Ao implantar um cluster de banco de dados em servidores diferentes, você terá obtido a vantagem de replicação de melhorar a disponibilidade dos dados. No entanto, há necessidade de acompanhar os processos e ver se eles estão em execução ou não. Um dos programas utilizados neste processo é o Heartbeat que tem a capacidade de verificar e verificar a presença de recursos em um ou mais sistemas em um determinado cluster. Além do PostgreSQL e dos sistemas de arquivos para os quais os dados do PostgreSQL são armazenados, o DRBD é um dos recursos que vamos discutir neste artigo sobre como o programa Heartbeat pode ser usado.
A pulsação cardíaca
Conforme discutido anteriormente no blog do DRBD, ter uma alta disponibilidade de dados é obtido por meio da execução de diferentes instâncias do servidor, mas servindo os mesmos dados. Essas instâncias de servidor em execução podem ser definidas como um cluster em relação a um Heartbeat. Basicamente, cada instância do servidor é fisicamente capaz de fornecer o mesmo serviço que as outras nesse cluster. No entanto, apenas uma instância pode fornecer serviço ativamente por vez com a finalidade de garantir a alta disponibilidade de dados. Podemos, portanto, definir as outras instâncias como “hot-spares” que podem ser colocadas em serviço em caso de falha do mestre. O pacote Heartbeat pode ser baixado neste link. Depois de instalar este pacote, você pode configurá-lo para funcionar com seu sistema com o procedimento abaixo. Uma estrutura simples da configuração Heartbeat é:
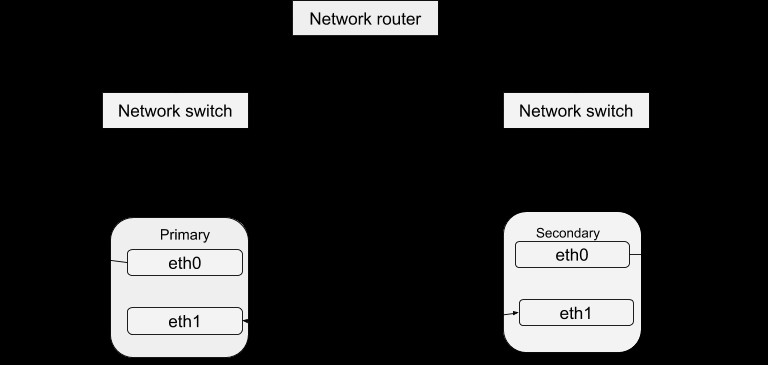
Configuração da pulsação
Olhando para este diretório /etc/ha.d você encontrará alguns arquivos que são usados no processo de configuração. O arquivo ha.cf forma a configuração principal de pulsação. Inclui a lista de todos os nós e horários para identificação de falhas além de direcionar o heartbeat sobre qual tipo de caminhos de mídia utilizar e como configurá-los. As informações de segurança do cluster são registradas no arquivo authkeys. As informações registradas nesses arquivos devem ser idênticas para todos os hosts do cluster e isso pode ser facilmente obtido por meio da sincronização entre todos os hosts. Isso quer dizer que qualquer mudança de informação em um host deve ser copiada para todos os outros.
Arquivo Ha.cf
O esboço básico do arquivo ha.cf é
logfacility local0
keepalive 3
Deadtime 7
warntime 3
initdead 30
mcast eth0 225.0.0.1 694 2 0
mcast eth1 225.0.0.2 694 1 0
auto_failback off
node drbd1
node drbd2
node drbd3-
Logfacility:este é usado para direcionar o Heartbeat em qual recurso de log do syslog ele deve usar para gravar mensagens. Os valores mais usados são auth, authpriv, user, local0, syslog e daemon. Você também pode decidir não ter nenhum log para que possa definir o valor como none.
logfacility none - Keepalive:é o tempo entre as pulsações, ou seja, a frequência com que o sinal de pulsação é enviado para os outros hosts. No código de exemplo acima, é definido como 3 segundos.
- Deadtime:é o atraso em segundos após o qual um nó é declarado como tendo falhado.
- Tempo de aviso:é o atraso em segundos após o qual um aviso é registrado em um log indicando que um nó não pode mais ser contatado.
- Initdead:este é o tempo em segundos para esperar durante a inicialização do sistema antes que o outro host seja considerado inativo.
- Mcast:é um procedimento de método definido para enviar um sinal de pulsação. Para o código de exemplo acima, o endereço de rede multicast está sendo usado em um dispositivo de rede limitado. Para um cluster múltiplo, o endereço multicast deve ser exclusivo para cada cluster. Você também pode escolher uma conexão serial sobre o multicast ou se você configurar de forma que haja várias interfaces de rede, use ambas para a conexão de pulsação como no exemplo. A vantagem de usar ambos é superar as chances de falha transitória que, consequentemente, pode causar um evento de falha inválido.
- Auto_failback:reconecta um servidor que falhou ao cluster se ele se tornar disponível. No entanto, pode causar confusão se o servidor for ligado e ficar online em um horário diferente. Em relação ao DRBD, se ele não estiver bem configurado, poderá acabar com mais de um conjunto de dados no mesmo servidor. Portanto, é aconselhável sempre desligá-lo.
- Nó:descreve o nó dentro do grupo de clusters Heartbeat. Você deve ter pelo menos 1 nó para cada.
Configurações adicionais
Você também pode definir informações de configuração adicionais, como:
ping 10.0.0.1
respawn hacluster /usr/lib64/heartbeat/ipfail
apiauth ipfail gid=haclient uid=hacluster
deadping 5- Ping:isso é importante para garantir que você tenha conectividade na interface pública para os servidores e conexão com outro host. É importante considerar o endereço IP em vez do nome do host da máquina de destino.
- Respawn:este é o comando a ser executado quando ocorre uma falha.
- Apiauth:é a autoridade para a falha. Você precisa configurar o ID do usuário e do grupo com o qual o comando será executado. O arquivo authkeys contém as informações de autorização para o cluster Heartbeat e essa chave é muito exclusiva para verificar máquinas em um determinado cluster Heartbeat.
- Deadping:define o tempo limite antes que uma não resposta acione uma falha.
Integração do Heartbeat com Postgres e DRBD
Conforme mencionado anteriormente, quando um servidor mestre falha, outro servidor com um determinado cluster entrará em ação para fornecer o mesmo serviço. Heartbeat auxilia na configuração de recursos que potencializam a seleção de um servidor em caso de falha. Por exemplo, define quais servidores individuais devem ser ativados ou descartados em caso de falha. Fazendo check-in no arquivo haresources no diretório /etc/ha.d, obtemos um resumo dos recursos que podem ser gerenciados. O caminho do arquivo de recurso é /etc/ha.d/resource.d e a definição de recurso está em uma linha que é:
drbd1 drbddisk Filesystem::/dev/drbd0::/drbd::ext3 postgres 10.0.0.1(observe os espaços em branco).
- Drbd1:refere-se ao nome do host preferencial para ser mais secante ao servidor que normalmente é utilizado como o mestre padrão para manipulação do serviço. Conforme mencionado no blog do DRBD, precisamos de recursos para nosso servidor e estes são definidos na linha como drbddisk, filesystem e postgres. O último campo é um endereço IP virtual que deve ser usado para compartilhar o serviço, ou seja, conectar-se ao servidor Postgres. Por padrão, ele será alocado ao servidor que estiver ativo quando o Heartbeat começar. Quando ocorre uma falha, esses recursos serão iniciados no servidor de backup em ordem de disposição quando o script correspondente for chamado. Na configuração, o script alternará o disco DRBD no host secundário para o modo primário, tornando o dispositivo de leitura/gravação.
- Sistema de arquivos:isso irá gerenciar os recursos do sistema de arquivos e neste caso o DRBD foi selecionado para que seja montado durante a chamada do script de recursos.
- Postgres:isso iniciará ou gerenciará o servidor Postgres
Às vezes você gostaria de receber notificações por e-mail. Para isso, adicione esta linha ao arquivo de recursos com seu e-mail para receber os textos de aviso:
MailTo:: example@sqldat.com::DRBDFailurePara iniciar a pulsação, você pode executar o comando
/etc/ha.d/heartbeat startou reinicialize os servidores primário e secundário. Agora se você executar o comando
$ /usr/lib64/heartbeat/hb_standbyO nó atual será acionado para liberar seus recursos de forma limpa para o outro nó.
Baixe o whitepaper hoje PostgreSQL Management &Automation with ClusterControlSaiba o que você precisa saber para implantar, monitorar, gerenciar e dimensionar o PostgreSQLBaixe o whitepaper
Como lidar com erros no nível do sistema
Às vezes, o kernel do servidor pode estar corrompido, indicando um possível problema com seu servidor. Você precisará configurar o servidor para se remover do cluster durante o evento de um problema. Esse problema é frequentemente chamado de kernel panic e, consequentemente, aciona uma reinicialização forçada em sua máquina. Você pode forçar uma reinicialização configurando kernel.panic e kernel.panic_on_oop do arquivo de controle do kernel /etc/sysctl.conf. Ou seja
kernel.panic_on_oops = 1
kernel.panic = 1Outra opção é fazê-lo a partir da linha de comando usando o comando sysctl, ou seja:
$ sysctl -w kernel.panic=1Você também pode editar o arquivo sysctl.conf e recarregar as informações de configuração usando este comando.
sysctl -pO valor indica o número de segundos a esperar antes de reinicializar. O segundo nó de pulsação deve detectar que o servidor está inativo e alternar o host de failover.
Conclusão
Heartbeat é um subsistema que permite a seleção de um servidor secundário em sistema primário e de backup quando um servidor ativo falha. Ele também determina se todos os outros servidores estão ativos. Também garante a transferência de recursos para o novo nó primário