Mencionei brevemente que os dados do modo de lote são normalizados no meu último artigo Bitmaps de modo de lote no SQL Server. Todos os dados em um lote são representados por um valor de oito bytes nesse formato normalizado específico, independentemente do tipo de dados subjacente.
Essa afirmação, sem dúvida, levanta algumas questões, principalmente sobre como dados com um comprimento muito maior que oito bytes podem ser armazenados dessa maneira. Este artigo explora a representação normalizada de dados em lote, explica por que nem todos os tipos de dados de oito bytes podem caber em 64 bits e mostra um exemplo de como tudo isso afeta o desempenho do modo de lote.
Demonstração
Vou começar com um exemplo que mostra o formato de dados em lote fazendo uma diferença importante em um plano de execução. Você precisará do SQL Server 2016 (ou posterior) e do Developer Edition (ou equivalente) para reproduzir os resultados mostrados aqui.
A primeira coisa que precisamos é de uma tabela de
bigint números de 1 a 102.400 inclusive. Esses números serão usados para preencher uma tabela columnstore em breve (o número de linhas é o mínimo necessário para obter um único segmento compactado). DROP TABLE IF EXISTS #Numbers;
GO
CREATE TABLE #Numbers (n bigint NOT NULL PRIMARY KEY);
GO
INSERT #Numbers (n)
SELECT
n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
n
OFFSET 0 ROWS
FETCH FIRST 102400 ROWS ONLY
OPTION (MAXDOP 1); Pushdown agregado bem-sucedido
O script a seguir usa a tabela de números para criar outra tabela contendo os mesmos números deslocados por um valor específico. Esta tabela usa columnstore para seu armazenamento primário para produzir a execução em modo de lote posteriormente.
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
@Start bigint = CONVERT(bigint, -4611686018427387905);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Execute as seguintes consultas de teste na nova tabela columnstore:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1); A adição dentro do
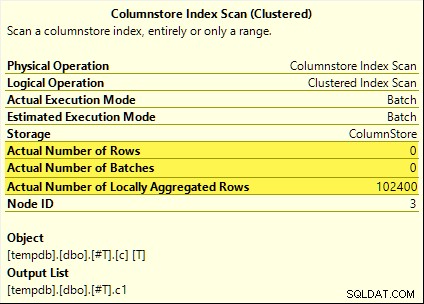
SUM é evitar transbordamento. Você pode pular o WHERE cláusulas (para evitar um plano trivial) se você estiver executando o SQL Server 2017. Todas essas consultas se beneficiam do empilhamento agregado. O agregado é calculado na Varredura de índice de armazenamento de colunas em vez do modo de lote Hash Aggregate operador. Os planos de pós-execução mostram zero linhas emitidas pela varredura. Todas as 102.400 linhas foram "agregadas localmente".
A
SUM plano é mostrado abaixo como um exemplo:
Pushdown agregado malsucedido
Agora solte e recrie a tabela de teste columnstore com o deslocamento reduzido em um:
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
-- Note this value has decreased by one
@Start bigint = CONVERT(bigint, -4611686018427387906);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Execute exatamente as mesmas consultas de teste de empilhamento agregadas de antes:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1); Desta vez, apenas o
COUNT_BIG agregado atinge o empilhamento agregado (somente SQL Server 2017). O MAX e SUM agregados não. Aqui está o novo SUM plano para comparação com o do primeiro teste:
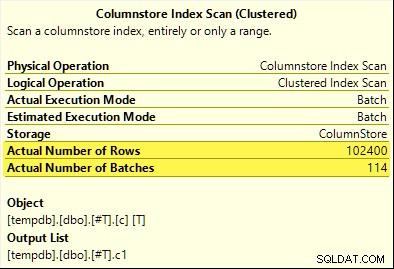
Todas as 102.400 linhas (em 114 lotes) são emitidas pela Varredura de índice de armazenamento de colunas , processado pelo Compute Scalar , e enviado para o Hash Aggregate .
Por que a diferença? Tudo o que fizemos foi compensar o intervalo de números armazenados na tabela columnstore por um!
Explicação
Mencionei na introdução que nem todos os tipos de dados de oito bytes podem caber em 64 bits. Este fato é importante porque muitas otimizações de desempenho de modo de armazenamento de colunas e lote só funcionam com dados de 64 bits de tamanho. O pushdown agregado é uma dessas coisas. Existem muitos outros recursos de desempenho (nem todos documentados) que funcionam melhor (ou funcionam) apenas quando os dados cabem em 64 bits.
Em nosso exemplo específico, o pushdown agregado está desativado para um segmento columnstore quando ele contém mesmo um valor de dados que não cabe em 64 bits. O SQL Server pode determinar isso a partir dos metadados de valor mínimo e máximo associados a cada segmento sem verificar todos os dados. Cada segmento é avaliado separadamente.
O pushdown agregado ainda funciona para o
COUNT_BIG agregar apenas no segundo teste. Esta é uma otimização adicionada em algum momento no SQL Server 2017 (meus testes foram executados no CU16). É lógico não desabilitar o empilhamento agregado quando estamos apenas contando linhas e não fazendo nada com os valores de dados específicos. Não consegui encontrar nenhuma documentação para essa melhoria, mas isso não é tão incomum nos dias de hoje. Como observação lateral, notei que o SQL Server 2017 CU16 habilita o empilhamento agregado para os tipos de dados não suportados anteriormente
real , float , datetimeoffset e numeric com precisão maior que 18 — quando os dados cabem em 64 bits. Isso também não está documentado no momento da redação. Ok, mas por quê?
Você pode estar fazendo a pergunta bastante razoável:Por que um conjunto de
bigint valores de teste aparentemente cabem em 64 bits mas o outro não? Se você adivinhou que o motivo estava relacionado a
NULL , dê-se um carrapato. Mesmo que a coluna da tabela de teste seja definida como NOT NULL , o SQL Server usa o mesmo layout de dados normalizado para bigint se os dados permitem nulos ou não. Há razões para isso, que vou descompactar pouco a pouco. Deixe-me começar com algumas observações:
- Cada valor de coluna em um lote é armazenado em exatamente oito bytes (64 bits), independentemente do tipo de dados subjacente. Esse layout de tamanho fixo torna tudo mais fácil e rápido. A execução do modo de lote tem tudo a ver com velocidade.
- Um lote tem 64 KB e contém entre 64 e 900 linhas, dependendo do número de colunas projetadas. Isso faz sentido, pois os tamanhos dos dados das colunas são fixados em 64 bits. Mais colunas significa que menos linhas cabem em cada lote de 64 KB.
- Nem todos os tipos de dados do SQL Server podem caber em 64 bits, mesmo em princípio. Uma string longa (para dar um exemplo) pode nem caber em um lote inteiro de 64 KB (se isso fosse permitido), muito menos em uma única entrada de 64 bits.
O SQL Server resolve este último problema armazenando uma referência de 8 bytes para dados maiores que 64 bits. O valor de dados 'grande' é armazenado em outro lugar na memória. Você pode chamar esse arranjo de armazenamento “fora da linha” ou “fora do lote”. Internamente, é chamado de dados profundos .
Agora, os tipos de dados de oito bytes não podem caber em 64 bits quando anuláveis. Pegue
bigint NULL por exemplo . O intervalo de dados não nulo pode exigir os 64 bits completos e ainda precisamos de outro bit para indicar nulo ou não. Resolvendo os problemas
A solução criativa e eficiente para esses desafios é reservar o bit menos significativo (LSB) do valor de 64 bits como um sinalizador. O sinalizador indica em lote armazenamento de dados quando o LSB está limpo (definido como zero). Quando o LSB está definido (para um), pode significar uma de duas coisas:
- O valor é nulo; ou
- O valor é armazenado fora do lote (são dados profundos).
Esses dois casos são diferenciados pelo estado dos 63 bits restantes. Quando eles são todos zero , o valor é
NULL . Caso contrário, o 'valor' é um ponteiro para dados profundos armazenados em outro lugar. Quando visualizado como um número inteiro, definir o LSB significa que os ponteiros para dados profundos sempre serão ímpares números. Nulos são representados pelo número (ímpar) 1 (todos os outros bits são zero). Os dados em lote são representados por par números porque o LSB é zero.
Isso não significa que o SQL Server só pode armazenar números pares em um lote! Significa apenas que a representação normalizada dos valores de coluna subjacentes sempre terão um LSB zero quando armazenados “em lote”. Isso fará mais sentido em um momento.
Normalização de dados em lote
A normalização é executada de diferentes maneiras, dependendo do tipo de dados subjacente. Para
bigint o processo é:- Se os dados forem nulos , armazena o valor 1 (somente o conjunto LSB).
- Se o valor puder ser representado em 63 bits , desloca todos os bits uma posição para a esquerda e zera o LSB. Ao olhar para o valor como um número inteiro, isso significa duplicar O valor que. Por exemplo, o
biginto valor 1 é normalizado para o valor 2. Em binário, são sete bytes zero seguidos por00000010. O LSB sendo zero indica que são dados armazenados em linha. Quando o SQL Server precisa do valor original, ele desloca o valor de 64 bits para a direita em uma posição (jogando fora o sinalizador LSB). - Se o valor não puder ser representado em 63 bits, o valor é armazenado fora do lote como dados profundos . O ponteiro em lote tem o LSB definido (tornando-o um número ímpar).
O processo de teste se um
bigint valor pode caber em 63 bits é:- Armazenar o bruto*
bigintvalor no registrador de processador de 64 bitsr8. - Armazenar o dobro do valor de
r8no registrorax. - Mude os bits de
raxum lugar à direita. - Teste se os valores em
raxer8são iguais.
* Observe que o valor bruto não pode ser determinado de forma confiável para todos os tipos de dados por uma conversão T-SQL em um tipo binário. O resultado do T-SQL pode ter uma ordem de byte diferente e também pode conter metadados, por exemplo.
time precisão fracionária de segundos. Se o teste na etapa 4 for aprovado, sabemos que o valor pode ser dobrado e dividido pela metade em 64 bits — preservando o valor original.
Um alcance reduzido
O resultado de tudo isso é que o intervalo de
bigint os valores que podem ser armazenados em lote são reduzidos por um bit (porque o LSB não está disponível). Os seguintes intervalos inclusivos de bigint os valores serão armazenados fora do lote como dados profundos :- -4.611.686.018.427.387.905 a -9.223.372.036.854.775.808
- +4.611.686.018.427.387.904 a +9.223.372.036.854.775.807
Em troca de aceitar que estes
bigint limitações de intervalo, a normalização permite que o SQL Server armazene (a maioria) bigint valores, nulos e referências de dados profundos em lote . Isso é muito mais simples e mais eficiente em termos de espaço do que ter estruturas separadas para nulidade e referências de dados profundas. Também facilita muito o processamento de dados em lote com instruções do processador SIMD. Normalização de outros tipos de dados
SQL Server contém normalização código para cada um dos tipos de dados suportados pela execução em modo de lote. Cada rotina é otimizada para lidar com o layout binário de entrada com eficiência e para criar dados profundos apenas quando necessário. A normalização sempre resulta na reserva do LSB para indicar dados nulos ou profundos, mas o layout dos 63 bits restantes varia de acordo com o tipo de dados.
Sempre em lote
Os dados normalizados para os seguintes tipos de dados são sempre armazenados em lote uma vez que eles nunca precisam de mais de 63 bits:
datetime(n)– redimensionado internamente paratime(7)datetime2(n)– redimensionado internamente paradatetime2(7)integersmallinttinyintbit– usa otinyintimplementação.smalldatetimedatetimerealfloatsmallmoney
Depende
Os seguintes tipos de dados podem ser armazenados em dados em lote ou profundos dependendo do valor dos dados:
bigint– conforme descrito anteriormente.money– mesmo intervalo em lote quebigintmas dividido por 10.000.numeric/decimal– 18 dígitos decimais ou menos em lote independentemente de precisão declarada. Por exemplo, odecimal(38,9)valor -999999999.999999999 pode ser representado como o inteiro de 8 bytes -999999999999999999 (f21f494c589c0001hex), que pode ser duplicado para -1999999999999999998 (e43e9298b1380002hex) reversivelmente dentro de 64 bits. O SQL Server sabe para onde vai o ponto decimal da escala de tipo de dados.datetimeoffset(n)– em lote se o valor do tempo de execução caberá emdatetimeoffset(2)independentemente de precisão de segundos fracionários declarados.timestamp– o formato interno é diferente do display. Por exemplo, umtimestampexibido do T-SQL como0x000000000099449Aé representado internamente como9a449900 00000000(em hexadecimal). Esse valor é armazenado como dados profundos porque não cabe em 64 bits quando duplicado (um bit deslocado para a esquerda).
Sempre dados profundos
Os itens a seguir são sempre armazenados como dados profundos (exceto nulos) :
uniqueidentifiervarbinary(n)– incluindo(max)binarychar/varchar(n)/nchar/nvarchar(n)/sysnameincluindo(max)– esses tipos também podem usar um dicionário (quando disponível).text/ntext/image/xml– usa ovarbinary(n)implementação.
Para ser claro, nulos para todos Os tipos de dados compatíveis com o modo de lote são armazenados em lote como o valor especial 'um'.
Considerações finais
Você pode esperar aproveitar ao máximo as otimizações de armazenamento de colunas e modo de lote disponíveis ao usar tipos de dados e valores que se encaixam em 64 bits. Você também terá a melhor chance de se beneficiar de melhorias incrementais do produto ao longo do tempo, por exemplo, as melhorias mais recentes para agregar empilhamento observadas no texto principal. Nem todas as vantagens de desempenho serão tão visíveis nos planos de execução, ou mesmo documentadas. No entanto, as diferenças podem ser extremamente significativas.
Também devo mencionar que os dados são normalizados quando um operador de plano de execução em modo de linha fornece dados a um pai em modo de lote ou quando uma varredura sem armazenamento em coluna produz lotes (modo em lote no armazenamento de linhas). Há um adaptador invisível de linha para lote que chama a rotina de normalização apropriada em cada valor de coluna antes de adicioná-lo ao lote. Evitar tipos de dados com normalização complicada e armazenamento de dados profundo também pode produzir benefícios de desempenho aqui.



