No mês passado postei um desafio para criar um gerador de séries numéricas eficiente. As respostas foram esmagadoras. Houve muitas ideias e sugestões brilhantes, com muitas aplicações muito além deste desafio específico. Isso me fez perceber como é bom fazer parte de uma comunidade e que coisas incríveis podem ser alcançadas quando um grupo de pessoas inteligentes une forças. Obrigado Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason e John Number2 por compartilhar suas ideias e comentários.
Inicialmente pensei em escrever apenas um artigo para resumir as ideias que as pessoas enviaram, mas eram muitas. Então vou dividir a cobertura em vários artigos. Este mês, vou me concentrar principalmente nas melhorias sugeridas por Charlie e Alan Burstein para as duas soluções originais que publiquei no mês passado na forma de TVFs inline chamadas dbo.GetNumsItzikBatch e dbo.GetNumsItzik. Vou nomear as versões melhoradas dbo.GetNumsAlanCharlieItzikBatch e dbo.GetNumsAlanCharlieItzik, respectivamente.
Isso é tão emocionante!
Soluções originais da Itzik
Como um lembrete rápido, as funções que abordei no mês passado usam um CTE básico que define um construtor de valor de tabela com 16 linhas. As funções usam uma série de CTEs em cascata, cada uma aplicando um produto (cross join) de duas instâncias de sua CTE anterior. Dessa forma, com cinco CTEs além da base, você pode obter um conjunto de até 4.294.967.296 linhas. Um CTE chamado Nums usa a função ROW_NUMBER para produzir uma série de números começando com 1. Finalmente, a consulta externa calcula os números no intervalo solicitado entre as entradas @low e @high.
A função dbo.GetNumsItzikBatch usa uma junção fictícia a uma tabela com um índice columnstore para obter o processamento em lote. Aqui está o código para criar a tabela fictícia:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
E aqui está o código que define a função dbo.GetNumsItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Usei o seguinte código para testar a função com "Descartar resultados após execução" habilitado no SSMS:
SELECT n FROM dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Aqui estão as estatísticas de desempenho que obtive para esta execução:
CPU time = 16985 ms, elapsed time = 18348 ms.
A função dbo.GetNumsItzik é semelhante, só que não possui uma junção fictícia e normalmente obtém processamento de modo de linha em todo o plano. Aqui está a definição da função:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; Aqui está o código que usei para testar a função:
SELECT n FROM dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Aqui estão as estatísticas de desempenho que obtive para esta execução:
CPU time = 19969 ms, elapsed time = 21229 ms.
Melhorias de Alan Burstein e Charlie
Alan e Charlie sugeriram várias melhorias em minhas funções, algumas com implicações de desempenho moderadas e outras mais dramáticas. Vou começar com as descobertas de Charlie sobre sobrecarga de compilação e dobras constantes. Em seguida, abordarei as sugestões de Alan, incluindo sequências baseadas em 1 versus sequências baseadas em @low (também compartilhadas por Charlie e Jeff Moden), evitando classificação desnecessária e computando um intervalo de números na ordem oposta.
Descobertas do tempo de compilação
Como Charlie observou, um gerador de séries numéricas é frequentemente usado para gerar séries com números muito pequenos de linhas. Nesses casos, o tempo de compilação do código pode se tornar uma parte substancial do tempo total de processamento da consulta. Isso é especialmente importante ao usar iTVFs, pois, diferentemente dos procedimentos armazenados, não é o código de consulta parametrizado que é otimizado, mas o código de consulta após a incorporação do parâmetro. Em outras palavras, os parâmetros são substituídos pelos valores de entrada antes da otimização e o código com as constantes é otimizado. Este processo pode ter implicações negativas e positivas. Uma das implicações negativas é que você obtém mais compilações à medida que a função é chamada com diferentes valores de entrada. Por esta razão, os tempos de compilação definitivamente devem ser levados em consideração - especialmente ao usar a função com muita frequência com pequenos intervalos.
Aqui estão os tempos de compilação que Charlie encontrou para as várias cardinalidades CTE básicas:
2: 22ms 4: 9ms 16: 7ms 256: 35ms
É curioso ver que entre estes, 16 é o ideal, e que há um salto muito dramático quando você sobe para o próximo nível, que é 256. Lembre-se de que as funções dbo.GetNumsItzikBacth e dbo.GetNumsItzik usam cardinalidade CTE de base de 16 .
Dobragem constante
A dobragem constante é muitas vezes uma implicação positiva que, nas condições certas, pode ser ativada graças ao processo de incorporação de parâmetros que um iTVF experimenta. Por exemplo, suponha que sua função tenha uma expressão @x + 1, onde @x é um parâmetro de entrada da função. Você invoca a função com @x =5 como entrada. A expressão embutida então se torna 5 + 1, e se for elegível para dobra constante (mais sobre isso em breve), então se torna 6. Se essa expressão for parte de uma expressão mais elaborada envolvendo colunas e for aplicada a muitos milhões de linhas, isso pode resultar em economias não negligenciáveis em ciclos de CPU.
A parte complicada é que o SQL Server é muito exigente sobre o que dobrar constantemente e o que não dobrar constantemente. Por exemplo, o SQL Server não constante fold col1 + 5 + 1, nem dobrará 5 + col1 + 1. Mas dobrará 5 + 1 + col1 para 6 + col1. Eu sei. Assim, por exemplo, se sua função retornou SELECT @x + col1 + 1 AS mycol1 FROM dbo.T1, você pode habilitar a dobra constante com a seguinte pequena alteração:SELECT @x + 1 + col1 AS mycol1 FROM dbo.T1. Não acredite em mim? Examine os planos para as três consultas a seguir no banco de dados PerformanceV5 (ou consultas semelhantes com seus dados) e veja por si mesmo:
SELECT orderid + 5 + 1 AS myorderid FROM dbo.orders; SELECT 5 + orderid + 1 AS myorderid FROM dbo.orders; SELECT 5 + 1 + orderid AS myorderid FROM dbo.orders;
Eu obtive as três expressões a seguir nos operadores Compute Scalar para essas três consultas, respectivamente:
[Expr1003] = Scalar Operator([PerformanceV5].[dbo].[Orders].[orderid]+(5)+(1)) [Expr1003] = Scalar Operator((5)+[PerformanceV5].[dbo].[Orders].[orderid]+(1)) [Expr1003] = Scalar Operator((6)+[PerformanceV5].[dbo].[Orders].[orderid])
Veja onde estou indo com isso? Nas minhas funções usei a seguinte expressão para definir a coluna de resultado n:
@low + rownum - 1 AS n
Charlie percebeu que, com a seguinte pequena alteração, ele pode permitir o dobramento constante:
@low - 1 + rownum AS n
Por exemplo, o plano para a consulta anterior que forneci em relação a dbo.GetNumsItzik, com @low =1, originalmente tinha a seguinte expressão definida pelo operador Compute Scalar:
[Expr1154] = Scalar Operator((1)+[Expr1153]-(1))
Após a aplicação da pequena alteração acima, a expressão no plano passa a ser:
[Expr1154] = Scalar Operator((0)+[Expr1153])
Isso é brilhante!
Quanto às implicações de desempenho, lembre-se de que as estatísticas de desempenho que obtive para a consulta em dbo.GetNumsItzikBatch antes da alteração foram as seguintes:
CPU time = 16985 ms, elapsed time = 18348 ms.
Aqui estão os números que recebi após a mudança:
CPU time = 16375 ms, elapsed time = 17932 ms.
Aqui estão os números que obtive para a consulta em dbo.GetNumsItzik originalmente:
CPU time = 19969 ms, elapsed time = 21229 ms.
E aqui estão os números após a mudança:
CPU time = 19266 ms, elapsed time = 20588 ms.
O desempenho melhorou um pouco em alguns por cento. Mas espere, tem mais! Se você precisar processar os dados ordenados, as implicações de desempenho podem ser muito mais dramáticas, como falarei mais adiante na seção sobre pedidos.
Sequência baseada em 1 versus sequência baseada em @low e números de linha opostos
Alan, Charlie e Jeff observaram que na grande maioria dos casos da vida real em que você precisa de um intervalo de números, você precisa começar com 1, ou às vezes 0. É muito menos comum precisar de um ponto de partida diferente. Portanto, pode fazer mais sentido que a função sempre retorne um intervalo que comece com, digamos, 1 e, quando você precisar de um ponto de partida diferente, aplique quaisquer cálculos externamente na consulta na função.
Alan, na verdade, teve uma ideia elegante de fazer com que o TVF em linha retornasse uma coluna que começa com 1 (simplesmente o resultado direto da função ROW_NUMBER) com alias de rn e uma coluna que começa com @low com alias de n. Como a função fica embutida, quando a consulta externa interage apenas com a coluna rn, a coluna n nem é avaliada e você obtém o benefício de desempenho. Quando você precisa que a sequência comece com @low, você interage com a coluna n e paga o custo extra aplicável, então não há necessidade de adicionar nenhum cálculo externo explícito. Alan até sugeriu adicionar uma coluna chamada op que calcula os números em ordem oposta, e interage com ela apenas quando necessário para tal sequência. A coluna op é baseada no cálculo:@high + 1 – rownum. Esta coluna tem importância quando você precisa processar as linhas em ordem de número decrescente, como demonstro posteriormente na seção de ordenação.
Então, vamos aplicar as melhorias de Charlie e Alan às minhas funções.
Para a versão do modo de lote, certifique-se de criar a tabela fictícia com o índice columnstore primeiro, se ainda não estiver presente:
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Em seguida, use a seguinte definição para a função dbo.GetNumsAlanCharlieItzikBatch:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum; Aqui está um exemplo para usar a função:
SELECT * FROM dbo.GetNumsAlanCharlieItzikBatch(-2, 3) AS F ORDER BY rn;
Este código gera a seguinte saída:
rn op n --- --- --- 1 3 -2 2 2 -1 3 1 0 4 0 1 5 -1 2 6 -2 3
Em seguida, teste o desempenho da função com 100 milhões de linhas, retornando primeiro a coluna n:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Aqui estão as estatísticas de desempenho que obtive para esta execução:
CPU time = 16375 ms, elapsed time = 17932 ms.
Como você pode ver, há uma pequena melhoria em comparação com dbo.GetNumsItzikBatch tanto na CPU quanto no tempo decorrido, graças à dobra constante que ocorreu aqui.
Teste a função, só que desta vez retornando a coluna rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Aqui estão as estatísticas de desempenho que obtive para esta execução:
CPU time = 15890 ms, elapsed time = 18561 ms.
O tempo de CPU reduziu ainda mais, embora o tempo decorrido pareça ter aumentado um pouco nesta execução em comparação com a consulta da coluna n.
A Figura 1 tem os planos para ambas as consultas.
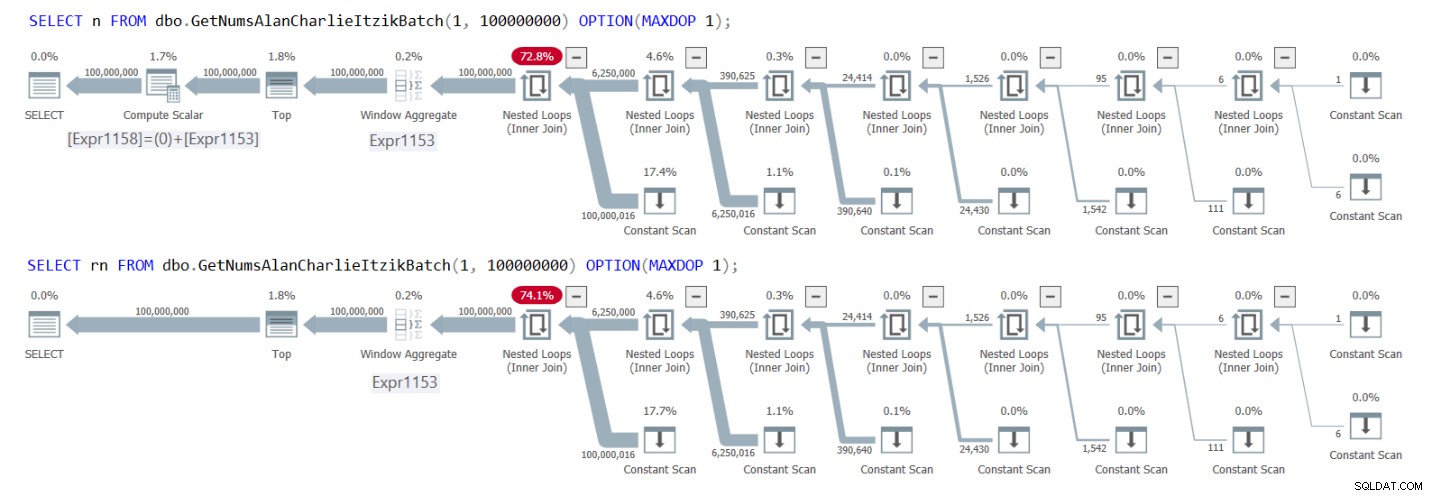 Figura 1:Planos para GetNumsAlanCharlieItzikBatch retornando n versus rn
Figura 1:Planos para GetNumsAlanCharlieItzikBatch retornando n versus rn Você pode ver claramente nos planos que ao interagir com a coluna rn, não há necessidade do operador Compute Scalar extra. Observe também no primeiro plano o resultado da atividade de dobra constante que descrevi anteriormente, onde @low – 1 + rownum foi alinhado a 1 – 1 + rownum e depois dobrado em 0 + rownum.
Aqui está a definição da versão em modo de linha da função chamada dbo.GetNumsAlanCharlieItzik:
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzik(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum; Use o código a seguir para testar a função, primeiro consultando a coluna n:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Aqui estão as estatísticas de desempenho que obtive:
CPU time = 19047 ms, elapsed time = 20121 ms.
Como você pode ver, é um pouco mais rápido que dbo.GetNumsItzik.
Em seguida, consulte a coluna rn:
SELECT rn FROM dbo.GetNumsAlanCharlieItzik(1, 100000000) OPTION(MAXDOP 1);
Os números de desempenho melhoram ainda mais na CPU e nas frentes de tempo decorrido:
CPU time = 17656 ms, elapsed time = 18990 ms.
Considerações sobre pedidos
As melhorias mencionadas são certamente interessantes, e o impacto no desempenho não é desprezível, mas não muito significativo. Um impacto de desempenho muito mais dramático e profundo pode ser observado quando você precisa processar os dados ordenados pela coluna numérica. Isso pode ser tão simples quanto a necessidade de retornar as linhas ordenadas, mas é igualmente relevante para qualquer necessidade de processamento baseado em ordem, por exemplo, um operador Stream Aggregate para agrupamento e agregação, um algoritmo Merge Join para junção e assim por diante.
Ao consultar dbo.GetNumsItzikBatch ou dbo.GetNumsItzik e ordenar por n, o otimizador não percebe que a expressão de ordenação subjacente @low + rownum – 1 é preservação de ordem em relação ao rownum. A implicação é um pouco semelhante à de uma expressão de filtragem não SARGable, apenas com uma expressão de ordenação isso resulta em um operador Sort explícito no plano. A classificação extra afeta o tempo de resposta. Também afeta o dimensionamento, que normalmente se torna n log n em vez de n.
Para demonstrar isso, consulte dbo.GetNumsItzikBatch, solicitando a coluna n, ordenada por n:
SELECT n FROM dbo.GetNumsItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Eu tenho as seguintes estatísticas de desempenho:
CPU time = 34125 ms, elapsed time = 39656 ms.
O tempo de execução mais que dobra em comparação com o teste sem a cláusula ORDER BY.
Teste a função dbo.GetNumsItzik de maneira semelhante:
SELECT n FROM dbo.GetNumsItzik(1,100000000) ORDER BY n OPTION(MAXDOP 1);
Eu obtive os seguintes números para este teste:
CPU time = 52391 ms, elapsed time = 55175 ms.
Também aqui o tempo de execução mais que dobra em comparação com o teste sem a cláusula ORDER BY.
A Figura 2 tem os planos para ambas as consultas.
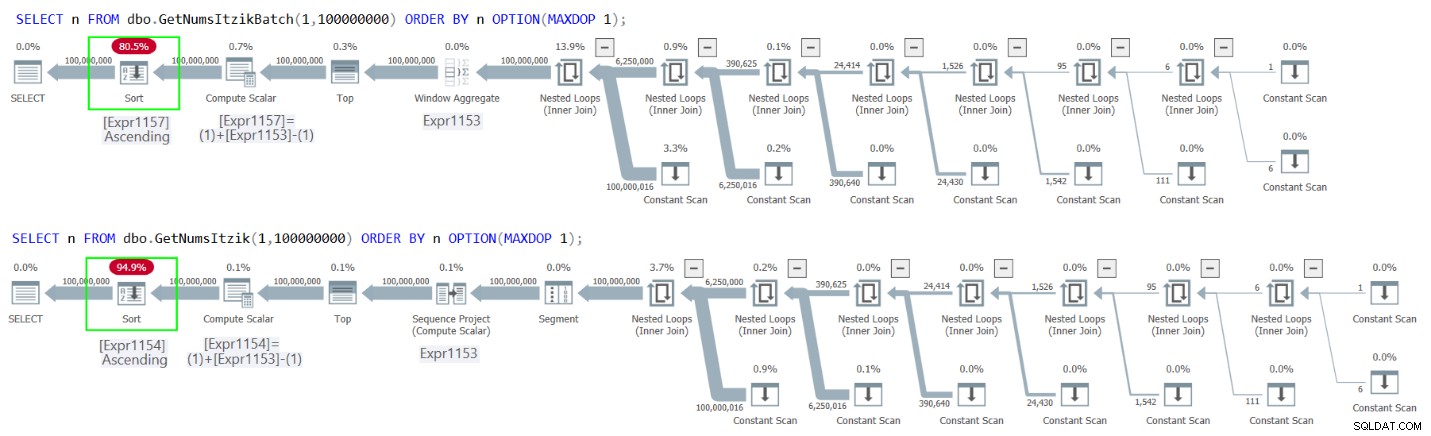 Figura 2:planos para GetNumsItzikBatch e GetNumsItzik ordenação por n
Figura 2:planos para GetNumsItzikBatch e GetNumsItzik ordenação por n Em ambos os casos, você pode ver o operador Sort explícito nos planos.
Ao consultar dbo.GetNumsAlanCharlieItzikBatch ou dbo.GetNumsAlanCharlieItzik e ordenar por rn, o otimizador não precisa adicionar um operador Sort ao plano. Então você pode retornar n, mas ordenar por rn, e assim evitar uma classificação. O que é um pouco chocante, porém - e eu quero dizer no bom sentido - é que a versão revisada de n, que sofre dobras constantes, preserva a ordem! É fácil para o otimizador perceber que 0 + rownum é uma expressão de preservação de ordem em relação a rownum e, assim, evitar uma classificação.
Tente. Consulte dbo.GetNumsAlanCharlieItzikBatch, retornando n e ordenando por n ou rn, assim:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Obtive os seguintes números de desempenho:
CPU time = 16500 ms, elapsed time = 17684 ms.
Isso se deve, obviamente, ao fato de não haver necessidade de um operador Sort no plano.
Execute um teste semelhante em dbo.GetNumsAlanCharlieItzik:
SELECT n FROM dbo.GetNumsAlanCharlieItzik(1,100000000) ORDER BY n -- same with rn OPTION(MAXDOP 1);
Recebi os seguintes números:
CPU time = 19546 ms, elapsed time = 20803 ms.
A Figura 3 tem os planos para ambas as consultas:
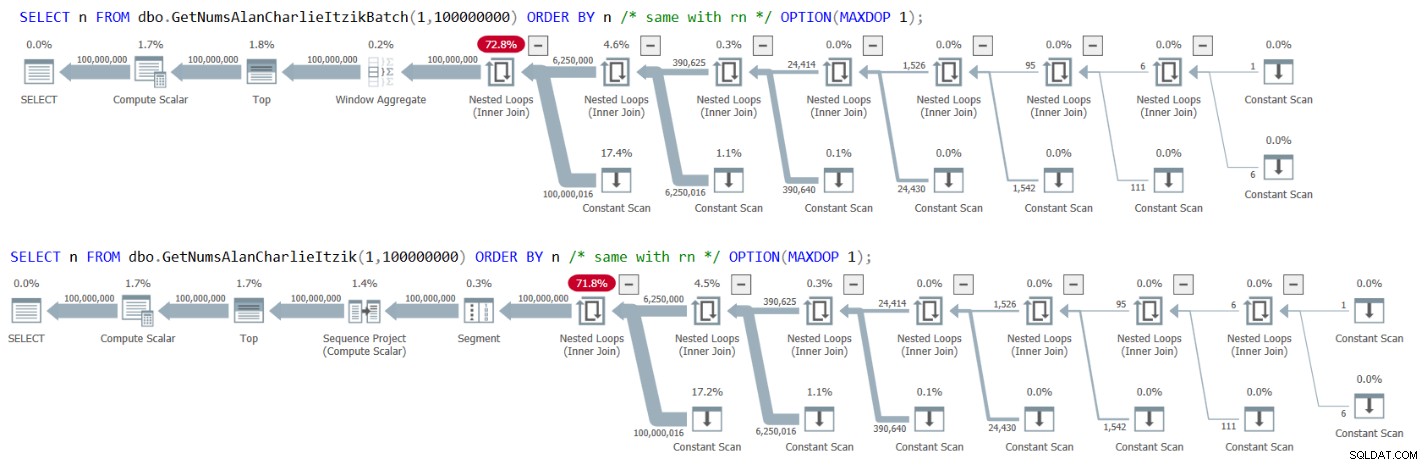
Figura 3:Planos para GetNumsAlanCharlieItzikBatch e GetNumsAlanCharlieItzik ordenando por n ou rn
Observe que não há operador Sort nos planos.
Dá vontade de cantar...
All you need is constant folding All you need is constant folding All you need is constant folding, constant folding Constant folding is all you need
Obrigado Charlie!
Mas e se você precisar devolver ou processar os números em ordem decrescente? A tentativa óbvia é usar ORDER BY n DESC, ou ORDER BY rn DESC, assim:
SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n DESC OPTION(MAXDOP 1); SELECT n FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY rn DESC OPTION(MAXDOP 1);
Infelizmente, porém, ambos os casos resultam em uma classificação explícita nos planos, conforme mostrado na Figura 4.
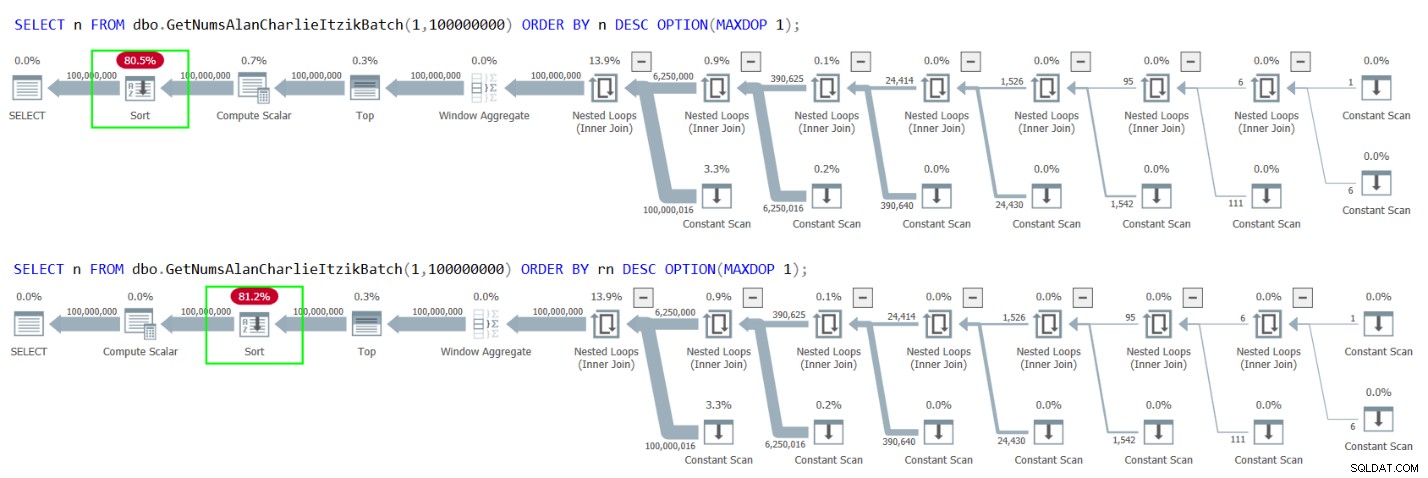 Figura 4:Planos para GetNumsAlanCharlieItzikBatch ordenação por n ou rn decrescente
Figura 4:Planos para GetNumsAlanCharlieItzikBatch ordenação por n ou rn decrescente É aqui que o truque inteligente de Alan com o op de coluna se torna um salva-vidas. Retorne a coluna op enquanto ordena por n ou rn, assim:
SELECT op FROM dbo.GetNumsAlanCharlieItzikBatch(1,100000000) ORDER BY n OPTION(MAXDOP 1);
O plano para esta consulta é mostrado na Figura 5.
 Figura 5:Plano para GetNumsAlanCharlieItzikBatch retornando op e ordenando por n ou rn crescente
Figura 5:Plano para GetNumsAlanCharlieItzikBatch retornando op e ordenando por n ou rn crescente Você obtém os dados de volta ordenados por n decrescente e não há necessidade de uma classificação no plano.
Obrigado Allan!
Resumo do desempenho
Então, o que aprendemos com tudo isso?
Os tempos de compilação podem ser um fator, especialmente ao usar a função frequentemente com pequenos intervalos. Em uma escala logarítmica com base 2, o doce 16 parece ser um bom número mágico.
Entenda as peculiaridades da dobragem constante e use-as a seu favor. Quando um iTVF tem expressões que envolvem parâmetros, constantes e colunas, coloque os parâmetros e constantes na parte inicial da expressão. Isso aumentará a probabilidade de dobra, reduzirá a sobrecarga da CPU e aumentará a probabilidade de preservação do pedido.
Não há problema em ter várias colunas que são usadas para diferentes propósitos em um iTVF e consultar as relevantes em cada caso sem se preocupar em pagar pelas que não são referenciadas.
Quando você precisar que a sequência numérica seja retornada em ordem oposta, use a coluna n ou rn original na cláusula ORDER BY com ordem crescente e retorne a coluna op, que calcula os números em ordem inversa.
A Figura 6 resume os números de desempenho que obtive nos vários testes.
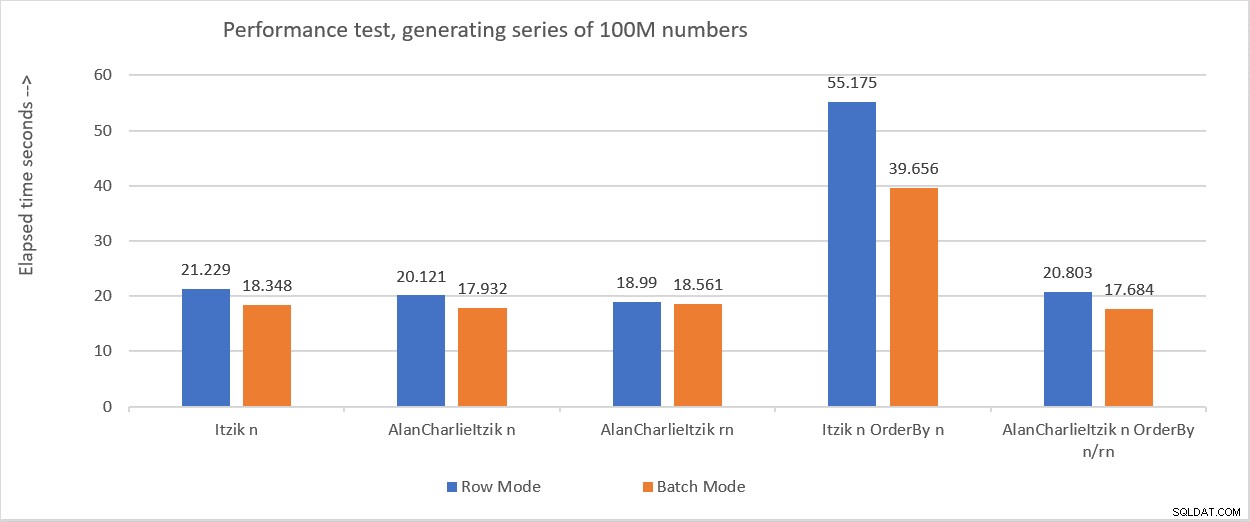 Figura 6:Resumo de desempenho
Figura 6:Resumo de desempenho No próximo mês, continuarei explorando ideias, insights e soluções adicionais para o desafio do gerador de séries numéricas.



