Este artigo é a quinta parte de uma série sobre expressões de tabela. Na Parte 1, forneci o pano de fundo para as expressões de tabela. Na Parte 2, Parte 3 e Parte 4, abordei os aspectos lógicos e de otimização das tabelas derivadas. Este mês começo a cobertura de expressões de tabela comuns (CTEs). Assim como nas tabelas derivadas, abordarei primeiro o tratamento lógico dos CTEs e, no futuro, abordarei as considerações de otimização.
Em meus exemplos, usarei um banco de dados de exemplo chamado TSQLV5. Você pode encontrar o script que o cria e o preenche aqui, e seu diagrama ER aqui.
CTEs
Vamos começar com o termo expressão de tabela comum . Nem este termo, nem seu acrônimo CTE, aparecem nas especificações do padrão ISO/IEC SQL. Portanto, pode ser que o termo tenha se originado em um dos produtos de banco de dados e posteriormente adotado por alguns dos outros fornecedores de banco de dados. Você pode encontrá-lo na documentação do Microsoft SQL Server e do Banco de Dados SQL do Azure. O T-SQL oferece suporte a partir do SQL Server 2005. O padrão usa o termo expressão de consulta para representar uma expressão que define um ou mais CTEs, incluindo a consulta externa. Ele usa o termo com elemento de lista para representar o que o T-SQL chama de CTE. Em breve, fornecerei a sintaxe para uma expressão de consulta.
A fonte do termo à parte, expressão de tabela comum , ou CTE , é o termo comumente usado pelos praticantes de T-SQL para a estrutura que é o foco deste artigo. Então, primeiro, vamos abordar se é um termo apropriado. Já concluímos que o termo expressão de tabela é apropriado para uma expressão que retorna conceitualmente uma tabela. Tabelas derivadas, CTEs, visualizações e funções com valor de tabela inline são todos os tipos de expressões de tabela nomeada que o T-SQL suporta. Portanto, a expressão de tabela parte da expressão de tabela comum certamente parece apropriado. Quanto ao comum parte do termo, provavelmente tem a ver com uma das vantagens de design das CTEs sobre as tabelas derivadas. Lembre-se de que você não pode reutilizar o nome da tabela derivada (ou mais precisamente o nome da variável de intervalo) mais de uma vez na consulta externa. Por outro lado, o nome CTE pode ser usado várias vezes na consulta externa. Em outras palavras, o nome CTE é comum para a consulta externa. Claro, vou demonstrar esse aspecto de design neste artigo.
Os CTEs oferecem benefícios semelhantes às tabelas derivadas, incluindo permitir o desenvolvimento de soluções modulares, reutilizar aliases de coluna, interagir indiretamente com funções de janela em cláusulas que normalmente não as permitem, suportar modificações que dependem indiretamente de TOP ou OFFSET FETCH com especificação de ordem, e outros. Mas há certas vantagens de design em comparação com as tabelas derivadas, que abordarei em detalhes depois de fornecer a sintaxe da estrutura.
Sintaxe
Aqui está a sintaxe do padrão para uma expressão de consulta:
7.17
Função
Especifique uma tabela.
Formato
[
[
AS
|
[
|
[
|
[
|
[
CORRESPONDING [ BY
FETCH { FIRST | NEXT } [
|
7.18
Função
Especifique a geração de informações de ordenação e detecção de ciclo no resultado de expressões de consulta recursiva.
Formato
SEARCH
PROFUNDIDADE PRIMEIRO POR
CYCLE
DEFAULT
7.3
Função
Especifique um conjunto de
Formato
VALUES
[ {
O termo padrão expressão de consulta representa uma expressão envolvendo uma cláusula WITH, uma com lista , que é composto por um ou mais com elementos de lista e uma consulta externa. T-SQL refere-se ao padrão com elemento de lista como CTE.
O T-SQL não oferece suporte a todos os elementos de sintaxe padrão. Por exemplo, ele não suporta alguns dos elementos de consulta recursiva mais avançados que permitem controlar a direção da pesquisa e lidar com ciclos em uma estrutura de gráfico. As consultas recursivas são o foco do artigo do próximo mês.
Aqui está a sintaxe T-SQL para uma consulta simplificada em um CTE:
WITH < table name > [ (< target columns >) ] AS ( < table expression > ) SELECT < select list > FROM < table name >;
Aqui está um exemplo para uma consulta simples em um CTE representando clientes dos EUA:
WITH UC AS ( SELECT custid, companyname FROM Sales.Customers WHERE country = N'USA' ) SELECT custid, companyname FROM UC;
Você encontrará as mesmas três partes em uma instrução em um CTE, como faria com uma instrução em uma tabela derivada:
- A expressão de tabela (a consulta interna)
- O nome atribuído à expressão de tabela (o nome da variável de intervalo)
- A consulta externa
O que é diferente no design dos CTEs em comparação com as tabelas derivadas é onde no código esses três elementos estão localizados. Com tabelas derivadas, a consulta interna é aninhada na cláusula FROM da consulta externa e o nome da expressão de tabela é atribuído após a própria expressão de tabela. Os elementos estão meio entrelaçados. Por outro lado, com CTEs, o código separa os três elementos:primeiro você atribui o nome da expressão da tabela; em segundo lugar, você especifica a expressão da tabela — do início ao fim, sem interrupções; terceiro, você especifica a consulta externa — do início ao fim, sem interrupções. Mais tarde, em “Considerações de design”, explicarei as implicações dessas diferenças de design.
Uma palavra sobre CTEs e o uso de um ponto e vírgula como um terminador de instrução. Infelizmente, ao contrário do SQL padrão, o T-SQL não força você a encerrar todas as instruções com um ponto e vírgula. No entanto, existem muito poucos casos em T-SQL em que sem um terminador o código é ambíguo. Nesses casos, a rescisão é obrigatória. Um desses casos diz respeito ao fato de que a cláusula WITH é usada para vários propósitos. Uma é definir um CTE, outra é definir uma dica de tabela para uma consulta e há alguns casos de uso adicionais. Como exemplo, na instrução a seguir, a cláusula WITH é usada para forçar o nível de isolamento serializável com uma dica de tabela:
SELECT custid, country FROM Sales.Customers WITH (SERIALIZABLE);
O potencial de ambiguidade é quando você tem uma instrução não terminada precedendo uma definição de CTE, caso em que o analisador pode não ser capaz de dizer se a cláusula WITH pertence à primeira ou à segunda instrução. Veja um exemplo demonstrando isso:
SELECT custid, country FROM Sales.Customers WITH UC AS ( SELECT custid, companyname FROM Sales.Customers WHERE country = N'USA' ) SELECT custid, companyname FROM UC
Aqui, o analisador não pode dizer se a cláusula WITH deve ser usada para definir uma dica de tabela para a tabela Customers na primeira instrução ou iniciar uma definição de CTE. Você recebe o seguinte erro:
Msg 336, Level 15, State 1, Line 159
Sintaxe incorreta perto de 'UC'. Se isso for uma expressão de tabela comum, você precisará encerrar explicitamente a instrução anterior com um ponto e vírgula.
A correção é, obviamente, encerrar a instrução que precede a definição de CTE, mas como prática recomendada, você realmente deve encerrar todas as suas instruções:
SELECT custid, country FROM Sales.Customers; WITH UC AS ( SELECT custid, companyname FROM Sales.Customers WHERE country = N'USA' ) SELECT custid, companyname FROM UC;
Você deve ter notado que algumas pessoas iniciam suas definições de CTE com um ponto e vírgula como prática, assim:
;WITH UC AS ( SELECT custid, companyname FROM Sales.Customers WHERE country = N'USA' ) SELECT custid, companyname FROM UC;
O ponto nesta prática é reduzir o potencial de erros futuros. E se em um momento posterior alguém adicionar uma instrução não terminada logo antes de sua definição de CTE no script e não se incomodar em verificar o script completo, apenas a instrução? Seu ponto e vírgula logo antes da cláusula WITH efetivamente se torna seu terminador de instrução. Você certamente pode ver a praticidade dessa prática, mas é um pouco antinatural. O que é recomendado, embora mais difícil de alcançar, é incutir boas práticas de programação na organização, incluindo o encerramento de todas as declarações.
Em termos das regras de sintaxe que se aplicam à expressão de tabela usada como consulta interna na definição de CTE, elas são as mesmas que se aplicam à expressão de tabela usada como consulta interna em uma definição de tabela derivada. Esses são:
- Todas as colunas da expressão de tabela devem ter nomes
- Todos os nomes de coluna da expressão de tabela devem ser exclusivos
- As linhas da expressão de tabela não têm ordem
Para obter detalhes, consulte a seção “Uma expressão de tabela é uma tabela” na Parte 2 da série.
Considerações de projeto
Se você pesquisar desenvolvedores experientes de T-SQL sobre se eles preferem usar tabelas derivadas ou CTEs, nem todos concordarão sobre o que é melhor. Naturalmente, pessoas diferentes têm preferências de estilo diferentes. Eu às vezes uso tabelas derivadas e às vezes CTEs. É bom ser capaz de identificar conscientemente as diferenças específicas de design de linguagem entre as duas ferramentas e escolher com base em suas prioridades em qualquer solução. Com o tempo e a experiência, você faz suas escolhas de forma mais intuitiva.
Além disso, é importante não confundir o uso de expressões de tabela e tabelas temporárias, mas essa é uma discussão relacionada ao desempenho que abordarei em um artigo futuro.
CTEs têm recursos de consulta recursiva e tabelas derivadas não. Então, se você precisa confiar neles, você naturalmente usaria CTEs. As consultas recursivas são o foco do artigo do próximo mês.
Na Parte 2, expliquei que vejo o aninhamento de tabelas derivadas adicionando complexidade ao código, pois dificulta seguir a lógica. Forneci o exemplo a seguir, identificando os anos do pedido em que mais de 70 clientes fizeram pedidos:
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70; CTEs não suportam aninhamento. Portanto, ao revisar ou solucionar problemas de uma solução com base em CTEs, você não se perde na lógica aninhada. Em vez de aninhar, você cria soluções mais modulares definindo vários CTEs na mesma instrução WITH, separados por vírgulas. Cada um dos CTEs é baseado em uma consulta que é escrita do início ao fim sem interrupções. Eu vejo isso como uma coisa boa de uma perspectiva de clareza de código e manutenção.
Aqui está uma solução para a tarefa mencionada usando CTEs:
WITH C1 AS ( SELECT YEAR(orderdate) AS orderyear, custid FROM Sales.Orders ), C2 AS ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts FROM C1 GROUP BY orderyear ) SELECT orderyear, numcusts FROM C2 WHERE numcusts > 70;
Eu gosto mais da solução baseada em CTE. Mas, novamente, pergunte aos desenvolvedores experientes qual das duas soluções acima eles preferem e nem todos concordarão. Alguns realmente preferem a lógica aninhada e poder ver tudo em um só lugar.
Uma vantagem muito clara das CTEs sobre as tabelas derivadas é quando você precisa interagir com várias instâncias da mesma expressão de tabela em sua solução. Lembre-se do exemplo a seguir baseado em tabelas derivadas da Parte 2 da série:
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM ( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS CUR
LEFT OUTER JOIN
( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS PRV
ON CUR.orderyear = PRV.orderyear + 1; Essa solução retorna anos de pedidos, contagens de pedidos por ano e a diferença entre as contagens do ano atual e do ano anterior. Sim, você poderia fazer isso mais facilmente com a função LAG, mas meu foco aqui não é encontrar a melhor maneira de realizar essa tarefa tão específica. Eu uso este exemplo para ilustrar certos aspectos de design de linguagem de expressões de tabela nomeada.
O problema com esta solução é que você não pode atribuir um nome a uma expressão de tabela e reutilizá-la na mesma etapa de processamento de consulta lógica. Você nomeia uma tabela derivada após a própria expressão de tabela na cláusula FROM. Se você definir e nomear uma tabela derivada como a primeira entrada de uma junção, também não poderá reutilizar esse nome de tabela derivada como a segunda entrada da mesma junção. Se você precisar unir duas instâncias da mesma expressão de tabela, com tabelas derivadas você não terá escolha a não ser duplicar o código. Foi o que você fez no exemplo acima. Por outro lado, o nome CTE é atribuído como o primeiro elemento do código entre os três acima mencionados (nome CTE, consulta interna, consulta externa). Em termos de processamento de consulta lógica, no momento em que você chega à consulta externa, o nome CTE já está definido e disponível. Isso significa que você pode interagir com várias instâncias do nome CTE na consulta externa, assim:
WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate)
)
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM OrdCount AS CUR
LEFT OUTER JOIN OrdCount AS PRV
ON CUR.orderyear = PRV.orderyear + 1; Essa solução tem uma clara vantagem de programação em relação à baseada em tabelas derivadas, pois você não precisa manter duas cópias da mesma expressão de tabela. Há mais a dizer sobre isso do ponto de vista do processamento físico e compará-lo com o uso de tabelas temporárias, mas farei isso em um artigo futuro com foco no desempenho.
Uma vantagem que o código baseado em tabelas derivadas tem em comparação com o código baseado em CTEs tem a ver com a propriedade closure que uma expressão de tabela deve possuir. Lembre-se de que a propriedade closure de uma expressão relacional diz que tanto as entradas quanto a saída são relações e que uma expressão relacional pode, portanto, ser usada onde uma relação é esperada, como entrada para outra expressão relacional. Da mesma forma, uma expressão de tabela retorna uma tabela e deve estar disponível como uma tabela de entrada para outra expressão de tabela. Isso vale para uma consulta baseada em tabelas derivadas — você pode usá-la onde uma tabela é esperada. Por exemplo, você pode usar uma consulta baseada em tabelas derivadas como a consulta interna de uma definição de CTE, como no exemplo a seguir:
WITH C AS
(
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C; No entanto, o mesmo não vale para uma consulta baseada em CTEs. Embora seja conceitualmente suposto ser considerada uma expressão de tabela, você não pode usá-la como a consulta interna em definições de tabela derivada, subconsultas e CTEs em si. Por exemplo, o código a seguir não é válido em T-SQL:
SELECT orderyear, custid
FROM (WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70) AS D; A boa notícia é que você pode usar uma consulta baseada em CTEs como a consulta interna em exibições e funções com valor de tabela inline, que abordarei em artigos futuros.
Além disso, lembre-se, você sempre pode definir outro CTE com base na última consulta e, em seguida, fazer com que a consulta externa interaja com esse CTE:
WITH C1 AS ( SELECT YEAR(orderdate) AS orderyear, custid FROM Sales.Orders ), C2 AS ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts FROM C1 GROUP BY orderyear ), C3 AS ( SELECT orderyear, numcusts FROM C2 WHERE numcusts > 70 ) SELECT orderyear, numcusts FROM C3;
Do ponto de vista da solução de problemas, como mencionado, geralmente acho mais fácil seguir a lógica do código baseado em CTEs, em comparação com o código baseado em tabelas derivadas. No entanto, as soluções baseadas em tabelas derivadas têm a vantagem de destacar qualquer nível de aninhamento e executá-lo independentemente, conforme mostrado na Figura 1.
 Figura 1:pode destacar e executar parte do código com tabelas derivadas
Figura 1:pode destacar e executar parte do código com tabelas derivadas Com CTEs as coisas são mais complicadas. Para que o código envolvendo CTEs seja executável, ele deve começar com uma cláusula WITH, seguida por uma ou mais expressões de tabela entre parênteses nomeadas separadas por vírgulas, seguidas por uma consulta sem parênteses sem vírgula precedente. Você pode destacar e executar qualquer uma das consultas internas que são realmente autocontidas, bem como o código completo da solução; no entanto, você não pode destacar e executar com êxito qualquer outra parte intermediária da solução. Por exemplo, a Figura 2 mostra uma tentativa malsucedida de executar o código que representa C2.
 Figura 2:não é possível destacar e executar parte do código com CTEs
Figura 2:não é possível destacar e executar parte do código com CTEs Assim, com os CTEs, você precisa recorrer a meios um pouco estranhos para poder solucionar uma etapa intermediária da solução. Por exemplo, uma solução comum é injetar temporariamente uma consulta SELECT * FROM your_cte logo abaixo do CTE relevante. Em seguida, você destaca e executa o código incluindo a consulta injetada e, quando terminar, exclui a consulta injetada. A Figura 3 demonstra esta técnica.
 Figura 3:Injetar SELECT * abaixo do CTE relevante
Figura 3:Injetar SELECT * abaixo do CTE relevante O problema é que sempre que você faz alterações no código - mesmo pequenas temporárias como as acima - há uma chance de que, ao tentar reverter para o código original, você acabe introduzindo um novo bug.
Outra opção é estilizar seu código de maneira um pouco diferente, de modo que cada definição de CTE não inicial comece com uma linha de código separada que se parece com isso:
, cte_name AS (
Então, sempre que você quiser executar uma parte intermediária do código em um determinado CTE, poderá fazê-lo com alterações mínimas em seu código. Usando um comentário de linha, você comenta apenas aquela linha de código que corresponde a esse CTE. Em seguida, você destaca e executa o código e inclui a consulta interna desse CTE, que agora é considerada a consulta mais externa, conforme ilustrado na Figura 4.
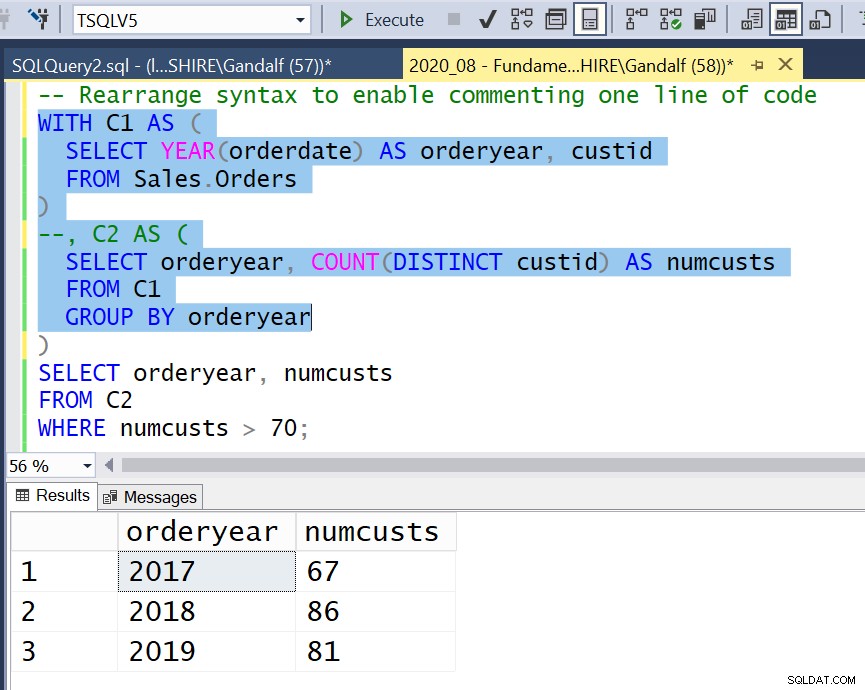 Figura 4:Reorganizar a sintaxe para permitir comentar uma linha de código
Figura 4:Reorganizar a sintaxe para permitir comentar uma linha de código Se você não está feliz com esse estilo, você tem mais uma opção. Você pode usar um comentário em bloco que começa logo antes da vírgula que precede o CTE de interesse e termina após o parêntese aberto, conforme ilustrado na Figura 5.
 Figura 5:Usar comentário de bloco
Figura 5:Usar comentário de bloco Tudo se resume a preferências pessoais. Normalmente, uso a técnica de consulta SELECT * temporariamente injetada.
Construtor de valor de tabela
Há uma certa limitação no suporte do T-SQL para construtores de valor de tabela em comparação com o padrão. Se você não estiver familiarizado com a construção, verifique primeiro a Parte 2 da série, onde a descrevo em detalhes. Enquanto o T-SQL permite definir uma tabela derivada com base em um construtor de valor de tabela, ele não permite definir um CTE com base em um construtor de valor de tabela.
Aqui está um exemplo compatível que usa uma tabela derivada:
SELECT custid, companyname, contractdate
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate); Infelizmente, código semelhante que usa um CTE não é suportado:
WITH MyCusts(custid, companyname, contractdate) AS
(
VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' )
)
SELECT custid, companyname, contractdate
FROM MyCusts; Este código gera o seguinte erro:
Msg 156, Level 15, State 1, Line 337
Sintaxe incorreta perto da palavra-chave 'VALUES'.
Existem algumas soluções alternativas, no entanto. Uma é usar uma consulta em uma tabela derivada, que por sua vez é baseada em um construtor de valor de tabela, como a consulta interna do CTE, assim:
WITH MyCusts AS
(
SELECT *
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate)
)
SELECT custid, companyname, contractdate
FROM MyCusts; Outra é recorrer à técnica que as pessoas usavam antes que os construtores com valor de tabela fossem introduzidos no T-SQL - usando uma série de consultas FROMless separadas por operadores UNION ALL, assim:
WITH MyCusts(custid, companyname, contractdate) AS
(
SELECT 2, 'Cust 2', '20200212'
UNION ALL SELECT 3, 'Cust 3', '20200118'
UNION ALL SELECT 5, 'Cust 5', '20200401'
)
SELECT custid, companyname, contractdate
FROM MyCusts; Observe que os aliases de coluna são atribuídos logo após o nome CTE.
Os dois métodos são algebrizados e otimizados da mesma forma, então use o que você se sentir mais confortável.
Produzindo uma sequência de números
Uma ferramenta que utilizo com bastante frequência em minhas soluções é uma tabela auxiliar de números. Uma opção é criar uma tabela de números reais em seu banco de dados e preenchê-la com uma sequência de tamanho razoável. Outra é desenvolver uma solução que produza uma sequência de números em tempo real. Para a última opção, você quer que as entradas sejam os delimitadores do intervalo desejado (vamos chamá-los de
@low e @high ). Você deseja que sua solução suporte intervalos potencialmente grandes. Aqui está minha solução para esse fim, usando CTEs, com uma solicitação para o intervalo de 1001 a 1010 neste exemplo específico:DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Este código gera a seguinte saída:
n ----- 1001 1002 1003 1004 1005 1006 1007 1008 1009 1010
O primeiro CTE chamado L0 é baseado em um construtor de valor de tabela com duas linhas. Os valores reais ali são insignificantes; o importante é que tem duas linhas. Em seguida, há uma sequência de cinco CTEs adicionais denominadas L1 a L5, cada uma aplicando uma junção cruzada entre duas instâncias do CTE anterior. O código a seguir calcula o número de linhas potencialmente geradas por cada um dos CTEs, em que @L é o número do nível de CTE:
DECLARE @L AS INT = 5; SELECT POWER(2., POWER(2., @L));
Aqui estão os números que você obtém para cada CTE:
| CTE | Cardinalidade |
|---|---|
| L0 | 2 |
| L1 | 4 |
| L2 | 16 |
| L3 | 256 |
| L4 | 65.536 |
| L5 | 4.294.967.296 |
Subir para o nível 5 oferece mais de quatro bilhões de linhas. Isso deve ser suficiente para qualquer caso de uso prático que eu possa imaginar. A próxima etapa ocorre no CTE chamado Nums. Você usa uma função ROW_NUMBER para gerar uma sequência de inteiros começando com 1 com base em nenhuma ordem definida (ORDER BY (SELECT NULL)) e nomeie a coluna de resultado como rownum. Por fim, a consulta externa usa um filtro TOP com base na ordem rownum para filtrar tantos números quanto a cardinalidade de sequência desejada (@high – @low + 1) e calcula o número do resultado n como @low + rownum – 1.
Aqui você pode realmente apreciar a beleza do design CTE e a economia que ele permite quando você cria soluções de forma modular. Por fim, o processo de desaninhamento descompacta 32 tabelas, cada uma consistindo em duas linhas com base em constantes. Isso pode ser visto claramente no plano de execução deste código, conforme mostrado na Figura 6 usando o SentryOne Plan Explorer.
 Figura 6:Plano para gerar a sequência de números de consulta
Figura 6:Plano para gerar a sequência de números de consulta Cada operador Constant Scan representa uma tabela de constantes com duas linhas. O problema é que o operador Top é quem solicita essas linhas e entra em curto-circuito depois de obter o número desejado. Observe as 10 linhas indicadas acima da seta fluindo para o operador Top.
Eu sei que o foco deste artigo é o tratamento conceitual de CTEs e não considerações físicas/de desempenho, mas olhando para o plano você pode realmente apreciar a brevidade do código em comparação com a profusão do que ele traduz nos bastidores.
Usando tabelas derivadas, você pode realmente escrever uma solução que substitui cada referência CTE pela consulta subjacente que ela representa. O que você recebe é bastante assustador:
DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D9
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D10 ) AS Nums
ORDER BY rownum; Obviously, you don’t want to write a solution like this, but it’s a good way to illustrate what SQL Server does behind the scenes with your CTE code.
If you were really planning to write a solution based on derived tables, instead of using the above nested approach, you’d be better off simplifying the logic to a single query with 31 cross joins between 32 table value constructors, each based on two rows, like so:
DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN (VALUES(1),(1)) AS D02(c)
CROSS JOIN (VALUES(1),(1)) AS D03(c)
CROSS JOIN (VALUES(1),(1)) AS D04(c)
CROSS JOIN (VALUES(1),(1)) AS D05(c)
CROSS JOIN (VALUES(1),(1)) AS D06(c)
CROSS JOIN (VALUES(1),(1)) AS D07(c)
CROSS JOIN (VALUES(1),(1)) AS D08(c)
CROSS JOIN (VALUES(1),(1)) AS D09(c)
CROSS JOIN (VALUES(1),(1)) AS D10(c)
CROSS JOIN (VALUES(1),(1)) AS D11(c)
CROSS JOIN (VALUES(1),(1)) AS D12(c)
CROSS JOIN (VALUES(1),(1)) AS D13(c)
CROSS JOIN (VALUES(1),(1)) AS D14(c)
CROSS JOIN (VALUES(1),(1)) AS D15(c)
CROSS JOIN (VALUES(1),(1)) AS D16(c)
CROSS JOIN (VALUES(1),(1)) AS D17(c)
CROSS JOIN (VALUES(1),(1)) AS D18(c)
CROSS JOIN (VALUES(1),(1)) AS D19(c)
CROSS JOIN (VALUES(1),(1)) AS D20(c)
CROSS JOIN (VALUES(1),(1)) AS D21(c)
CROSS JOIN (VALUES(1),(1)) AS D22(c)
CROSS JOIN (VALUES(1),(1)) AS D23(c)
CROSS JOIN (VALUES(1),(1)) AS D24(c)
CROSS JOIN (VALUES(1),(1)) AS D25(c)
CROSS JOIN (VALUES(1),(1)) AS D26(c)
CROSS JOIN (VALUES(1),(1)) AS D27(c)
CROSS JOIN (VALUES(1),(1)) AS D28(c)
CROSS JOIN (VALUES(1),(1)) AS D29(c)
CROSS JOIN (VALUES(1),(1)) AS D30(c)
CROSS JOIN (VALUES(1),(1)) AS D31(c)
CROSS JOIN (VALUES(1),(1)) AS D32(c) ) AS Nums
ORDER BY rownum; Still, the solution based on CTEs is obviously significantly simpler. The plans are identical.
Used in modification statements
CTEs can be used as the source and target tables in INSERT, UPDATE, DELETE and MERGE statements. They cannot be used in the TRUNCATE statement.
The syntax is pretty straightforward. You start the statement as usual with a WITH clause, followed by one or more CTEs separated by commas. Then you specify the outer modification statement, which interacts with the CTEs that were defined under the WITH clause as the source tables, target table, or both. Just like I explained in Part 2 about derived tables, also with CTEs what really gets modified is the underlying base table that the table expression uses. I’ll show a couple of examples using DELETE and UPDATE statements, but remember that you can use CTEs in MERGE and INSERT statements as well.
Here’s the general syntax of a DELETE statement against a CTE:
WITH < table name > [ (< target columns >) ] AS ( < table expression > ) DELETE [ FROM ] <table name> [ WHERE <filter predicate> ];
As an example (don’t actually run it), the following code deletes the 10 oldest orders:
WITH OldestOrders AS ( SELECT TOP (10) * FROM Sales.Orders ORDER BY orderdate, orderid ) DELETE FROM OldestOrders;
Here’s the general syntax of an UPDATE statement against a CTE:
WITH < table name > [ (< target columns >) ] AS ( < table expression > ) UPDATE <table name> SET <assignments> [ WHERE <filter predicate> ];
As an example, the following code updates the 10 oldest unshipped orders that have an overdue required date, increasing the required date to 10 days from today:
BEGIN TRAN;
WITH OldestUnshippedOrders AS
(
SELECT TOP (10) orderid, requireddate,
DATEADD(day, 10, CAST(SYSDATETIME() AS DATE)) AS newrequireddate
FROM Sales.Orders
WHERE shippeddate IS NULL
AND requireddate < CAST(SYSDATETIME() AS DATE)
ORDER BY orderdate, orderid
)
UPDATE OldestUnshippedOrders
SET requireddate = newrequireddate
OUTPUT
inserted.orderid,
deleted.requireddate AS oldrequireddate,
inserted.requireddate AS newrequireddate;
ROLLBACK TRAN; The code applies the update in a transaction that it then rolls back so that the change won’t stick.
This code generates the following output, showing both the old and the new required dates:
orderid oldrequireddate newrequireddate ----------- --------------- --------------- 11008 2019-05-06 2020-07-16 11019 2019-05-11 2020-07-16 11039 2019-05-19 2020-07-16 11040 2019-05-20 2020-07-16 11045 2019-05-21 2020-07-16 11051 2019-05-25 2020-07-16 11054 2019-05-26 2020-07-16 11058 2019-05-27 2020-07-16 11059 2019-06-10 2020-07-16 11061 2019-06-11 2020-07-16 (10 rows affected)
Of course you will get a different new required date based on when you run this code.
Summary
I like CTEs. They have a few advantages compared to derived tables. Instead of nesting the code, you define multiple CTEs separated by commas, typically leading to a more modular solution that is easier to review and maintain. Also, you can have multiple references to the same CTE name in the outer statement, so you don’t need to repeat the inner table expression’s code. However, unlike derived tables, CTEs cannot be defined directly based on a table value constructor, and you cannot highlight and execute some of the intermediate parts of the code. The following table summarizes the differences between derived tables and CTEs:
| Item | Derived table | CTE |
|---|---|---|
| Supports nesting | Yes | No |
| Supports multiple references | No | Yes |
| Supports table value constructor | Yes | No |
| Can highlight and run part of code | Yes | No |
| Supports recursion | No | Yes |
As the last item says, derived tables do not support recursive capabilities, whereas CTEs do. Recursive queries are the focus of next month’s article.