[ Parte 1 | Parte 2 | Parte 3]
Na parte 1 desta série, experimentei algumas maneiras de compactar uma tabela de 1 TB. Embora tenha obtido resultados decentes em minha primeira tentativa, queria ver se poderia melhorar o desempenho na parte 2. Lá, descrevi algumas das coisas que achei que poderiam ser problemas de desempenho e expus como eu poderia particionar melhor a tabela de destino para compactação ideal de columnstore. Eu já:
- particionou a tabela em 8 partições (uma por núcleo);
- coloque o arquivo de dados de cada partição em seu próprio grupo de arquivos; e,
- defina a compactação de arquivo em todas as partições, exceto a "ativa".
Ainda preciso fazer com que cada agendador grave exclusivamente em sua própria partição.
Primeiro, preciso fazer alterações na tabela de lote que criei. Eu preciso de uma coluna para armazenar o número de linhas adicionadas por lote (uma espécie de verificação de sanidade de auto-auditoria) e horários de início/término para medir o progresso.
ALTER TABLE dbo.BatchQueue ADD RowsAdded int, StartTime datetime2, EndTime datetime2;
Em seguida, preciso criar uma tabela para fornecer afinidade – nunca queremos mais de um processo em execução em qualquer agendador, mesmo que isso signifique perder algum tempo para repetir a lógica. Portanto, precisamos de uma tabela que acompanhe qualquer sessão em um agendador específico e evite o empilhamento:
CREATE TABLE dbo.OpAffinity ( SchedulerID int NOT NULL, SessionID int NULL, CONSTRAINT PK_OpAffinity PRIMARY KEY CLUSTERED (SchedulerID) );
A ideia é que eu teria oito instâncias de um aplicativo (SQLQueryStress) que seriam executados em um agendador dedicado, manipulando apenas os dados destinados a uma partição / grupo de arquivos / arquivo de dados específico, ~ 100 milhões de linhas por vez (clique para ampliar) :
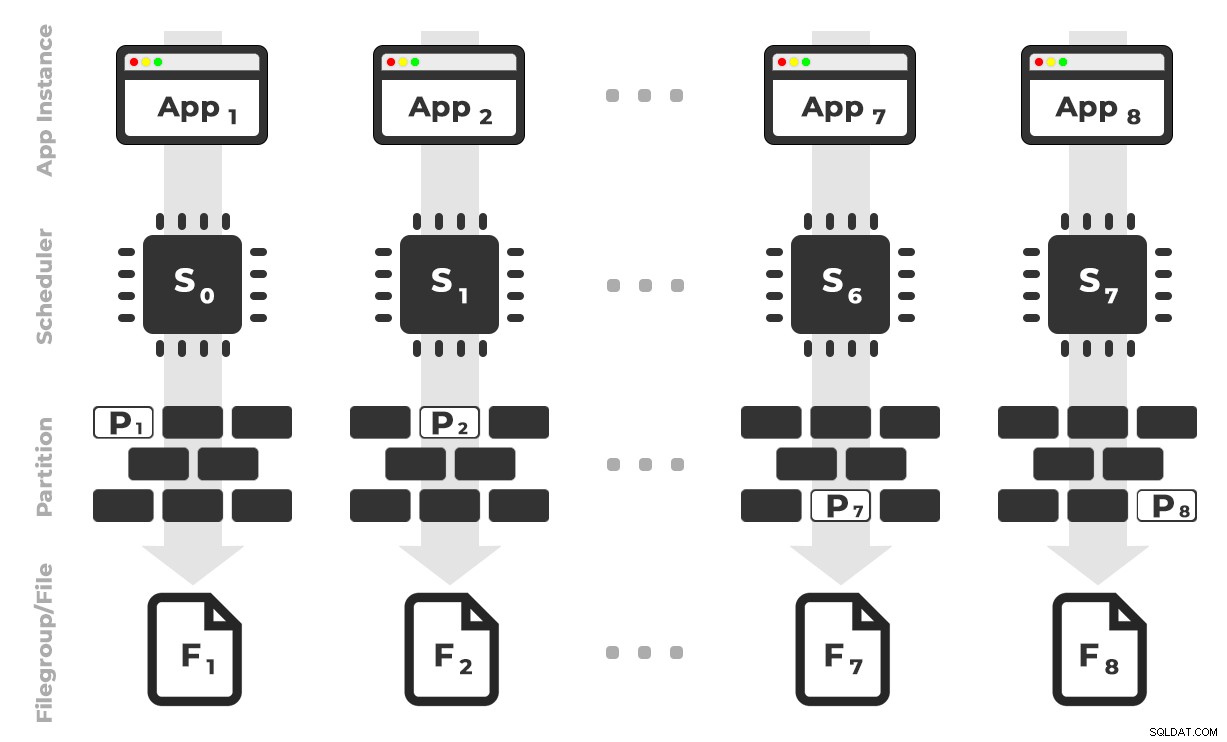 O aplicativo 1 obtém o agendador 0 e grava na partição 1 no grupo de arquivos 1 e assim por diante …
O aplicativo 1 obtém o agendador 0 e grava na partição 1 no grupo de arquivos 1 e assim por diante … Em seguida, precisamos de um procedimento armazenado que permitirá que cada instância do aplicativo reserve tempo em um único agendador. Como mencionei em um post anterior, essa não é minha ideia original (e eu nunca a teria encontrado nesse guia se não fosse por Joe Obbish). Aqui está o procedimento que criei em
Utility :CREATE PROCEDURE dbo.DoMyBatch
@PartitionID int, -- pass in 1 through 8
@BatchID int -- pass in 1 through 4
AS
BEGIN
DECLARE @BatchSize bigint,
@MinID bigint,
@MaxID bigint,
@rc bigint,
@ThisSchedulerID int =
(
SELECT scheduler_id
FROM sys.dm_exec_requests
WHERE session_id = @@SPID
);
-- try to get the requested scheduler, 0-based
IF @ThisSchedulerID <> @PartitionID - 1
BEGIN
-- surface the scheduler we got to the application, but force a delay
RAISERROR('Got wrong scheduler %d.', 11, 1, @ThisSchedulerID);
WAITFOR DELAY '00:00:05';
RETURN -3;
END
ELSE
BEGIN
-- we are on our scheduler, now serializibly make sure we're exclusive
INSERT Utility.dbo.OpAffinity(SchedulerID, SessionID)
SELECT @ThisSchedulerID, @@SPID
WHERE NOT EXISTS
(
SELECT 1 FROM Utility.dbo.OpAffinity WITH (TABLOCKX)
WHERE SchedulerID = @ThisSchedulerID
);
-- if someone is already using this scheduler, raise roar:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Wrong scheduler %d, try again.',11,1,@ThisSchedulerID) WITH NOWAIT;
RETURN @ThisSchedulerID;
END
-- checkpoint twice to clear log
EXEC OCopy.sys.sp_executesql N'CHECKPOINT; CHECKPOINT;';
-- get our range of rows for the current batch
SELECT @MinID = MinID, @MaxID = MaxID
FROM Utility.dbo.BatchQueue
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID
AND StartTime IS NULL;
-- if we couldn't get a row here, must already be done:
IF @@ROWCOUNT <> 1
BEGIN
RAISERROR('Already done.', 11, 1) WITH NOWAIT;
RETURN -1;
END
-- update the BatchQueue table to indicate we've started:
UPDATE msdb.dbo.BatchQueue
SET StartTime = sysdatetime(), EndTime = NULL
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- do the work - copy from Original to Partitioned
INSERT OCopy.dbo.tblPartitionedCCI
SELECT * FROM OCopy.dbo.tblOriginal AS o
WHERE o.CostID >= @MinID AND o.CostID <= @MaxID
OPTION (MAXDOP 1); -- don't want parallelism here!
/*
You might think, don't I want a TABLOCK hint on the insert,
to benefit from minimal logging? I thought so too, but while
this leads to a BULK UPDATE lock on rowstore tables, it is a
TABLOCKX with columnstore. This isn't going to work well if
we want to have multiple processes inserting into separate
partitions simultaneously. We need a PARTITIONLOCK hint!
*/
SET @rc = @@ROWCOUNT;
-- update BatchQueue that we've finished and how many rows:
UPDATE Utility.dbo.BatchQueue
SET EndTime = sysdatetime(), RowsAdded = @rc
WHERE PartitionID = @PartitionID
AND BatchID = @BatchID;
-- remove our lock to this scheduler:
DELETE Utility.dbo.OpAffinity
WHERE SchedulerID = @ThisSchedulerID
AND SessionID = @@SPID;
END
END Simples, certo? Ative 8 instâncias do SQLQueryStress e coloque este lote em cada uma:
EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 1; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 2; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 3; EXEC dbo.DoMyBatch @PartitionID = /* PartitionID - 1 through 8 */, @BatchID = 4;
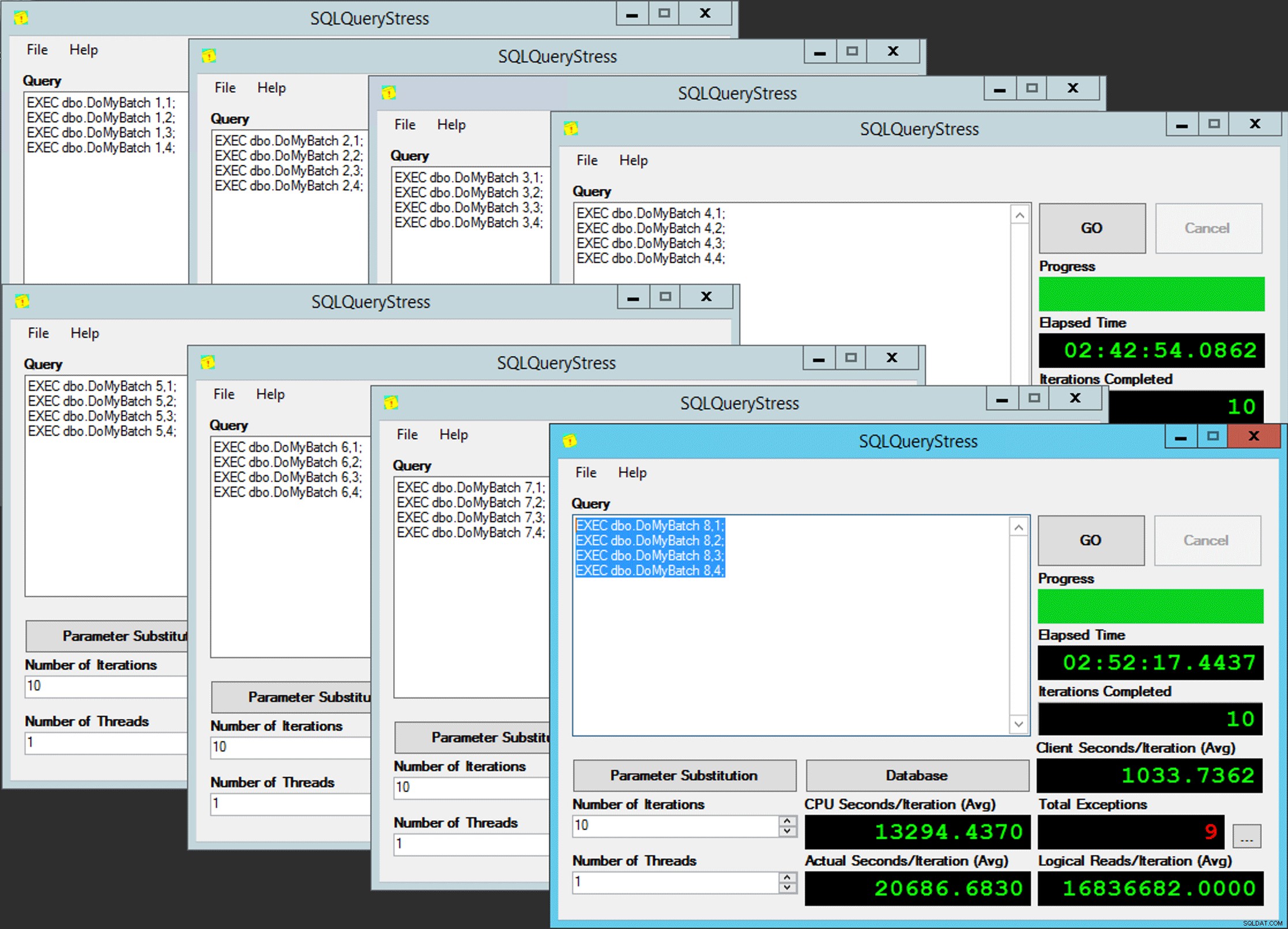 Paralelismo do pobre homem
Paralelismo do pobre homem Exceto que não é tão simples, já que a atribuição do agendador é como uma caixa de chocolates. Foram necessárias muitas tentativas para obter cada instância do aplicativo no agendador esperado; Eu inspecionaria as exceções em qualquer instância do aplicativo e alteraria o
PartitionID para corresponder. É por isso que usei mais de uma iteração (mas ainda queria apenas um thread por instância). Como exemplo, esta instância do aplicativo esperava estar no agendador 3, mas obteve o agendador 4: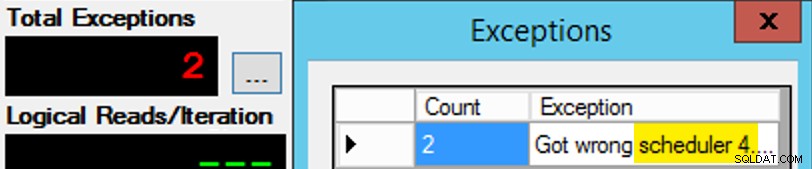 Se você não conseguir…
Se você não conseguir… Mudei os 3s na janela de consulta para 4s e tentei novamente. Se eu fosse rápido, a atribuição do agendador era "pegajosa" o suficiente para que ele a pegasse imediatamente e começasse a sair. Mas eu nem sempre era rápido o suficiente, então era como bater na toupeira para seguir em frente. Eu provavelmente poderia ter inventado uma rotina de repetição/loop melhor para tornar o trabalho menos manual aqui e encurtar o atraso para saber imediatamente se funcionou ou não, mas isso foi bom o suficiente para minhas necessidades. Isso também gerou um escalonamento não intencional dos horários de início de cada processo, outro conselho do Sr. Obbish.
Monitoramento
Enquanto a cópia com afinidade está em execução, posso obter uma dica sobre o status atual com as duas consultas a seguir:
SELECT r.session_id, r.[status], r.scheduler_id, partition_id = o.SchedulerID + 1,
r.logical_reads, r.total_elapsed_time, r.last_wait_type, longest_wait_type =
(
SELECT TOP (1) wait_type
FROM sys.dm_exec_session_wait_stats
WHERE session_id = r.session_id AND wait_type <> 'WAITFOR'
ORDER BY wait_time_ms - signal_wait_time_ms DESC
)
FROM sys.dm_exec_requests AS r
INNER JOIN Utility.dbo.OpAffinity AS o
ON o.SessionID = r.session_id
WHERE r.command = N'INSERT'
ORDER BY r.scheduler_id;
SELECT SchedulerID = PartitionID - 1, Duration = DATEDIFF(SECOND, StartTime, EndTime), *
FROM Utility.dbo.BatchQueue WITH (NOLOCK)
WHERE StartTime IS NOT NULL -- AND EndTime IS NULL
ORDER BY PartitionID; Se eu fizesse tudo certo, ambas as consultas retornariam 8 linhas e mostrariam leituras lógicas e duração incrementadas. Os tipos de espera alternarão entre
PAGEIOLATCH_SH , SOS_SCHEDULER_YIELD , e ocasionalmente RESERVED_MEMORY_ALLOCATION_EXT. Quando um lote foi concluído (eu poderia revisá-los descomentando -- AND EndTime IS NULL , eu confirmaria que RowsAdded = RowsInRange . Depois que todas as 8 instâncias do SQLQueryStress foram concluídas, eu poderia apenas executar um
SELECT INTO <newtable> FROM dbo.BatchQueue para registrar os resultados finais para análise posterior. Outros testes
Além de copiar os dados para o índice columnstore clusterizado particionado que já existia, usando afinidade, eu queria tentar algumas outras coisas também:
- Copiar os dados para a nova tabela sem tentar controlar a afinidade. Eu tirei a lógica de afinidade do procedimento e deixei toda a coisa de "espero que você consiga o programador certo" ao acaso. Isso levou mais tempo porque, com certeza, o empilhamento do agendador realizou ocorrer. Por exemplo, neste ponto específico, o agendador 3 estava executando dois processos, enquanto o agendador 0 estava fazendo uma pausa para o almoço:
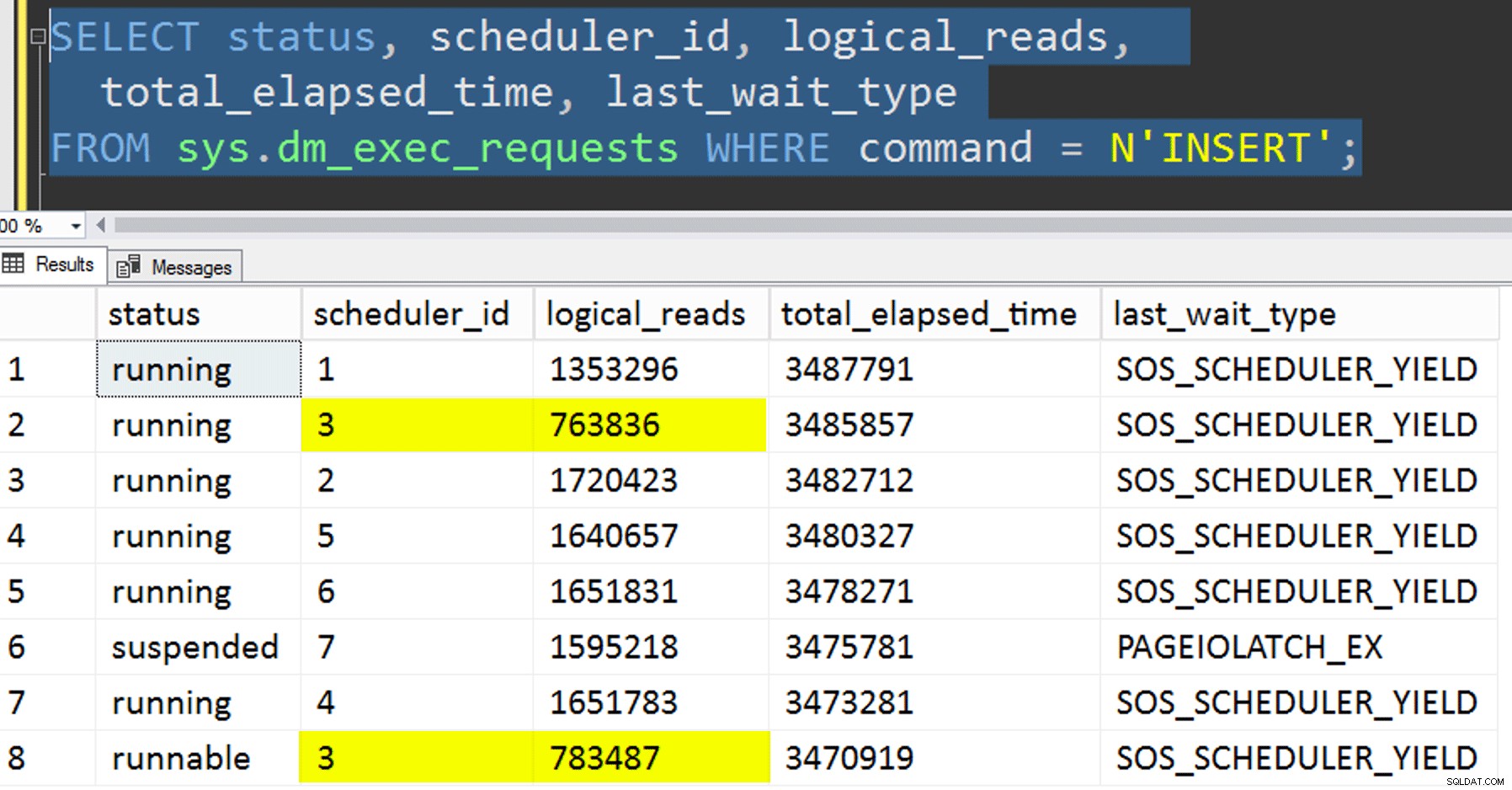 Onde você está, agendador número 0?
Onde você está, agendador número 0? - Aplicando a página ou linha compressão (tanto online/offline) para a fonte antes a cópia com afinidade (offline), para ver se compactar os dados primeiro pode acelerar o destino. Observe que a cópia também pode ser feita online, mas, como o
intde Andy Mallon parabigintconversão, requer alguma ginástica. Observe que, neste caso, não podemos aproveitar a afinidade da CPU (embora pudéssemos se a tabela de origem já estivesse particionada). Fui esperto e fiz um backup da fonte original e criei um procedimento para reverter o banco de dados de volta ao seu estado inicial. Muito mais rápido e fácil do que tentar reverter para um estado específico manualmente.
-- refresh source, then do page online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do page offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = PAGE, ONLINE = OFF); -- then run SQLQueryStress -- refresh source, then do row online: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = ON); -- then run SQLQueryStress -- refresh source, then do row offline: ALTER TABLE dbo.tblOriginal REBUILD WITH (DATA_COMPRESSION = ROW, ONLINE = OFF); -- then run SQLQueryStress
- E, finalmente, reconstruir primeiro o índice clusterizado no esquema de partição e, em seguida, construir o índice columnstore clusterizado em cima disso. A desvantagem deste último é que, no SQL Server 2017, você não pode executá-lo online… mas poderá fazê-lo em 2019.
Aqui precisamos eliminar a restrição PK primeiro; você não pode usarDROP_EXISTING, pois a restrição exclusiva original não pode ser imposta pelo índice columnstore clusterizado e você não pode substituir um índice clusterizado exclusivo por um índice clusterizado não exclusivo.
Msg 1907, Level 16, State 1
Não é possível recriar o índice 'pk_tblOriginal'. A nova definição de índice não corresponde à restrição imposta pelo índice existente.
Todos esses detalhes fazem deste um processo de três etapas, apenas a segunda etapa online. A primeira etapa eu só testei explicitamenteOFFLINE; que foi executado em três minutos, enquantoONLINEParei depois de 15 minutos. Uma daquelas coisas que talvez não devesse ser uma operação de tamanho de dados em ambos os casos, mas deixarei isso para outro dia.
ALTER TABLE dbo.tblOriginal DROP CONSTRAINT PK_tblOriginal WITH (ONLINE = OFF); GO CREATE CLUSTERED INDEX CCI_tblOriginal -- yes, a bad name, but only temporarily ON dbo.tblOriginal(OID) WITH (ONLINE = ON) ON PS_OID (OID); -- this moves the data CREATE CLUSTERED COLUMNSTORE INDEX CCI_tblOriginal ON dbo.tblOriginal WITH ( DROP_EXISTING = ON, DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) -- in 2019, CCI can be ONLINE = ON as well ) ON PS_OID (OID); GO
Resultados
Tempos e taxas de compressão:
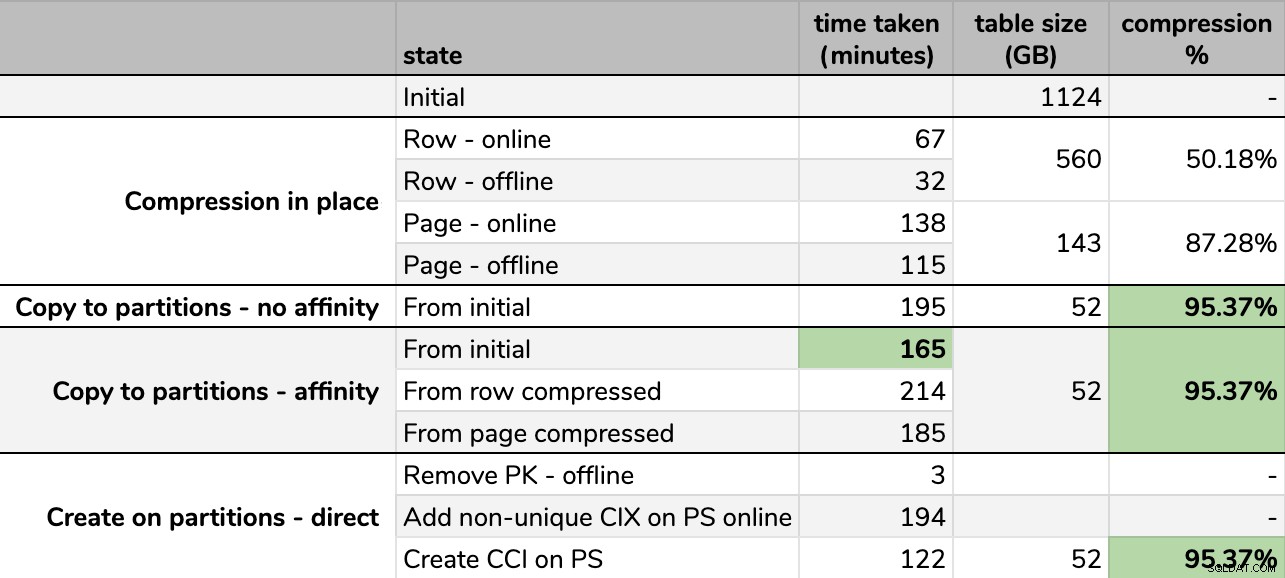 Algumas opções são melhores que outras
Algumas opções são melhores que outras Observe que arredondei para GB porque haveria pequenas diferenças no tamanho final após cada execução, mesmo usando a mesma técnica. Além disso, os tempos para os métodos de afinidade foram baseados na média tempo de execução do agendador/lote individual, já que alguns agendadores terminaram mais rápido que outros.
É difícil visualizar uma imagem exata da planilha como mostrado, porque algumas tarefas têm dependências, então tentarei exibir as informações como uma linha do tempo e mostrar quanta compactação você obtém em comparação com o tempo gasto:
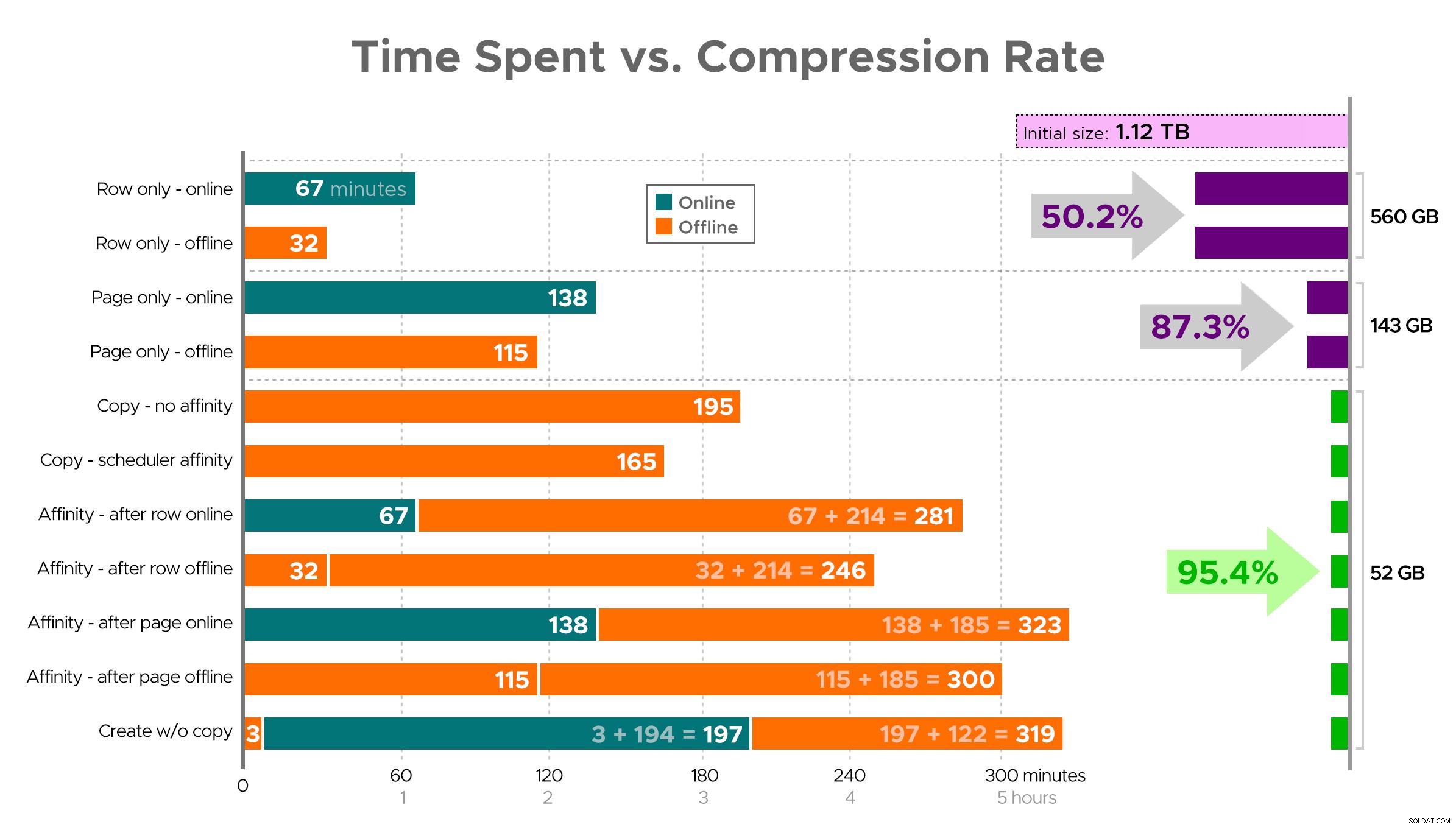 Tempo gasto (minutos) x taxa de compactação
Tempo gasto (minutos) x taxa de compactação Algumas observações dos resultados, com a ressalva de que seus dados podem ser compactados de maneira diferente (e que as operações online só se aplicam a você se você usar o Enterprise Edition):
- Se sua prioridade é economizar espaço o mais rápido possível , sua melhor aposta é aplicar a compactação de linha no local. Se você quiser minimizar a interrupção, use online; se você quiser otimizar a velocidade, use offline.
- Se você deseja maximizar a compactação sem interrupção , você pode atingir uma redução de armazenamento de 90% sem nenhuma interrupção, usando a compactação de página online.
- Se você quiser maximizar a compactação e a interrupção, tudo bem , copie os dados para uma nova versão particionada da tabela, com um índice columnstore clusterizado e use o processo de afinidade descrito acima para migrar os dados. (E, novamente, você pode eliminar essa interrupção se for um planejador melhor do que eu.)
A opção final funcionou melhor para o meu cenário, embora ainda tenhamos que chutar os pneus nas cargas de trabalho (sim, no plural). Observe também que no SQL Server 2019 essa técnica pode não funcionar tão bem, mas você pode criar índices columnstore clusterizados online, portanto, pode não importar tanto.
Algumas dessas abordagens podem ser mais ou menos aceitáveis para você, porque você pode preferir "permanecer disponível" em vez de "terminar o mais rápido possível" ou "minimizar o uso do disco" em vez de "permanecer disponível" ou apenas equilibrar o desempenho de leitura e a sobrecarga de gravação .
Se você quiser mais detalhes sobre qualquer aspecto disso, é só perguntar. Cortei um pouco da gordura para equilibrar os detalhes com a digestibilidade, e já errei sobre esse equilíbrio antes. Um pensamento de despedida é que estou curioso para ver como isso é linear – temos outra tabela com uma estrutura semelhante que tem mais de 25 TB, e estou curioso para saber se podemos causar algum impacto semelhante lá. Até lá, boa compressão!
[ Parte 1 | Parte 2 | Parte 3]