Um evento recorrente, por definição, é um evento que se repete em um intervalo; também é chamado de evento periódico. Existem muitos aplicativos que permitem que seus usuários configurem eventos recorrentes. Como um sistema de banco de dados gerencia eventos recorrentes? Neste artigo, exploraremos uma maneira de lidar com eles.
A recorrência não é fácil para os aplicativos lidarem. Isso pode se tornar uma tarefa difícil, especialmente quando se trata de cobrir todos os cenários recorrentes possíveis – incluindo criar eventos quinzenais ou trimestrais ou permitir o reagendamento de todas as instâncias de eventos futuros.
Duas maneiras de gerenciar eventos recorrentes
Posso pensar em pelo menos duas maneiras de lidar com tarefas periódicas em um modelo de dados. Antes de discuti-los, vamos examinar rapidamente os requisitos desta tarefa. Em poucas palavras, uma gestão eficaz significa:
- Os usuários podem criar eventos regulares e recorrentes.
- Eventos diários, semanais, quinzenais, mensais, trimestrais, semestrais e anuais podem ser criados sem restrições de data de término.
- Os usuários podem reagendar ou cancelar uma instância de um evento ou todas as instâncias futuras de um evento.
Considerando esses parâmetros, duas formas de gerenciar eventos recorrentes no modelo de dados vêm à mente. Vamos chamá-los de maneira ingênua e de maneira especialista.
A maneira ingênua: Armazenar todas as instâncias recorrentes possíveis de um evento como linhas separadas em uma tabela. Nesta solução, exigimos apenas uma tabela, chamada
event . Esta tabela tem colunas como event_title , start_date , end_date , is_full_day_event , etc. O start_date e end_date colunas são tipos de dados de carimbo de data/hora; desta forma, eles podem acomodar eventos que não duram o dia todo. 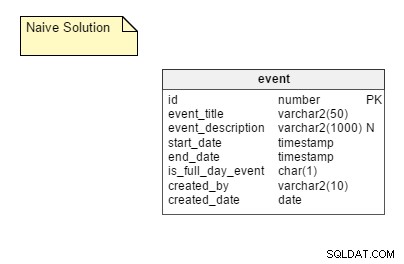
Os prós: Esta é uma abordagem bastante direta e a mais simples de implementar.
Os contras: A maneira ingênua tem algumas desvantagens significativas, incluindo:
- A necessidade de armazenar todas as instâncias possíveis de um evento. Se você estiver levando em consideração as necessidades de uma grande base de usuários, será necessário um grande espaço. No entanto, o espaço é bastante barato, então esse ponto não tem grande impacto.
- Um processo de atualização muito confuso. Suponha que um evento seja reagendado. Nesse caso, alguém precisa atualizar todas as instâncias dele. Um grande número de operações DML precisa ser realizado durante o reagendamento, o que cria um impacto negativo no desempenho do aplicativo.
- Tratamento de exceções. Todas as exceções devem ser tratadas normalmente, especialmente se você precisar voltar e editar o compromisso original depois de fazer uma exceção. Por exemplo, suponha que você avance a terceira instância de um evento recorrente em um dia. E se você editar posteriormente a hora do evento original? Você reinsere outro evento no dia original e deixa aquele que você trouxe? Desvincular a exceção? Tente alterá-lo adequadamente?
Event_id– Esta coluna é referenciada a partir doeventtabela, e atua como a chave primária nesta tabela. Ele mostra a relação de identificação entreeventerecurring_patternmesas. Essa coluna também garantirá que haja no máximo um padrão recorrente para cada evento.Recurring_type_id– Esta coluna indica o tipo de recorrência, seja diária, semanal, mensal ou anual.Max_num_of_occurrances– Há momentos em que não sabemos a data exata de término de um evento, mas sabemos quantas ocorrências (reuniões) são necessárias para completá-lo. Esta coluna armazena um número arbitrário que define o fim lógico de um evento.Separation_count– Você pode estar se perguntando como um evento quinzenal ou bi-anual pode ser configurado se houver apenas quatro valores de tipo de recorrência possíveis (diário, semanal, mensal, anual). A resposta é oseparation_countcoluna. Esta coluna significa o intervalo (em dias, semanas ou meses) antes que a próxima instância do evento seja permitida. Por exemplo, se um evento precisar ser configurado a cada duas semanas, separation_count =“1” para atender a este requisito. O valor padrão para esta coluna é "0".- O
recurring_type_idseria "semanal". - O
separation_countseria "1". - O
day_of_weekseria "2". Week_of_month– Esta coluna é para eventos que estão agendados para uma determinada semana do mês – ou seja, o primeiro, segundo, último, penúltimo, etc. Podemos armazenar esses valores como 1,2,3, 4,.. (contando de início do mês) ou -1,-2,-3,... (contando a partir do final do mês).Day_of_month– Há casos em que um evento está agendado em um determinado dia do mês, digamos, dia 25. Esta coluna atende a esse requisito. Comoweek_of_month, ele pode ser preenchido com números positivos ( "7" para o 7º dia a partir do início do mês) ou números negativos ( "-7" para o sétimo dia a partir do final do mês).- O
recurring_type_idseria "mensal". - O
separation_countseria "2". - O
day_of_monthseria "11". - Todas as colunas restantes seriam nulas.
- Eventos que ocorrem em feriados. Quando uma ocorrência específica de um evento ocorre em um feriado, ela deve ser automaticamente transferida para o dia útil imediatamente seguinte ao feriado? Ou deve ser cancelado automaticamente? Em que circunstâncias qualquer uma dessas situações se aplicaria?
- Conflitos entre eventos. E se determinados eventos (que são mutuamente exclusivos) ocorrerem no mesmo dia?
A maneira de especialista: Armazenar um padrão recorrente e gerar instâncias de eventos passados e futuros programaticamente. Esta solução aborda as desvantagens da solução ingênua. Explicaremos a solução especializada em detalhes neste artigo.
O modelo proposto
Criando eventos
Todos os eventos programados, independentemente de sua natureza regular ou recorrente, são registrados no
event tabela. Nem todos os eventos são recorrentes, então precisaremos de uma coluna de sinalização, is_recurring , nesta tabela para especificar explicitamente eventos recorrentes. O event_title e event_description colunas armazenam o assunto e um breve resumo dos eventos. As descrições de eventos são opcionais, razão pela qual esta coluna é anulável. Como seus nomes sugerem, o
start_date e end_date colunas mantêm as datas de início e término dos eventos. No caso de eventos regulares, essas colunas armazenam as datas reais de início e término. No entanto, eles também armazenam as datas da primeira e da última ocorrência de eventos periódicos. Manteremos a end_date coluna como anulável, pois os usuários podem configurar eventos recorrentes sem data de término. Nesse caso, ocorrências futuras até uma data de término hipotética (digamos, por um ano) seriam mostradas na interface do usuário. O
is_full_date_event coluna significa se um evento é um evento de dia inteiro. No caso de um evento de dia inteiro, o start_time e end_time colunas seriam nulas; essa é a razão para manter essas duas colunas anuláveis. O
created_by e created_date as colunas armazenam qual usuário criou um evento e a data em que o evento foi criado. Em seguida, há o
parent_event_id coluna. Isso desempenha um papel importante em nosso modelo de dados. Explicarei seu significado mais adiante. 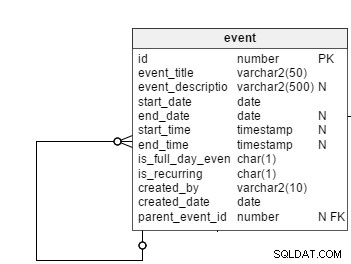
Gerenciando recorrências
Agora vamos direto para a declaração do problema principal:E se um evento recorrente for criado no
event table – ou seja, o is_recurring flag para o evento é “Y”? Conforme explicado anteriormente, armazenaremos um padrão recorrente para eventos para que possamos construir todas as suas ocorrências futuras. Vamos começar criando o
recurring_pattern tabela. Esta tabela tem as seguintes colunas:Vamos considerar o significado das colunas restantes em termos dos diferentes tipos de recorrências.
Recorrência diária
Nós realmente precisamos capturar um padrão para um evento recorrente diário? Não, porque todos os detalhes necessários para gerar um padrão de recorrência diário já estão registrados no
event tabela. O único cenário que requer um padrão é quando os eventos são agendados para dias alternados ou a cada X dias. Nesse caso, o
separation_count column nos ajudará a entender o padrão de recorrência e derivar outras instâncias. Recorrência semanal
Exigimos apenas uma coluna adicional,
day_of_week , para armazenar em qual dia da semana esse evento ocorrerá. Supondo que segunda-feira seja o primeiro dia da semana e domingo seja o último, os valores possíveis seriam 1,2,3,4,5,6 e 7. Alterações apropriadas no código que gera ocorrências de eventos individuais devem ser feitas conforme necessário. Todas as colunas restantes seriam nulas para eventos semanais. Vamos pegar um tipo clássico de evento semanal:a ocorrência quinzenal. Nesse caso, diremos que acontece toda semana alternada em uma terça-feira, o segundo dia da semana. Então:

Recorrência mensal
Além de
day_of_week , exigimos mais duas colunas para atender a qualquer cenário de recorrência mensal. Em resumo, essas colunas são:Vamos agora considerar um exemplo mais complicado – um evento trimestral. Suponha que uma empresa agende um evento de projeção de resultado trimestral para o 11º dia do primeiro mês de cada trimestre (geralmente janeiro, abril, julho e outubro). Então neste caso:
No exemplo acima, supomos que o usuário esteja criando a projeção de resultado trimestral em janeiro. Observe que essa lógica de separação começará a contar a partir do mês, semana ou dia em que o evento for criado.
Em linhas semelhantes, eventos semestrais podem ser registrados como eventos mensais com um
separation_count de “5”. 
Recorrência anual
A recorrência anual é bastante simples. Temos colunas para determinados dias da semana e do mês, portanto, exigimos apenas uma coluna adicional para o mês do ano. Chamamos esta coluna de
month_of_year . 
Como lidar com exceções de eventos recorrentes
Agora vamos às exceções. E se uma instância específica de um evento recorrente for cancelada ou reprogramada? Todas essas instâncias são registradas separadamente no
event_instance_exception tabela. Vamos dar uma olhada em duas colunas,
Is_rescheduled e is_cancelled . Essas colunas significam se esta instância foi reprogramada para alguma data/hora posterior ou cancelada completamente. Por que eu tenho duas colunas separadas para isso? Bem, pense nos eventos que foram primeiro remarcados e depois cancelados completamente. Isso acontece, e temos uma maneira de gravá-lo com essas colunas. Além dessas duas colunas, todas as colunas restantes agem da mesma forma que no
event tabela. 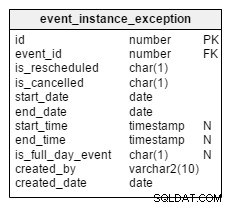
Por que vincular dois eventos por meio de parent_event_id ?
Existem aplicativos que permitem aos usuários reprogramar todas as instâncias futuras de um evento recorrente. Nesses casos, temos duas opções. Podemos armazenar todas as instâncias futuras em
event_instance_exception (dica:não é uma solução aceitável). Ou podemos criar um novo evento com novos parâmetros de data/hora no event tabela e vinculá-lo com seu evento anterior (o evento pai) por meio do id_parent_event coluna. Com esta solução, podemos obter todas as ocorrências passadas de um evento, mesmo quando seu padrão de recorrência foi alterado.
Como melhorar o tratamento de eventos recorrentes?
Existem algumas áreas mais complexas em torno de eventos recorrentes que não discutimos. Aqui estão dois:
Que mudanças precisamos fazer para construir essas capacidades? Por favor, conte-nos suas opiniões na seção de comentários.