor lado da troca de fluxos de coleta, as duas tarefas paralelas da Filial B sincronizam abrindo a porta de troca e aguardam em
CXPACKET para o lado do consumidor abrir. A tarefa principal A espera no lado do consumidor dos fluxos de coleta agora está lançada de seu
CXPACKET wait, o que permite concluir a abertura da porta de troca no lado do consumidor. Isso, por sua vez, libera os produtores de seu (breve) CXPACKET esperar. Os fluxos de coleta do nó 2 agora foram abertos por todos os proprietários. Concluindo a verificação de consulta
A tarefa principal agora sobe a árvore de varredura de consulta da troca de fluxos de coleta, retornando do
Open chamadas na central, segmento , e projeto de sequência operadores da Filial A. Isso conclui a abertura a árvore de verificação de consulta, iniciada há muito tempo pela chamada para
CQueryScan::StartupQuery . Todas as ramificações do plano paralelo já começaram a ser executadas. Retornando linhas
O plano de execução está pronto para começar a retornar linhas em resposta a
GetRow chamadas na raiz da árvore de varredura de consulta, iniciada por uma chamada para CQueryScan::GetRow . Não vou entrar em detalhes, pois está estritamente além do escopo de um artigo sobre como os planos paralelos iniciam . Ainda assim, a breve sequência é:
- A tarefa pai chama
GetRowno projeto de sequência, que chamaGetRowno segmento, que chamaGetRowno consumidor lado da troca de fluxos de coleta. - Se ainda não houver linhas disponíveis na troca, a tarefa pai aguarda em
CXCONSUMER. - Enquanto isso, as tarefas paralelas do Branch B de execução independente têm chamado recursivamente
GetRowcomeçando no produtor lado da troca de fluxos de coleta. - As linhas são fornecidas à Filial B pelos lados do consumidor das trocas de fluxos de repartição nos nós 5 e 12.
- As ramificações C e D ainda estão processando linhas de suas classificações por meio de seus respectivos agregados de fluxo. As tarefas da Filial B podem ter que esperar em
CXCONSUMERnos fluxos de repartição dos nós 5 e 12 para que um pacote completo de linhas fique disponível. - Linhas emergentes do
GetRowaninhado as chamadas na Filial B são montadas em pacotes de linha no produtor lado da troca de fluxos de coleta. - O
CXCONSUMERda tarefa pai esperar no lado do consumidor dos fluxos de coleta termina quando um pacote fica disponível. - Uma linha de cada vez é processada pelos operadores pai na Filial A e, finalmente, para o cliente.
- Eventualmente, as linhas se esgotam e um
Closeaninhado chame ondulações na árvore, nas trocas, e a execução paralela chega ao fim.
Resumo e notas finais
Primeiro, um resumo da sequência de execução deste plano de execução paralelo específico:
- A tarefa principal abre a filial A . Fase inicial o processamento começa na troca de fluxos de coleta.
- As chamadas de fase inicial da tarefa pai descem da árvore de varredura para a busca de índice no nó 9 e, em seguida, sobem de volta para a troca de reparticionamento no nó 5.
- A tarefa pai inicia tarefas paralelas para a ramificação C , então espera enquanto eles lêem todas as linhas disponíveis nos operadores de classificação de bloqueio no nó 7.
- As chamadas de fase inicial sobem até a junção de mesclagem e, em seguida, descem a entrada interna para a troca no nó 11.
- Tarefas para Ramo D são iniciadas como para a Filial C, enquanto a tarefa pai aguarda no nó 11.
- As chamadas de fase inicial retornam do nó 11 até os fluxos de coleta. A fase inicial termina aqui.
- A tarefa pai cria tarefas paralelas para a ramificação B , e aguarda até que a abertura da filial B seja concluída.
- As tarefas da ramificação B atingem os fluxos de repartição do nó 5, sincronizam, concluem a troca e liberam as tarefas da ramificação C para começar a agregar linhas das classificações.
- Quando as tarefas da Filial B atingem os 12 fluxos de repartição do nó, elas sincronizam, concluem a troca e liberam as tarefas da Filial D para começar a agregar linhas da classificação.
- As tarefas da ramificação B retornam à troca de fluxos de coleta e sincronizam, liberando a tarefa pai de sua espera. A tarefa pai agora está pronta para iniciar o processo de retorno de linhas ao cliente.
Você pode gostar de assistir a execução deste plano no Sentry One Plan Explorer. Certifique-se de habilitar a opção "Com perfil de consulta ao vivo" da coleção Plano Real. O bom de executar a consulta diretamente no Plan Explorer é que você poderá percorrer várias capturas no seu próprio ritmo e até retroceder. Ele também mostrará um resumo gráfico de E/S, CPU e esperas sincronizadas com os dados de criação de perfil de consulta ao vivo.
Notas adicionais
Aumentar a árvore de varredura de consulta durante o processamento da fase inicial define o primeiro e o último horário ativo em cada iterador de criação de perfil para a tarefa pai, mas não acumula o tempo decorrido ou de CPU. Subindo na árvore durante
Open e GetRow chama em uma tarefa paralela define o último horário ativo e acumula o tempo decorrido e de CPU em cada iterador de criação de perfil por tarefa. O processamento de fase inicial é específico para planos paralelos de modo de linha. É necessário garantir que as trocas sejam inicializadas na ordem correta e que todo o maquinário paralelo funcione corretamente.
A tarefa pai nem sempre executa todo o processamento da fase inicial. As fases iniciais começam em uma troca de raiz, mas como essas chamadas navegam na árvore depende dos iteradores encontrados. Eu escolhi uma junção de mesclagem para esta demonstração porque ela exige processamento de fase inicial para ambas as entradas.
As fases iniciais em (por exemplo) uma junção de hash paralela propagam-se apenas na entrada de compilação. Quando a junção de hash faz a transição para sua fase de teste, ela abre iteradores nessa entrada, incluindo quaisquer trocas. Outra rodada de processamento de fase inicial é iniciada, tratada por (exatamente) uma das tarefas paralelas, desempenhando o papel da tarefa pai.
Quando o processamento de fase inicial encontra uma ramificação paralela contendo um iterador de bloqueio, ele inicia as tarefas paralelas adicionais para essa ramificação e espera que esses produtores concluam sua fase de abertura. Essa ramificação também pode ter ramificações filhas, que são tratadas da mesma maneira, recursivamente.
Algumas ramificações em um plano paralelo de modo de linha podem precisar ser executadas em um único thread (por exemplo, devido a um agregado global ou superior). Essas 'zonas seriais' também são executadas em uma tarefa 'paralela' adicional, a única diferença é que há apenas uma tarefa, contexto de execução e trabalhador para essa ramificação. O processamento da fase inicial funciona da mesma forma, independentemente do número de tarefas atribuídas a uma ramificação. Por exemplo, uma 'zona serial' relata os tempos para a tarefa pai (ou uma tarefa paralela desempenhando essa função), bem como a única tarefa adicional. Isso se manifesta no plano de exibição como dados para o “thread 0” (fases iniciais), bem como o “thread 1” (a tarefa adicional).
Pensamentos finais
Tudo isso certamente representa uma camada extra de complexidade. O retorno desse investimento está no uso de recursos de tempo de execução (principalmente threads e memória), esperas de sincronização reduzidas, maior taxa de transferência, métricas de desempenho potencialmente precisas e uma chance minimizada de travamentos paralelos intra-consulta.
Embora o paralelismo de modo de linha tenha sido amplamente eclipsado pelo mecanismo de execução paralela de modo de lote mais moderno, o design do modo de linha ainda tem uma certa beleza. A maioria dos iteradores finge que ainda está executando em um plano serial, com quase toda a sincronização, controle de fluxo e agendamento manipulados pelas trocas. O cuidado e a atenção evidentes nos detalhes da implementação, como o processamento de fase inicial, permitem que até mesmo os maiores planos paralelos sejam executados com sucesso sem que o designer de consultas pense muito nas dificuldades práticas.



