De acordo com a Wikipedia, a inserção em massa é um processo ou método fornecido por um sistema de gerenciamento de banco de dados para carregar várias linhas de dados em uma tabela de banco de dados. Se ajustarmos esta explicação à instrução BULK INSERT, a inserção em massa permite importar arquivos de dados externos para o SQL Server.
Suponha que nossa organização tenha um arquivo CSV de 1.500.000 linhas e queremos importá-lo para uma tabela específica no SQL Server para usar a instrução BULK INSERT no SQL Server. Podemos encontrar vários métodos para lidar com essa tarefa. Pode estar usando BCP (b ulk c opi p programa), Assistente de Importação e Exportação do SQL Server ou pacote do SQL Server Integration Service. No entanto, a instrução BULK INSERT é muito mais rápida e potente. Outra vantagem é que oferece vários parâmetros que ajudam a determinar as configurações do processo de inserção em massa.
Vamos começar com uma amostra básica. Em seguida, passaremos por cenários mais sofisticados.
Preparação
Em primeiro lugar, precisamos de um arquivo CSV de amostra. Baixamos um arquivo CSV de amostra do site E for Excel (uma coleção de arquivos CSV de amostra com um número de linha diferente). Aqui, vamos usar 1.500.000 registros de vendas.
Baixe um arquivo zip, descompacte-o para obter um arquivo CSV e coloque-o em sua unidade local.
Importar arquivo CSV para a tabela do SQL Server
Importamos nosso arquivo CSV para a tabela de destino da forma mais simples. Coloquei meu arquivo CSV de amostra na unidade C:. Agora criamos uma tabela para importar os dados do arquivo CSV para ela:
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
A seguinte instrução BULK INSERT importa o arquivo CSV para a tabela Sales:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Você provavelmente notou os parâmetros específicos da instrução de inserção em massa acima. Vamos esclarecê-los:
- PRIMEIRO especifica o ponto inicial da instrução insert. No exemplo abaixo, queremos pular os cabeçalhos das colunas, então definimos esse parâmetro como 2.

- FIELDTERMINATOR define o caractere que separa os campos uns dos outros. O SQL Server detecta cada campo dessa maneira.
- ROWTERMINATOR não difere muito de FIELDTERMINATOR. Ele define o caractere de separação das linhas.
No arquivo CSV de amostra, FIELDTERMINATOR é muito claro e é uma vírgula (,). Para detectar esse parâmetro, abra o arquivo CSV no Notepad++ e navegue até View -> Show Symbol -> Show All Charters. Os caracteres CRLF estão no final de cada campo.
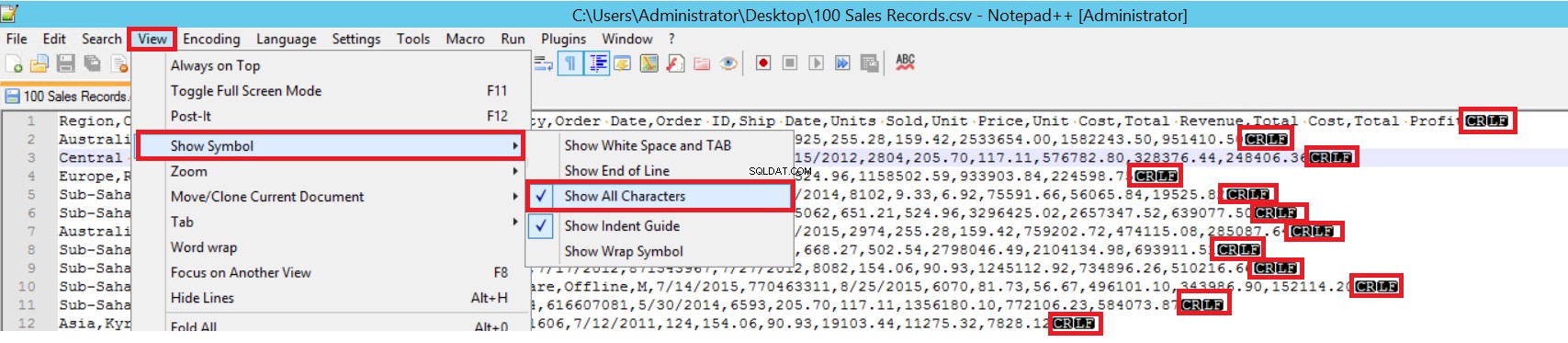
CR =Retorno de carro e LF =Alimentação de linha. Eles são usados para marcar uma quebra de linha em um arquivo de texto. O indicador é “\n” na instrução de inserção em massa.
Outra maneira de importar um arquivo CSV para uma tabela com inserção em massa é usando o parâmetro FORMAT. Observe que esse parâmetro está disponível apenas no SQL Server 2017 e em versões posteriores.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
Esse foi o cenário mais simples em que a tabela de destino e o arquivo CSV têm um número igual de colunas. No entanto, no caso de a tabela de destino ter mais colunas, o arquivo CSV é típico. Vamos considerá-lo.
Adicionamos uma chave primária à tabela Sales para quebrar os mapeamentos de coluna de igualdade. Criamos a tabela Sales com uma chave primária e importamos o arquivo CSV por meio do comando bulk insert.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Mas dá um erro:
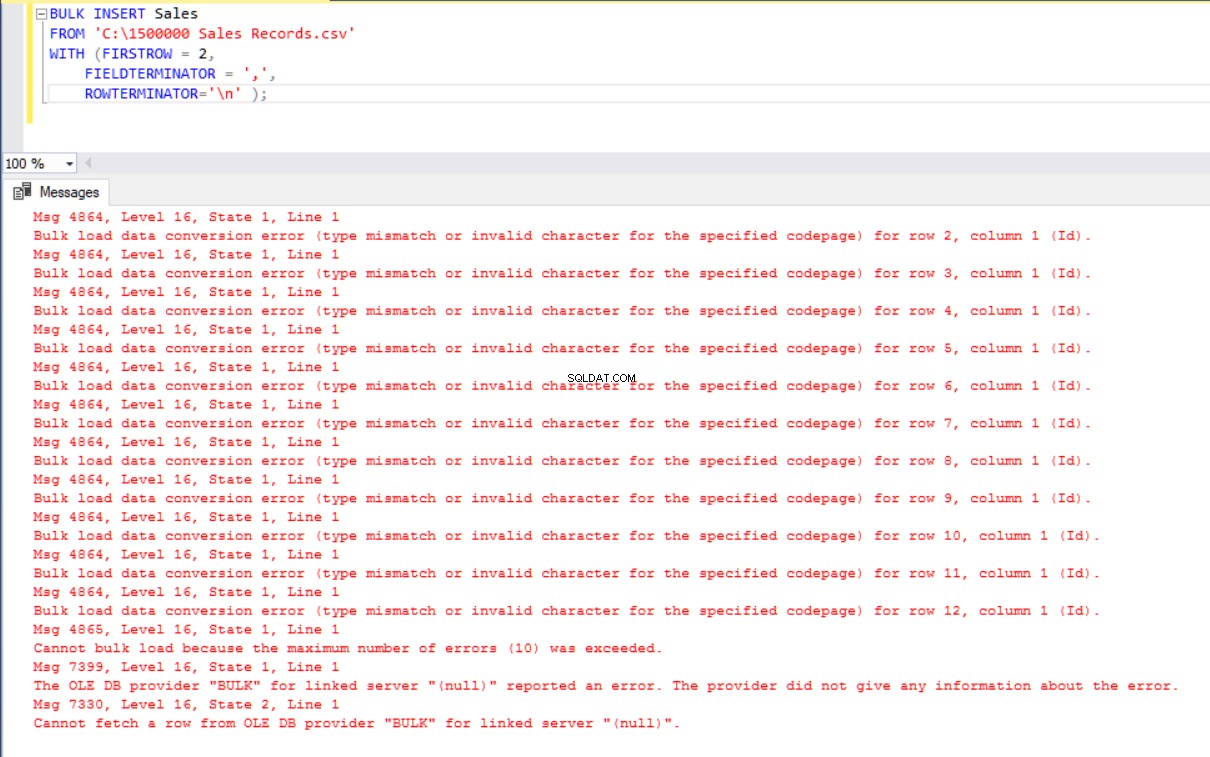
Para superar o erro, criamos uma visualização da tabela Sales com colunas de mapeamento para o arquivo CSV. Em seguida, importamos os dados CSV dessa visualização para a tabela Sales:
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Separe e carregue um arquivo CSV grande em um tamanho de lote pequeno
O SQL Server adquire um bloqueio para a tabela de destino durante a operação de inserção em massa. Por padrão, se você não definir o parâmetro BATCHSIZE, o SQL Server abre uma transação e insere todos os dados CSV nela. Com este parâmetro, o SQL Server divide os dados CSV de acordo com o valor do parâmetro.
Vamos dividir todos os dados CSV em vários conjuntos de 300.000 linhas cada.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 ); Os dados serão importados cinco vezes em partes.
- Se sua instrução de inserção em massa não incluir o parâmetro BATCHSIZE, ocorrerá um erro e o SQL Server reverterá todo o processo de inserção em massa.
- Com esse parâmetro definido como instrução de inserção em massa, o SQL Server reverte apenas a parte em que ocorreu o erro.
Não há valor ideal ou melhor para esse parâmetro porque seu valor pode ser alterado de acordo com os requisitos do sistema de banco de dados.
Defina o comportamento em caso de erros
Se ocorrer um erro em alguns cenários de cópia em massa, podemos cancelar o processo de cópia em massa ou mantê-lo em andamento. O parâmetro MAXERRORS permite especificar o número máximo de erros. Se o processo de inserção em massa atingir esse valor máximo de erro, ele cancelará a operação de importação em massa e reverterá. O valor padrão para este parâmetro é 10.
Por exemplo, corrompemos tipos de dados em 3 linhas do arquivo CSV. O parâmetro MAXERRORS é definido como 2.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2); Toda a operação de inserção em massa será cancelada porque há mais erros do que o valor do parâmetro MAXERRORS.
Se alterarmos o parâmetro MAXERRORS para 4, a instrução de inserção em massa ignorará essas linhas com erros e inserirá linhas estruturadas de dados corretas. O processo de inserção em massa será concluído.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Se usarmos BATCHSIZE e MAXERRORS simultaneamente, o processo de cópia em massa não cancelará toda a operação de inserção. Só cancelará a parte dividida.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Dê uma olhada na imagem abaixo que mostra o resultado da execução do script:
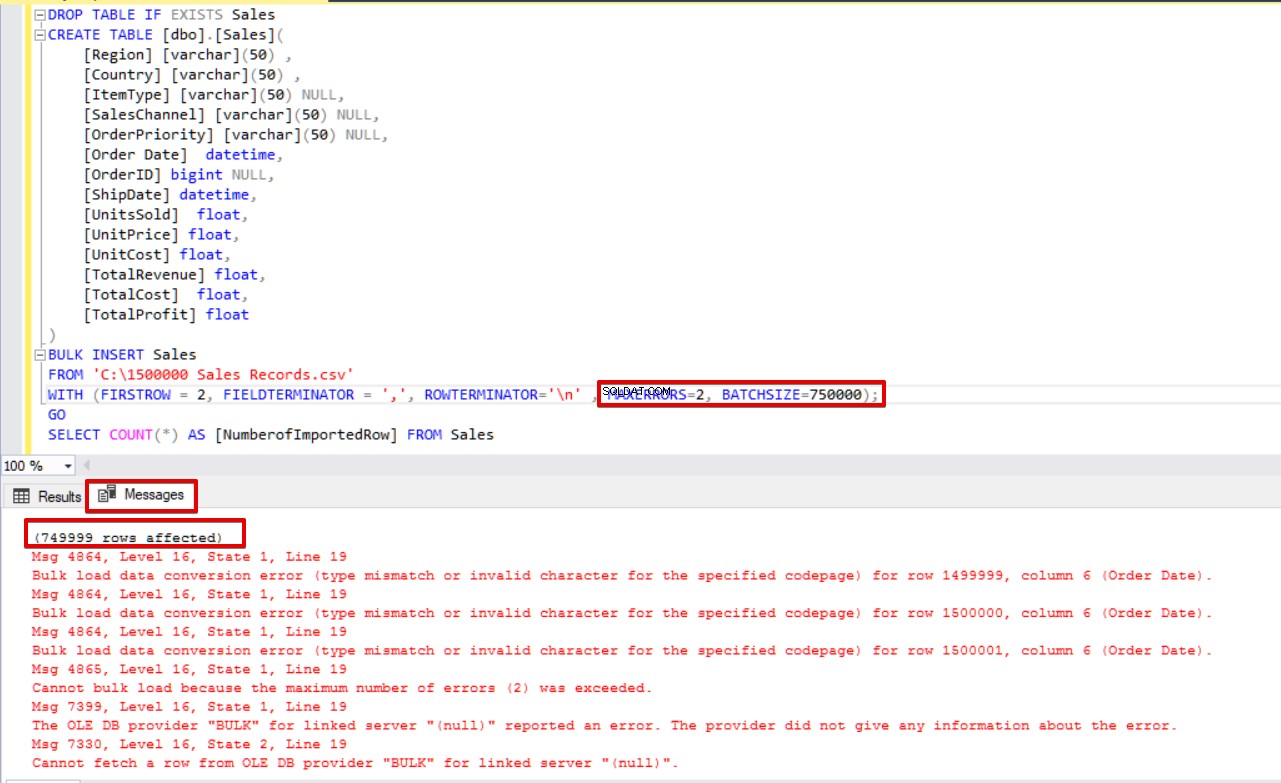
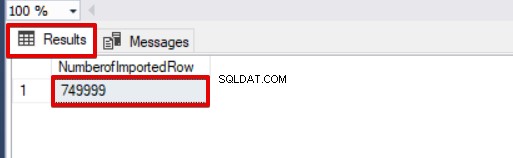
Outras opções do processo de inserção em massa
FIRE_TRIGGERS – ativa acionadores na tabela de destino durante a operação de inserção em massa
Por padrão, durante o processo de inserção em massa, os acionadores de inserção especificados na tabela de destino não são acionados. Ainda assim, em algumas situações, podemos querer habilitá-los.
A solução é usar a opção FIRE_TRIGGERS em instruções de inserção em massa. Mas observe que isso pode afetar e diminuir o desempenho da operação de inserção em massa. É porque trigger/triggers podem fazer operações separadas no banco de dados.
A princípio, não definimos o parâmetro FIRE_TRIGGERS e o processo de inserção em massa não acionará o acionador de inserção. Veja o script T-SQL abaixo:
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLogQuando este script é executado, o gatilho de inserção não será acionado porque a opção FIRE_TRIGGERS não está definida.
Agora, vamos adicionar a opção FIRE_TRIGGERS à instrução de inserção em massa:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
FIRE_TRIGGERS);
GO
SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog 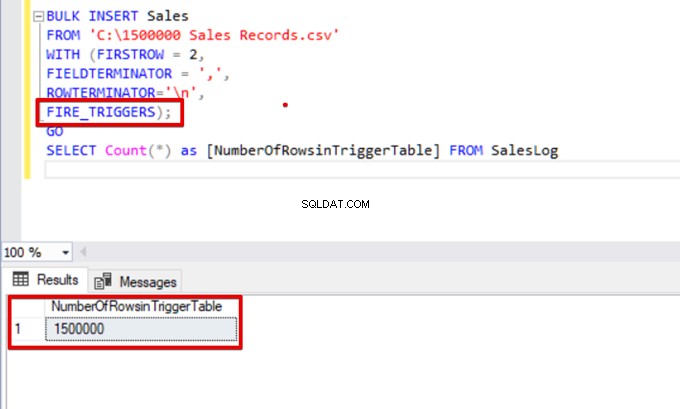
CHECK_CONSTRAINTS – ativa uma restrição de verificação durante a operação de inserção em massa
As restrições de verificação nos permitem impor a integridade dos dados nas tabelas do SQL Server. O objetivo da restrição é verificar os valores inseridos, atualizados ou excluídos de acordo com sua regulação de sintaxe. Por exemplo, a restrição NOT NULL fornece que o valor NULL não pode modificar uma coluna especificada.
Aqui, nos concentramos em restrições e interações de inserção em massa. Por padrão, durante o processo de inserção em massa, todas as restrições de verificação e chave estrangeira são ignoradas. Mas há algumas exceções.
De acordo com a Microsoft, “as restrições UNIQUE e PRIMARY KEY são sempre aplicadas. Ao importar para uma coluna de caracteres para a qual a restrição NOT NULL está definida, BULK INSERT insere uma string em branco quando não há valor no arquivo de texto.”
No script T-SQL a seguir, adicionamos uma restrição de verificação à coluna OrderDate, que controla a data do pedido maior que 01.01.2016.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'Como resultado, o processo de inserção em massa ignora o controle de restrição de verificação. No entanto, o SQL Server indica a restrição de verificação como não confiável:
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'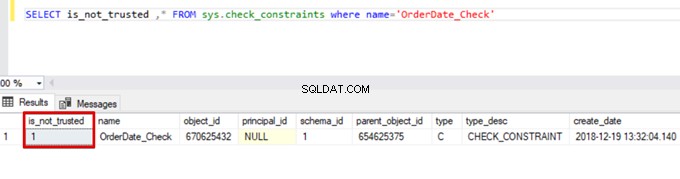
Esse valor indica que alguém inseriu ou atualizou alguns dados nessa coluna ignorando a restrição de verificação. Ao mesmo tempo, esta coluna pode conter dados inconsistentes em relação a essa restrição.
Tente executar a instrução de inserção em massa com a opção CHECK_CONSTRAINTS. O resultado é direto:check constraint retorna um erro devido a dados impróprios.
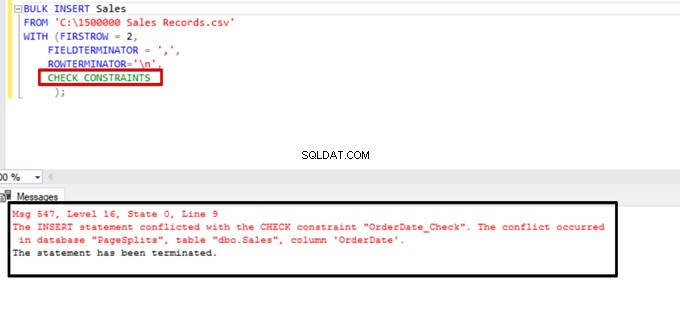
TABLOCK – aumente o desempenho em várias inserções em massa em uma tabela de destino
O objetivo principal do mecanismo de bloqueio no SQL Server é proteger e garantir a integridade dos dados. No artigo Conceito principal do bloqueio do SQL Server, você pode encontrar detalhes sobre o mecanismo de bloqueio.
Vamos nos concentrar nos detalhes de bloqueio do processo de inserção em massa.
Se você executar a instrução de inserção em massa sem a opção TABLELOCK, ela adquirirá o bloqueio de linhas ou tabelas de acordo com a hierarquia de bloqueio. Mas, em alguns casos, podemos querer executar vários processos de inserção em massa em uma tabela de destino e, assim, diminuir o tempo de operação.
Primeiro, executamos duas instruções de inserção em massa simultaneamente e analisamos o comportamento do mecanismo de bloqueio. Abra duas janelas de consulta no SQL Server Management Studio e execute as seguintes instruções de inserção em massa simultaneamente.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
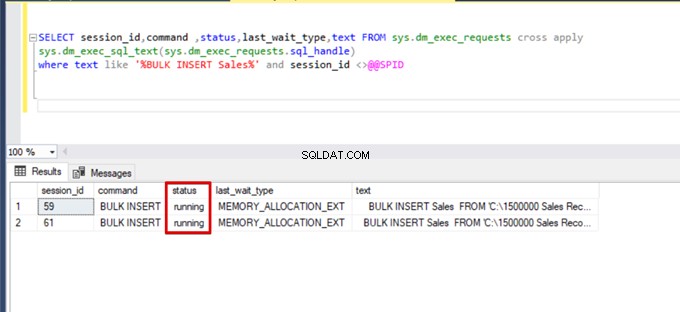
);Execute a seguinte consulta DMV (Dynamic Management View) – ajuda a monitorar o status do processo de inserção em massa:
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply
sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle)
where text like '%BULK INSERT Sales%' and session_id <>@@SPID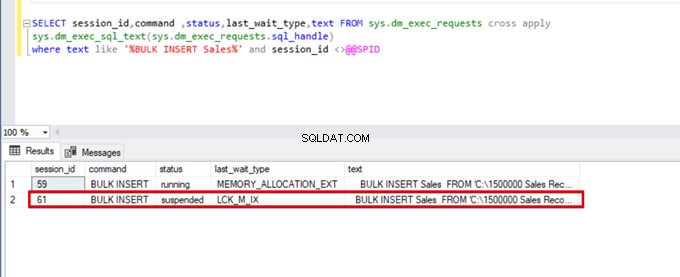
Como você pode ver na imagem acima, sessão 61, o status do processo de inserção em massa está suspenso devido ao bloqueio. Se verificarmos o problema, a sessão 59 bloqueará a tabela de destino de inserção em massa. Em seguida, a sessão 61 aguarda a liberação desse bloqueio para continuar o processo de inserção em massa.
Agora, adicionamos a opção TABLOCK às instruções de inserção em massa e executamos as consultas.
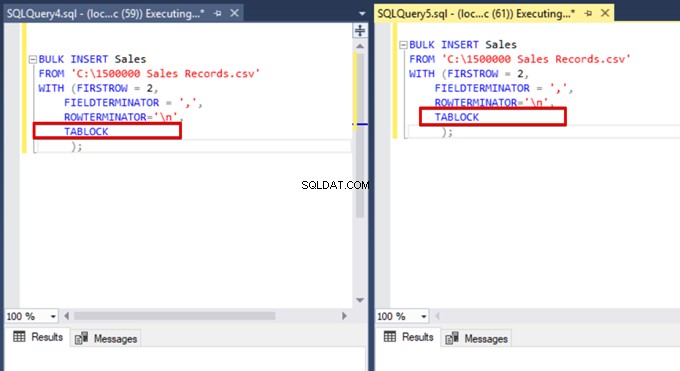
Quando executamos a consulta de monitoramento DMV novamente, não podemos ver nenhum processo de inserção em massa suspenso porque o SQL Server usa um tipo de bloqueio específico chamado bloqueio de atualização em massa (BU). Esse tipo de bloqueio permite processar várias operações de inserção em massa na mesma tabela simultaneamente. Essa opção também diminui o tempo total do processo de inserção em massa.
Quando executamos a seguinte consulta durante o processo de inserção em massa, podemos monitorar os detalhes e os tipos de bloqueio:
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()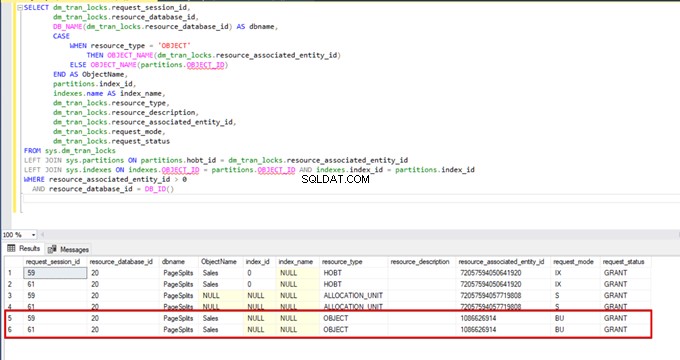
Conclusão
O artigo atual explorou todos os detalhes da operação de inserção em massa no SQL Server. Notavelmente, mencionamos o comando BULK INSERT e suas configurações e opções. Além disso, analisamos vários cenários próximos a problemas da vida real.
Ferramenta útil:
dbForge Data Pump – um add-in SSMS para preencher bancos de dados SQL com dados de origem externa e migrar dados entre sistemas.