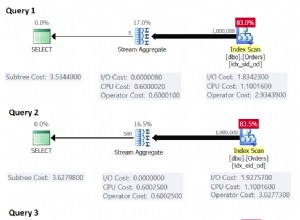
Sim, você pode, e você pode fazer o otimizador reconhecê-lo também.
Paul White tem essa cantiga :
WHERE NOT EXISTS (
SELECT d.[Data]
INTERSECT
SELECT i.[Data])
Isso funciona por causa da semântica de
INTERSECT que lidam com nulos. O que isso diz é "há não linhas na subconsulta composta de valor B e valor B", isso só será satisfeito se forem valores diferentes ou um for nulo e o outro não. Se ambos forem nulos, haverá uma linha com um valor nulo. Se você verificar o plano de consulta XML (não o gráfico no SSMS), verá que ele compila até
d.[Data] <> i.[Data] , mas o operador usado terá CompareOp="IS" e não EQ . Veja o plano completo aqui .
A parte relevante do plano é:
<Predicate>
<ScalarOperator ScalarString="@t1.[i] as [t1].[i] = @t2.[i] as [t2].[i]">
<Compare CompareOp="IS">
<ScalarOperator>
<Identifier>
<ColumnReference Table="@t1" Alias="[t1]" Column="i" />
</Identifier>
</ScalarOperator>
<ScalarOperator>
<Identifier>
<ColumnReference Table="@t2" Alias="[t2]" Column="i" />
</Identifier>
</ScalarOperator>
</Compare>
</ScalarOperator>
</Predicate>
Acho que o otimizador funciona muito bem dessa maneira, em vez de fazer
EXISTS / EXCEPT . Peço que você vote no Feedback do Azure para implementar um operador adequado