Na Parte 1 e na Parte 2 desta série, abordei os aspectos lógicos ou conceituais das expressões de tabela nomeada em geral e das tabelas derivadas especificamente. Este mês e no próximo vou cobrir os aspectos de processamento físico de tabelas derivadas. Lembre-se da Parte 1 da independência de dados físicos princípio da teoria relacional. O modelo relacional e a linguagem de consulta padrão que se baseia nele devem lidar apenas com os aspectos conceituais dos dados e deixar os detalhes de implementação física como armazenamento, otimização, acesso e processamento dos dados para a plataforma de banco de dados (o implementação ). Ao contrário do tratamento conceitual dos dados que é baseado em um modelo matemático e uma linguagem padrão e, portanto, é muito semelhante nos vários sistemas de gerenciamento de banco de dados relacionais existentes, o tratamento físico dos dados não é baseado em nenhum padrão e, portanto, tende a para ser muito específico da plataforma. Na minha cobertura do tratamento físico de expressões de tabelas nomeadas na série, concentro-me no tratamento no Microsoft SQL Server e no Banco de Dados SQL do Azure. O tratamento físico em outras plataformas de banco de dados pode ser bem diferente.
Lembre-se de que o que desencadeou esta série foi alguma confusão que existe na comunidade do SQL Server em torno de expressões de tabela nomeada. Tanto em termos de terminologia como em termos de otimização. Abordei algumas considerações de terminologia nas duas primeiras partes da série e abordarei mais em artigos futuros ao discutir CTEs, visualizações e TVFs inline. Quanto à otimização de expressões de tabela nomeada, há confusão em torno dos seguintes itens (menciono tabelas derivadas aqui, pois esse é o foco deste artigo):
- Persistência: Uma tabela derivada é persistida em algum lugar? Ele é persistido no disco e como o SQL Server lida com a memória para ele?
- Projeção de coluna: Como a correspondência de índice funciona com tabelas derivadas? Por exemplo, se uma tabela derivada projeta um determinado subconjunto de colunas de alguma tabela subjacente e a consulta externa projeta um subconjunto das colunas da tabela derivada, o SQL Server é inteligente o suficiente para descobrir a indexação ideal com base no subconjunto final de colunas que é realmente necessário? E as permissões; o usuário precisa de permissões para todas as colunas que são referenciadas nas consultas internas ou apenas para as últimas que são realmente necessárias?
- Várias referências a aliases de coluna: Se a tabela derivada tiver uma coluna de resultado baseada em uma computação não determinística, por exemplo, uma chamada para a função SYSDATETIME, e a consulta externa tiver várias referências a essa coluna, a computação será feita apenas uma vez ou separadamente para cada referência externa ?
- Desaninhamento/substituição/inline: O SQL Server desaninha ou inline a consulta de tabela derivada? Ou seja, o SQL Server executa um processo de substituição pelo qual converte o código aninhado original em uma consulta que vai diretamente nas tabelas base? E em caso afirmativo, existe uma maneira de instruir o SQL Server para evitar esse processo de desaninhamento?
Essas são todas perguntas importantes e as respostas a essas perguntas têm implicações significativas no desempenho, portanto, é uma boa ideia ter uma compreensão clara de como esses itens são tratados no SQL Server. Este mês vou abordar os três primeiros itens. Há muito a dizer sobre o quarto item, então dedicarei um artigo separado a ele no próximo mês (Parte 4).
Em meus exemplos, usarei um banco de dados de exemplo chamado TSQLV5. Você pode encontrar o script que cria e preenche o TSQLV5 aqui e seu diagrama ER aqui.
Persistência
Algumas pessoas assumem intuitivamente que o SQL Server mantém o resultado da parte da expressão de tabela da tabela derivada (o resultado da consulta interna) em uma tabela de trabalho. Na data desta redação, esse não é o caso; no entanto, como as considerações de persistência são uma escolha do fornecedor, a Microsoft pode decidir mudar isso no futuro. Na verdade, o SQL Server é capaz de persistir resultados de consultas intermediárias em tabelas de trabalho (normalmente em tempdb) como parte do processamento da consulta. Se optar por fazê-lo, você verá algum tipo de operador de spool no plano (Spool, Spool Eager, Spool Lazy, Spool de Mesa, Spool de Índice, Spool de Janela, Spool de Contagem de Linhas). No entanto, a escolha do SQL Server de colocar algo em spool em uma tabela de trabalho ou não atualmente não tem nada a ver com o uso de expressões de tabela nomeada na consulta. O SQL Server às vezes coloca em spool resultados intermediários por motivos de desempenho, como evitar trabalho repetido (embora atualmente não relacionado ao uso de expressões de tabela nomeada) e, às vezes, por outros motivos, como proteção de Halloween.
Como mencionado, no próximo mês eu vou chegar aos detalhes de desaninhamento de tabelas derivadas. Por enquanto, basta dizer que o SQL Server normalmente aplica um processo de desaninhamento/embutimento a tabelas derivadas, onde substitui as consultas aninhadas por uma consulta nas tabelas base subjacentes. Bem, estou simplificando um pouco. Não é como se o SQL Server literalmente convertesse a string de consulta T-SQL original com as tabelas derivadas em uma nova string de consulta sem elas; em vez disso, o SQL Server aplica transformações a uma árvore lógica interna de operadores, e o resultado é que as tabelas derivadas normalmente são desaninhadas. Quando você observa um plano de execução para uma consulta envolvendo tabelas derivadas, não vê nenhuma menção a elas porque, para a maioria dos propósitos de otimização, elas não existem. Você vê o acesso às estruturas físicas que mantêm os dados para as tabelas base subjacentes (heap, índices rowstore de árvore B e índices columnstore para tabelas baseadas em disco e índices de árvore e hash para tabelas com otimização de memória).
Há casos que impedem o SQL Server de desaninhar uma tabela derivada, mas mesmo nesses casos o SQL Server não persiste o resultado da expressão de tabela em uma tabela de trabalho. Vou fornecer os detalhes junto com exemplos no próximo mês.
Como o SQL Server não mantém tabelas derivadas, mas interage diretamente com as estruturas físicas que contêm os dados das tabelas base subjacentes, a questão sobre como a memória é tratada para tabelas derivadas é discutível. Se as tabelas base subjacentes forem baseadas em disco, suas páginas relevantes precisam ser processadas no buffer pool. Se as tabelas subjacentes forem otimizadas para memória, suas linhas relevantes na memória precisam ser processadas. Mas isso não é diferente de quando você consulta as tabelas subjacentes diretamente sem usar tabelas derivadas. Então não há nada de especial aqui. Quando você usa tabelas derivadas, o SQL Server não precisa aplicar nenhuma consideração especial de memória para elas. Para a maioria dos propósitos de otimização de consulta, eles não existem.
Se você tiver um caso em que precisa persistir o resultado de alguma etapa intermediária em uma tabela de trabalho, precisará usar tabelas temporárias ou variáveis de tabela - não expressões de tabela nomeadas.
Projeção de coluna e uma palavra em SELECT *
A projeção é um dos operadores originais da álgebra relacional. Suponha que você tenha uma relação R1 com atributos x, y e z. A projeção de R1 em algum subconjunto de seus atributos, por exemplo, x e z, é uma nova relação R2, cujo cabeçalho é o subconjunto de atributos projetados de R1 (x e z em nosso caso), e cujo corpo é o conjunto de tuplas formado a partir da combinação original de valores de atributos projetados das tuplas de R1.
Lembre-se de que o corpo de uma relação – sendo um conjunto de tuplas – por definição não tem duplicatas. Portanto, não é preciso dizer que as tuplas da relação de resultado são a combinação distinta de valores de atributo projetados a partir da relação original. No entanto, lembre-se de que o corpo de uma tabela em SQL é um multiconjunto de linhas e não um conjunto e, normalmente, o SQL não eliminará linhas duplicadas, a menos que você o instrua. Dada uma tabela R1 com colunas x, y e z, a consulta a seguir pode retornar linhas duplicadas e, portanto, não segue a semântica do operador de projeção da álgebra relacional de retornar um conjunto:
SELECT x, zFROM R1;
Ao adicionar uma cláusula DISTINCT, você elimina linhas duplicadas e segue mais de perto a semântica da projeção relacional:
SELECT DISTINCT x, zFROM R1;
Claro, existem alguns casos em que você sabe que o resultado da sua consulta tem linhas distintas sem a necessidade de uma cláusula DISTINCT, por exemplo, quando um subconjunto das colunas que você está retornando inclui uma chave da tabela consultada. Por exemplo, se x for uma chave em R1, as duas consultas acima são logicamente equivalentes.
De qualquer forma, lembre-se das perguntas que mencionei anteriormente sobre a otimização de consultas envolvendo tabelas derivadas e projeção de colunas. Como funciona a correspondência de índice? Se uma tabela derivada projeta um determinado subconjunto de colunas de alguma tabela subjacente e a consulta externa projeta um subconjunto das colunas da tabela derivada, o SQL Server é inteligente o suficiente para descobrir a indexação ideal com base no subconjunto final de colunas que é realmente precisava? E as permissões; o usuário precisa de permissões para todas as colunas que são referenciadas nas consultas internas ou apenas para as últimas que são realmente necessárias? Além disso, suponha que a consulta de expressão de tabela defina uma coluna de resultado baseada em um cálculo, mas a consulta externa não projete essa coluna. A computação é avaliada?
Começando com a última pergunta, vamos tentar. Considere a seguinte consulta:
USE TSQLV5;GO SELECT custid, cidade, 1/0 AS div0errorFROM Sales.Customers;
Como seria de esperar, esta consulta falha com um erro de divisão por zero:
Msg 8134, Level 16, State 1
Dividir por zero erro encontrado.
Em seguida, defina uma tabela derivada chamada D com base na consulta acima e no projeto de consulta externa D em apenas custid e city, assim:
SELECT custid, cityFROM ( SELECT custid, city, 1/0 AS div0error FROM Sales.Customers ) AS D;
Como mencionado, o SQL Server normalmente aplica desaninhamento/substituição, e como não há nada nesta consulta que iniba o desaninhamento (mais neste próximo mês), a consulta acima é equivalente à seguinte consulta:
SELECT custid, cityFROM Sales.Customers;
Novamente, estou simplificando um pouco aqui. A realidade é um pouco mais complexa do que essas duas consultas sendo consideradas realmente idênticas, mas chegarei a essas complexidades no próximo mês. A questão é que a expressão 1/0 nem aparece no plano de execução da consulta e não é avaliada, então a consulta acima é executada com sucesso sem erros.
Ainda assim, a expressão da tabela precisa ser válida. Por exemplo, considere a seguinte consulta:
SELECT countryFROM ( SELECT * FROM Sales.Customers GROUP BY country ) AS D;
Embora a consulta externa projete apenas uma coluna do conjunto de agrupamento da consulta interna, a consulta interna não é válida, pois tenta retornar colunas que não fazem parte do conjunto de agrupamento nem estão contidas em uma função agregada. Esta consulta falha com o seguinte erro:
Msg 8120, Level 16, State 1
A coluna 'Sales.Customers.custid' é inválida na lista de seleção porque não está contida em uma função agregada ou na cláusula GROUP BY.
Em seguida, vamos abordar a questão de correspondência de índice. Se a consulta externa projetar apenas um subconjunto das colunas da tabela derivada, o SQL Server será inteligente o suficiente para fazer a correspondência de índice com base apenas nas colunas retornadas (e, claro, quaisquer outras colunas que desempenhem um papel significativo, como filtragem, agrupamento e assim por diante)? Mas antes de abordarmos essa questão, você pode se perguntar por que estamos nos preocupando com isso. Por que você faria a consulta interna retornar colunas que a consulta externa não precisa?
A resposta é simples, para encurtar o código fazendo com que a consulta interna use o infame SELECT *. Todos nós sabemos que usar SELECT * é uma prática ruim, mas esse é o caso principalmente quando é usado na consulta externa. E se você consultar uma tabela com um determinado título e, posteriormente, esse título for alterado? O aplicativo pode acabar com bugs. Mesmo que você não acabe com bugs, você pode acabar gerando tráfego de rede desnecessário retornando colunas que o aplicativo realmente não precisa. Além disso, você utiliza a indexação de forma menos otimizada nesse caso, pois reduz as chances de correspondência de índices de cobertura baseados nas colunas realmente necessárias.
Dito isso, na verdade me sinto bastante confortável usando SELECT * em uma expressão de tabela, sabendo que vou projetar apenas as colunas realmente necessárias na consulta mais externa. Do ponto de vista lógico, isso é bastante seguro, com algumas pequenas ressalvas que chegarei em breve. Isso desde que a correspondência de índice seja feita de maneira ideal nesse caso, e a boa notícia é que é.
Para demonstrar isso, suponha que você precise consultar a tabela Sales.Orders, retornando os três pedidos mais recentes de cada cliente. Você está planejando definir uma tabela derivada chamada D com base em uma consulta que calcula números de linha (coluna de resultado rownum) que são particionados por custid e ordenados por orderdate DESC, orderid DESC. A consulta externa filtrará de D (restrição relacional ) apenas as linhas em que rownum é menor ou igual a 3 e projeta D em custid, orderdate, orderid e rownum. Agora, Sales.Orders tem mais colunas do que as que você precisa para projetar, mas para ser mais breve, você quer que a consulta interna use SELECT *, mais o cálculo do número da linha. Isso é seguro e será tratado de forma otimizada em termos de correspondência de índice.
Use o código a seguir para criar o índice de cobertura ideal para dar suporte à sua consulta:
CREATE INDEX idx_custid_odD_oidD ON Sales.Orders(custid, orderdate DESC, orderid DESC);
Aqui está a consulta que arquiva a tarefa em questão (vamos chamá-la de Consulta 1):
SELECT custid, orderdate, orderid, rownumFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE rownum <=3;
Observe o SELECT * da consulta interna e a lista de colunas explícitas da consulta externa.
O plano para esta consulta, conforme renderizado pelo SentryOne Plan Explorer, é mostrado na Figura 1.
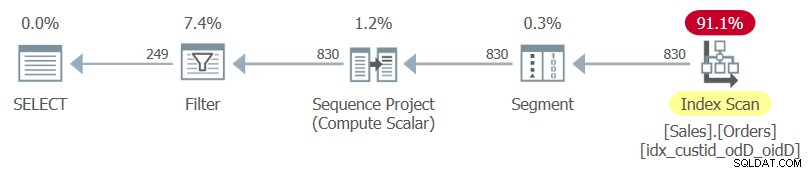 Figura 1:plano para consulta 1
Figura 1:plano para consulta 1 Observe que o único índice usado neste plano é o índice de cobertura ideal que você acabou de criar.
Se você destacar apenas a consulta interna e examinar seu plano de execução, verá o índice clusterizado da tabela usado seguido por uma operação de classificação.
Então isso é uma boa notícia.
Quanto às permissões, essa é uma história diferente. Ao contrário da correspondência de índice, em que você não precisa que o índice inclua colunas referenciadas pelas consultas internas, desde que elas não sejam necessárias, você precisa ter permissões para todas as colunas referenciadas.
Para demonstrar isso, use o código a seguir para criar um usuário chamado user1 e atribuir algumas permissões (permissões SELECT em todas as colunas de Sales.Customers e apenas nas três colunas de Sales.Orders que são relevantes na consulta acima):
CRIA USUÁRIO user1 SEM LOGIN; GRANT SHOWPLAN TO user1; GRANT SELECT ON Sales.Customers TO user1; GRANT SELECT ON Sales.Orders(custid, orderdate, orderid) TO user1;
Execute o seguinte código para representar user1:
EXECUTAR COMO USUÁRIO ='usuário1';
Tente selecionar todas as colunas de Sales.Orders:
SELECT * FROM Sales.Orders;
Como esperado, você recebe os seguintes erros devido à falta de permissões em algumas das colunas:
Msg 230, Level 14, State 1
A permissão SELECT foi negada na coluna 'empid' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230 , Nível 14, Estado 1
A permissão SELECT foi negada na coluna 'requireddate' do objeto 'Pedidos', banco de dados 'TSQLV5', esquema 'Vendas'.
Msg 230, Nível 14, Estado 1
A permissão SELECT foi negada na coluna 'data de envio' do objeto 'Pedidos', banco de dados 'TSQLV5', esquema 'Vendas'.
Msg 230, Nível 14, Estado 1
A permissão SELECT foi negada na coluna 'shipperid' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
A permissão SELECT foi negada na coluna 'freight' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
/>A permissão SELECT foi negada na coluna 'shipname' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
/>A permissão SELECT foi negada na coluna 'shipaddress' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
A permissão SELECT foi negada na coluna 'shipcity' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
O SELECT foi negada a permissão na coluna 'shipregion' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
A permissão SELECT foi negado na coluna 'shippostalcode' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
A permissão SELECT foi negada em a coluna 'shipcountry' do objeto 'Pedidos', banco de dados 'TSQLV5', esquema 'Vendas'.
Tente a seguinte consulta, projetando e interagindo apenas com colunas para as quais user1 tem permissões:
SELECT custid, orderdate, orderid, rownumFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE rownum <=3;
Ainda assim, você obtém erros de permissão de coluna devido à falta de permissões em algumas das colunas que são referenciadas pela consulta interna por meio de seu SELECT *:
Msg 230, Level 14, State 1
A permissão SELECT foi negada na coluna 'empid' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230 , Nível 14, Estado 1
A permissão SELECT foi negada na coluna 'requireddate' do objeto 'Pedidos', banco de dados 'TSQLV5', esquema 'Vendas'.
Msg 230, Nível 14, Estado 1
A permissão SELECT foi negada na coluna 'data de envio' do objeto 'Pedidos', banco de dados 'TSQLV5', esquema 'Vendas'.
Msg 230, Nível 14, Estado 1
A permissão SELECT foi negada na coluna 'shipperid' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
A permissão SELECT foi negada na coluna 'freight' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
/>A permissão SELECT foi negada na coluna 'shipname' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
/>A permissão SELECT foi negada na coluna 'shipaddress' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
A permissão SELECT foi negada na coluna 'shipcity' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
O SELECT foi negada a permissão na coluna 'shipregion' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
A permissão SELECT foi negado na coluna 'shippostalcode' do objeto 'Orders', banco de dados 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
A permissão SELECT foi negada em a coluna 'shipcountry' do objeto 'Pedidos', banco de dados 'TSQLV5', esquema 'Vendas'.
Se de fato em sua empresa é uma prática atribuir permissões aos usuários apenas em colunas relevantes com as quais eles precisam interagir, faria sentido usar um código um pouco mais longo e ser explícito sobre a lista de colunas nas consultas internas e externas, igual a:
SELECT custid, orderdate, orderid, rownumFROM ( SELECT custid, orderdate, orderid, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE rownum <=3;
Desta vez, a consulta é executada sem erros.
Outra variação que exige que o usuário tenha permissões apenas nas colunas relevantes é ser explícito sobre os nomes das colunas na lista SELECT da consulta interna e usar SELECT * na consulta externa, assim:
SELECT *FROM ( SELECT custid, orderdate, orderid, ROW_NUMBER() OVER(PARTITION BY custid ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.Orders ) AS DWHERE rownum <=3;
Essa consulta também é executada sem erros. No entanto, vejo esta versão como propensa a bugs, caso mais tarde algumas alterações sejam feitas em algum nível interno de aninhamento. Como mencionado anteriormente, para mim, a melhor prática é ser explícito sobre a lista de colunas na consulta externa. Portanto, desde que você não tenha nenhuma preocupação com a falta de permissão em algumas das colunas, me sinto confortável com SELECT * em consultas internas, mas uma lista de colunas explícita na consulta externa. Se a aplicação de permissões de coluna específicas for uma prática comum na empresa, é melhor simplesmente ser explícito sobre os nomes das colunas em todos os níveis de aninhamento. Lembre-se de que ser explícito sobre os nomes das colunas em todos os níveis de aninhamento é realmente obrigatório se sua consulta for usada em um objeto vinculado a esquema, pois a vinculação de esquema não permite o uso de SELECT * em qualquer lugar da consulta.
Neste ponto, execute o seguinte código para remover o índice que você criou anteriormente em Sales.Orders:
DROP INDEX IF EXISTS idx_custid_odD_oidD ON Sales.Orders;
Há outro caso com um dilema semelhante em relação à legitimidade do uso de SELECT *; na consulta interna do predicado EXISTS.
Considere a seguinte consulta (vamos chamá-la de Consulta 2):
SELECT custidFROM Sales.Customers AS CWHERE EXISTS (SELECT * FROM Sales.Orders AS O WHERE O.custid =C.custid);
O plano para esta consulta é mostrado na Figura 2.
Figura 2:plano para consulta 2
Ao aplicar a correspondência de índice, o otimizador percebeu que o índice idx_nc_custid é um índice de cobertura em Sales.Orders, pois contém a coluna custid — a única coluna realmente relevante nessa consulta. Isso apesar do fato de que este índice não contém nenhuma outra coluna além de custid, e que a consulta interna no predicado EXISTS diz SELECT *. Até agora, o comportamento parece semelhante ao uso de SELECT * em tabelas derivadas.
A diferença dessa consulta é que ela é executada sem erros, apesar de user1 não ter permissões em algumas das colunas de Sales.Orders. Há um argumento para justificar não exigir permissões em todas as colunas aqui. Afinal, o predicado EXISTS só precisa verificar a existência de linhas correspondentes, então a lista SELECT da consulta interna é realmente sem sentido. Provavelmente teria sido melhor se o SQL não exigisse uma lista SELECT nesse caso, mas esse navio já partiu. A boa notícia é que a lista SELECT é efetivamente ignorada - tanto em termos de correspondência de índice quanto em termos de permissões necessárias.
Também parece que há outra diferença entre tabelas derivadas e EXISTS ao usar SELECT * na consulta interna. Lembre-se desta consulta no início do artigo:
SELECT countryFROM ( SELECT * FROM Sales.Customers GROUP BY country ) AS D;
Se você se lembra, esse código gerou um erro, pois a consulta interna é inválida.
Tente a mesma consulta interna, só que desta vez no predicado EXISTS (chamaremos isso de Declaração 3):
IF EXISTS ( SELECT * FROM Sales.Customers GROUP BY country ) PRINT 'Isto funciona! Obrigado Dmitri Korotkevitch pela dica!';
Estranhamente, o SQL Server considera esse código válido e é executado com êxito. O plano para este código é mostrado na Figura 3.
Figura 3:plano para a declaração 3
Este plano é idêntico ao plano que você obteria se a consulta interna fosse apenas SELECT * FROM Sales.Customers (sem o GROUP BY). Afinal, você está verificando a existência de grupos e, se houver linhas, naturalmente haverá grupos. De qualquer forma, acho que o fato de o SQL Server considerar essa consulta como válida é um bug. Certamente, o código SQL deve ser válido! Mas posso ver por que alguns podem argumentar que a lista SELECT na consulta EXISTS deve ser ignorada. De qualquer forma, o plano usa uma semijunção esquerda testada, que não precisa retornar nenhuma coluna, em vez disso, apenas sonda uma tabela para verificar a existência de quaisquer linhas. O índice em Clientes pode ser qualquer índice.
Neste ponto, você pode executar o seguinte código para parar de representar o usuário1 e eliminá-lo:
REVERTER; DROP USER SE EXISTE user1;
Voltando ao fato de que acho uma prática conveniente usar SELECT * em níveis internos de aninhamento, quanto mais níveis você tiver, mais essa prática encurtará e simplificará seu código. Aqui está um exemplo com dois níveis de aninhamento:
SELECT orderid, orderyear, custid, empid, shipperidFROM ( SELECT *, DATEFROMPARTS(orderyear, 12, 31) AS endofyear FROM ( SELECT *, YEAR(orderdate) AS orderyear FROM Sales.Orders ) AS D1 ) AS D2WHERE orderdate =fim de ano;
Há casos em que esta prática não pode ser utilizada. Por exemplo, quando a consulta interna une tabelas com nomes de colunas comuns, como no exemplo a seguir:
SELECT custid, nome da empresa, orderdate, orderid, rownumFROM ( SELECT *, ROW_NUMBER() OVER(PARTITION BY C.custid ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum FROM Sales.Customers AS C LEFT OUTER JOIN Vendas.Pedidos AS O ON C.custid =O.custid ) AS DWHERE rownum <=3;
Tanto Sales.Customers quanto Sales.Orders têm uma coluna chamada custid. Você está usando uma expressão de tabela baseada em uma junção entre as duas tabelas para definir a tabela derivada D. Lembre-se de que o cabeçalho de uma tabela é um conjunto de colunas e, como conjunto, você não pode ter nomes de coluna duplicados. Portanto, essa consulta falha com o seguinte erro:
Msg 8156, Level 16, State 1
A coluna 'custid' foi especificada várias vezes para 'D'.
Aqui, você precisa ser explícito sobre os nomes das colunas na consulta interna e certificar-se de retornar custid de apenas uma das tabelas ou atribuir nomes de coluna exclusivos às colunas de resultado caso deseje retornar ambas. Mais frequentemente, você usaria a abordagem anterior, assim:
SELECT custid, companyname, orderdate, orderid, rownumFROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid, ROW_NUMBER() OVER(PARTITION BY C.custid ORDER BY O.orderdate DESC, O. orderid DESC) AS rownum FROM Sales.Customers AS C LEFT OUTER JOIN Sales.Orders AS O ON C.custid =O.custid ) AS DWHERE rownum <=3;
Novamente, você pode ser explícito com os nomes das colunas na consulta interna e usar SELECT * na consulta externa, assim:
SELECT *FROM ( SELECT C.custid, C.companyname, O.orderid, O.orderid, ROW_NUMBER() OVER(PARTITION BY C.custid ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum FROM Sales .Clientes AS C LEFT OUTER JOIN Vendas.Pedidos AS O ON C.custid =O.custid ) AS DWHERE rownum <=3;
Mas, como mencionei anteriormente, considero uma prática ruim não ser explícito sobre os nomes das colunas na consulta externa.
Várias referências a aliases de coluna
Vamos prosseguir para o próximo item – várias referências a colunas de tabelas derivadas. Se a tabela derivada tiver uma coluna de resultado baseada em uma computação não determinística e a consulta externa tiver várias referências a essa coluna, a computação será avaliada apenas uma vez ou separadamente para cada referência?
Vamos começar com o fato de que várias referências à mesma função não determinística em uma consulta devem ser avaliadas independentemente. Considere a seguinte consulta como um exemplo:
SELECT NEWID() AS mynewid1, NEWID() AS mynewid2;
Este código gera a seguinte saída mostrando dois GUIDs diferentes:
mynewid1 mynewid2--------------------- --------- ---------------------------7BF389EC-082F-44DA-B98A-DB85CD095506 EA1EFF65-B2E4-4060-9592-7116F674D406
Por outro lado, se você tiver uma tabela derivada com uma coluna baseada em uma computação não determinística e a consulta externa tiver várias referências a essa coluna, a computação deverá ser avaliada apenas uma vez. Considere a seguinte consulta (chamaremos isso de Consulta 4):
SELECT mynewid AS mynewid1, mynewid AS mynewid2FROM ( SELECT NEWID() AS mynewid ) AS D;
O plano para esta consulta é mostrado na Figura 4.
Figura 4:planejar a consulta 4
Observe que há apenas uma invocação da função NEWID no plano. Assim, a saída mostra o mesmo GUID duas vezes:
mynewid1 mynewid2--------------------- --------- ---------------------------296A80C9-260A-47F9-9EB1-C2D0C401E74A 296A80C9-260A-47F9-9EB1-C2D0C401E74A
Portanto, as duas consultas acima não são logicamente equivalentes e há casos em que a inserção/substituição não ocorre.
Com algumas funções não determinísticas, é um pouco mais complicado demonstrar que várias invocações em uma consulta são tratadas separadamente. Tome a função SYSDATETIME como exemplo. Tem precisão de 100 nanossegundos. Quais são as chances de que uma consulta como a seguinte mostre realmente dois valores diferentes?
SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2;
Se você estiver entediado, pode pressionar F5 repetidamente até que isso aconteça. Se você tiver coisas mais importantes para fazer com seu tempo, talvez prefira executar um loop, assim:
DECLARE @i AS INT =1; WHILE EXISTS( SELECT * FROM ( SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2 ) AS D WHERE mydt1 =mydt2 ) SET @i +=1; IMPRIMIR @i;
Por exemplo, quando executei este código, obtive 1971.
Se você quiser certificar-se de que a função não determinística seja invocada apenas uma vez e contar com o mesmo valor em várias referências de consulta, certifique-se de definir uma expressão de tabela com uma coluna baseada na invocação da função e ter várias referências a essa coluna da consulta externa, assim (chamaremos essa Consulta 5):
SELECT mydt AS mydt1, mydt AS mydt1FROM ( SELECT SYSDATETIME() AS mydt ) AS D;
O plano para esta consulta é mostrado na Figura 5.
Figura 5:planejar a consulta 5
Observe no plano que a função é chamada apenas uma vez.
Agora, este pode ser um exercício muito interessante em pacientes para bater F5 repetidamente até obter dois valores diferentes. A boa notícia é que uma vacina para o COVID-19 será encontrada mais cedo.
Você pode, é claro, tentar executar um teste com um loop:
DECLARE @i AS INT =1; WHILE EXISTS ( SELECT * FROM (SELECT mydt AS mydt1, mydt AS mydt2 FROM ( SELECT SYSDATETIME() AS mydt ) AS D1) AS D2 WHERE mydt1 =mydt2 ) SET @i +=1; PRINT @i;
You can let it run as long as you feel that it’s reasonable to wait, but of course it won’t stop on its own.
Understanding this, you will know to avoid writing code such as the following:
SELECT CASE WHEN RAND() <0.5 THEN STR(RAND(), 5, 3) + ' is less than half.' ELSE STR(RAND(), 5, 3) + ' is at least half.' END;
Because occasionally, the output will not seem to make sense, e.g.,
0.550 is less than half.For more on evaluation within a CASE expression, see the section "Expressions can be evaluated more than once" in Aaron Bertrand's post, "Dirty Secrets of the CASE Expression."
Instead, you should either store the function’s result in a variable and then work with the variable or, if it needs to be part of a query, you can always work with a derived table, like so:
SELECT CASE WHEN rnd <0.5 THEN STR(rnd, 5, 3) + ' is less than half.' ELSE STR(rnd, 5, 3) + ' is at least half.' ENDFROM ( SELECT RAND() AS rnd ) AS D;Resumo
In this article I covered some aspects of the physical processing of derived tables.
When the outer query projects only a subset of the columns of a derived table, SQL Server is able to apply efficient index matching based on the columns in the outermost SELECT list, or that play some other meaningful role in the query, such as filtering, grouping, ordering, and so on. From this perspective, if for brevity you prefer to use SELECT * in inner levels of nesting, this will not negatively affect index matching. However, the executing user (or the user whose effective permissions are evaluated), needs permissions to all columns that are referenced in inner levels of nesting, even those that eventually are not really relevant. An exception to this rule is the SELECT list of the inner query in an EXISTS predicate, which is effectively ignored.
When you have multiple references to a nondeterministic function in a query, the different references are evaluated independently. Conversely, if you encapsulate a nondeterministic function call in a result column of a derived table, and refer to that column multiple times from the outer query, all references will rely on the same function invocation and get the same values.