Já escrevi anteriormente sobre os benefícios de usar
NOEXPAND dicas, mesmo na Enterprise Edition. Os detalhes estão todos no artigo vinculado, mas para resumir brevemente:- O SQL Server só criará automaticamente estatísticas em uma visualização indexada quando um
NOEXPANDdica de tabela é usada. Omitir essa dica pode levar a avisos do plano de execução sobre estatísticas ausentes que não podem ser resolvidas com a criação manual de estatísticas. - O SQL Server só usará estatísticas de visualização criadas automaticamente ou manualmente em cálculos de estimativa de cardinalidade quando a consulta faz referência à visualização diretamente e um
NOEXPANDdica é usada. Para todas as definições de exibição, exceto as mais triviais, isso significa que a qualidade das estimativas de cardinalidade provavelmente será menor quando essa dica não for usada, geralmente resultando em planos de execução menos ideais. - A falta ou incapacidade de usar estatísticas de visualização pode fazer com que o otimizador adivinhe as estimativas de cardinalidade, mesmo quando as estatísticas da tabela base estiverem disponíveis. Isso pode acontecer quando parte do plano de consulta é substituída por uma referência de visualização indexada pelo recurso de correspondência automática de visualização, mas as estatísticas de visualização não estão disponíveis, conforme descrito acima.
Há outra consequência de não usar o
NOEXPAND dica, que mencionei de passagem alguns anos atrás em meu artigo, Limitações do otimizador com índices filtrados:
ONOEXPANDas dicas são necessárias mesmo na Enterprise Edition para garantir que a garantia de exclusividade fornecida pelos índices de exibição seja usada pelo otimizador.
Este artigo examina essa afirmação e suas implicações com mais detalhes.
Configuração de demonstração
O script a seguir cria uma tabela simples e uma exibição indexada:
CREATE TABLE dbo.T
(
col1 integer NOT NULL
);
GO
INSERT dbo.T WITH (TABLOCKX)
(col1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.type = N'P';
GO
CREATE VIEW dbo.VT
WITH SCHEMABINDING
AS
SELECT T.col1
FROM dbo.T AS T;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.VT (col1); Isso cria uma tabela de heap de coluna única e uma exibição irrestrita da mesma tabela com um índice clusterizado exclusivo. Isso não se destina a ser um caso de uso realista para uma exibição indexada; mas ajudará a ilustrar os pontos-chave com o mínimo de distrações. O ponto importante é que a tabela base aqui não tem nenhum índice (nem mesmo um índice clusterizado), mas a visão tem, e esse índice é único.
A consulta de exemplo
Considere a seguinte consulta simples na tabela base:
SELECT DISTINCT
T.col1
FROM dbo.T AS T; O plano de execução que você verá para essa consulta depende da edição do SQL Server em uso. Se não for Enterprise Edition (ou equivalente), você verá um plano como este:

O otimizador de consulta do SQL Server optou por verificar a tabela base e aplicar a distinção especificada usando um operador Distinct Sort. Essa forma de plano é totalmente esperada, pois a correspondência de exibição indexada automática não está disponível fora do Enterprise Edition. Vou parar de dizer "Enterprise Edition ou equivalente" a partir de agora, mas continue inferindo que me refiro a qualquer edição que suporte a correspondência automática de exibição quando digo "Enterprise Edition" de agora em diante.
A dica EXPANDIR VISUALIZAÇÕES
Isso é um pouco a parte, mas para obter o mesmo plano na Enterprise Edition, precisamos usar um
EXPAND VIEWS dica de consulta:SELECT DISTINCT
T.col1
FROM dbo.T AS T
OPTION (EXPAND VIEWS); Pode parecer um pouco estranho usar esta dica quando não há nenhuma referência de visualização na consulta, mas é assim que funciona. As
EXPAND VIEWS A dica especifica efetivamente que a correspondência de exibição indexada deve ser desabilitada durante a compilação e otimização da consulta. Para ser claro:sem essa dica, a Enterprise Edition pode corresponder (partes de) a consulta a uma ou mais exibições indexadas. Com a correspondência de visualização automática ativada
Sem um
EXPAND VIEWS dica, compilar a mesma consulta no Developer Edition (por exemplo) produz um plano diferente: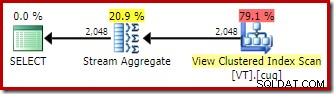
A aplicação de correspondência de exibição indexada significa que o plano de execução apresenta uma varredura do índice clusterizado de exibição em vez de uma varredura de tabela base.
O mesmo plano é produzido neste caso se a consulta referenciar a visão diretamente (em vez da tabela base):
SELECT DISTINCT
V.col1
FROM dbo.VT AS V; Em todas as edições, a referência de visualização é expandida antes do início da otimização da consulta. Em edições equivalentes ao Enterprise, o formulário expandido pode ser correspondido à exibição posteriormente. Esse é um conceito-chave a ser entendido ao pensar em como o compilador e o otimizador de consulta usam exibições indexadas no SQL Server.
O agregado de stream
A diferença mais interessante entre os dois planos que vimos até agora é o Stream Aggregate no plano de correspondência de visualização. Se você observar os custos estimados dos operadores Table Scan e View Scan, verá que eles são exatamente os mesmos. O otimizador não decidiu usar a visualização indexada porque tornava o acesso aos dados mais barato. Em vez disso, escanear o índice de visualização permite que o
DISTINCT requisito para ser implementado como um Stream Aggregate, em vez de um Hash Aggregate ou Distinct Sort (como no primeiro plano). Um Stream Aggregate requer entrada ordenada pela(s) coluna(s) de agrupamento. Nesse caso, o distinto é equivalente ao agrupamento por coluna única, e o índice clusterizado exclusivo da exibição fornece a garantia de ordenação necessária. O modelo de custo do otimizador identifica o Stream Aggregate como uma opção mais barata do que um Distinct Sort ou Hash Aggregate para essa consulta. Essa é a base para o otimizador optar por acessar a exibição indexada quando a correspondência automática de exibição estiver disponível.
Com tudo isso dito e entendido, o Stream Aggregate ainda é inesperado:Dada a garantia de exclusividade fornecida pelo índice de exibição, não há necessidade de realizar essa operação de agrupamento. O único índice clusterizado já garante que a coluna não contém duplicatas.
Este, em poucas palavras, é o problema. Quando a correspondência automática de exibição é usada, o otimizador reconhece a garantia de ordenação fornecida pelo índice de exibição, mas não a garantia de exclusividade.
Usando uma dica NOEXPAND
Para obter o plano de execução ideal para esta consulta, precisamos referenciar a visualização diretamente e usar um
NOEXPAND dica de mesa:SELECT DISTINCT
V.col1
FROM dbo.VT AS V WITH (NOEXPAND); Isso nos dá o plano que uma pessoa experiente em banco de dados esperaria; um que reconhece corretamente que a operação distinta é redundante e pode ser removida:
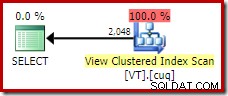
Um segundo exemplo
Deixar de aproveitar a garantia de exclusividade fornecida por um índice de exibição pode ter outros efeitos no plano de execução final. Considere agora uma autojunção da visão indexada (novamente, apenas para ilustrar um conceito – isso não pretende ser uma consulta realista):
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1; Usando o Developer Edition, o plano de execução escolhido não acessa a visualização indexada e apresenta uma junção de hash (às vezes uma indicação de que um índice útil está faltando):
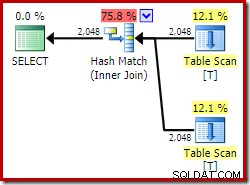
Agora vamos tentar exatamente a mesma consulta, mas com um
NOEXPAND dica em cada referência de visualização:SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1 WITH (NOEXPAND)
JOIN dbo.VT AS V2 WITH (NOEXPAND)
ON V2.col1 = V1.col1; O plano de execução agora apresenta dois acessos de visualização indexada e uma junção de mesclagem:
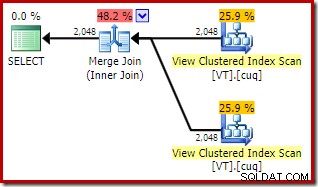
Este novo plano tem um custo estimado muito menor do que o plano hash join, então por que o otimizador não escolheu essa opção antes? Podemos ver por que adicionando uma dica de junção de mesclagem à consulta original:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1
OPTION (MERGE JOIN); Isso dá uma aparência semelhante plano que opta por acessar a visualização mesmo que
NOEXPAND não foi especificado: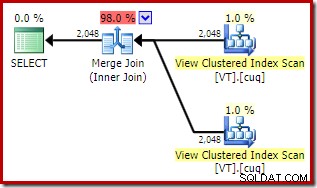
O custo total estimado deste plano é maior do que os dois exemplos anteriores. O Merge Join neste plano também representa uma proporção maior do custo total estimado do que antes (98% versus 48,2%).
A razão para isso pode ser vista observando as propriedades da junção de mesclagem. No
NOEXPAND plano, era uma junção de mesclagem de um para muitos. No plano diretamente acima, é uma junção de mesclagem de muitos para muitos. O modelo de custo do otimizador atribui um custo mais alto a junções de mesclagem muitos para muitos porque uma tabela de trabalho tempdb é necessária para lidar com quaisquer duplicatas. Conclusões
As garantias fornecidas por um índice exclusivo podem ser uma poderosa ferramenta de otimização, por isso é uma pena que a correspondência automática de índice não consiga tirar proveito disso. Os benefícios potenciais vão além de eliminar agregações desnecessárias ou habilitar uma junção de mesclagem de um para muitos, conforme visto nos exemplos simples anteriores. Em geral, pode ser difícil identificar que um plano de execução está abaixo do ideal porque o otimizador não tirou vantagem de uma garantia de exclusividade.
Essa limitação do otimizador não se aplica apenas ao índice clusterizado exclusivo que uma exibição deve ter para ser materializada. Em cenários mais complexos, índices não clusterizados adicionais também podem estar presentes na exibição; talvez para refletir relacionamentos entre tabelas que são difíceis de impor ou representar de outra forma. Se esses índices não clusterizados forem definidos como exclusivos, o otimizador também ignorará essas garantias, se a correspondência automática de índice for usada.
Adicionando isso às limitações em torno da criação e uso de informações estatísticas, parece que confiar na correspondência automática de visualizações pode resultar em planos de execução inferiores. A opção mais segura é provavelmente fazer referência a visualizações indexadas explicitamente e usar um
NOEXPAND dica sempre – pelo menos até que esses problemas sejam abordados no produto. Fatores atenuantes
Devo enfatizar que o problema descrito neste artigo se aplica apenas à garantia de exclusividade fornecida por um índice de exibição exclusivo. Se o otimizador puder obter as informações de exclusividade necessárias de outra maneira , as chances são boas de que problemas de otimização sejam evitados.
Por exemplo, pode haver um índice exclusivo adequado em uma tabela base referenciada pela exibição. Ou, no caso de uma visão que contém agregação, o otimizador já pode inferir uma garantia de exclusividade útil do
GROUP BY da visão cláusula. A prática comum de adicionar um índice clusterizado de exibição às chaves de agrupamento não adiciona informações extras de exclusividade nesse caso. No entanto, há momentos em que essa "supervisão de exclusividade" pode significar que você obterá planos de execução de melhor qualidade usando uma referência de visualização explícita e
NOEXPAND dicas, mesmo na Enterprise Edition.