A Replicação Transacional do SQL Server é uma das técnicas de replicação mais comuns usadas para copiar ou distribuir dados em vários destinos.
Nos artigos anteriores, discutimos a Replicação do SQL Server, como ela funciona internamente e como configurar a Replicação por meio do Assistente de Replicação ou da abordagem T-SQL. Agora, nos concentramos nos problemas de Replicação SQL e na solução de problemas deles corretamente.
Problemas de replicação SQL
A maioria dos clientes que usam a Replicação Transacional do SQL Server se concentra principalmente em obter dados quase em tempo real disponíveis nas instâncias do banco de dados do Assinante. Portanto, o DBA que gerencia a Replicação deve estar ciente de vários possíveis problemas relacionados à Replicação SQL que podem surgir. Além disso, o DBA deve ser capaz de resolver esses problemas em pouco tempo.
Podemos categorizar todos os problemas de replicação SQL nas categorias abaixo (com base na minha experiência):
Problemas de configuração
- Tamanho máximo de replicação de texto
- Serviço do SQL Server Agent não definido para iniciar o modo automático
- As instâncias de replicação não monitoradas entram em um estado de assinaturas não inicializadas
- Problemas conhecidos no SQL Server
Problemas de permissão
- Problemas de permissão de trabalho do SQL Server Agent
- A credencial de trabalho do agente de instantâneos não pode acessar o caminho da pasta de instantâneos
- A credencial de trabalho do Log Reader Agent não pode se conectar ao banco de dados do editor/distribuição
- A credencial de trabalho do Agente de Distribuição não pode se conectar ao banco de dados de distribuição/Assinante
Problemas de conectividade
- O servidor do editor não foi encontrado ou não estava acessível
- O servidor de distribuição não foi encontrado ou não estava acessível
- O servidor do assinante não foi encontrado ou não estava acessível
Problemas de integridade de dados
- Erros de violação de chave primária ou chave exclusiva
- Erros de linha não encontrada
- Foreign Key ou outros erros de violação de restrição
Problemas de desempenho
- Transações ativas de longa duração no banco de dados do Publisher
- Operações INSERT/UPDATE/DELETE em massa em artigos
- Grandes mudanças de dados em uma única transação
- Bloqueios no banco de dados de distribuição
Problemas relacionados a corrupção
- Corrupções no banco de dados do editor
- Corrupções no arquivo de log transacional do editor
- Corrupções no banco de dados de distribuição
- Corrupções no banco de dados do assinante
Preparação do Ambiente DEMO
Antes de mergulhar nos detalhes sobre os problemas de Replicação SQL, precisamos preparar nosso ambiente para a demonstração. Conforme discutido em meus artigos anteriores, quaisquer alterações de dados que ocorram no banco de dados do Assinante na Replicação Transacional não serão visíveis diretamente no banco de dados do Publicador. Assim, faremos algumas modificações diretamente no banco de dados do Assinante para fins de aprendizado.
Tome muito cuidado e não modifique nada nos bancos de dados de produção. Isso afetará a integridade dos dados dos bancos de dados do Assinante. Levarei os scripts de backup para cada alteração realizada e usarei esses scripts para corrigir os problemas de replicação SQL.
Alteração 1 – Inserindo registros na tabela Person.ContactType
Antes de inserir registros no Person.ContacType table, vamos dar uma olhada nessa estrutura de tabela, algumas restrições padrão e propriedades estendidas redigidas no script abaixo:
CREATE TABLE [Person].[ContactType](
[ContactTypeID] [int] IDENTITY(1,1) NOT FOR REPLICATION NOT NULL,
[Name] [dbo].[Name] NOT NULL,
[ModifiedDate] [datetime] NOT NULL,
CONSTRAINT [PK_ContactType_ContactTypeID] PRIMARY KEY CLUSTERED
(
[ContactTypeID] ASC
) ON [PRIMARY]
) ON [PRIMARY]
GO
Escolhi esta tabela porque tem menos colunas. É mais conveniente para fins de teste. Agora, vamos verificar o que temos sobre sua estrutura:
- ContactTypeId é definida como uma COLUNA DE IDENTIDADE - ela gerará automaticamente os valores da chave primária e NÃO PARA REPLICAÇÃO.
- NOT FOR REPLICATION é uma propriedade especial que pode ser usada em vários tipos de objetos, como tabelas, restrições como restrições de chave estrangeira, restrições de verificação, acionadores e colunas de identidade no editor ou no assinante ao usar apenas qualquer uma das metodologias de replicação. Ele permite que o DBA planeje ou implemente a replicação para garantir que certas funcionalidades se comportem de forma diferente no editor/assinante ao usar a replicação.
- No nosso caso, instruímos o SQL Server a usar os valores IDENTITY gerados apenas no banco de dados do Publisher. A propriedade IDENTITY não deve ser usada no Person.ContactType tabela no banco de dados do Assinante. Da mesma forma, podemos modificar as Restrições ou Acionadores para que se comportem de maneira diferente enquanto a Replicação estiver configurada usando esta opção.
- 2 outras colunas NOT NULL estão disponíveis na tabela.
- A tabela tem uma chave primária definida em ContactTypeId . Apenas para lembrar, a chave primária é um requisito obrigatório para replicação. Sem ele em uma tabela, não poderíamos replicar um artigo de tabela.
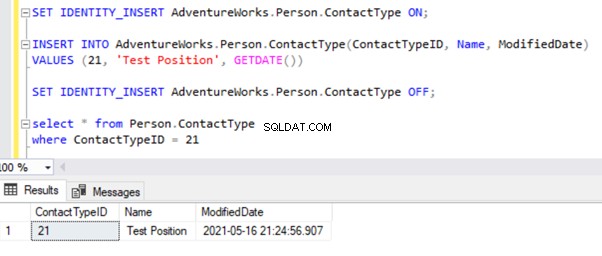
Agora, vamos INSERIR um registro de amostra para Pessoa .Tipo de contato tabela no AdventureWorks_REPL base de dados:
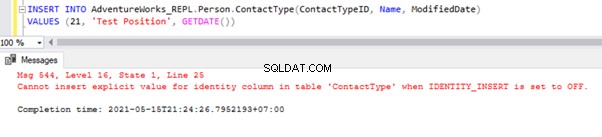
O INSERT direto na tabela falhará no banco de dados do Assinante porque a Propriedade de Identidade está desativada apenas para Replicação pela opção NÃO PARA REPLICAÇÃO. Sempre que realizamos a operação INSERT manualmente, ainda precisamos usar a opção SET IDENTITY_INSERT assim:
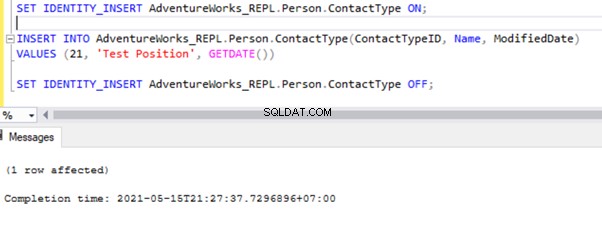
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType ON;
INSERT INTO AdventureWorks_REPL.Person.ContactType(ContactTypeID, Name, ModifiedDate)
VALUES (21, 'Test Position', GETDATE())
SET IDENTITY_INSERT AdventureWorks_REPL.Person.ContactType OFF;
Depois de adicionar a opção SET IDENTITY_INSERT, podemos INSERT gravar com sucesso no Person.ContactType tabela.
Executando o SELECT na tabela mostra o registro recém inserido:
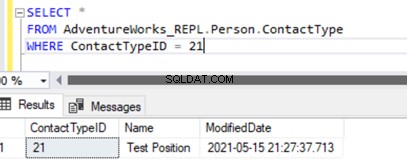
Adicionamos um novo registro apenas ao banco de dados do Assinante que não está disponível no banco de dados do Publicador no Person.ContactType tabela.
A execução de um SELECT na mesma tabela do banco de dados do Publisher não mostra nenhum registro. Assim, quaisquer alterações feitas no banco de dados do Assinante não são replicadas no banco de dados do Publicador.
Alteração 2 – Excluindo 2 registros da tabela Person.ContactType
Mantemos nosso familiar Person.ContactType tabela. Antes de excluir registros do banco de dados do Assinante, devemos verificar se esses registros existem no Publicador e no Assinante. Ver abaixo:
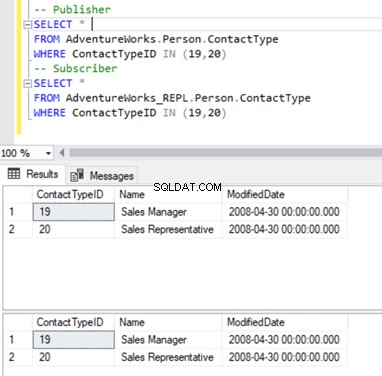
Agora, podemos excluir esses 2 ContactTypeId usando a seguinte declaração:
DELETE FROM AdventureWorks_REPL.Person.ContactType
WHERE ContactTypeID IN (19,20)
O script acima nos permite excluir 2 registros do Person.ContactType tabela no banco de dados do Assinante:
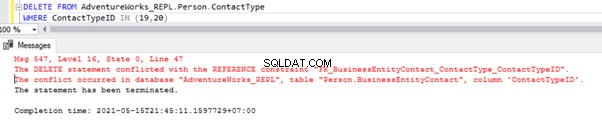
Temos a referência de chave estrangeira que impede a exclusão desses 2 registros do Person.ContactType tabela. Podemos lidar com esse cenário desabilitando temporariamente a restrição de chave estrangeira na tabela filha. O roteiro está abaixo:
ALTER TABLE [Person].[BusinessEntityContact] NOCHECK CONSTRAINT [FK_BusinessEntityContact_ContactType_ContactTypeID];
Uma vez que as chaves estrangeiras são desabilitadas, podemos excluir registros com sucesso do Person.ContactType tabela:
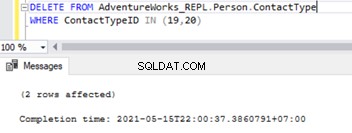
Isso também modificou a restrição Referencial de chave estrangeira nas 2 tabelas. Podemos tentar simular problemas de replicação SQL com base nesse cenário.
Em nosso cenário atual, sabemos que o Person.ContactType tabela não tinha dados sincronizados entre o Publicador e o Assinante.
Acredite, em poucos ambientes de Produção, desenvolvedores ou DBAs fazem algumas correções de dados no banco de dados do Assinante. como todas as alterações que realizamos anteriormente, causaram problemas de integridade de dados nos bancos de dados do Publicador e do Assinante na mesma tabela. Como DBA, preciso de um mecanismo mais simples para verificar esses tipos de discrepâncias. Caso contrário, tornaria patética a vida do DBA.
Aqui vem a solução da Microsoft que nos permite verificar as discrepâncias de dados nas tabelas do Publicador e do Assinante. Sim, você acertou. É o utilitário TableDiff que discutimos em artigos anteriores.
Utilitário TableDiff
O utilitário TableDiff é usado principalmente em ambientes de replicação. Também podemos usá-lo para outros casos em que precisamos comparar 2 tabelas do SQL Server para não convergência. Podemos compará-los e identificar as diferenças entre essas 2 tabelas. Em seguida, o utilitário ajuda a sincronizar o Destino tabela para a Fonte tabela gerando scripts INSERT/UPDATE/DELETE necessários.
TableDiff é um programa autônomo tablediff.exe instalado por padrão em C:\Program Files\Microsoft SQL Server\130\COM depois de instalarmos os componentes de replicação. Observe que o caminho padrão pode variar de acordo com os parâmetros de instalação do SQL Server. O número 130 no caminho indica a versão do SQL Server (SQL Server 2016). Portanto, ele variará para cada versão diferente da instalação do SQL Server.
Você pode acessar o utilitário TableDiff por meio do prompt de comando ou apenas de arquivos em lote. O utilitário não possui um assistente sofisticado ou GUI para usar. A sintaxe detalhada do utilitário TableDiff está no artigo do MSDN. Nosso artigo atual se concentra apenas em algumas opções necessárias.
Para comparar 2 tabelas usando o utilitário TableDiff, precisamos fornecer detalhes obrigatórios para as tabelas de origem e destino, como o nome do servidor de origem, o nome do banco de dados de origem, o nome do esquema de origem, o nome da tabela de origem, o nome do servidor de destino, o nome do banco de dados de destino, o destino Nome do Esquema e Nome da Tabela de Destino.
Vamos testar TableDiff com o Person.ContactType tabela com diferenças entre o Publicador e o Assinante.
Abra o prompt de comando e navegue até o caminho do utilitário TableDiff (se esse caminho não for adicionado às variáveis de ambiente).
Para visualizar a lista de todos os parâmetros disponíveis, digite o comando “tablediff-?” para listar todas as opções e parâmetros disponíveis. Os resultados estão abaixo:
Vamos verificar o Person.ContactType table em nossos bancos de dados de Publicador e Assinante executando o comando abaixo:
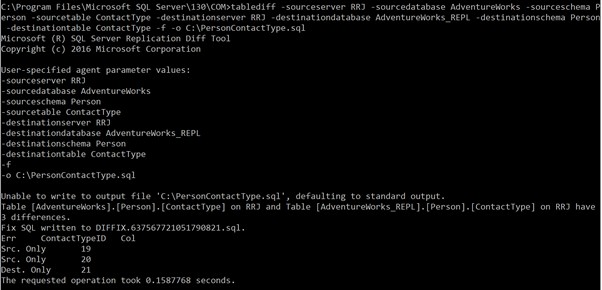
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactTypeObserve que não forneci o sourceuser , senha de origem , usuário de destino e senha de destino já que meu login do Windows tem acesso às tabelas. Se você deseja usar as credenciais do SQL em vez da autenticação do Windows, os parâmetros acima são obrigatórios para acessar as tabelas para comparação . Caso contrário, você receberá erros.
Os resultados da execução correta do comando:
Isso mostra que temos 3 discrepâncias. Um é um novo registro no banco de dados de destino e dois registros não estão disponíveis no banco de dados de destino.
Agora, vamos dar uma olhada rápida em Diversos opções disponíveis para o utilitário TableDiff.
- -et – registra o resumo do resultado na tabela de destino
- -dt – descarta a tabela de destino do resultado se ela já existir
- -f – gera um script DML T-SQL com instruções INSERT/UPDATE/DELETE para trazer a tabela de destino para a convergência com a tabela de origem.
- -o – nome do arquivo de saída se opção -f é usado para gerar o arquivo de convergência.
Criaremos um arquivo de convergência com o -f e -o opções para o nosso comando anterior:
tablediff -sourceserver RRJ -sourcedatabase AdventureWorks -sourceschema Person -sourcetable ContactType -destinationserver RRJ -destinationdatabase AdventureWorks_REPL -destinationschema Person -destinationtable ContactType -f -o C:\PersonContactType.sqlO arquivo de convergência foi criado com sucesso:
Como você pode ver, a criação de um novo arquivo na pasta raiz da unidade C:não é permitida por motivos de segurança. Portanto, ele mostra uma mensagem de erro e cria o arquivo de saída arquivo DIFFIX.*.sql na pasta do utilitário TableDiff. Quando abrimos esse arquivo, podemos ver os detalhes abaixo:

Os scripts INSERT foram criados para os 2 registros excluídos e os scripts DELETE foram criados para os registros recém-inseridos no banco de dados do Assinante. A ferramenta também se preocupa em usar as opções IDENTITY_INSERT conforme necessário para o Destino tabela. Portanto, esta ferramenta será de grande utilidade sempre que um DBA precisar sincronizar duas tabelas.
No nosso caso, não executarei os scripts, pois precisamos dessas variações para simular nossos problemas de replicação SQL.
Vantagens do utilitário TableDiff
- TableDiff é um utilitário gratuito que vem como parte da instalação dos componentes do SQL Server Replication para ser usado para comparação ou convergência de tabelas.
- Os scripts de criação de convergência podem ser criados sem intervenção manual.
Limitações do utilitário TableDiff
- O utilitário TableDiff pode ser executado apenas a partir do prompt de comando ou arquivo em lote.
- No prompt de comando, você pode realizar apenas uma comparação de tabela por vez, a menos que tenha vários prompts de comando abertos em paralelo para comparar várias tabelas.
- A tabela de origem que você precisa comparar usando o utilitário TableDiff requer uma chave primária ou uma coluna de identidade definida, ou a coluna ROWGUID disponível para realizar a comparação linha por linha. Se o -estrito for usada, a tabela de destino também exigirá uma chave primária ou uma coluna de identidade ou a coluna ROWGUID disponível.
- Se a tabela de origem ou destino contiver a sql_variant coluna de tipo de dados, você não pode usar o utilitário TableDiff para compará-lo.
- Problemas de desempenho podem ser observados durante a execução do utilitário TableDiff em tabelas contendo registros enormes, pois ele fará a comparação linha por linha nessas tabelas.
- Os scripts de convergência criados pelo utilitário TableDiff não incluem as colunas de tipo de dados de caractere BLOB, como varchar(max) , nvarchar(max) , varbinary(max) , texto , ntext , ou imagem colunas e xml ou carimbo de data e hora colunas. Portanto, você precisa de abordagens alternativas para lidar com as tabelas com essas colunas de tipo de dados.
No entanto, mesmo com essas limitações, o utilitário TableDiff pode ser usado em qualquer tabela do SQL Server para verificação rápida de dados ou verificação de convergência. No entanto, você também pode comprar uma boa ferramenta de terceiros.
Agora, vamos considerar os vários problemas de Replicação SQL em detalhes.
Problemas de configuração
Com base na minha experiência, categorizei as opções de configuração de replicação frequentemente perdidas que podem levar a problemas críticos de replicação de SQL como Configuração questões. Alguns deles estão abaixo.
Tamanho máximo de replicação de texto
Tamanho máximo da réplica de texto refere-se ao Tamanho máximo de replicação de texto em bytes . Aplica-se a todos os tipos de dados como char(max), nvarchar(max), varbinary(max), text, ntext, varbinary, xml, e imagem .
O SQL Server tem uma opção padrão para limitar o comprimento máximo da coluna do tipo de dados de string (em bytes) a ser replicado como 65536 bytes.
Precisamos avaliar o Tamanho Máximo de Repl de Texto com cuidado sempre que a Replicação for configurada para um banco de dados. Para isso, devemos verificar todas as colunas de tipo de dados acima e identificar o máximo possível de bytes que serão transferidos via Replicação.
Alterar o valor para -1 indica que não há limites. No entanto, recomendamos que você avalie o comprimento máximo da string e configure esse valor.
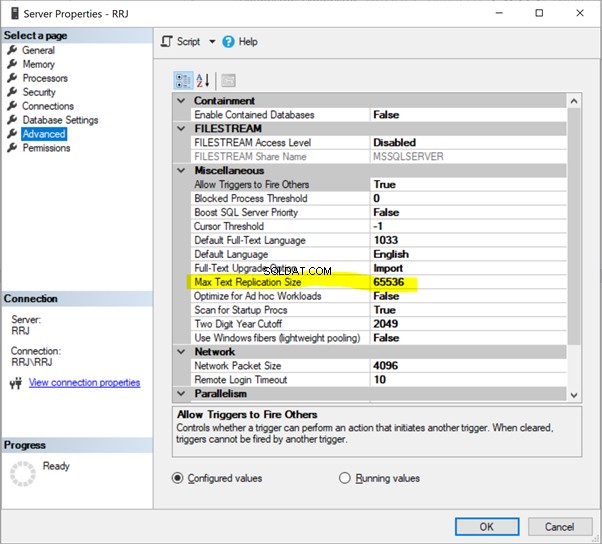
Podemos configurar o Max Text Repl Size usando SSMS ou T-SQL.
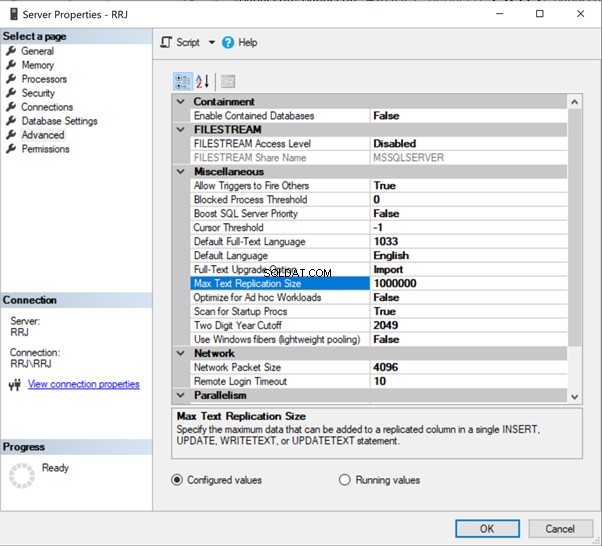
No SSMS, clique com o botão direito do mouse no nome do servidor> Propriedades > Avançado :
Basta clicar em 65536 para modificá-lo. Para testes, alterei 65536 para 1000000 e cliquei em OK :
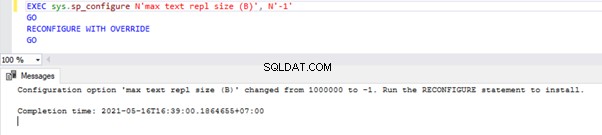
Para configurar a opção Max Text Repl Size via T-SQL, abra uma nova janela de consulta e execute o script abaixo no banco de dados mestre:
EXEC sys.sp_configure N'max text repl size (B)', N'-1'
GO
RECONFIGURE WITH OVERRIDE
GO
Essa consulta permitirá que a Replicação não restrinja o tamanho das colunas de tipo de dados acima.
Para verificar, podemos realizar um SELECT em sys.configurations DMV e verifique o value_in_use coluna como abaixo:

Serviço do SQL Server Agent não definido para iniciar o modo automático
A replicação depende de Replication Agents que são executados como trabalhos do SQL Server Agent. Portanto, qualquer problema com algum serviço do SQL Server Agent terá um impacto direto na funcionalidade de replicação.
Precisamos ter certeza de que o Modo de Início do SQL Server e os Serviços do SQL Server Agent estão definidos como Automático. Se definido como Manual, devemos configurar alguns alertas. Eles notificariam o DBA ou os administradores do servidor para iniciar o SQL Server Agent Service quando o servidor reiniciar os planejados ou não planejados.
Se não for feito, a Replicação pode não estar em execução por um longo tempo, o que também afeta outros trabalhos do SQL Server Agent.
As instâncias de replicação não monitoradas entram em um estado de assinaturas não inicializadas
Semelhante ao monitoramento do SQL Server Agent Service, configurar o Database Mail Service em qualquer instância do SQL Server desempenha um papel vital no alerta do DBA ou da pessoa configurada em tempo hábil. Para quaisquer falhas ou problemas de trabalho, os trabalhos do SQL Server Agent, como Log Reader Agent ou Distribution Agent, podem ser configurados para enviar alertas ao DBA ou ao respectivo membro da equipe por e-mail. A falha na execução do trabalho do Replication Agent pode levar aos cenários abaixo:
Não execução do trabalho do Log Reader Agent . O arquivo de log de transações do banco de dados do Publicador será reutilizado somente após o comando marcado para replicação é lido pelo Log Reader Agent e enviado com sucesso para o banco de dados de distribuição. Caso contrário, o log_reuse_wait_desc coluna de sys.databases mostrará o valor como Replicação, indicando que o log do banco de dados não pode ser reutilizado até que ele transfira com sucesso as alterações para o banco de dados de distribuição. Portanto, a não execução do agente Log Reader continuará aumentando o tamanho do arquivo de log transacional do banco de dados do Publicador e encontraremos problemas de desempenho durante o backup completo ou problemas de espaço em disco na instância do banco de dados do Publicador.
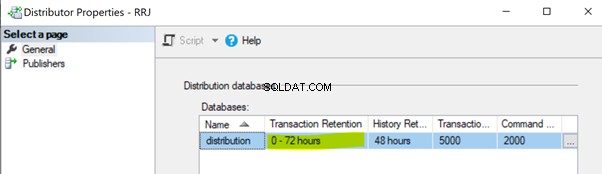
Não execução do trabalho de agente de distribuição. O trabalho do Agente de Distribuição lê os dados do banco de dados de distribuição e os envia para o banco de dados do Assinante. Em seguida, marca esses registros para exclusão no banco de dados de distribuição. Se o trabalho do Distribution Agent não estiver em execução, ele aumentará o tamanho do banco de dados de distribuição, causando problemas de desempenho no desempenho geral da Replicação. Por padrão, o banco de dados de distribuição é configurado para reter registros por um período máximo de 0 a 72 horas, conforme mostrado na propriedade Retenção de Transação abaixo. Se a Replicação estiver falhando por mais de 72 horas, a assinatura correspondente será marcada como não inicializada, forçando-nos a reconfigurar a Assinatura ou gerar um novo instantâneo para que a Replicação funcione novamente.
Não execução da limpeza de distribuição:trabalho de distribuição . O trabalho de limpeza de distribuição é responsável por excluir todos os registros replicados do banco de dados de distribuição para manter o tamanho do banco de dados de distribuição sob controle. A não execução deste trabalho leva ao aumento do tamanho do banco de dados de distribuição, resultando em problemas de desempenho de replicação.
Para garantir que não encontremos nenhum desses problemas não monitorados, o Database Mail deve ser configurado para relatar todas as falhas de trabalho ou novas tentativas aos respectivos membros da equipe para ação imediata.
Problemas conhecidos no SQL Server
Certas versões do SQL Server tinham problemas de replicação conhecidos na versão RTM ou em versões anteriores. Esses problemas foram corrigidos nos Service Packs ou pacotes CU subsequentes. Portanto, é recomendável aplicar os Service packs ou CU packs mais recentes assim que estiverem disponíveis para todos os SQL Server após testá-los no ambiente de controle de qualidade. Embora essa seja uma recomendação geral para servidores que executam o SQL Server, ela também se aplica à Replicação.
Problemas de permissão
Em um ambiente com a Replicação Transacional do SQL Server configurada, podemos observar os problemas de Permissões com frequência. Podemos enfrentá-los durante o tempo de configuração da Replicação ou quaisquer atividades de Manutenção no Publicador, Distribuidor ou instâncias de banco de dados do Assinante. Isso resulta em credenciais ou permissões perdidas. Vamos agora observar alguns problemas frequentes de permissão relacionados à Replicação.
Problemas de permissão de trabalho do SQL Server Agent
Todos os agentes de replicação usam trabalhos do SQL Server Agent. Cada trabalho do SQL Server Agent relacionado ao Snapshot ou Log Reader Agent ou Distribution é executado em algumas credenciais de login do Windows ou SQL, conforme mostrado abaixo:
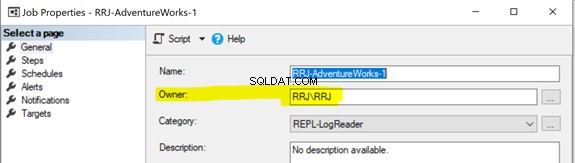
Para iniciar um trabalho do SQL Server Agent, você precisa possuir o SQLAgentOperatorRole para iniciar todos os trabalhos ou SQLAgentUserRole ou o SQLAgentReaderRole para iniciar trabalhos que você possui. Se algum trabalho não puder ser iniciado corretamente, verifique se o proprietário do trabalho tem os direitos necessários para executar esse trabalho.
A credencial de trabalho do agente de instantâneo não pode acessar o caminho da pasta de instantâneo
Em nossos artigos anteriores, notamos que a execução do agente Snapshot criaria o snapshot dos artigos no caminho da pasta local ou compartilhada para ser propagado para o banco de dados do Assinante por meio do Agente de distribuição. O local do caminho do instantâneo pode ser identificado em Propriedades da publicação > Instantâneo :
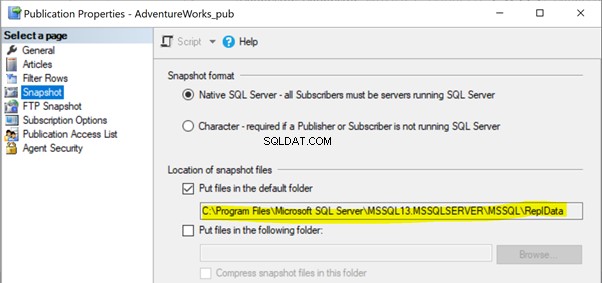
Se o agente do Snapshot não tiver acesso a este local de arquivos do Snapshot, podemos receber o erro:
O acesso ao caminho 'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\XXXX\YYYYMMDDHHMISS\' foi negado.
Para resolver o problema, é melhor conceder acesso completo ao caminho da pasta C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\repldata\unc\ para a conta sob a qual o Snapshot Agent é executado. Em nossa configuração, usamos a conta do SQL Server Agent e o SQL Server Agent Service está sendo executado na conta RRJ\RRJ.
A credencial de trabalho do Log Reader Agent não pode se conectar ao banco de dados do editor/distribuição
O Log Reader Agent se conecta ao banco de dados do Publisher para executar o sp_replcmds procedimento para verificar as transações marcadas para replicação nos logs transacionais do banco de dados do Publicador.
Se o proprietário do banco de dados do Publisher não estiver definido corretamente, podemos receber os seguintes erros:
O processo não pôde executar 'sp_replcmds' em 'RRJ.
Ou
Não é possível executar como o principal do banco de dados porque o principal “dbo” não existe, esse tipo de principal não pode ser representado ou você não tem permissão.
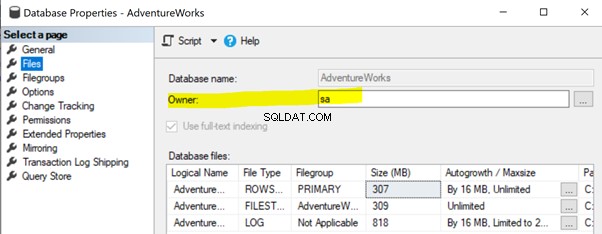
Para resolver esse problema, verifique se a propriedade do proprietário do banco de dados do banco de dados do Publicador está definida como sa ou outra conta válida (veja abaixo).
Clique com o botão direito do mouse no Editor banco de dados (AdventureWorks )> Propriedades > Arquivos . Certifique-se de que o Proprietário campo está definido como sa ou qualquer login válido e não em branco .
Se ocorrer algum problema de permissão quando estivermos nos conectando ao Publicador ou banco de dados de distribuição, verifique as credenciais usadas para o Log Reader Agent e conceda a eles permissões para acessar esses bancos de dados.
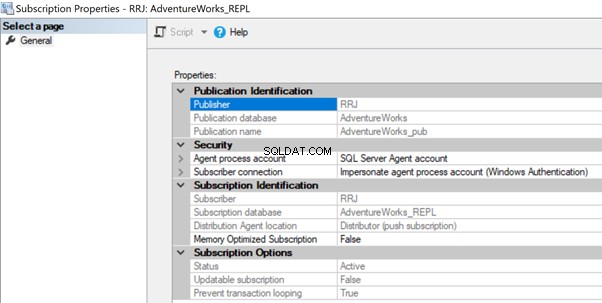
A credencial de trabalho do agente de distribuição não pode se conectar ao banco de dados de distribuição/assinante
O agente de distribuição pode ter problemas de permissão se a conta não tiver permissão para acessar o banco de dados de distribuição ou se conectar ao banco de dados do assinante. Nesse caso, podemos receber os seguintes erros:
Não é possível iniciar a execução da etapa 2 (motivo:erro ao autenticar proxy RRJ\RRJ, erro do sistema:o nome de usuário ou a senha estão incorretos.)
O processo não pôde se conectar ao Assinante 'RRJ.
Falha no login do usuário 'RRJ\RRJ'.
Para resolvê-lo, verifique a conta usada nas Propriedades da Assinatura e certifique-se de que ela tenha as permissões necessárias para se conectar ao banco de dados de Distribuição ou Assinante.
Problemas de conectividade
Normalmente, configuramos a Replicação Transacional em servidores dentro da mesma rede ou em locais distribuídos geograficamente. Se o banco de dados de distribuição estiver localizado em um servidor dedicado separado do Publicador ou do Assinante, ele se tornará suscetível a perdas de pacotes de rede – problemas de conectividade.
No caso de tais problemas, os agentes de replicação (leitor de log ou agente de distribuição) podem relatar os erros abaixo:
O servidor do editor não foi encontrado ou não estava acessível
O servidor de distribuição não foi encontrado ou não estava acessível
O servidor do assinante não foi encontrado ou não estava acessível
Para solucionar esses problemas, podemos tentar nos conectar ao Publicador, Distribuidor ou banco de dados do Assinante no SSMS para verificar se podemos nos conectar a essas instâncias do SQL Server sem problemas ou não.
Se os problemas de conectividade ocorrerem com frequência, podemos tentar fazer ping no servidor continuamente para identificar qualquer perda de pacote. Além disso, temos que trabalhar com os membros da equipe necessários para resolver esses problemas e colocar o servidor em funcionamento para que a Replicação retome a transferência de dados.
Problemas de integridade de dados
Como a Replicação Transacional é um mecanismo unidirecional, quaisquer alterações de dados que ocorram no Assinante (manualmente ou do aplicativo) não serão refletidas no Publicador. Isso pode levar a variações de dados entre o Publicador e o Assinante.
Vamos revisar esses problemas relacionados à integridade dos dados e ver como resolvê-los. Observe que inserimos um registro no Person.ContactType tabela e excluiu 2 registros do Person.ContactType tabela no banco de dados do Assinante. Vamos usar esses 3 registros para encontrar erros.
Erros de violação de chave primária ou chave exclusiva
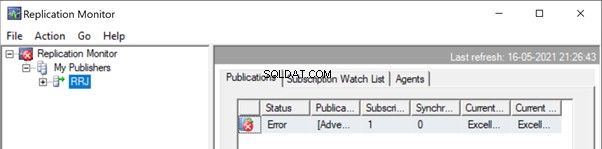
Vou testar o registro INSERT no Person.ContactType tabela. Vamos inserir esse registro no banco de dados do Publisher e ver o que acontece:
Inicie o Replication Monitor para ver como funciona. Obtemos o erro:
Expansão do Editor e Publicação , obtemos os seguintes detalhes:
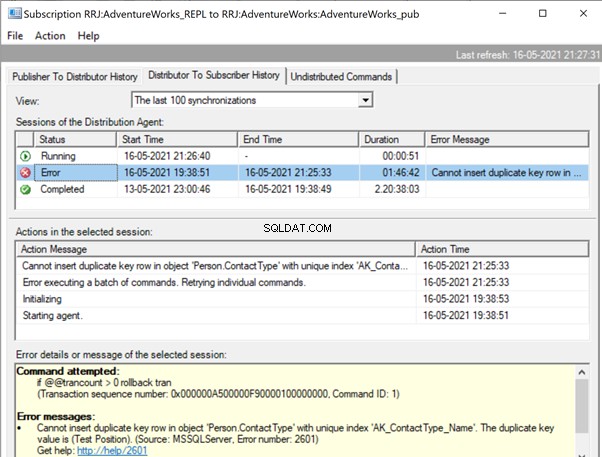
Se tivermos configurado os Alertas de replicação e atribuído as respectivas pessoas para receber seu alerta de e-mail, receberemos as notificações de e-mail apropriadas com a mensagem de erro:Não é possível inserir uma linha de chave duplicada no objeto 'Person.ContactType' com índice exclusivo 'AK_ContactType_Name ' . O valor da chave duplicada é (Posição de teste). (Fonte:MSSQLServer, número do erro:2601)
Para resolver o problema relacionado a violações de chave exclusiva ou problemas de chave primária, temos várias opções:
- Analise por que esse erro ocorreu, como o registro estava disponível no banco de dados do Assinante e quem o inseriu por quais motivos. Identifique se foi necessário ou não.
- Adicione os skiperrors parâmetro para o perfil do Agente de Distribuição para ignorar o Erro Número 2601 ou Erro número 2627 no caso de violação da chave primária.
No nosso caso, inserimos dados propositalmente para receber esse erro. Para lidar com esse problema, exclua esse registro inserido manualmente para continuar replicando as alterações recebidas do Publicador.
DELETE from Person.ContactType
where ContactTypeID = 21
Para estudar outras opções e comparar as diferenças entre essas duas abordagens, estou pulando a primeira opção (que é eficiente e recomendada) e prossigo para a segunda opção adicionando os -skiperrors parâmetro para o trabalho do Agente de Distribuição.
Podemos implementá-lo editando o Tarefa de agente de distribuição > Etapas > clique em 2 Etapa de Trabalho chamada Executar Agente > clique em Editar para visualizar o comando disponível:
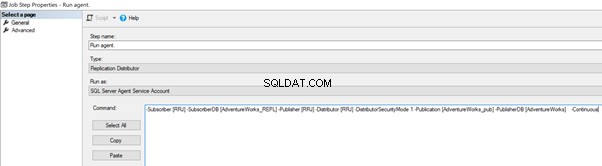
Agora, adicione o -SkipErrors 2601 palavra-chave no final (2601 é o número do erro – podemos pular qualquer número de erro recebido como parte da Replicação) e clique em OK .
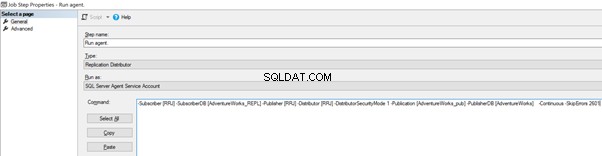
Para garantir que o trabalho de distribuição esteja ciente dessa alteração de configuração, precisamos reiniciar o trabalho do agente de distribuição. Para isso, pare e comece novamente a partir da Etapa 1, conforme mostrado abaixo:
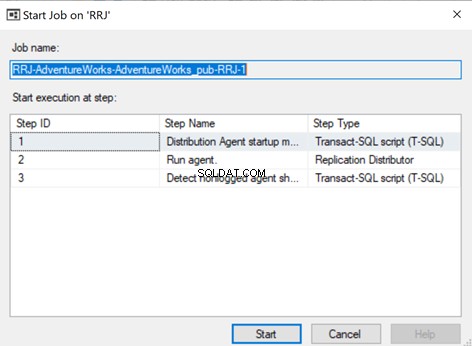
The Replication Monitor displays that one of the error records is skipped from the Replication, that started working fine.
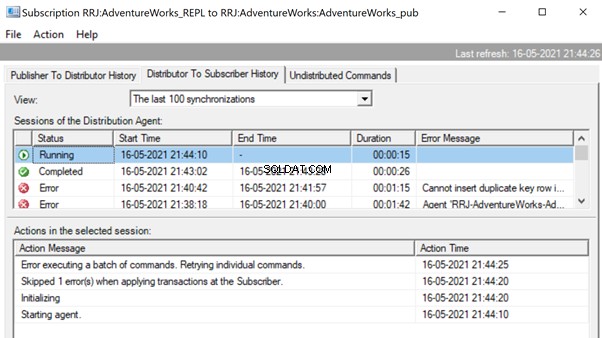
Since the Replication issue is resolved successfully, we’d recommend removing the -SkipErrors parameter from the Distribution Agent job. Then, restart the job to get the changes reflected.
Thus, we’ve fixed the replication issue, but let’s compare the data across the same Person.ContactType in the Publisher and Subscriber databases. The results show the data variance, or the data integrity issue :
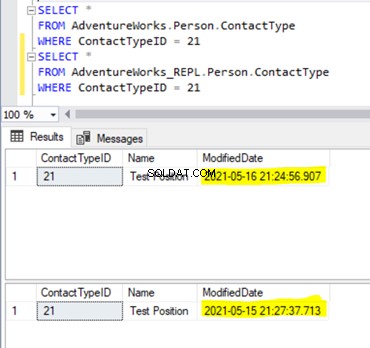
ModifiedDate is different across the Publisher and Subscriber databases. It happens because the data in the Subscriber database was inserted earlier (when we were preparing the test data), and the data in the Publisher database has just been inserted.
If we deleted the record from the Subscriber database, the record from the Publisher would have been inserted to match the data across the Publisher and the Subscriber databases.
Most of the newbie DBAs simply add the -SkipErrors option to get the replication working immediately without detailed investigations of the issue. Hence, it is recommended not to use the -SkipErrors option as a primary solution without proper examination of the problem. The Person.ContactType table had only 3 columns. Assume that the table has over 20 columns. Then, we have just screwed up the Data integrity of this table with that -SkipErrors command.
We used this approach just to illustrate the usage of that option. The best way is to examine and clarify the reason for variance and then perform the appropriate DELETE statements on the Subscriber database to maintain the Data Integrity across the Publisher and Subscriber databases.
Row Not Found Errors
Let’s try to perform an UPDATE on one of the records that were deleted from the Subscriber database:
Let’s check the Replication Monitor to see the performance. We have the following error:
The row was not found at the Subscriber when applying the replicated UPDATE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =19 (Source:MSSQLServer, Error number:20598).
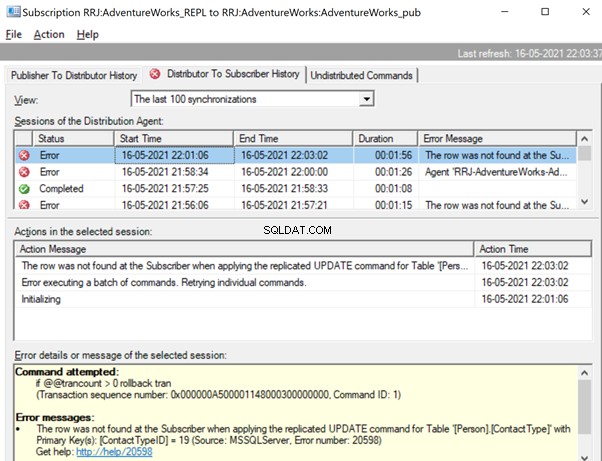
There are two ways to resolve this error. First, we can use -SkipErrors for Error Number 20598 . Or, we can INSERT the record with ContactTypeID =19 (shown in the error message) to get the data changes reflected.
If we skip this error, we’ll lose the record with ContactTypeId =19 from the Subscriber database permanently. It can cause data inconsistency issues. Hence, we aren’t going to use the -SkipErrors option. Instead, we’ll apply the INSERT approach.
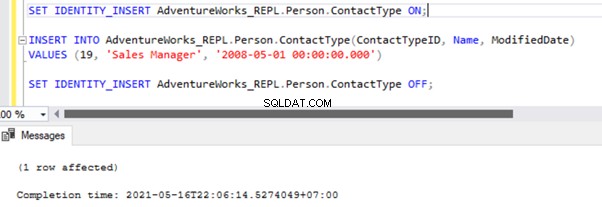
The Replication resumes correctly by sending the UPDATE to the Subscriber database.
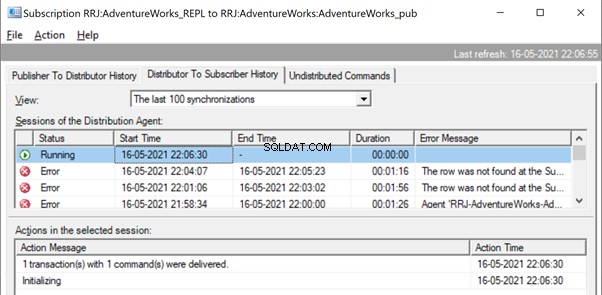
It is the same when we try to delete the ContactTypeId =20 from the Publisher database and see the error popping up in the Replication Monitor.
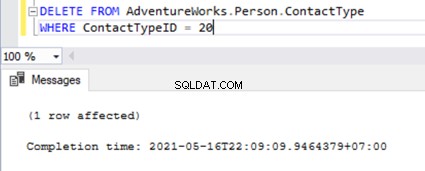
The Replication Monitor shows us a message similar to the one we already noticed:
The row was not found at the Subscriber when applying the replicated DELETE command for Table ‘[Person].[ContactType]’ with Primary Key(s):[ContactTypeID] =20 (Source:MSSQLServer, Error number:20598)
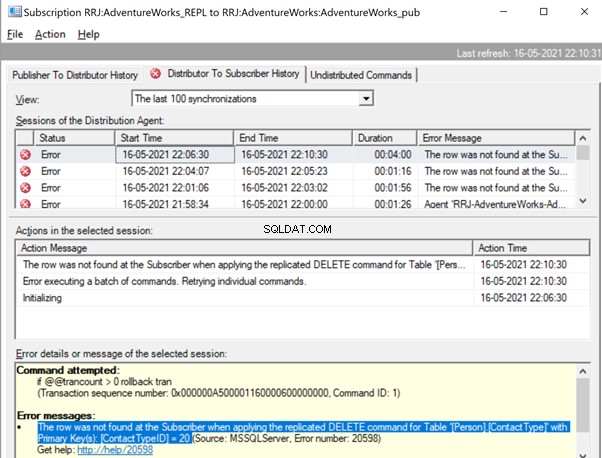
Similar to the previous error, we need to identify the missing record and insert it back to the Subscriber database for the DELETE statement to get replicated properly. For DELETE scenario, using -SkipErrors doesn’t have any issues but can’t be considered as a safe option, as both missing UPDATE or missing DELETE record are captured with the same error number 20598 and adding -SkipErrors 20598 will skip applying all records from the Subscriber database.
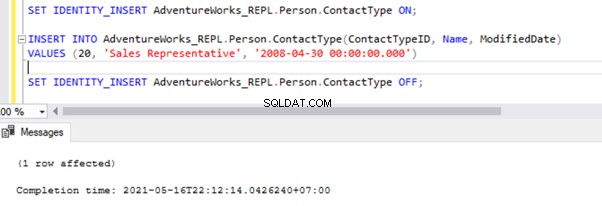
We can also get more details about the problematic command by using the sp_browsereplcmds stored procedure which we have discussed earlier as well. Let’s try to use sp_browsereplcmds stored procedure for the previous error we have received out as shown below.

exec sp_browsereplcmds @xact_seqno_start = '0x000000A500001160000600000000'
, @xact_seqno_end = '0x000000A500001160000600000000'
, @publisher_database_id = 1
, @command_id = 1
@xact_seqno_start and @xact_seqno_end will be the same value. We can fetch that value from the Transaction Sequence number in the Replication Monitor along with Command ID.
@publisher_database_id can be fetched from the id column of the distribution..MSPublisher_databases DMV.
select * from MSpublisher_databases Foreign Key or Other Constraint Violation Errors
The error messages related to Foreign keys or any other data issues are slightly different. Microsoft has made these error messages detailed and self-explanatory for anyone to understand what the issue is about.
To identify the exact command that was executed on the Publisher and resolve it efficiently, we can use the sp_browsereplcmds procedure explained above and identify the root cause of the issue.
Once the commands are identified as INSERT/UPDATE/DELETE which caused the errors, we can take corresponding actions to resolve the problems correctly which is more efficient compared to simply adding -SkipErrors approach. Once corrective measures are taken, Replication will start resuming fine immediately.
Word of Caution Using -SkipErrors Option
Those who are comfortable using -SkipErrors option to resolve error quickly should remember that -SkipErrors option is added at the Distribution agent level and applies to all Published articles in that Publication. Command -SkipErrors will result in skipping any number of commands related to that particular error across all published articles any number of times resulting in discrepancies we have seen in demo resulting in data discrepancies across Publisher and Subscriber without knowing how many tables are having discrepancies and would require efforts to compare the tables and fix it out.
Conclusion
Thanks for going through another robust article. I hope it was helpful for you to understand the SQL Server Transactional Replication issues and methods of troubleshooting them. In our next article, we’ll continue the discussion about the SQL Transaction Replication issues, examine other types, such as Corruption-related issues, and learn the best methods of handling them.