Este artigo é a quarta parte de uma série sobre expressões de tabela. Na Parte 1 e na Parte 2 abordei o tratamento conceitual de tabelas derivadas. Na Parte 3, comecei a abordar as considerações de otimização de tabelas derivadas. Este mês abordo mais aspectos de otimização de tabelas derivadas; especificamente, concentro-me na substituição/desaninhamento de tabelas derivadas.
Em meus exemplos, usarei bancos de dados de exemplo chamados TSQLV5 e PerformanceV5. Você pode encontrar o script que cria e preenche o TSQLV5 aqui e seu diagrama ER aqui. Você pode encontrar o script que cria e preenche o PerformanceV5 aqui.
Desaninhamento/substituição
Desaninhar/substituir expressões de tabela é um processo de fazer uma consulta que envolve o aninhamento de expressões de tabela e como se a substituísse por uma consulta onde a lógica aninhada é eliminada. Devo enfatizar que, na prática, não existe um processo real no qual o SQL Server converte a string de consulta original com a lógica aninhada em uma nova string de consulta sem o aninhamento. O que realmente acontece é que o processo de análise de consulta produz uma árvore inicial de operadores lógicos refletindo de perto a consulta original. Em seguida, o SQL Server aplica transformações a essa árvore de consulta, eliminando algumas das etapas desnecessárias, reduzindo várias etapas em menos etapas e movendo os operadores. Em suas transformações, contanto que certas condições sejam atendidas, o SQL Server pode mudar as coisas através do que eram originalmente os limites da expressão da tabela — às vezes efetivamente como se eliminasse as unidades aninhadas. Tudo isso na tentativa de encontrar um plano ideal.
Neste artigo, abordo os dois casos em que esse desaninhamento ocorre, bem como os inibidores de desaninhamento. Ou seja, quando você usa determinados elementos de consulta, ele impede que o SQL Server possa mover operadores lógicos na árvore de consulta, forçando-o a processar os operadores com base nos limites das expressões de tabela usadas na consulta original.
Começarei demonstrando um exemplo simples em que tabelas derivadas são desaninhadas. Também demonstrarei um exemplo de um inibidor de desaninhamento. Em seguida, falarei sobre casos incomuns em que o desaninhamento pode ser indesejável, resultando em erros ou degradação de desempenho, e demonstrarei como evitar o desaninhamento nesses casos empregando um inibidor de desaninhamento.
A consulta a seguir (chamaremos de Consulta 1) usa várias camadas aninhadas de tabelas derivadas, onde cada uma das expressões de tabela aplica lógica de filtragem básica com base em constantes:
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101') AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180301') AS D3WHERE orderdate>='20180401';
Como você pode ver, cada uma das expressões de tabela filtra um intervalo de datas de pedidos começando com uma data diferente. O SQL Server desaninha essa lógica de consulta de várias camadas, o que permite mesclar os quatro predicados de filtragem em um único que representa a interseção de todos os quatro predicados.
Examine o plano para a Consulta 1 mostrado na Figura 1.
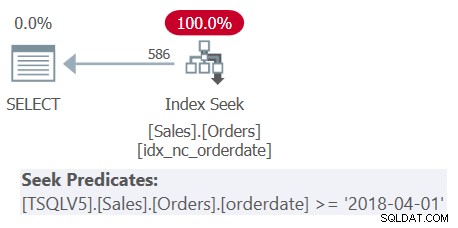 Figura 1:plano para a consulta 1
Figura 1:plano para a consulta 1 Observe que todos os quatro predicados de filtragem foram mesclados em um único predicado representando a interseção dos quatro. O plano aplica uma busca no índice idx_nc_orderdate com base no único predicado mesclado como o predicado de busca. Este índice é definido em orderdate (explicitamente), orderid (implicitamente devido à presença de um índice clusterizado em orderid) como as chaves de índice.
Observe também que, embora todas as expressões de tabela usem SELECT * e apenas a consulta mais externa projete as duas colunas de interesse:orderdate e orderid, o índice mencionado acima é considerado de cobertura. Conforme expliquei na Parte 3, para fins de otimização, como seleção de índice, o SQL Server ignora as colunas das expressões de tabela que, em última análise, não são relevantes. Lembre-se de que você precisa ter permissões para consultar essas colunas.
Conforme mencionado, o SQL Server tentará desaninhar expressões de tabela, mas evitará o desaninhamento se encontrar um inibidor de desaninhamento. Com uma certa exceção que descreverei mais adiante, o uso de TOP ou OFFSET FETCH inibirá o desaninhamento. O motivo é que tentar desaninhar uma expressão de tabela com TOP ou OFFSET FETCH pode resultar em uma alteração no significado da consulta original.
Como exemplo, considere a seguinte consulta (chamaremos de Consulta 2):
SELECT orderid, orderdateFROM (SELECT TOP (9223372036854775807) * FROM (SELECT TOP (9223372036854775807) * FROM (SELECT TOP (9223372036854775807) * FROM Sales.Orders WHERE orderdate>='20180108'201 AS D1 WHERE orderdate>='20180108'201 ' ) AS D2 WHERE orderdate>='20180301' ) AS D3WHERE orderdate>='20180401';
O número de linhas de entrada para o filtro TOP é um valor do tipo BIGINT. Neste exemplo, estou usando o valor BIGINT máximo (2^63 – 1, computar em T-SQL usando SELECT POWER(2., 63) – 1). Mesmo que você e eu saibamos que nossa tabela Orders nunca terá tantas linhas e, portanto, o filtro TOP não tem sentido, o SQL Server precisa levar em consideração a possibilidade teórica de o filtro ser significativo. Consequentemente, o SQL Server não desaninha as expressões de tabela nesta consulta. O plano para a Consulta 2 é mostrado na Figura 2.
 Figura 2:plano para a consulta 2
Figura 2:plano para a consulta 2 Os inibidores de desaninhamento impediram o SQL Server de mesclar os predicados de filtragem, fazendo com que a forma do plano se assemelhasse mais à consulta conceitual. No entanto, é interessante observar que o SQL Server ainda ignorou as colunas que, em última análise, não eram relevantes para a consulta externa e, portanto, foi capaz de usar o índice de cobertura em orderdate, orderid.
Para ilustrar por que TOP e OFFSET-FETCH são inibidores de desaninhamento, vamos usar uma técnica simples de otimização de empilhamento de predicados. Empilhamento de predicado significa que o otimizador envia um predicado de filtro para um ponto anterior em comparação ao ponto original em que ele aparece no processamento da consulta lógica. Por exemplo, suponha que você tenha uma consulta com uma junção interna e um filtro WHERE com base em uma coluna de um dos lados da junção. Em termos de processamento de consulta lógica, o filtro WHERE deve ser avaliado após a junção. Mas muitas vezes o otimizador irá empurrar o predicado de filtro para uma etapa anterior à junção, pois isso deixa a junção com menos linhas para trabalhar, normalmente resultando em um plano mais otimizado. Lembre-se, porém, que tais transformações são permitidas apenas nos casos em que o significado da consulta original é preservado, no sentido de que você terá a garantia de obter o conjunto de resultados correto.
Considere o código a seguir, que tem uma consulta externa com um filtro WHERE em uma tabela derivada, que por sua vez é baseada em uma expressão de tabela com um filtro TOP:
SELECT orderid, orderdateFROM ( SELECT TOP (3) * FROM Sales.Orders ) AS DWHERE orderdate>='20180101';
Essa consulta é, obviamente, não determinística devido à falta de uma cláusula ORDER BY na expressão da tabela. Quando o executei, o SQL Server acessou as três primeiras linhas com datas de pedidos anteriores a 2018, então obtive um conjunto vazio como saída:
orderid orderdate----------- ----------(0 linhas afetadas)
Como mencionado, o uso de TOP na expressão de tabela impediu o desaninhamento/substituição da expressão de tabela aqui. Se o SQL Server tivesse desaninhado a expressão de tabela, o processo de substituição teria resultado no equivalente à seguinte consulta:
SELECT TOP (3) orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20180101';
Essa consulta também não é determinística devido à falta da cláusula ORDER BY, mas claramente tem um significado diferente da consulta original. Se a tabela Sales.Orders tiver pelo menos três pedidos feitos em 2018 ou posterior — e tem — essa consulta necessariamente retornará três linhas, ao contrário da consulta original. Aqui está o resultado que obtive quando executei esta consulta:
orderid orderdate----------- ----------10400 2018-01-0110401 2018-01-0110402 2018-01-02(3 linhas afetadas)
Caso a natureza não determinística das duas consultas acima o confunda, aqui está um exemplo com uma consulta determinística:
SELECT orderid, orderdateFROM ( SELECT TOP (3) * FROM Sales.Orders ORDER BY orderid ) AS DWHERE orderdate>='20170708'ORDER BY orderid;
A expressão de tabela filtra os três pedidos com os IDs de pedido mais baixos. A consulta externa filtra desses três pedidos apenas aqueles que foram feitos em ou após 8 de julho de 2017. Acontece que há apenas um pedido qualificado. Essa consulta gera a seguinte saída:
orderid orderdate----------- ----------10250 2017-07-08(1 linha afetada)
Suponha que o SQL Server tenha desaninhado a expressão de tabela na consulta original, com o processo de substituição resultando no seguinte equivalente de consulta:
SELECT TOP (3) orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20170708'ORDER BY orderid;
O significado desta consulta é diferente da consulta original. Essa consulta filtra primeiro os pedidos que foram feitos em ou após 8 de julho de 2017 e, em seguida, filtra os três primeiros entre aqueles com os IDs de pedido mais baixos. Essa consulta gera a seguinte saída:
orderid orderdate----------- ----------10250 2017-07-0810251 2017-07-0810252 2017-07-09(3 linhas afetadas)
Para evitar alterar o significado da consulta original, o SQL Server não aplica desaninhamento/substituição aqui.
Os dois últimos exemplos envolveram uma mistura simples de filtragem WHERE e TOP, mas pode haver elementos conflitantes adicionais resultantes do desaninhamento. Por exemplo, e se você tiver especificações de ordenação diferentes na expressão de tabela e na consulta externa, como no exemplo a seguir:
SELECT orderid, orderdateFROM ( SELECT TOP (3) * FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC ) AS DORDER BY orderid;
Você percebe que, se o SQL Server desaninhasse a expressão de tabela, reunindo as duas especificações de ordenação diferentes em uma, a consulta resultante teria um significado diferente da consulta original. Ele teria filtrado as linhas erradas ou apresentado as linhas de resultados na ordem de apresentação errada. Em resumo, você percebe por que o mais seguro para o SQL Server fazer é evitar o desaninhamento/substituição de expressões de tabela baseadas em consultas TOP e OFFSET-FETCH.
Mencionei anteriormente que há uma exceção à regra de que o uso de TOP e OFFSET-FETCH impede o desaninhamento. É quando você usa TOP (100) PERCENT em uma expressão de tabela aninhada, com ou sem uma cláusula ORDER BY. O SQL Server percebe que não há filtragem real acontecendo e otimiza a opção. Veja um exemplo demonstrando isso:
SELECT orderid, orderdateFROM ( SELECT TOP (100) PERCENT * FROM ( SELECT TOP (100) PERCENT * FROM ( SELECT TOP (100) PERCENT * FROM Sales.Orders WHERE orderdate>='20180101') AS D1 WHERE orderdate> ='20180201' ) AS D2 WHERE orderdate>='20180301' ) AS D3WHERE orderdate>='20180401';
O filtro TOP é ignorado, o desaninhamento ocorre e você obtém o mesmo plano mostrado anteriormente para a Consulta 1 na Figura 1.
Ao usar OFFSET 0 ROWS sem cláusula FETCH em uma expressão de tabela aninhada, também não há filtragem real acontecendo. Portanto, teoricamente, o SQL Server poderia ter otimizado essa opção também e habilitado o desaninhamento, mas na data de redação deste artigo não. Veja um exemplo demonstrando isso:
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D1 WHERE orderdate>='20180201' ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D2 WHERE orderdate>='20180301' ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D3WHERE orderdate>='20180401';
Você obtém o mesmo plano mostrado anteriormente para a Consulta 2 na Figura 2, mostrando que nenhum desaninhamento ocorreu.
Anteriormente, expliquei que o processo de desaninhamento/substituição não gera realmente uma nova string de consulta que é otimizada, mas tem a ver com as transformações que o SQL Server aplica à árvore de operadores lógicos. Há uma diferença entre a maneira como o SQL Server otimiza uma consulta com expressões de tabela aninhada versus uma consulta logicamente equivalente real sem o aninhamento. O uso de expressões de tabela, como tabelas derivadas, bem como subconsultas, impede a parametrização simples. Lembre-se da consulta 1 mostrada anteriormente no artigo:
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101') AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180301') AS D3WHERE orderdate>='20180401';
Como a consulta usa tabelas derivadas, a parametrização simples não ocorre. Ou seja, o SQL Server não substitui as constantes por parâmetros e depois otimiza a consulta, mas sim otimiza a consulta com as constantes. Com predicados baseados em constantes, o SQL Server pode mesclar os períodos de interseção, o que em nosso caso resultou em um único predicado no plano, conforme mostrado anteriormente na Figura 1.
Em seguida, considere a seguinte consulta (vamos chamá-la de Consulta 3), que é um equivalente lógico da Consulta 1, mas onde você mesmo aplica o desaninhamento:
SELECT orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20180101' AND orderdate>='20180201' AND orderdate>='20180301' AND orderdate>='20180401';
O plano para esta consulta é mostrado na Figura 3.
 Figura 3:plano para a consulta 3
Figura 3:plano para a consulta 3 Este plano é considerado seguro para parametrização simples, então as constantes são substituídas por parâmetros e, consequentemente, os predicados não são mesclados. A motivação para a parametrização é, obviamente, aumentar a probabilidade de reutilização do plano ao executar consultas semelhantes que diferem apenas nas constantes usadas.
Conforme mencionado, o uso de tabelas derivadas na Consulta 1 impediu a parametrização simples. Da mesma forma, o uso de subconsultas impediria a parametrização simples. Por exemplo, aqui está nossa Consulta 3 anterior com um predicado sem sentido baseado em uma subconsulta adicionada à cláusula WHERE:
SELECT orderid, orderdateFROM Sales.OrdersWHERE orderdate>='20180101' AND orderdate>='20180201' AND orderdate>='20180301' AND orderdate>='20180401' AND (SELECT 42) =42;
Desta vez, a parametrização simples não ocorre, permitindo que o SQL Server mescle os períodos de interseção representados pelos predicados com as constantes, resultando no mesmo plano mostrado anteriormente na Figura 1.
Se você tem consultas com expressões de tabela que usam constantes, e é importante para você que o SQL Server tenha parametrizado o código, e por algum motivo você não pode parametrizá-lo sozinho, lembre-se que você tem a opção de usar a parametrização forçada com um guia de plano. Como exemplo, o código a seguir cria um guia de plano para a Consulta 3:
DECLARE @stmt AS NVARCHAR(MAX), @params AS NVARCHAR(MAX); EXEC sys.sp_get_query_template @querytext =N'SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>=''20180101'') AS D1 WHERE orderdate>=''20180201'') AS D2 WHERE orderdate>=''20180301'') AS D3WHERE orderdate>=''20180401'';', @templatetext =@stmt OUTPUT, @parameters =@params OUTPUT; EXEC sys.sp_create_plan_guide @name =N'TG1', @stmt =@stmt, @type =N'TEMPLATE', @module_or_batch =NULL, @params =@params, @hints =N'OPTION(PARAMETERIZATION FORCED)';
Execute a Consulta 3 novamente após criar o guia de plano:
SELECT orderid, orderdateFROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101') AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180301') AS D3WHERE orderdate>='20180401';
Você obtém o mesmo plano mostrado anteriormente na Figura 3 com os predicados parametrizados.
Quando terminar, execute o código a seguir para descartar o guia do plano:
EXEC sys.sp_control_plan_guide @operation =N'DROP', @name =N'TG1';Evitando o desaninhamento
Lembre-se de que o SQL Server desaninha expressões de tabela por motivos de otimização. O objetivo é aumentar a probabilidade de encontrar um plano com um custo menor em comparação com sem desaninhamento. Isso é verdade para a maioria das regras de transformação aplicadas pelo otimizador. No entanto, pode haver alguns casos incomuns em que você deseja evitar o desaninhamento. Isso pode ser para evitar erros (sim, em alguns casos incomuns, o desaninhamento pode resultar em erros) ou por motivos de desempenho para forçar uma determinada forma de plano, semelhante ao uso de outras dicas de desempenho. Lembre-se, você tem uma maneira simples de inibir o desaninhamento usando TOP com um número muito grande.
Exemplo para evitar erros
Vou começar com um caso em que o desaninhamento de expressões de tabela pode resultar em erros.
Considere a seguinte consulta (vamos chamá-la de Consulta 4):
SELECT orderid, productid, discountFROM Sales.OrderDetailsWHERE desconto> (SELECT MIN(desconto) FROM Sales.OrderDetails) AND 1,0 / desconto> 10,0;
Este exemplo é um pouco artificial no sentido de que é fácil reescrever o segundo predicado do filtro para que nunca resulte em um erro (desconto <0,1), mas é um exemplo conveniente para ilustrar meu ponto. Os descontos não são negativos. Portanto, mesmo que haja linhas de pedido com desconto zero, a consulta deve filtrá-las (o primeiro predicado do filtro diz que o desconto deve ser maior que o desconto mínimo na tabela). No entanto, não há garantia de que o SQL Server avaliará os predicados em ordem escrita, portanto, você não pode contar com um curto-circuito.
Examine o plano para a Consulta 4 mostrado na Figura 4.
Figura 4:planejar a consulta 4
Observe que no plano o predicado 1.0/desconto> 10.0 (segundo na cláusula WHERE) é avaliado antes do predicado desconto>(primeiro na cláusula WHERE). Consequentemente, esta consulta gera um erro de divisão por zero:
Msg 8134, Level 16, State 1Divide by zero error encontrado.
Talvez você esteja pensando que pode evitar o erro usando uma tabela derivada, separando as tarefas de filtragem em uma interna e outra externa, assim:
SELECT orderid, productid, discountFROM ( SELECT * FROM Sales.OrderDetails WHERE desconto> (SELECT MIN(desconto) FROM Sales.OrderDetails) ) AS DWHERE 1.0 / desconto> 10.0;
No entanto, o SQL Server aplica o desaninhamento da tabela derivada, resultando no mesmo plano mostrado anteriormente na Figura 4 e, consequentemente, esse código também falha com um erro de divisão por zero:
Msg 8134, Level 16, State 1Divide by zero error encontrado.
Uma correção simples aqui é introduzir um inibidor de desaninhamento, assim (chamaremos essa solução de Consulta 5):
SELECT orderid, productid, discountFROM ( SELECT TOP (9223372036854775807) * FROM Sales.OrderDetails WHERE desconto> (SELECT MIN(desconto) FROM Sales.OrderDetails) ) AS DWHERE 1.0 / desconto> 10.0;
O plano para a Consulta 5 é mostrado na Figura 5.
Figura 5:planejar a consulta 5
Não se confunda com o fato de a expressão 1.0/desconto aparecer na parte interna do operador Nested Loops, como se estivesse sendo avaliada primeiro. Esta é apenas a definição do membro Expr1006. A avaliação real do predicado Expr1006> 10.0 é aplicada pelo operador Filter como a última etapa no plano depois que as linhas com o desconto mínimo foram filtradas anteriormente pelo operador Nested Loops. Esta solução é executada com sucesso sem erros.
Exemplo por motivos de desempenho
Continuarei com um caso em que o desaninhamento de expressões de tabela pode prejudicar o desempenho.
Comece executando o seguinte código para alternar o contexto para o banco de dados PerformanceV5 e habilitar STATISTICS IO e TIME:
USE PerformanceV5; SET STATISTICS IO, TIME ON;
Considere a seguinte consulta (vamos chamá-la de Consulta 6):
SELECT shipperid, MAX(orderdate) AS maxodFROM dbo.OrdersGROUP BY shipperid;
O otimizador identifica um índice de cobertura de suporte com shipperid e orderdate como as chaves principais. Assim, ele cria um plano com uma varredura ordenada do índice seguida por um operador Stream Aggregate baseado em ordem, conforme mostrado no plano para a Consulta 6 na Figura 6.
Figura 6:planejar a consulta 6
A tabela Pedidos tem 1.000.000 de linhas e a coluna de agrupamento shipperid é muito densa — há apenas 5 IDs de remetente distintos, resultando em 20% de densidade (porcentagem média por valor distinto). A aplicação de uma varredura completa da folha de índice envolve a leitura de alguns milhares de páginas, resultando em um tempo de execução de cerca de um terço de segundo no meu sistema. Aqui estão as estatísticas de desempenho que obtive para a execução desta consulta:
Tempo de CPU =344 ms, tempo decorrido =346 ms, leituras lógicas =3854
A árvore de índice tem atualmente três níveis de profundidade.
Vamos dimensionar o número de pedidos por um fator de 1.000 a 1.000.000.000, mas ainda com apenas 5 remetentes distintos. O número de páginas na folha de índice cresceria por um fator de 1.000, e a árvore de índice provavelmente resultaria em um nível extra (quatro níveis de profundidade). Este plano tem escala linear. Você terminaria com cerca de 4.000.000 de leituras lógicas e um tempo de execução de alguns minutos.
Quando você precisa calcular um agregado MIN ou MAX em uma tabela grande, com densidade muito alta na coluna de agrupamento (importante!) plan shape do que o da Figura 6. Imagine uma forma de plano que varre o pequeno conjunto de IDs de remetente de algum índice na tabela Shippers e, em um loop, aplica a cada remetente uma busca no índice de suporte em Orders para obter a agregação. Com 1.000.000 de linhas na tabela, 5 buscas envolveriam 15 leituras. Com 1.000.000.000 de linhas, 5 buscas envolveriam 20 leituras. Com um trilhão de linhas, 25 leituras no total. Claramente, um plano muito mais ideal. Você pode realmente alcançar esse plano consultando a tabela Shippers e obtendo a agregação usando uma subconsulta de agregação escalar em Orders, assim (chamaremos essa solução de Consulta 7):
SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxodFROM dbo.Shippers AS S;
O plano para esta consulta é mostrado na Figura 7.
Figura 7:planejar a consulta 7
A forma de plano desejada é alcançada e os números de desempenho para a execução desta consulta são insignificantes conforme o esperado:
Tempo de CPU =0 ms, tempo decorrido =0 ms, leituras lógicas =15
Enquanto a coluna de agrupamento for muito densa, o tamanho da tabela Pedidos se tornará praticamente insignificante.
Mas espere um momento antes de ir comemorar. Há um requisito para manter apenas os remetentes cuja data máxima de pedido relacionado na tabela Pedidos é igual ou posterior a 2018. Parece uma adição bastante simples. Defina uma tabela derivada com base na Consulta 7 e aplique o filtro na consulta externa, assim (chamaremos essa solução de Consulta 8):
SELECT shipperid, maxodFROM ( SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) AS DWHERE maxod>='20180101';
Infelizmente, o SQL Server desaninha a consulta de tabela derivada, bem como a subconsulta, convertendo a lógica de agregação para o equivalente da lógica de consulta agrupada, com shipperid como a coluna de agrupamento. E a maneira como o SQL Server sabe otimizar uma consulta agrupada é baseada em uma única passagem pelos dados de entrada, resultando em um plano muito semelhante ao mostrado anteriormente na Figura 6, apenas com o filtro extra. O plano para a Consulta 8 é mostrado na Figura 8.
Figura 8:planejar a consulta 8
Consequentemente, o dimensionamento é linear e os números de desempenho são semelhantes aos da Consulta 6:
Tempo de CPU =328 ms, tempo decorrido =325 ms, leituras lógicas =3854
A correção é introduzir um inibidor de desaninhamento. Isso pode ser feito adicionando um filtro TOP à expressão de tabela na qual a tabela derivada é baseada, assim (chamaremos essa solução de Consulta 9):
SELECT shipperid, maxodFROM ( SELECT TOP (9223372036854775807) S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) AS DWHERE maxod>='20180101';
O plano para esta consulta é mostrado na Figura 9 e possui o formato de plano desejado com as buscas:
Figura 9:planejar a consulta 9
Os números de desempenho para esta execução são, obviamente, insignificantes:
Tempo de CPU =0 ms, tempo decorrido =0 ms, leituras lógicas =15
Outra opção é evitar o desaninhamento da subconsulta, substituindo o agregado MAX por um filtro TOP (1) equivalente, assim (chamaremos essa solução de Consulta 10):
SELECT shipperid, maxodFROM ( SELECT S.shipperid, (SELECT TOP (1) O.orderdate FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid ORDER BY O.orderdate DESC) AS maxod FROM dbo.Shippers AS S ) AS DWHERE maxod>='20180101';
O plano para esta consulta é mostrado na Figura 10 e novamente, tem a forma desejada com as buscas.
Figura 10:planejar a consulta 10
Eu tenho os números de desempenho insignificantes familiares para esta execução:
Tempo de CPU =0 ms, tempo decorrido =0 ms, leituras lógicas =15
Quando terminar, execute o seguinte código para parar de relatar estatísticas de desempenho:
SET STATISTICS IO, TIME OFF;Resumo
Neste artigo, continuei a discussão que comecei no mês passado sobre otimização de tabelas derivadas. Este mês concentrei-me no desaninhamento de tabelas derivadas. Expliquei que normalmente o desaninhamento resulta em um plano mais ideal em comparação com sem desaninhamento, mas também abordei exemplos em que isso é indesejável. Mostrei um exemplo em que o desaninhamento resultou em um erro, bem como um exemplo que resultou em degradação do desempenho. Demonstrei como evitar o desaninhamento aplicando um inibidor de desaninhamento como o TOP.
No próximo mês continuarei a exploração de expressões de tabelas nomeadas, mudando o foco para CTEs.