Muito do código T-SQL de produção é escrito com a suposição implícita de que os dados subjacentes não serão alterados durante a execução. Como vimos no artigo anterior desta série, essa é uma suposição insegura, pois dados e entradas de índice podem se mover abaixo de nós, mesmo durante a execução de uma única instrução.
Onde o programador T-SQL está ciente dos tipos de problemas de correção e integridade de dados que podem surgir devido a modificações de dados simultâneas por outros processos, a solução mais comumente oferecida é agrupar as instruções vulneráveis em uma transação. Não está claro como o mesmo tipo de raciocínio seria aplicado ao caso de instrução única, que já está envolvido em uma transação de confirmação automática por padrão.
Deixando isso de lado por um segundo, a ideia de proteger uma área importante do código T-SQL com uma transação parece ser baseada em um mal-entendido das proteções oferecidas pelas propriedades da transação ACID. O elemento importante dessa sigla para a presente discussão é o Isolamento propriedade. A ideia é que o uso de uma transação forneça automaticamente um isolamento completo dos efeitos de outras atividades simultâneas.
A verdade é que as transações abaixo de
SERIALIZABLE fornecer apenas um grau de isolamento, que depende do nível de isolamento de transação atualmente efetivo. Para entender o que tudo isso significa para o nosso dia a dia T Práticas de codificação SQL, primeiro examinaremos detalhadamente o nível de isolamento serializável. Isolamento serializável
Serializable é o mais isolado dos níveis de isolamento de transação padrão. Também é o padrão nível de isolamento especificado pelo padrão SQL, embora o SQL Server (como a maioria dos sistemas de banco de dados comerciais) seja diferente do padrão nesse aspecto. O nível de isolamento padrão no SQL Server é leitura confirmada, um nível de isolamento inferior que exploraremos mais adiante na série.
A definição do nível de isolamento serializável no padrão SQL-92 contém o seguinte texto (ênfase minha):
Uma execução serializável é definida como uma execução das operações de transações SQL em execução simultânea que produz o mesmo efeito que algumas execuções seriais dessas mesmas transações SQL. Uma execução serial é aquela em que cada transação SQL é executada até a conclusão antes do início da próxima transação SQL.
Há uma distinção importante a ser feita aqui entre verdadeiramente serializados execução (onde cada transação realmente é executada exclusivamente até a conclusão antes do início da próxima) e serializável isolamento, onde as transações só precisam ter os mesmos efeitos como se eles foram executados em série (em alguma ordem não especificada).
Dito de outra forma, um sistema de banco de dados real pode se sobrepor fisicamente a execução de transações serializáveis no tempo (aumentando assim a concorrência), desde que os efeitos dessas transações ainda correspondam a alguma ordem possível de execução serial. Em outras palavras, transações serializáveis são potencialmente serializáveis em vez de ser realmente serializado .
Transações logicamente serializáveis
Deixe de lado todas as considerações físicas (como bloqueio) por um momento e pense apenas no processamento lógico de duas transações serializáveis simultâneas.
Considere uma tabela que contém um grande número de linhas, cinco das quais satisfazem algum predicado de consulta interessante. Uma transação serializável T1 começa a contar o número de linhas na tabela que correspondem a esse predicado. Algum tempo depois de T1 começa, mas antes de confirmar, uma segunda transação serializável T2 começa. Transação T2 adiciona quatro novas linhas que também satisfazem o predicado de consulta à tabela e confirma. O diagrama abaixo mostra a sequência temporal dos eventos:

A questão é:quantas linhas deve a consulta na transação serializável T1 contar? Lembre-se de que estamos pensando puramente nos requisitos lógicos aqui, portanto, evite pensar em quais bloqueios podem ser usados e assim por diante.
As duas transações se sobrepõem fisicamente no tempo, o que é bom. O isolamento serializável requer apenas que os resultados dessas duas transações correspondam a alguma execução serial possível. Existem claramente duas possibilidades para uma programação serial lógica de transações T1 e T2 :
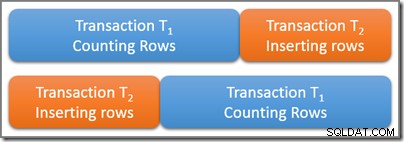
Usando a primeira programação serial possível (T1 então T2 ) o T1 consulta de contagem veria cinco linhas , porque a segunda transação não inicia até que a primeira seja concluída. Usando o segundo agendamento lógico possível, o T1 a consulta contaria nove linhas , porque a inserção de quatro linhas foi concluída logicamente antes do início da transação de contagem.
Ambas as respostas são logicamente corretas sob isolamento serializável. Além disso, nenhuma outra resposta é possível (portanto, a transação T1 não podia contar sete linhas, por exemplo). Qual dos dois resultados possíveis é realmente observado depende do tempo preciso e de vários detalhes de implementação específicos do mecanismo de banco de dados em uso.
Observe que não estamos concluindo que as transações são de alguma forma reordenadas no tempo. A execução física é livre para se sobrepor, conforme mostrado no primeiro diagrama, desde que o mecanismo de banco de dados garanta que os resultados reflitam o que teria acontecido se eles fossem executados em uma das duas sequências seriais possíveis.
Serializável e os fenômenos de simultaneidade
Além da serialização lógica, o padrão SQL também menciona que uma transação operando no nível de isolamento serializável não deve passar por certos fenômenos de simultaneidade. Ele não deve ler dados não confirmados (sem leituras sujas ); e uma vez que os dados tenham sido lidos, uma repetição da mesma operação deve retornar exatamente o mesmo conjunto de dados (leituras repetíveis sem fantasmas ).
O padrão faz questão de dizer que esses fenômenos de simultaneidade são excluídos no nível de isolamento serializável como uma consequência direta de exigir que a transação seja logicamente serializável. Em outras palavras, o requisito de serialização é suficiente por si só para evitar a leitura suja, leitura não repetível e fenômenos de simultaneidade fantasma. Por outro lado, evitar os três fenômenos de simultaneidade por si só não é suficiente para garantir a serialização, como veremos em breve.
Intuitivamente, as transações serializáveis evitam todos os fenômenos relacionados à simultaneidade porque são obrigadas a agir como se tivessem sido executadas em completo isolamento. Nesse sentido, o nível de isolamento de transação serializável corresponde às expectativas comuns dos programadores T-SQL de maneira bastante próxima.
Implementações serializáveis
O SQL Server usa uma implementação de bloqueio do nível de isolamento serializável, onde os bloqueios físicos são adquiridos e mantidos até o final da transação (daí a dica de tabela obsoleta
HOLDLOCK como sinônimo de SERIALIZABLE ). Essa estratégia não é suficiente para fornecer uma garantia técnica de serialização total, pois dados novos ou alterados podem aparecer em uma série de linhas previamente processadas pela transação. Esse fenômeno de simultaneidade é conhecido como fantasma e pode resultar em efeitos que não poderiam ter ocorrido em nenhuma programação serial.
Para garantir a proteção contra o fenômeno de simultaneidade fantasma, os bloqueios feitos pelo SQL Server no nível de isolamento serializável também podem incorporar bloqueio de intervalo de chaves para evitar que linhas novas ou alteradas apareçam entre valores de chave de índice examinados anteriormente. Os bloqueios de intervalo não são sempre adquiridos sob o nível de isolamento serializável; tudo o que podemos dizer em geral é que o SQL Server sempre adquire bloqueios suficientes para atender aos requisitos lógicos do nível de isolamento serializável. Na verdade, as implementações de bloqueio muitas vezes adquirem mais bloqueios e mais rígidos do que são realmente necessários para garantir a serialização, mas eu discordo.
O bloqueio é apenas uma das possíveis implementações físicas do nível de isolamento serializável. Devemos ter o cuidado de separar mentalmente os comportamentos específicos da implementação de bloqueio do SQL Server da definição lógica de serializável.
Como exemplo de uma estratégia física alternativa, veja a implementação do PostgreSQL de isolamento de instantâneo serializável, embora esta seja apenas uma alternativa. Cada implementação física diferente tem seus próprios pontos fortes e fracos, é claro. Como um aparte, observe que a Oracle ainda não fornece uma implementação totalmente compatível do nível de isolamento serializável. Tem um nível de isolamento nomeado serializável, mas não garante verdadeiramente que as transações serão executadas de acordo com alguma programação serial possível. Em vez disso, a Oracle fornece isolamento de instantâneo quando serializável é solicitado, da mesma forma que o PostgreSQL fazia antes do isolamento de instantâneo serializável (SSI ) foi implementado.
O isolamento de instantâneo não evita anomalias de simultaneidade como distorção de gravação, o que não é possível sob isolamento verdadeiramente serializável. Se você estiver interessado, poderá encontrar exemplos de distorção de gravação e outros efeitos de simultaneidade permitidos pelo isolamento de instantâneo no link SSI acima. Também discutiremos a implementação do nível de isolamento de instantâneo do SQL Server posteriormente na série.
Uma visualização pontual?
Uma razão pela qual passei tempo falando sobre as diferenças entre serialização lógica e execução fisicamente serializada é que, de outra forma, é fácil inferir garantias que podem não existir. Por exemplo, se você pensar em transações serializáveis como na verdade executando uma após a outra, você pode inferir que uma transação serializável necessariamente verá o banco de dados como existia no início da transação, fornecendo uma visão pontual.
Na verdade, esse é um detalhe específico da implementação. Lembre-se do exemplo anterior, onde a transação serializável T1 pode contar legitimamente cinco ou nove linhas. Se uma contagem de nove for retornada, a primeira transação verá claramente as linhas que não existiam no momento em que a transação foi iniciada. Esse resultado é possível no SQL Server, mas não no PostgreSQL SSI, embora ambas as implementações estejam em conformidade com os comportamentos lógicos especificados para o nível de isolamento serializável.
No SQL Server, as transações serializáveis não necessariamente veem os dados como existiam no início da transação. Em vez disso, os detalhes da implementação do SQL Server significam que uma transação serializável vê os dados confirmados mais recentes, a partir do momento em que os dados foram bloqueados para acesso. Além disso, é garantido que o conjunto de dados confirmados mais recentemente lidos não alterará sua associação antes que a transação termine.
Próxima vez
A próxima parte desta série examina o nível de isolamento de leitura repetível, que fornece garantias de isolamento de transação mais fracas do que serializável.
[ Veja o índice para toda a série ]



