Os profissionais de dados nem sempre conseguem usar bancos de dados com um design ideal. Às vezes, as coisas que fazem você chorar são coisas que fizemos a nós mesmos, porque pareciam boas ideias na época. Às vezes, são por causa de aplicativos de terceiros. Às vezes eles simplesmente antecedem você.
O que estou pensando neste post é quando sua coluna datetime (ou datetime2, ou melhor ainda, datetimeoffset) é na verdade duas colunas – uma para a data e outra para a hora. (Se você tiver uma coluna separada novamente para o deslocamento, eu lhe darei um abraço na próxima vez que o vir, porque você provavelmente teve que lidar com todos os tipos de mágoa.)
Fiz uma pesquisa no Twitter e descobri que esse é um problema muito real que cerca de metade de vocês tem que lidar com data e hora de vez em quando.
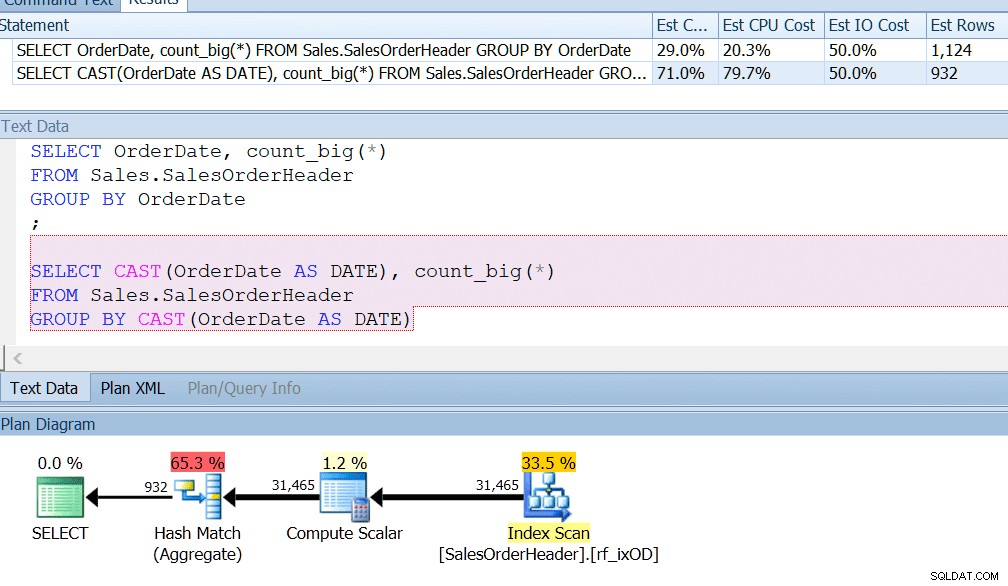
A AdventureWorks quase faz isso – se você olhar na tabela Sales.SalesOrderHeader, verá uma coluna de data e hora chamada OrderDate, que sempre tem datas exatas. Aposto que, se você é um desenvolvedor de relatórios na AdventureWorks, provavelmente já escreveu consultas que procuram o número de pedidos em um determinado dia, usando GROUP BY OrderDate ou algo assim. Mesmo se você soubesse que esta era uma coluna de data e hora e havia potencial para ela também armazenar um horário diferente da meia-noite, você ainda diria GROUP BY OrderDate apenas para usar um índice corretamente. GROUP BY CAST (OrderDate AS DATE) simplesmente não funciona.
Eu tenho um índice no OrderDate, como você faria se estivesse consultando regularmente essa coluna, e posso ver que o agrupamento por CAST(OrderDate AS DATE) é cerca de quatro vezes pior do ponto de vista da CPU.
Então, entendo por que você ficaria feliz em consultar sua coluna como se fosse uma data, simplesmente sabendo que terá um mundo de dor se o uso dessa coluna mudar. Talvez você resolva isso tendo uma restrição na mesa. Talvez você acabou de colocar a cabeça na areia.
E quando alguém chega e diz “Sabe, devemos armazenar a hora em que os pedidos acontecem também”, bem, você pensa em todo o código que assume que OrderDate é simplesmente uma data, e imagina que ter uma coluna separada chamada OrderTime (tipo de dados de tempo, por favor) será a opção mais sensata. Eu entendo. Não é o ideal, mas funciona sem quebrar muita coisa.
Neste ponto, recomendo que você também crie OrderDateTime, que seria uma coluna computada unindo as duas (o que você deve fazer adicionando o número de dias desde o dia 0 a CAST(OrderDate as datetime2), em vez de tentar adicionar o tempo a data, que geralmente é muito mais confusa). E então indexe OrderDateTime, porque isso seria sensato.
Mas, muitas vezes, você se encontrará com data e hora como colunas separadas, basicamente sem nada que possa fazer a respeito. Você não pode adicionar uma coluna computada, porque é um aplicativo de terceiros e você não sabe o que pode quebrar. Tem certeza que eles nunca fazem SELECT *? Um dia espero que eles nos deixem adicionar colunas e escondê-las, mas por enquanto, você certamente corre o risco de quebrar coisas.
E, você sabe, até msdb faz isso. Ambos são inteiros. E é por causa da compatibilidade com versões anteriores, presumo. Mas duvido que você esteja pensando em adicionar uma coluna computada a uma tabela no msdb.
Então, como podemos questionar isso? Vamos supor que queremos encontrar as entradas que estavam dentro de um determinado intervalo de data e hora?
Vamos fazer algumas experiências.
Primeiro, vamos criar uma tabela com 3 milhões de linhas e indexar as colunas que nos interessam.
select identity(int,1,1) as ID, OrderDate,
dateadd(minute, abs(checksum(newid())) % (60 * 24), cast('00:00' as time)) as OrderTime
into dbo.Sales3M
from Sales.SalesOrderHeader
cross apply (select top 100 * from master..spt_values) v;
create index ixDateTime on dbo.Sales3M (OrderDate, OrderTime) include (ID); (Eu poderia ter feito disso um índice clusterizado, mas acho que um índice não clusterizado é mais típico para o seu ambiente.)
Nossos dados são assim, e eu quero encontrar linhas entre, digamos, 2 de agosto de 2011 às 8h30 e 5 de agosto de 2011 às 21h30.
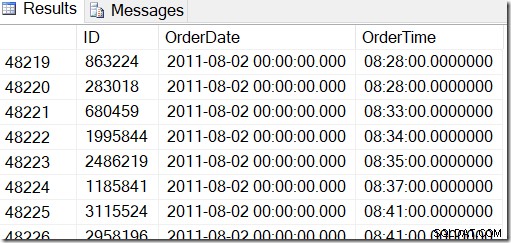
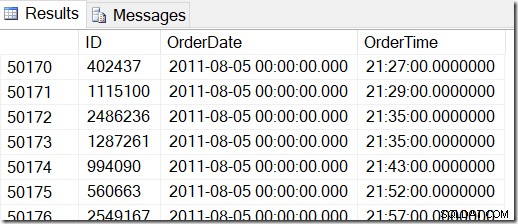
Ao examinar os dados, posso ver que quero todas as linhas entre 48221 e 50171. São 50171-48221+1=1951 linhas (o +1 é porque é um intervalo inclusivo). Isso me ajuda a ter certeza de que meus resultados estão corretos. Provavelmente você teria semelhante em sua máquina, mas não exato, pois usei valores aleatórios ao gerar minha tabela.
Eu sei que não posso simplesmente fazer algo assim:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and OrderTime between '8:30' and '21:30';
... porque isso não inclui algo que aconteceu durante a noite no dia 4. Isso me dá 1268 linhas – claramente não está certo.
Uma opção é combinar as colunas:
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30';
Isso dá os resultados corretos. Sim. É só que isso é completamente não-sargável e nos dá um Scan em todas as linhas da nossa tabela. Em nossas 3 milhões de linhas, pode levar segundos para executar isso.
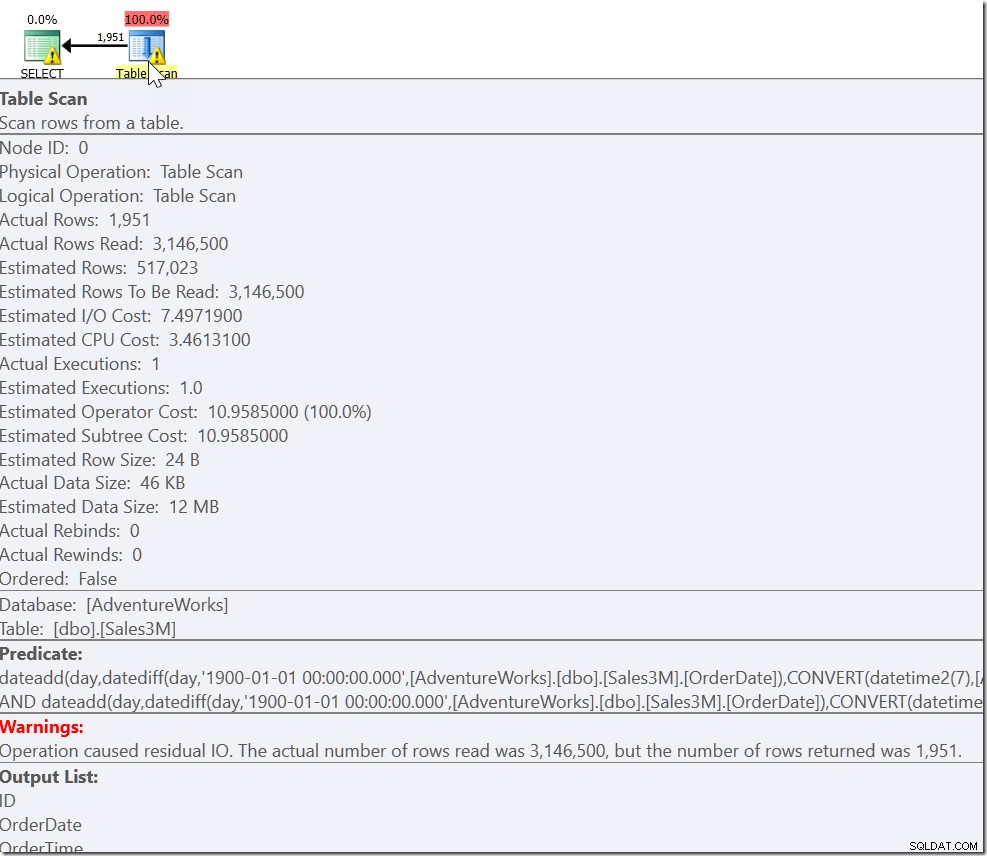
Nosso problema é que temos um caso comum e dois casos especiais. Sabemos que cada linha que satisfaça OrderDate> '20110802' E OrderDate <'20110805' é aquela que queremos. Mas também precisamos de todas as linhas que são a partir das 8h30 em 20110802 e até às 21h30 em 20110805. E isso nos leva a:
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') or (OrderDate = '20110802' and OrderTime >= '8:30') or (OrderDate = '20110805' and OrderTime <= '21:30');
OR é horrível, eu sei. Também pode levar a Scans, embora não necessariamente. Aqui eu vejo três Buscas de Índice, sendo concatenadas e então verificadas quanto à exclusividade. O Query Optimizer obviamente percebe que não deve retornar a mesma linha duas vezes, mas não percebe que as três condições são mutuamente exclusivas. E, na verdade, se você estivesse fazendo isso em um intervalo em um único dia, obteria os resultados errados.
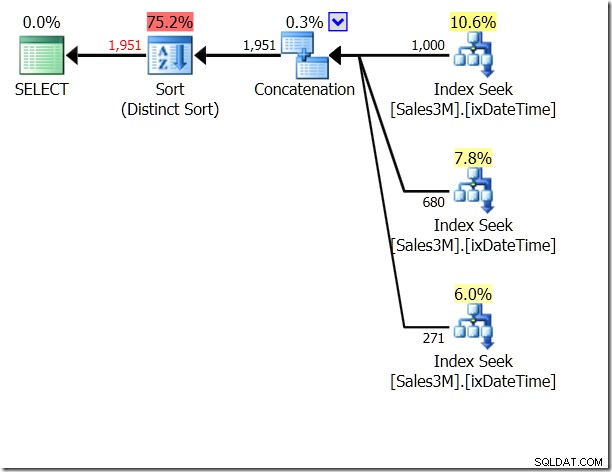
Poderíamos usar UNION ALL nisso, o que significaria que o QO não se importaria se as condições fossem mutuamente exclusivas. Isso nos dá três Buscas que são concatenadas – isso é muito bom.
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') union all select * from dbo.Sales3M where (OrderDate = '20110802' and OrderTime >= '8:30') union all select * from dbo.Sales3M where (OrderDate = '20110805' and OrderTime <= '21:30');

Mas ainda são três buscas. Estatísticas IO me dizem que são 20 leituras na minha máquina.

Agora, quando penso em sargabilidade, não penso apenas em evitar colocar colunas de índices dentro de expressões, também penso no que pode ajudar algo parece sargável.
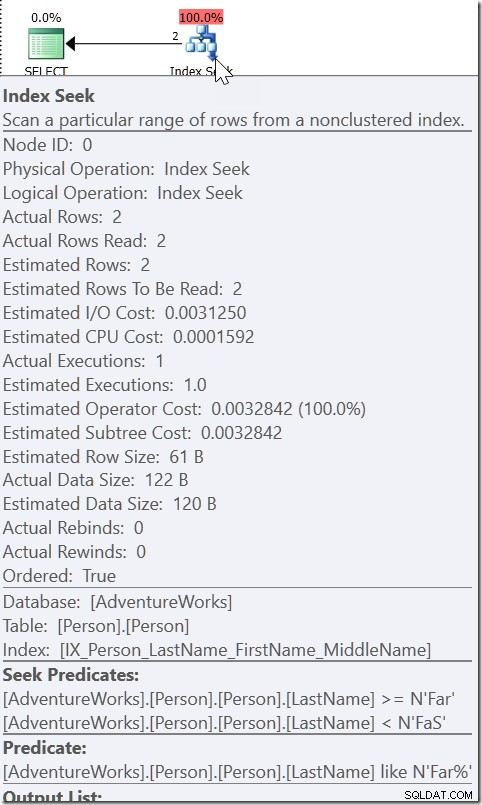
Tome WHERE LastName LIKE 'Far%' por exemplo. Quando olho para o plano para isso, vejo um Seek, com um Seek Predicate procurando por qualquer nome de Far até (mas não incluindo) FaS. E então há um Predicado Residual verificando a condição LIKE. Isso não ocorre porque o QO considera que LIKE é sargável. Se fosse, seria capaz de usar LIKE no predicado de busca. É porque sabe que tudo o que é satisfeito por essa condição LIKE deve estar dentro desse intervalo.
Take WHERE CAST(OrderDate AS DATE) ='20110805'
Aqui vemos um predicado de busca que procura valores OrderDate entre dois valores que foram trabalhados em outro lugar no plano, mas criando um intervalo no qual os valores corretos devem existir. Isso não é>=20110805 00:00 e <20110806 00:00 (que é o que eu teria feito), é outra coisa. O valor para início deste intervalo deve ser menor que 20110805 00:00, pois é>, não>=. Tudo o que podemos realmente dizer é que quando alguém dentro da Microsoft implementou como o QO deveria responder a esse tipo de predicado, eles forneceram informações suficientes para chegar ao que chamo de “predicado auxiliar”.
Agora, eu adoraria que a Microsoft tornasse mais funções sargáveis, mas essa solicitação específica foi encerrada muito antes de eles aposentarem o Connect.
Mas talvez o que quero dizer é que eles façam mais predicados auxiliares.
O problema com predicados auxiliares é que eles quase certamente leem mais linhas do que você deseja. Mas ainda é muito melhor do que examinar todo o índice.
Eu sei que todas as linhas que quero retornar terão OrderDate entre 20110802 e 20110805. Só que tem algumas que eu não quero.
Eu poderia apenas removê-los, e isso seria válido:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and not (OrderDate = '20110802' and OrderTime < '8:30') and not (OrderDate = '20110805' and OrderTime > '21:30');
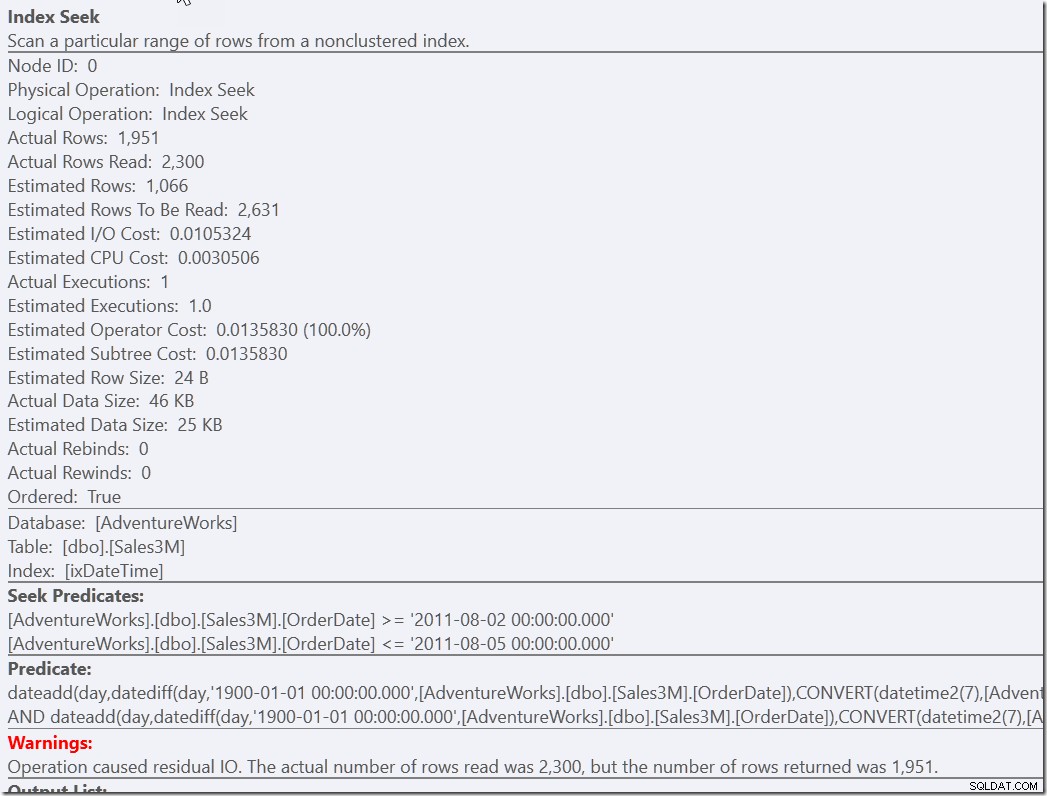
Mas eu sinto que esta é uma solução que requer algum esforço de pensamento para chegar. Menos esforço do lado do desenvolvedor é simplesmente fornecer um predicado auxiliar para nossa versão correta, mas lenta.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' and OrderDate between '20110802' and '20110805';
Ambas as consultas encontram as 2300 linhas que estão nos dias certos e precisam verificar todas essas linhas em relação aos outros predicados. Um deve verificar as duas condições NOT, o outro deve fazer alguma conversão de tipo e matemática. Mas ambos são muito mais rápidos do que tínhamos antes e fazem uma única Busca (13 leituras). Claro, recebo avisos sobre um RangeScan ineficiente, mas esta é a minha preferência em relação a três eficientes.
De certa forma, o maior problema com este último exemplo é que alguma pessoa bem-intencionada veria que o predicado auxiliar era redundante e poderia excluí-lo. Este é o caso de todos os predicados auxiliares. Então coloque um comentário.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' /* This next predicate is just a helper to improve performance */ and OrderDate between '20110802' and '20110805';
Se você tem algo que não se encaixa em um bom predicado sargável, elabore um que seja, e então descubra o que você precisa excluir dele. Você pode apenas encontrar uma solução melhor.
@rob_farley