O Modelo Relacional de gerenciamento de dados foi desenvolvido pela primeira vez pelo Dr. Edgar F. Codd em 1969. Os modernos sistemas de gerenciamento de banco de dados relacional (RDBMSs) estão alinhados com o paradigma. A estrutura chave identificada com RDBMS é a estrutura lógica chamada de “tabela”. As tabelas são compostas principalmente de linhas e colunas (também chamadas de registros e atributos ou tuplas e campos). Em um sentido matemático estrito, o termo tabela é realmente referido como uma relação e responde pelo termo “Modelo Relacional”. Em matemática, uma relação é uma representação de um conjunto.
O atributo expression fornece uma boa descrição da finalidade de uma coluna – caracteriza o conjunto de linhas associadas a ela. Cada coluna deve ser de um tipo de dados específico e cada linha deve ter algumas características de identificação exclusivas chamadas “chaves”. A mudança de dados geralmente é mais eficiente quando feita usando o modelo relacional, enquanto a recuperação de dados pode ser mais rápida com o modelo hierárquico mais antigo, que foi redefinido em sistemas NoSQL de modelo.
A Normalização de Dados é um processo matemático de modelagem de dados de negócios em um formato que garante que cada entidade seja representada por uma única relação (tabela). Os primeiros proponentes do modelo relacional propuseram um conceito de Formas Normais. Edgar Codd definiu a primeira, a segunda e a terceira Formas Normais. Ele foi então acompanhado por Raymond F. Boyce. Juntos, eles definiram a Forma Normal de Boyce-Codd. Até agora, seis Formas Normais são definidas teoricamente, mas na maioria das aplicações práticas, normalmente estendemos a Normalização até a Terceira Forma Normal. Cada forma normal se esforça para evitar anomalias durante a modificação de dados, reduzir a redundância e a dependência dos dados em uma tabela. Cada nível de normalização tende a introduzir mais tabelas, reduzir a redundância, aumentar a simplicidade de cada tabela, mas também aumenta a complexidade de todo o sistema de gerenciamento de banco de dados relacional. Portanto, os sistemas RDBM estruturalmente tendem a ser mais complexos do que os sistemas hierárquicos.
Por que a normalização do banco de dados:quatro anomalias
O armazenamento de dados sem normalização causa vários problemas com o consumo de dados. Os proponentes da normalização chamaram tais problemas de anomalias. Para descrever essas anomalias, vejamos os dados apresentados na Fig. 1.

Fig. 1 mesa de funcionários
Lista 1. Tabela Básica para Demonstrar a Normalização do Banco de Dados.
1.1. Criar a tabela
use privatework go create table staffers ( staffID int identity (1,1) ,StaffName varchar(50) ,Role varchar(50) ,Department varchar (100) ,Manager varchar (50) ,Gender char(1) ,DateofBirth datetime2 )
1.2. Inserir linhas
insert into staffers values ('John Doe','Engineering','Kweku Amarh','M','06-Oct-1965');
insert into staffers values ('Henry Ofori','Engineering','Kweku Amarh','M','06-Mar-1982');
insert into staffers values ('Jessica Yuiah','Engineering','Kweku Amarh','F','06-Oct-1965');
insert into staffers values ('Ahmed Assah','Engineering','Kweku Amarh','M','06-Oct-1965'); 1.3. Consultar a Tabela
select * from staffers;
Esta tabela representa basicamente dois conjuntos de dados que foram combinados inadvertidamente:nomes de funcionários e departamentos. Observe que todos os funcionários são do mesmo departamento:Engenharia. Isso foi feito por simplicidade e para demonstrar a normalização. Existem três problemas principais associados à manipulação dessa estrutura:
A anomalia de inserção
Para inserir um novo registro, temos que ficar repetindo os nomes dos departamentos e gerentes.
A anomalia de exclusão
Para excluir o registro de um funcionário, também devemos excluir o gerente e o departamento associados. Se houver necessidade de remover os registros de TODOS os funcionários, também devemos remover todos os departamentos e todos os gerentes.
A anomalia de atualização
Se houver necessidade de mudar o gerente de algum departamento, devemos fazer a mudança em cada linha desta tabela, pois os valores são duplicados para cada funcionário.
Formas normais do banco de dados
Nas seções seguintes do artigo, tentaremos descrever a 1ª, a 2ª e a 3ª Formas Normais que são muito mais prováveis de serem observadas em Sistemas RDBM reais. Existem outras extensões da teoria, como a Quarta, a Quinta e as Formas Normais de Boyce-Codd, mas neste artigo nos limitaremos às Três Formas Normais.
A primeira forma normal
A 1ª Forma Normal é definida por quatro regras:
Cada coluna deve conter valores do mesmo tipo de dados.
A tabela Staffers já atende a essa regra.
Cada coluna em uma tabela deve ser atômica.
Isso significa essencialmente que você deve dividir o conteúdo de uma coluna até que eles não possam mais ser divididos. Observe que a Função coluna na coluna Funcionários tabela quebra a regra 2 para a linha com StaffID=3.
Cada linha em uma tabela deve ser exclusiva.
Singularidade em tabelas normalizadas é normalmente alcançada usando Chaves Primárias. Uma chave primária define exclusivamente cada linha em uma tabela. Na maioria das vezes, uma Chave Primária é definida por apenas uma coluna. Uma chave primária composta por mais de uma coluna é chamada de chave composta.
A ordem em que os registros são armazenados não importa.
Para alinhar os dados nos Staffers tabela com os princípios da Primeira Forma Normal, precisamos dividir a tabela conforme mostrado nas Figuras 2, 3 e 4.
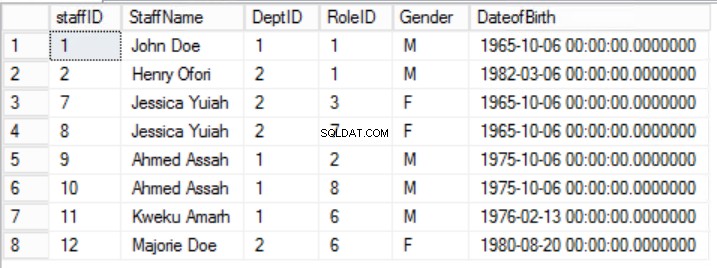
Fig. Mesa de 2 funcionários
Restringimos os dados nos Funcionários table e implementou uma chave primária composta para garantir a exclusividade. Também criamos duas tabelas adicionais Funções e Departamentos que têm relacionamentos com os Funcionários principais tabela implementada usando Chaves Estrangeiras. Revise o DDL na Listagem 2.
Listagem 2. DDL de Novos Funcionários Tabela para a Primeira Forma Normal.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID] [int] NOT NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC, [RoleID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([RoleID]) REFERENCES [dbo].[Roles] ([RoleID]) GO
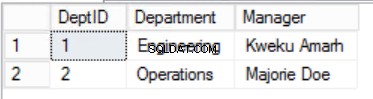
Fig. Tabela de 3 Departamentos
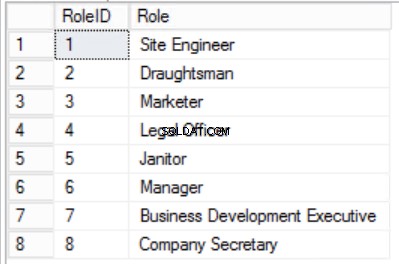
Fig. Tabela de 4 funções
A segunda forma normal
O 1º formulário Normal já deve estar em vigor.
Toda coluna não chave não deve ter Dependência Parcial da Chave Primária.
O objetivo da segunda regra é que todas as colunas da tabela devem depender de todas as colunas que compõem a Chave Primária juntas. Olhando para as tabelas nas Figuras 2, 3 e 4, descobrimos que cumprimos todos os requisitos da Primeira Forma Normal. Também atingimos os requisitos da Segunda Forma Normal para duas tabelas Funções e Departamentos . No entanto, no caso dos Funcionários mesa, ainda temos um problema. Nossa Chave Primária é composta pelas colunas StaffID e RoleID.
A regra 2 da Segunda Forma Normal é quebrada aqui pelo fato de que o Gênero e a Data de Nascimento dos funcionários não dependem do RoleID. Existe uma Dependência Parcial.
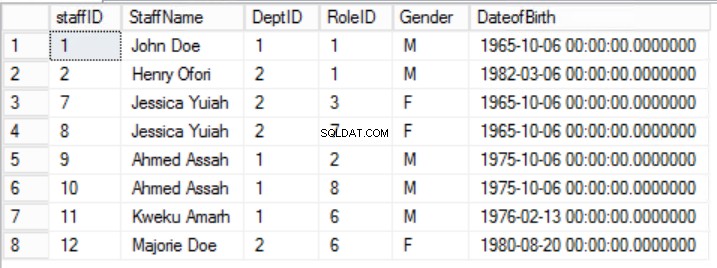
Fig. 5 funcionários para a primeira forma normal
No exemplo dado, podemos tentar corrigir isso removendo RoleID da Chave Primária, mas se fizermos isso, quebraremos outra regra:o papel de exclusividade declarado na Primeira Forma Normal. Devemos adotar outra abordagem. Modificaremos os Funcionários mesa com o entendimento de que um funcionário pode desempenhar mais de um papel. Veja a Fig. 6.
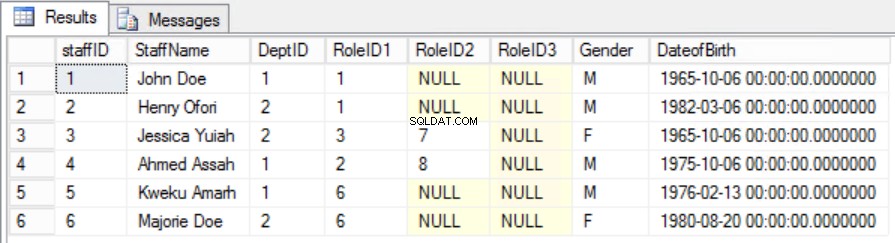
Fig. Tabela de 6 funcionários para a segunda forma normal
Conseguimos manter a exclusividade, bem como remover a dependência parcial.
Listagem 3. Tabela DDL de Novos Funcionários para a Segunda Forma Normal.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers2NF]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID1] [int] NOT NULL, [RoleID2] [int] NULL, [RoleID3] [int] NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID1]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID2]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID3]) REFERENCES [dbo].[Roles] ([RoleID]) GO
A Terceira Forma Normal
A 2ª forma Normal já deve estar em vigor.
Toda coluna não chave não deve ter Dependência Transitiva na Chave Primária.
O objetivo da terceira forma normal é que não deve haver colunas que dependam de colunas não-chave, mesmo que essas colunas não-chave já dependam da chave primária.
Como exemplo, suponha que decidimos adicionar uma coluna adicional aos Funcionários tabela conforme mostrado na Fig. 7 para ver claramente o gerente do funcionário. Fazendo isso, teríamos quebrado a segunda regra da Terceira Forma Normal, porque o Nome do Gerente depende do DeptID e o DeptID, por sua vez, depende do StaffID. Esta é uma Dependência Transitiva.
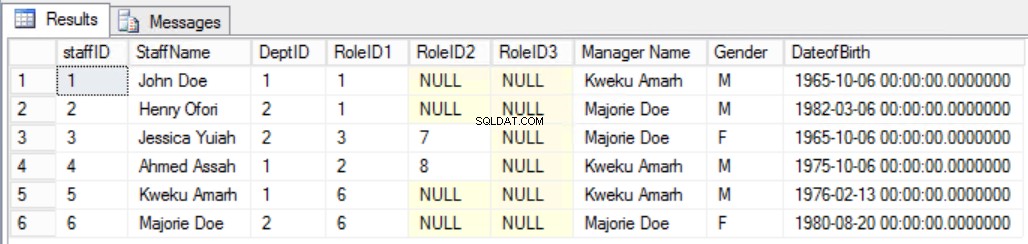
Fig. Tabela de 7 funcionários para a terceira forma normal (regra quebrada)
Seria melhor manter o formulário antigo e exibir as informações necessárias usando uma junção entre a tabela Staffers e a tabela Department.
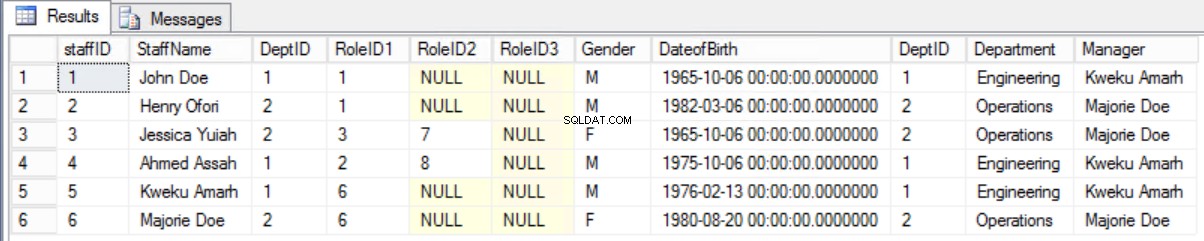
Fig. 8 União entre equipe e departamento
Listagem 4. Consulta para exibir funcionários e gerentes.
select * from staffers2NF s join Department d on s.DeptID=d.DeptID;
Aplicação prática
A maioria dos aplicativos maduros implementam as regras de normalização em níveis razoáveis. Vemos que a implementação da normalização de dados dá origem ao uso de Restrições de Chave Primária e Restrições de Chave Estrangeira. Além disso, questões como a indexação de Chaves Estrangeiras também aparecem à medida que nos aprofundamos no assunto. Anteriormente, mencionamos como a falta de normalização pode afetar a manipulação suave de dados, conforme descrito em Anomalias de inserção, exclusão e atualização. A falta de normalização adequada também pode afetar indiretamente o desempenho da consulta.
Recentemente me deparei com uma tabela que tinha o formato mostrado na tabela 1 que chamaremos Customer_Accounts.
S/Não | Nome | Account_No | Telefone_Nº |
1 | Kenneth Igiri | 9922344592 | 2348039988456, 2348039988456, 2348039988456 |
2 | Ernest Doe | 6677554897 | 2348022887546, 2348039988456 |
Tabela 1 Customer_Accounts
O principal problema com esta tabela é que ela quebra a segunda regra da Primeira Forma Normal. O resultado em nosso caso foi que a busca de clientes com base em seus números de telefone exigia o uso de um LIKE na cláusula WHERE e um %.
Select account_no from Customer_Accounts where Phone_No like ‘%2348039988456%’;
O impacto da construção acima foi que o otimizador nunca usou um índice que era um grande problema de desempenho.
Conclusão
A normalização de dados está no domínio do design de banco de dados e tanto os desenvolvedores quanto os DBAs devem prestar atenção às regras descritas neste artigo. É sempre melhor fazer a normalização antes que o banco de dados entre em produção. Os benefícios de um Sistema de Gerenciamento de Banco de Dados Relacional adequadamente projetado simplesmente valem o esforço.