Na Parte 2 desta série, você adicionou a capacidade de salvar as alterações feitas por meio da API REST em um banco de dados usando SQLAlchemy e aprendeu a serializar esses dados para a API REST usando Marshmallow. Conectar a API REST a um banco de dados para que o aplicativo possa fazer alterações nos dados existentes e criar novos dados é ótimo e torna o aplicativo muito mais útil e robusto.
No entanto, isso é apenas parte do poder que um banco de dados oferece. Um recurso ainda mais poderoso é o R parte do RDBMS sistemas:relacionamentos . Em um banco de dados, um relacionamento é a capacidade de conectar duas ou mais tabelas de maneira significativa. Neste artigo, você aprenderá a implementar relacionamentos e transformar sua
Person banco de dados em um aplicativo web de miniblogging. Neste artigo, você aprenderá:
- Por que mais de uma tabela em um banco de dados é útil e importante
- Como as tabelas estão relacionadas umas às outras
- Como o SQLAlchemy pode ajudar você a gerenciar relacionamentos
- Como os relacionamentos ajudam você a criar um aplicativo de miniblog
Para quem é este artigo
A Parte 1 desta série guiou você na construção de uma API REST, e a Parte 2 mostrou como conectar essa API REST a um banco de dados.
Este artigo expande ainda mais seu cinto de ferramentas de programação. Você aprenderá como criar estruturas de dados hierárquicas representadas como relacionamentos um-para-muitos pelo SQLAlchemy. Além disso, você estenderá a API REST que já criou para fornecer suporte CRUD (Criar, Ler, Atualizar e Excluir) para os elementos dessa estrutura hierárquica.
O aplicativo Web apresentado na Parte 2 terá seus arquivos HTML e JavaScript modificados das principais maneiras para criar um aplicativo de miniblog mais totalmente funcional. Você pode revisar a versão final do código da Parte 2 no repositório GitHub desse artigo.
Espere enquanto você começa a criar relacionamentos e seu aplicativo de miniblog!
Dependências Adicionais
Não há novas dependências do Python além do necessário para o artigo da Parte 2. No entanto, você usará dois novos módulos JavaScript no aplicativo da Web para tornar as coisas mais fáceis e consistentes. Os dois módulos são os seguintes:
- Handlebars.js é um mecanismo de modelagem para JavaScript, muito parecido com Jinja2 para Flask.
- Moment.js é um módulo de análise e formatação de data e hora que facilita a exibição de carimbos de data e hora UTC.
Você não precisa baixar nenhum deles, pois o aplicativo da web os obterá diretamente da CDN (Content Delivery Network) da Cloudflare, como você já está fazendo para o módulo jQuery.
Dados de pessoas estendidos para blogs
Na Parte 2, as
People data existia como um dicionário no build_database.py Código Python. Isso é o que você usou para preencher o banco de dados com alguns dados iniciais. Você vai modificar o People estrutura de dados para dar a cada pessoa uma lista de notas associadas a eles. As novas People estrutura de dados ficará assim:# Data to initialize database with
PEOPLE = [
{
"fname": "Doug",
"lname": "Farrell",
"notes": [
("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
("This could be useful", "2019-01-08 22:17:54"),
("Well, sort of useful", "2019-03-06 22:17:54"),
],
},
{
"fname": "Kent",
"lname": "Brockman",
"notes": [
(
"I'm going to make really profound observations",
"2019-01-07 22:17:54",
),
(
"Maybe they'll be more obvious than I thought",
"2019-02-06 22:17:54",
),
],
},
{
"fname": "Bunny",
"lname": "Easter",
"notes": [
("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
("I'm really late delivering these!", "2019-04-06 22:17:54"),
],
},
]
Cada pessoa no
People dicionário agora inclui uma chave chamada notes , que está associado a uma lista contendo tuplas de dados. Cada tupla nas notes list representa uma única nota contendo o conteúdo e um carimbo de data/hora. Os carimbos de data/hora são inicializados (em vez de criados dinamicamente) para demonstrar a ordenação posteriormente na API REST. Cada pessoa está associada a várias notas e cada nota está associada a apenas uma pessoa. Essa hierarquia de dados é conhecida como relacionamento um-para-muitos, em que um único objeto pai está relacionado a muitos objetos filho. Você verá como esse relacionamento um para muitos é gerenciado no banco de dados com SQLAlchemy.
Abordagem da Força Bruta
O banco de dados que você construiu armazenou os dados em uma tabela, e uma tabela é uma matriz bidimensional de linhas e colunas. As
People podem dicionário acima seja representado em uma única tabela de linhas e colunas? Pode ser, da seguinte forma, em sua person tabela de banco de dados. Infelizmente, incluir todos os dados reais no exemplo cria uma barra de rolagem para a tabela, como você verá abaixo:person_id | lname | fname | timestamp | content | note_timestamp |
|---|---|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01 | Legal, um aplicativo de miniblog! | 2019-01-06 22:17:54 |
| 2 | Farrell | Doug | 2018-08-08 21:16:01 | Isso pode ser útil | 2019-01-08 22:17:54 |
| 3 | Farrell | Doug | 2018-08-08 21:16:01 | Bem, meio útil | 2019-03-06 22:17:54 |
| 4 | Brockman | Kent | 2018-08-08 21:16:01 | Vou fazer observações muito profundas | 2019-01-07 22:17:54 |
| 5 | Brockman | Kent | 2018-08-08 21:16:01 | Talvez eles sejam mais óbvios do que eu pensava | 2019-02-06 22:17:54 |
| 6 | Páscoa | Coelho | 2018-08-08 21:16:01 | Alguém viu meus ovos de páscoa? | 2019-01-07 22:47:54 |
| 7 | Páscoa | Coelho | 2018-08-08 21:16:01 | Estou muito atrasado para entregar isso! | 2019-04-06 22:17:54 |
A tabela acima realmente funcionaria. Todos os dados são representados e uma única pessoa é associada a uma coleção de notas diferentes.
Vantagens
Conceitualmente, a estrutura da tabela acima tem a vantagem de ser relativamente simples de entender. Você pode até argumentar que os dados podem ser persistidos em um arquivo simples em vez de um banco de dados.
Devido à estrutura da tabela bidimensional, você pode armazenar e usar esses dados em uma planilha. As planilhas foram usadas bastante como armazenamento de dados.
Desvantagens
Embora a estrutura da tabela acima funcione, ela tem algumas desvantagens reais.
Para representar a coleção de notas, todos os dados de cada pessoa são repetidos para cada nota única, portanto, os dados pessoais são redundantes. Isso não é um grande problema para seus dados pessoais, pois não há muitas colunas. Mas imagine se uma pessoa tivesse muito mais colunas. Mesmo com unidades de disco grandes, isso pode se tornar uma preocupação de armazenamento se você estiver lidando com milhões de linhas de dados.
Ter dados redundantes como esse pode levar a problemas de manutenção com o passar do tempo. Por exemplo, e se o coelhinho da Páscoa decidisse que uma mudança de nome era uma boa ideia. Para isso, todos os registros contendo o nome do coelhinho da Páscoa teriam que ser atualizados para manter os dados consistentes. Esse tipo de trabalho no banco de dados pode levar à inconsistência de dados, principalmente se o trabalho for feito por uma pessoa executando uma consulta SQL manualmente.
Nomear colunas torna-se estranho. Na tabela acima, há um
timestamp coluna usada para rastrear a hora de criação e atualização de uma pessoa na tabela. Você também deseja ter uma funcionalidade semelhante para a hora de criação e atualização de uma nota, mas porque timestamp já é usado, um nome artificial de note_timestamp é usado. E se você quiser adicionar relacionamentos um-para-muitos adicionais à
person tabela? Por exemplo, para incluir os filhos ou números de telefone de uma pessoa. Cada pessoa pode ter vários filhos e vários números de telefone. Isso pode ser feito de forma relativamente fácil para o Python People dicionário acima adicionando children e phone_numbers keys com novas listas contendo os dados. No entanto, representando esses novos relacionamentos um-para-muitos em sua
person tabela de banco de dados acima torna-se significativamente mais difícil. Cada novo relacionamento um-para-muitos aumenta drasticamente o número de linhas necessárias para representá-lo para cada entrada nos dados filho. Além disso, os problemas associados à redundância de dados ficam maiores e mais difíceis de lidar. Por fim, os dados que você receberia da estrutura da tabela acima não seriam muito Pythonicos:seriam apenas uma grande lista de listas. SQLAlchemy não seria capaz de ajudá-lo muito porque o relacionamento não existe.
Abordagem de banco de dados relacional
Com base no que você viu acima, fica claro que tentar representar mesmo um conjunto de dados moderadamente complexo em uma única tabela se torna incontrolável rapidamente. Diante disso, que alternativa oferece um banco de dados? É aqui que o R parte do RDBMS bancos de dados entra em jogo. Representar relacionamentos remove as desvantagens descritas acima.
Em vez de tentar representar dados hierárquicos em uma única tabela, os dados são divididos em várias tabelas, com um mecanismo para relacioná-los entre si. As tabelas são divididas ao longo das linhas de coleção, portanto, para suas
People dicionário acima, isso significa que haverá uma tabela representando pessoas e outra representando notas. Isso traz de volta sua person original tabela, que se parece com isso:person_id | lname | fname | timestamp |
|---|---|---|---|
| 1 | Farrell | Doug | 2018-08-08 21:16:01.888444 |
| 2 | Brockman | Kent | 2018-08-08 21:16:01.889060 |
| 3 | Páscoa | Coelho | 2018-08-08 21:16:01.886834 |
Para representar as novas informações da nota, você criará uma nova tabela chamada
note . (Lembre-se de nossa convenção de nomenclatura de tabela singular.) A tabela se parece com isso:note_id | person_id | content | timestamp |
|---|---|---|---|
| 1 | 1 | Legal, um aplicativo de miniblog! | 2019-01-06 22:17:54 |
| 2 | 1 | Isso pode ser útil | 2019-01-08 22:17:54 |
| 3 | 1 | Bem, meio útil | 2019-03-06 22:17:54 |
| 4 | 2 | Vou fazer observações muito profundas | 2019-01-07 22:17:54 |
| 5 | 2 | Talvez eles sejam mais óbvios do que eu pensava | 2019-02-06 22:17:54 |
| 6 | 3 | Alguém viu meus ovos de páscoa? | 2019-01-07 22:47:54 |
| 7 | 3 | Estou muito atrasado para entregar isso! | 2019-04-06 22:17:54 |
Observe que, como a
person tabela, a note tabela tem um identificador exclusivo chamado note_id , que é a chave primária para a note tabela. Uma coisa que não é óbvia é a inclusão do person_id valor na tabela. Para que serve isso? Isso é o que cria o relacionamento com a person tabela. Considerando que note_id é a chave primária da tabela, person_id é o que é conhecido como chave estrangeira. A chave estrangeira fornece cada entrada na
note tabela a chave primária da person registro a que está associado. Usando isso, o SQLAlchemy pode reunir todas as notas associadas a cada pessoa conectando o person.person_id chave primária para o note.person_id chave estrangeira, criando um relacionamento. Vantagens
Ao dividir o conjunto de dados em duas tabelas e introduzir o conceito de chave estrangeira, você tornou os dados um pouco mais complexos de se pensar, resolveu as desvantagens de uma única representação de tabela. SQLAlchemy irá ajudá-lo a codificar a complexidade aumentada com bastante facilidade.
Os dados não são mais redundantes no banco de dados. Há apenas uma entrada de pessoa para cada pessoa que você deseja armazenar no banco de dados. Isso resolve o problema de armazenamento imediatamente e simplifica drasticamente os problemas de manutenção.
Se o coelhinho da Páscoa ainda quisesse alterar os nomes, você só precisaria alterar uma única linha na
person tabela e qualquer outra coisa relacionada a essa linha (como a note tabela) imediatamente aproveitaria a mudança. A nomeação de colunas é mais consistente e significativa. Como os dados de pessoa e nota existem em tabelas separadas, o carimbo de data/hora de criação e atualização pode ser nomeado de forma consistente em ambas as tabelas, pois não há conflito de nomes nas tabelas.
Além disso, você não precisaria mais criar permutações de cada linha para novos relacionamentos um-para-muitos que deseja representar. Leve nossos
children e phone_numbers exemplo de antes. Implementar isso exigiria child e phone_number mesas. Cada tabela conteria uma chave estrangeira de person_id relacionando-o de volta à person tabela. Usando SQLAlchemy, os dados que você obteria das tabelas acima seriam mais imediatamente úteis, pois o que você obteria é um objeto para cada linha de pessoa. Esse objeto tem atributos nomeados equivalentes às colunas da tabela. Um desses atributos é uma lista Python contendo os objetos de nota relacionados.
Desvantagens
Onde a abordagem de força bruta era mais simples de entender, o conceito de chaves estrangeiras e relacionamentos torna o pensamento sobre os dados um pouco mais abstrato. Essa abstração precisa ser pensada para cada relacionamento que você estabelece entre tabelas.
Fazer uso de relacionamentos significa comprometer-se a usar um sistema de banco de dados. Esta é outra ferramenta para instalar, aprender e manter acima e além do aplicativo que realmente usa os dados.
Modelos SQLAlchemy
Para usar as duas tabelas acima e o relacionamento entre elas, você precisará criar modelos SQLAlchemy que estejam cientes de ambas as tabelas e do relacionamento entre elas. Aqui está o SQLAlchemy
Person modelo da Parte 2, atualizado para incluir um relacionamento com uma coleção de notes : 1class Person(db.Model):
2 __tablename__ = 'person'
3 person_id = db.Column(db.Integer, primary_key=True)
4 lname = db.Column(db.String(32))
5 fname = db.Column(db.String(32))
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
9 notes = db.relationship(
10 'Note',
11 backref='person',
12 cascade='all, delete, delete-orphan',
13 single_parent=True,
14 order_by='desc(Note.timestamp)'
15 )
As linhas 1 a 8 da classe Python acima se parecem exatamente com o que você criou antes na Parte 2. As linhas 9 a 16 criam um novo atributo no
Person classe chamada notes . Este novo note atributos é definido nas seguintes linhas de código:-
Linha 9: Assim como os outros atributos da classe, esta linha cria um novo atributo chamadonotese o define igual a uma instância de um objeto chamadodb.relationship. Este objeto cria o relacionamento que você está adicionando aoPersonclass e é criado com todos os parâmetros definidos nas linhas a seguir.
-
Linha 10: O parâmetro de string'Note'define a classe SQLAlchemy que oPersonaula será relacionada. ANoteclass ainda não está definida, e é por isso que é uma string aqui. Esta é uma referência direta e ajuda a lidar com problemas que a ordem das definições pode causar quando algo é necessário e não é definido até mais tarde no código. A'Note'string permite que aPersonclass para encontrar aNoteclass em tempo de execução, que está depois dePersoneNoteforam definidos.
-
Linha 11: Obackref='person'parâmetro é mais complicado. Ele cria o que é conhecido como referência inversa emNoteobjetos. Cada instância de umaNoteobjeto conterá um atributo chamadoperson. Apersonatributo referencia o objeto pai que umaNoteespecífica instância está associada. Ter uma referência ao objeto pai (personneste caso) no filho pode ser muito útil se seu código iterar sobre notas e tiver que incluir informações sobre o pai. Isso acontece com frequência surpreendente no código de renderização de exibição.
-
Linha 12: Ocascade='all, delete, delete-orphan'O parâmetro determina como tratar as instâncias do objeto de nota quando as alterações são feitas no paiPersoninstância. Por exemplo, quando umaPersonobjeto for excluído, SQLAlchemy criará o SQL necessário para excluir oPersondo banco de dados. Além disso, este parâmetro diz para ele também excluir todas asNoteinstâncias associadas a ele. Você pode ler mais sobre essas opções na documentação do SQLAlchemy.
-
Linha 13: Osingle_parent=Trueparâmetro é necessário sedelete-orphanfaz parte dacascadeanterior parâmetro. Isso diz ao SQLAlchemy para não permitirNoteórfão instâncias (umaNotesem paiPersonobject) existir porque cadaNotetem um único pai.
-
Linha 14: Oorder_by='desc(Note.timestamp)'O parâmetro informa ao SQLAlchemy como classificar aNoteinstâncias associadas a umaPerson. Quando umaPersonobjeto é recuperado, por padrão asnoteslista de atributos conteráNoteobjetos em uma ordem desconhecida. O SQLAlchemydesc(...)A função classificará as notas em ordem decrescente da mais recente para a mais antiga. Se esta linha fosseorder_by='Note.timestamp', SQLAlchemy usaria o padrãoasc(...)função e ordena as notas em ordem crescente, da mais antiga para a mais recente.
Agora que sua
Person modelo tem as novas notes atributo, e isso representa o relacionamento um-para-muitos com Note objetos, você precisará definir um modelo SQLAlchemy para uma Note : 1class Note(db.Model):
2 __tablename__ = 'note'
3 note_id = db.Column(db.Integer, primary_key=True)
4 person_id = db.Column(db.Integer, db.ForeignKey('person.person_id'))
5 content = db.Column(db.String, nullable=False)
6 timestamp = db.Column(
7 db.DateTime, default=datetime.utcnow, onupdate=datetime.utcnow
8 )
A
Note class define os atributos que compõem uma nota como visto em nosso exemplo note tabela de banco de dados acima. Os atributos são definidos aqui:-
Linha 1 cria aNoteclasse, herdando dedb.Model, exatamente como você fez antes ao criar aPersonaula.
-
Linha 2 diz à classe qual tabela de banco de dados usar para armazenarNoteobjetos.
-
Linha 3 cria onote_idatributo, definindo-o como um valor inteiro e como a chave primária para aNoteobjeto.
-
Linha 4 cria operson_idatributo e o define como a chave estrangeira, relacionando aNoteclasse para aPersonclasse usando operson.person_idchave primária. Isso e oPerson.notesatributo, são como SQLAlchemy sabe o que fazer ao interagir comPersoneNoteobjetos.
-
Linha 5 cria ocontentatributo, que contém o texto real da nota. Onullable=Falseparâmetro indica que não há problema em criar novas notas sem conteúdo.
-
Linha 6 cria otimestampatributo e exatamente como oPersonclasse, contém a hora de criação ou atualização para qualquerNoteespecífica instância.
Inicializar o banco de dados
Agora que você atualizou o
Person e criou a Note models, você os usará para reconstruir o banco de dados de teste people.db . Você fará isso atualizando o build_database.py código da Parte 2. Veja como será o código: 1import os
2from datetime import datetime
3from config import db
4from models import Person, Note
5
6# Data to initialize database with
7PEOPLE = [
8 {
9 "fname": "Doug",
10 "lname": "Farrell",
11 "notes": [
12 ("Cool, a mini-blogging application!", "2019-01-06 22:17:54"),
13 ("This could be useful", "2019-01-08 22:17:54"),
14 ("Well, sort of useful", "2019-03-06 22:17:54"),
15 ],
16 },
17 {
18 "fname": "Kent",
19 "lname": "Brockman",
20 "notes": [
21 (
22 "I'm going to make really profound observations",
23 "2019-01-07 22:17:54",
24 ),
25 (
26 "Maybe they'll be more obvious than I thought",
27 "2019-02-06 22:17:54",
28 ),
29 ],
30 },
31 {
32 "fname": "Bunny",
33 "lname": "Easter",
34 "notes": [
35 ("Has anyone seen my Easter eggs?", "2019-01-07 22:47:54"),
36 ("I'm really late delivering these!", "2019-04-06 22:17:54"),
37 ],
38 },
39]
40
41# Delete database file if it exists currently
42if os.path.exists("people.db"):
43 os.remove("people.db")
44
45# Create the database
46db.create_all()
47
48# Iterate over the PEOPLE structure and populate the database
49for person in PEOPLE:
50 p = Person(lname=person.get("lname"), fname=person.get("fname"))
51
52 # Add the notes for the person
53 for note in person.get("notes"):
54 content, timestamp = note
55 p.notes.append(
56 Note(
57 content=content,
58 timestamp=datetime.strptime(timestamp, "%Y-%m-%d %H:%M:%S"),
59 )
60 )
61 db.session.add(p)
62
63db.session.commit()
O código acima veio da Parte 2, com algumas alterações para criar o relacionamento um-para-muitos entre
Person e Note . Aqui estão as linhas atualizadas ou novas adicionadas ao código:-
Linha 4 foi atualizado para importar aNoteclasse definida anteriormente.
-
Linhas 7 a 39 contém oPEOPLEatualizado dicionário contendo nossos dados pessoais, juntamente com a lista de notas associadas a cada pessoa. Esses dados serão inseridos no banco de dados.
-
Linhas 49 a 61 iterar sobrePEOPLEdicionário, obtendo cadapersonpor sua vez e usando-o para criar umaPersonobjeto.
-
Linha 53 itera sobre operson.noteslista, obtendo cadanotepor sua vez.
-
Linha 54 descompacta ocontentetimestampde cadanotetupla.
-
Linha 55 a 60 cria umaNoteobjeto e anexa-o à coleção de notas da pessoa usandop.notes.append().
-
Linha 61 adiciona aPersonobjetoppara a sessão de banco de dados.
-
Linha 63 confirma toda a atividade na sessão para o banco de dados. É nesse ponto que todos os dados são gravados napersonenotetabelas nopeople.dbarquivo de banco de dados.
Você pode ver isso trabalhando com as
notes coleção na Person instância do objeto p é como trabalhar com qualquer outra lista em Python. SQLAlchemy cuida das informações de relacionamento um-para-muitos subjacentes quando o db.session.commit() chamada é feita. Por exemplo, assim como uma
Person instância tem seu campo de chave primária person_id inicializado pelo SQLAlchemy quando é confirmado no banco de dados, instâncias de Note terão seus campos de chave primária inicializados. Além disso, a Note chave estrangeira person_id também será inicializado com o valor da chave primária de Person instância a que está associado. Aqui está uma instância de exemplo de uma
Person objeto antes do db.session.commit() em uma espécie de pseudocódigo:Person (
person_id = None
lname = 'Farrell'
fname = 'Doug'
timestamp = None
notes = [
Note (
note_id = None
person_id = None
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = None
person_id = None
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
Aqui está o exemplo
Person objeto após o db.session.commit() :Person (
person_id = 1
lname = 'Farrell'
fname = 'Doug'
timestamp = '2019-02-02 21:27:10.336'
notes = [
Note (
note_id = 1
person_id = 1
content = 'Cool, a mini-blogging application!'
timestamp = '2019-01-06 22:17:54'
),
Note (
note_id = 2
person_id = 1
content = 'This could be useful'
timestamp = '2019-01-08 22:17:54'
),
Note (
note_id = 3
person_id = 1
content = 'Well, sort of useful'
timestamp = '2019-03-06 22:17:54'
)
]
)
A diferença importante entre os dois é que a chave primária da
Person e Note objetos foi inicializado. O mecanismo de banco de dados cuidou disso à medida que os objetos foram criados devido ao recurso de incremento automático de chaves primárias discutido na Parte 2. Além disso, o
person_id chave estrangeira em todas as Note instâncias foi inicializada para referenciar seu pai. Isso acontece devido à ordem em que a Person e Note objetos são criados no banco de dados. SQLAlchemy está ciente da relação entre
Person e Note objetos. Quando uma Person objeto está comprometido com a person tabela de banco de dados, SQLAlchemy obtém o person_id valor da chave primária. Esse valor é usado para inicializar o valor da chave estrangeira de person_id em uma Note objeto antes de ser confirmado no banco de dados. O SQLAlchemy cuida desse trabalho de manutenção do banco de dados por causa das informações que você passou quando o
Person.notes atributo foi inicializado com o db.relationship(...) objeto. Além disso, o
Person.timestamp atributo foi inicializado com o timestamp atual. Executando o
build_database.py programa a partir da linha de comando (no ambiente virtual irá recriar o banco de dados com as novas adições, deixando-o pronto para uso com a aplicação web. Esta linha de comando irá reconstruir o banco de dados:$ python build_database.py
O
build_database.py programa utilitário não gera nenhuma mensagem se for executado com sucesso. Se lançar uma exceção, um erro será impresso na tela. Atualizar API REST
Você atualizou os modelos SQLAlchemy e os usou para atualizar o
people.db base de dados. Agora é hora de atualizar a API REST para fornecer acesso às novas informações de notas. Aqui está a API REST que você criou na Parte 2:| Ação | Verbo HTTP | Caminho do URL | Descrição |
|---|---|---|---|
| Criar | POST | /api/people | URL para criar uma nova pessoa |
| Ler | GET | /api/people | URL para ler uma coleção de pessoas |
| Ler | GET | /api/people/{person_id} | URL para ler uma única pessoa por person_id |
| Atualizar | PUT | /api/people/{person_id} | URL para atualizar uma pessoa existente por person_id |
| Excluir | DELETE | /api/people/{person_id} | URL para excluir uma pessoa existente por person_id |
A API REST acima fornece caminhos de URL HTTP para coleções de coisas e para as próprias coisas. Você pode obter uma lista de pessoas ou interagir com uma única pessoa dessa lista de pessoas. Esse estilo de caminho refina o que é retornado da esquerda para a direita, ficando mais granular à medida que avança.
Você continuará esse padrão da esquerda para a direita para obter mais granularidade e acessar as coleções de notas. Aqui está a API REST estendida que você criará para fornecer notas ao aplicativo da web de miniblog:
| Ação | Verbo HTTP | Caminho do URL | Descrição |
|---|---|---|---|
| Criar | POST | /api/people/{person_id}/notes | URL para criar uma nova nota |
| Ler | GET | /api/people/{person_id}/notes/{note_id} | URL para ler a nota de uma única pessoa |
| Atualizar | PUT | api/people/{person_id}/notes/{note_id} | URL para atualizar a nota única de uma única pessoa |
| Excluir | DELETE | api/people/{person_id}/notes/{note_id} | URL para excluir a nota de uma única pessoa |
| Ler | GET | /api/notes | URL para obter todas as notas de todas as pessoas classificadas por note.timestamp |
Existem duas variações nas
notes parte da API REST em comparação com a convenção usada no people seção:-
Não há URL definido para obter todas asnotesassociado a uma pessoa, apenas um URL para obter uma única nota. Isso tornaria a API REST completa de certa forma, mas o aplicativo da Web que você criará mais tarde não precisa dessa funcionalidade. Por isso, ficou de fora.
-
Há a inclusão da última URL/api/notes. Este é um método de conveniência criado para a aplicação web. Ele será usado no mini-blog na página inicial para mostrar todas as notas do sistema. There isn’t a way to get this information readily using the REST API pathing style as designed, so this shortcut has been added.
As in Part 2, the REST API is configured in the
swagger.yml Arquivo. Observação:
The idea of designing a REST API with a path that gets more and more granular as you move from left to right is very useful. Thinking this way can help clarify the relationships between different parts of a database. Just be aware that there are realistic limits to how far down a hierarchical structure this kind of design should be taken.
For example, what if the
Note object had a collection of its own, something like comments on the notes. Using the current design ideas, this would lead to a URL that went something like this:/api/people/{person_id}/notes/{note_id}/comments/{comment_id} There is no practical limit to this kind of design, but there is one for usefulness. In actual use in real applications, a long, multilevel URL like that one is hardly ever needed. A more common pattern is to get a list of intervening objects (like notes) and then use a separate API entry point to get a single comment for an application use case.
Implement the API
With the updated REST API defined in the
swagger.yml file, you’ll need to update the implementation provided by the Python modules. This means updating existing module files, like models.py and people.py , and creating a new module file called notes.py to implement support for Notes in the extended REST API. Update Response JSON
The purpose of the REST API is to get useful JSON data out of the database. Now that you’ve updated the SQLAlchemy
Person and created the Note models, you’ll need to update the Marshmallow schema models as well. As you may recall from Part 2, Marshmallow is the module that translates the SQLAlchemy objects into Python objects suitable for creating JSON strings. The updated and newly created Marshmallow schemas are in the
models.py module, which are explained below, and look like this: 1class PersonSchema(ma.ModelSchema):
2 class Meta:
3 model = Person
4 sqla_session = db.session
5 notes = fields.Nested('PersonNoteSchema', default=[], many=True)
6
7class PersonNoteSchema(ma.ModelSchema):
8 """
9 This class exists to get around a recursion issue
10 """
11 note_id = fields.Int()
12 person_id = fields.Int()
13 content = fields.Str()
14 timestamp = fields.Str()
15
16class NoteSchema(ma.ModelSchema):
17 class Meta:
18 model = Note
19 sqla_session = db.session
20 person = fields.Nested('NotePersonSchema', default=None)
21
22class NotePersonSchema(ma.ModelSchema):
23 """
24 This class exists to get around a recursion issue
25 """
26 person_id = fields.Int()
27 lname = fields.Str()
28 fname = fields.Str()
29 timestamp = fields.Str()
There are some interesting things going on in the above definitions. The
PersonSchema class has one new entry:the notes attribute defined in line 5. This defines it as a nested relationship to the PersonNoteSchema . It will default to an empty list if nothing is present in the SQLAlchemy notes relationship. The many=True parameter indicates that this is a one-to-many relationship, so Marshmallow will serialize all the related notes . The
PersonNoteSchema class defines what a Note object looks like as Marshmallow serializes the notes Lista. The NoteSchema defines what a SQLAlchemy Note object looks like in terms of Marshmallow. Notice that it has a person attribute. This attribute comes from the SQLAlchemy db.relationship(...) definition parameter backref='person' . The person Marshmallow definition is nested, but because it doesn’t have the many=True parameter, there is only a single person connected. The
NotePersonSchema class defines what is nested in the NoteSchema.person attribute. Observação:
You might be wondering why the
PersonSchema class has its own unique PersonNoteSchema class to define the notes collection attribute. By the same token, the NoteSchema class has its own unique NotePersonSchema class to define the person attribute. You may be wondering whether the PersonSchema class could be defined this way:class PersonSchema(ma.ModelSchema):
class Meta:
model = Person
sqla_session = db.session
notes = fields.Nested('NoteSchema', default=[], many=True)
Additionally, couldn’t the
NoteSchema class be defined using the PersonSchema to define the person attribute? A class definition like this would each refer to the other, and this causes a recursion error in Marshmallow as it will cycle from PersonSchema to NoteSchema until it runs out of stack space. Using the unique schema references breaks the recursion and allows this kind of nesting to work. People
Now that you’ve got the schemas in place to work with the one-to-many relationship between
Person and Note , you need to update the person.py and create the note.py modules in order to implement a working REST API. The
people.py module needs two changes. The first is to import the Note class, along with the Person class at the top of the module. Then only read_one(person_id) needs to change in order to handle the relationship. That function will look like this: 1def read_one(person_id):
2 """
3 This function responds to a request for /api/people/{person_id}
4 with one matching person from people
5
6 :param person_id: Id of person to find
7 :return: person matching id
8 """
9 # Build the initial query
10 person = (
11 Person.query.filter(Person.person_id == person_id)
12 .outerjoin(Note)
13 .one_or_none()
14 )
15
16 # Did we find a person?
17 if person is not None:
18
19 # Serialize the data for the response
20 person_schema = PersonSchema()
21 data = person_schema.dump(person).data
22 return data
23
24 # Otherwise, nope, didn't find that person
25 else:
26 abort(404, f"Person not found for Id: {person_id}")
The only difference is line 12:
.outerjoin(Note) . An outer join (left outer join in SQL terms) is necessary for the case where a user of the application has created a new person object, which has no notes related to it. The outer join ensures that the SQL query will return a person object, even if there are no note rows to join with. At the start of this article, you saw how person and note data could be represented in a single, flat table, and all of the disadvantages of that approach. You also saw the advantages of breaking that data up into two tables,
person and note , with a relationship between them. Until now, we’ve been working with the data as two distinct, but related, items in the database. But now that you’re actually going to use the data, what we essentially want is for the data to be joined back together. This is what a database join does. It combines data from two tables together using the primary key to foreign key relationship.
A join is kind of a boolean
and operation because it only returns data if there is data in both tables to combine. If, for example, a person row exists but has no related note row, then there is nothing to join, so nothing is returned. This isn’t what you want for read_one(person_id) . This is where the outer join comes in handy. It’s a kind of boolean
or Operação. It returns person data even if there is no associated note data to combine with. This is the behavior you want for read_one(person_id) to handle the case of a newly created Person object that has no notes yet. You can see the complete
people.py in the article repository. Notes
You’ll create a
notes.py module to implement all the Python code associated with the new note related REST API definitions. In many ways, it works like the people.py module, except it must handle both a person_id and a note_id as defined in the swagger.yml configuration file. As an example, here is read_one(person_id, note_id) : 1def read_one(person_id, note_id):
2 """
3 This function responds to a request for
4 /api/people/{person_id}/notes/{note_id}
5 with one matching note for the associated person
6
7 :param person_id: Id of person the note is related to
8 :param note_id: Id of the note
9 :return: json string of note contents
10 """
11 # Query the database for the note
12 note = (
13 Note.query.join(Person, Person.person_id == Note.person_id)
14 .filter(Person.person_id == person_id)
15 .filter(Note.note_id == note_id)
16 .one_or_none()
17 )
18
19 # Was a note found?
20 if note is not None:
21 note_schema = NoteSchema()
22 data = note_schema.dump(note).data
23 return data
24
25 # Otherwise, nope, didn't find that note
26 else:
27 abort(404, f"Note not found for Id: {note_id}")
The interesting parts of the above code are lines 12 to 17:
- Line 13 begins a query against the
NoteSQLAlchemy objects and joins to the relatedPersonSQLAlchemy object comparingperson_idfrom bothPersonandNote. - Line 14 filters the result down to the
Noteobjects that has aPerson.person_idequal to the passed inperson_idparameter. - Line 15 filters the result further to the
Noteobject that has aNote.note_idequal to the passed innote_idparameter. - Line 16 returns the
Noteobject if found, orNoneif nothing matching the parameters is found.
You can check out the complete
notes.py . Updated Swagger UI
The Swagger UI has been updated by the action of updating the
swagger.yml file and creating the URL endpoint implementations. Below is a screenshot of the updated UI showing the Notes section with the GET /api/people/{person_id}/notes/{note_id} expanded: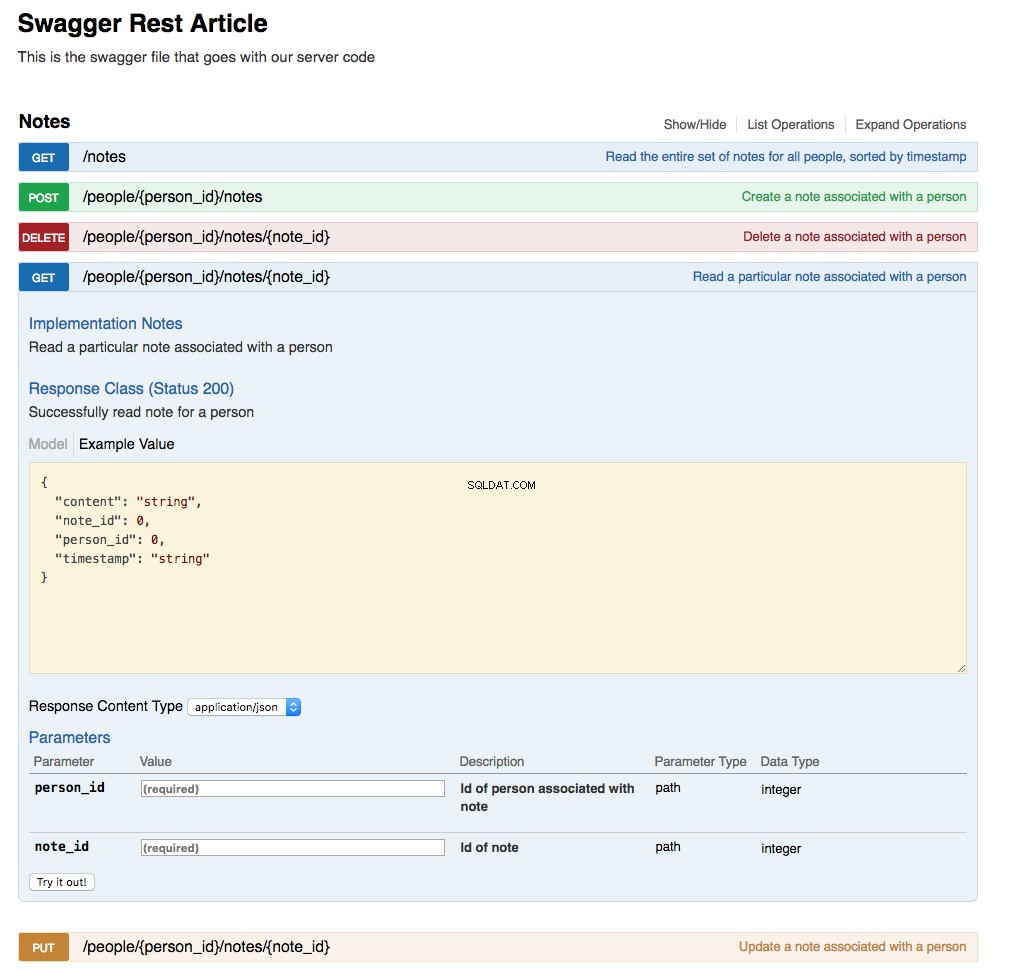
Mini-Blogging Web Application
The web application has been substantially changed to show its new purpose as a mini-blogging application. It has three pages:
-
The home page (localhost:5000/) , which shows all of the blog messages (notes) sorted from newest to oldest
-
The people page (localhost:5000/people) , which shows all the people in the system, sorted by last name, and also allows the user to create a new person and update or delete an existing one
-
The notes page (localhost:5000/people/{person_id}/notes) , which shows all the notes associated with a person, sorted from newest to oldest, and also allows the user to create a new note and update or delete an existing one
Navigation
There are two buttons on every page of the application:
- The Home button will navigate to the home screen.
- The People button navigates to the
/peoplescreen, showing all people in the database.
These two buttons are present on every screen in the application as a way to get back to a starting point.
Home Page
Below is a screenshot of the home page showing the initialized database contents:
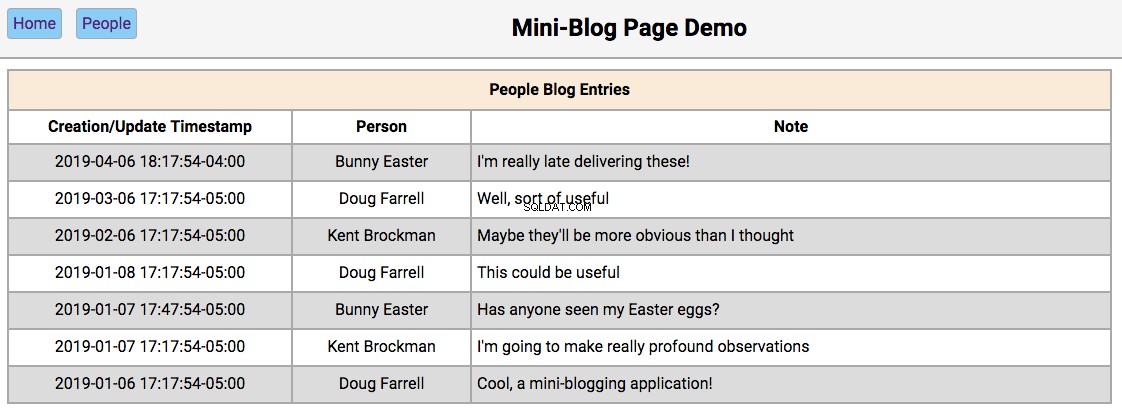
The functionality of this page works like this:
-
Double-clicking on a person’s name will take the user to the/people/{person_id}page, with the editor section filled in with the person’s first and last names and the update and reset buttons enabled.
-
Double-clicking on a person’s note will take the user to the/people/{person_id}/notes/{note_id}page, with the editor section filled in with the note’s contents and the Update and Reset buttons enabled.
People Page
Below is a screenshot of the people page showing the people in the initialized database:
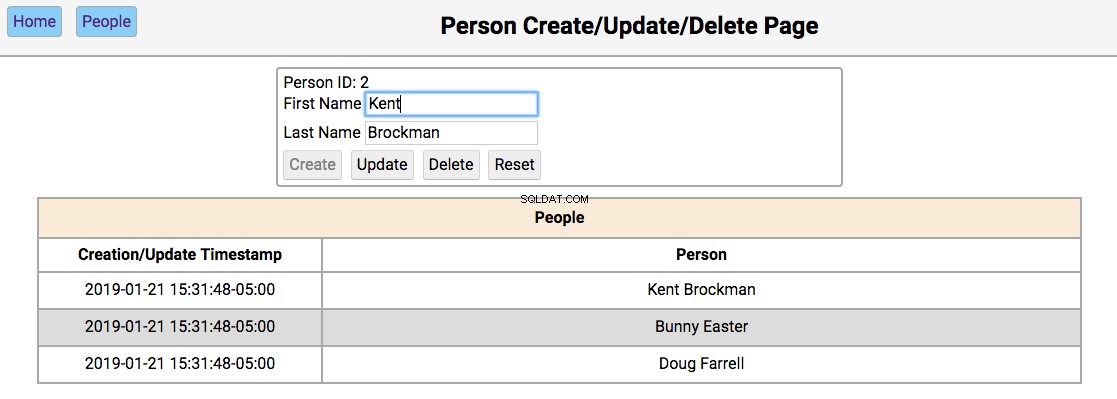
The functionality of this page works like this:
-
Single-clicking on a person’s name will populate the editor section of the page with the person’s first and last name, disabling the Create button, and enabling the Update and Delete buttons.
-
Double clicking on a person’s name will navigate to the notes pages for that person.
The functionality of the editor works like this:
-
If the first and last name fields are empty, the Create and Reset buttons are enabled. Entering a new name in the fields and clicking Create will create a new person and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the first and last name fields have data, the user navigated here by double-clicking the person’s name from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the first or last name and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the person from the database and re-render the table.
Notes Page
Below is a screenshot of the notes page showing the notes for a person in the initialized database:
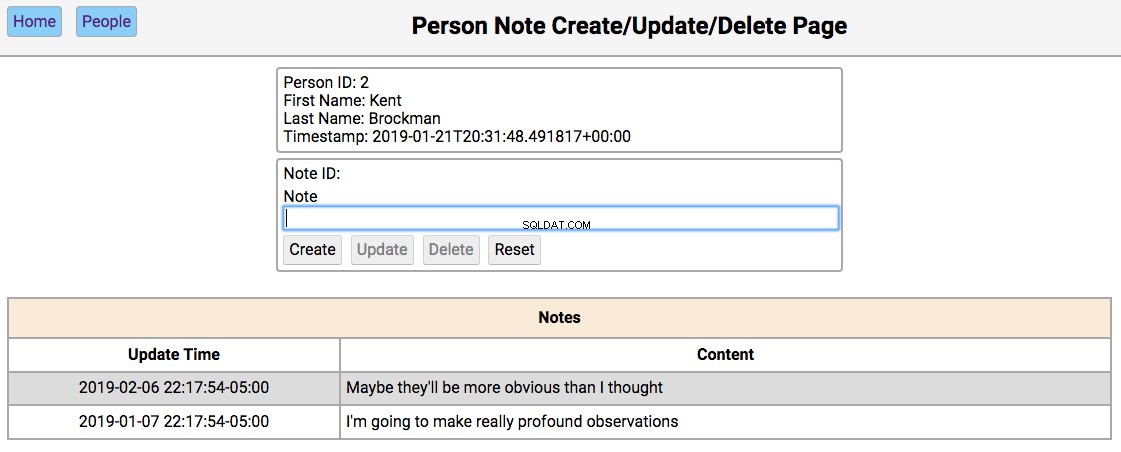
The functionality of this page works like this:
-
Single-clicking on a note will populate the editor section of the page with the notes content, disabling the Create button, and enabling the Update and Delete buttons.
-
All other functionality of this page is in the editor section.
The functionality of the editor works like this:
-
If the note content field is empty, then the Create and Reset buttons are enabled. Entering a new note in the field and clicking Create will create a new note and update the database and re-render the table below the editor. Clicking Reset will clear the editor fields.
-
If the note field has data, the user navigated here by double-clicking the person’s note from the home screen. In this case, the Update , Delete , and Reset buttons are enabled. Changing the note and clicking Update will update the database and re-render the table below the editor. Clicking Delete will remove the note from the database and re-render the table.
Web Application
This article is primarily focused on how to use SQLAlchemy to create relationships in the database, and how to extend the REST API to take advantage of those relationships. As such, the code for the web application didn’t get much attention. When you look at the web application code, keep an eye out for the following features:
-
Each page of the application is a fully formed single page web application.
-
Each page of the application is driven by JavaScript following an MVC (Model/View/Controller) style of responsibility delegation.
-
The HTML that creates the pages takes advantage of the Jinja2 inheritance functionality.
-
The hardcoded JavaScript table creation has been replaced by using the Handlebars.js templating engine.
-
The timestamp formating in all of the tables is provided by Moment.js.
You can find the following code in the repository for this article:
- The HTML for the web application
- The CSS for the web application
- The JavaScript for the web application
All of the example code for this article is available in the GitHub repository for this article. This contains all of the code related to this article, including all of the web application code.
Conclusão
Congratulations are in order for what you’ve learned in this article! Knowing how to build and use database relationships gives you a powerful tool to solve many difficult problems. There are other relationship besides the one-to-many example from this article. Other common ones are one-to-one, many-to-many, and many-to-one. All of them have a place in your toolbelt, and SQLAlchemy can help you tackle them all!
For more information about databases, you can check out these tutorials. You can also set up Flask to use SQLAlchemy. You can check out Model-View-Controller (MVC) more information about the pattern used in the web application JavaScript code.
In Part 4 of this series, you’ll focus on the HTML, CSS, and JavaScript files used to create the web application.
« Part 2:Database PersistencePart 3:Database RelationshipsPart 4:Simple Web Applications »