Este artigo é a terceira parte de uma série sobre complexidades NULL. Na Parte 1 abordei o significado do marcador NULL e como ele se comporta em comparações. Na Parte 2, descrevi as inconsistências do tratamento NULL em diferentes elementos da linguagem. Este mês, descrevo recursos poderosos de manipulação de NULL padrão que ainda não chegaram ao T-SQL e as soluções alternativas que as pessoas usam atualmente.
Continuarei usando o banco de dados de exemplo TSQLV5 como no mês passado em alguns dos meus exemplos. Você pode encontrar o script que cria e preenche esse banco de dados aqui e seu diagrama ER aqui.
Predicado DISTINTO
Na Parte 1 da série, expliquei como os NULLs se comportam em comparações e as complexidades em torno da lógica de predicado de três valores que SQL e T-SQL empregam. Considere o seguinte predicado:
X =Y
Se algum predicado for NULL — inclusive quando ambos forem NULL — o resultado desse predicado será o valor lógico UNKNOWN. Com exceção dos operadores IS NULL e IS NOT NULL, o mesmo se aplica a todos os outros operadores, incluindo diferente de (<>):
X <> Y
Muitas vezes, na prática, você deseja que NULLs se comportem como valores não NULL para fins de comparação. Esse é especialmente o caso quando você os usa para representar ausentes, mas inaplicáveis valores. O padrão tem uma solução para essa necessidade na forma de um recurso chamado predicado DISTINCT, que utiliza a seguinte forma:
Em vez de usar semântica de igualdade ou desigualdade, esse predicado usa semântica baseada em distinção ao comparar predicandos. Como alternativa a um operador de igualdade (=), você usaria a seguinte forma para obter um TRUE quando os dois predicandos são iguais, inclusive quando ambos são NULLs, e um FALSE quando não são, inclusive quando um é NULL e o outro não é:
X NÃO É DIFERENTE DE Y
Como alternativa a um diferente de operador (<>), você usaria a seguinte forma para obter um TRUE quando os dois predicandos são diferentes, inclusive quando um é NULL e o outro não, e um FALSE quando eles são iguais, inclusive quando ambos são NULL:
X É DIFERENTE DE Y
Vamos aplicar o predicado DISTINCT aos exemplos que usamos na Parte 1 da série. Lembre-se de que você precisava escrever uma consulta que fornecesse um parâmetro de entrada @dt retornasse pedidos que foram enviados na data de entrada se não for NULL, ou que não foram enviados se a entrada for NULL. De acordo com o padrão, você usaria o seguinte código com o predicado DISTINCT para lidar com essa necessidade:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT DISTINCT FROM @dt;
Por enquanto, lembre-se da Parte 1 que você pode usar uma combinação do predicado EXISTS e do operador INTERSECT como uma solução SARGable no T-SQL, assim:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
Para devolver pedidos que foram enviados em uma data diferente (diferente) da data de entrada @dt, você usaria a seguinte consulta:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS DISTINCT FROM @dt;
A solução alternativa que funciona no T-SQL usa uma combinação do predicado EXISTS e do operador EXCEPT, assim:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
Na Parte 1, também discuti cenários em que você precisa unir tabelas e aplicar semântica baseada em distinção no predicado de junção. Em meus exemplos, usei tabelas chamadas T1 e T2, com colunas de junção NULLable chamadas k1, k2 e k3 em ambos os lados. De acordo com o padrão, você usaria o seguinte código para lidar com essa junção:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON T1.k1 IS NOT DISTINCT FROM T2.k1 AND T1.k2 IS NOT DISTINCT FROM T2.k2 AND T1.k3 IS NOT DISTINCT FROM T2.k3;
Por enquanto, semelhante às tarefas de filtragem anteriores, você pode usar uma combinação do predicado EXISTS e do operador INTERSECT na cláusula ON da junção para emular o predicado distinto no T-SQL, assim:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
Quando usado em um filtro, esse formulário é SARGable e, quando usado em junções, esse formulário pode depender da ordem do índice.
Se você gostaria de ver o predicado DISTINCT adicionado ao T-SQL, você pode votar nele aqui.
Se depois de ler esta seção você ainda se sentir um pouco desconfortável com o predicado DISTINCT, você não está sozinho. Talvez esse predicado seja muito melhor do que qualquer solução existente que temos atualmente no T-SQL, mas é um pouco verboso e um pouco confuso. Ele usa uma forma negativa para aplicar o que em nossas mentes é uma comparação positiva e vice-versa. Bem, ninguém disse que todas as sugestões padrão são perfeitas. Como Charlie observou em um de seus comentários à Parte 1, a seguinte forma simplificada funcionaria melhor:
É conciso e muito mais intuitivo. Em vez de X NÃO É DISTINTO DE Y, você usaria:
X É Y
E em vez de X IS DISTINCT FROM Y, você usaria:
X NÃO É Y
Este operador proposto está realmente alinhado com os operadores IS NULL e IS NOT NULL já existentes.
Aplicado à nossa tarefa de consulta, para devolver pedidos que foram enviados na data de entrada (ou que não foram enviados se a entrada for NULL), você usaria o seguinte código:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS @dt;
Para devolver pedidos que foram enviados em uma data diferente da data de entrada, você usaria o seguinte código:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT @dt;
Se a Microsoft decidir adicionar o predicado distinto, seria bom se eles suportassem tanto a forma detalhada padrão quanto essa forma não padrão, ainda mais concisa e intuitiva. Curiosamente, o processador de consultas do SQL Server já suporta um operador de comparação interno IS, que usa a mesma semântica do operador IS desejado que descrevi aqui. Você pode encontrar detalhes sobre esse operador no artigo de Paul White Planos de consulta não documentados:Comparações de igualdade (pesquisa “IS em vez de EQ”). O que está faltando é expô-lo externamente como parte do T-SQL.
Cláusula de tratamento NULL (IGNORE NULLS | RESPECT NULLS)
Ao usar as funções de janela de deslocamento LAG, LEAD, FIRST_VALUE e LAST_VALUE, às vezes você precisa controlar o comportamento do tratamento NULL. Por padrão, essas funções retornam o resultado da expressão solicitada na posição solicitada, independentemente de o resultado da expressão ser um valor real ou NULL. No entanto, às vezes você deseja continuar se movendo na direção relevante (para trás para LAG e LAST_VALUE, para frente para LEAD e FIRST_VALUE) e retornar o primeiro valor não NULL se estiver presente e NULL caso contrário. O padrão dá a você controle sobre esse comportamento usando uma cláusula de tratamento NULL com a seguinte sintaxe:
offset_function(
O padrão caso a cláusula de tratamento NULL não seja especificada é a opção RESPECT NULLS, ou seja, retornar o que estiver presente na posição solicitada mesmo que seja NULL. Infelizmente, esta cláusula ainda não está disponível no T-SQL. Fornecerei exemplos para a sintaxe padrão usando as funções LAG e FIRST_VALUE, bem como soluções alternativas que funcionam em T-SQL. Você pode usar técnicas semelhantes se precisar dessa funcionalidade com LEAD e LAST_VALUE.
Como dados de exemplo, usarei uma tabela chamada T4 que você cria e preenche usando o seguinte código:
DROP TABLE IF EXISTS dbo.T4; GO CREATE TABLE dbo.T4 ( id INT NOT NULL CONSTRAINT PK_T4 PRIMARY KEY, col1 INT NULL ); INSERT INTO dbo.T4(id, col1) VALUES ( 2, NULL), ( 3, 10), ( 5, -1), ( 7, NULL), (11, NULL), (13, -12), (17, NULL), (19, NULL), (23, 1759);
Há uma tarefa comum que envolve retornar o último relevante valor. Um NULL em col1 indica nenhuma alteração no valor, enquanto um valor não NULL indica um novo valor relevante. Você precisa retornar o último valor col1 não NULL com base na ordenação de id. Usando a cláusula de tratamento NULL padrão, você lidaria com a tarefa assim:
SELECT id, col1, COALESCE(col1, LAG(col1) IGNORE NULLS OVER(ORDER BY id)) AS lastval FROM dbo.T4;
Aqui está a saída esperada desta consulta:
id col1 lastval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 -1 7 NULL -1 11 NULL -1 13 -12 -12 17 NULL -12 19 NULL -12 23 1759 1759
Existe uma solução alternativa no T-SQL, mas envolve duas camadas de funções de janela e uma expressão de tabela.
Na primeira etapa, você usa a função de janela MAX para calcular uma coluna chamada grp que contém o valor máximo de id até agora quando col1 não é NULL, assim:
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Este código gera a seguinte saída:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 5 7 NULL 5 11 NULL 5 13 -12 13 17 NULL 13 19 NULL 13 23 1759 23
Como você pode ver, um valor grp exclusivo é criado sempre que houver uma alteração no valor col1.
Na segunda etapa, você define um CTE com base na consulta da primeira etapa. Então, na consulta externa, você retorna o valor máximo de col1 até agora, dentro de cada partição definida por grp. Esse é o último valor col1 não NULL. Aqui está o código completo da solução:
WITH C AS
(
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
MAX(col1) OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS lastval
FROM C; Claramente, isso é muito mais código e trabalho comparado a apenas dizer IGNORE_NULLS.
Outra necessidade comum é retornar o primeiro valor relevante. Em nosso caso, suponha que você precise retornar o primeiro valor col1 não NULL até agora com base na ordenação de id. Usando a cláusula de tratamento NULL padrão, você lidaria com a tarefa com a função FIRST_VALUE e a opção IGNORE NULLS, assim:
SELECT id, col1,
FIRST_VALUE(col1) IGNORE NULLS
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM dbo.T4; Aqui está a saída esperada desta consulta:
id col1 firstval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 10 7 NULL 10 11 NULL 10 13 -12 10 17 NULL 10 19 NULL 10 23 1759 10
A solução alternativa no T-SQL usa uma técnica semelhante à usada para o último valor não NULL, apenas em vez de uma abordagem de MAX duplo, você usa a função FIRST_VALUE sobre uma função MIN.
Na primeira etapa, você usa a função de janela MIN para calcular uma coluna chamada grp mantendo o valor mínimo de id até agora quando col1 não é NULL, assim:
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Este código gera a seguinte saída:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 3 7 NULL 3 11 NULL 3 13 -12 3 17 NULL 3 19 NULL 3 23 1759 3
Se houver NULLs presentes antes do primeiro valor relevante, você terminará com dois grupos - o primeiro com o NULL como o valor grp e o segundo com o primeiro id não NULL como o valor grp.
Na segunda etapa, você coloca o código da primeira etapa em uma expressão de tabela. Em seguida, na consulta externa, você usa a função FIRST_VALUE, particionada por grp, para coletar o primeiro valor relevante (não NULL) se estiver presente e NULL caso contrário, assim:
WITH C AS
(
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
FIRST_VALUE(col1)
OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM C; Novamente, isso é muito código e trabalho comparado a simplesmente usar a opção IGNORE_NULLS.
Se você acha que esse recurso pode ser útil para você, você pode votar pela sua inclusão no T-SQL aqui.
ORDEM POR NULOS PRIMEIRO | ÚLTIMO NULOS
Quando você solicita dados, seja para fins de apresentação, janelamento, filtragem TOP/OFFSET-FETCH ou qualquer outro propósito, surge a questão de como os NULLs devem se comportar nesse contexto? O padrão SQL diz que os NULLs devem ser classificados antes ou depois dos não-NULLs, e eles deixam para a implementação determinar de uma maneira ou de outra. No entanto, seja qual for a escolha do fornecedor, ele precisa ser consistente. No T-SQL, os NULLs são ordenados primeiro (antes de não NULLs) ao usar a ordem crescente. Considere a seguinte consulta como um exemplo:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate, orderid;
Essa consulta gera a seguinte saída:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06
A saída mostra que os pedidos não enviados, que têm uma data de envio NULL, fazem pedidos antes dos pedidos enviados, que têm uma data de envio aplicável existente.
Mas e se você precisar de NULLs para pedir por último ao usar a ordem crescente? O padrão ISO/IEC SQL suporta uma cláusula que você aplica a uma expressão de ordenação que controla se os NULLs ordenam primeiro ou por último. A sintaxe desta cláusula é:
Para atender a nossa necessidade, devolvendo os pedidos ordenados por suas datas de envio, em ordem crescente, mas com pedidos não enviados retornados por último e, em seguida, por seus IDs de pedido como critério de desempate, você usaria o seguinte código:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate NULLS LAST, orderid;
Infelizmente, esta cláusula de ordenação NULLS não está disponível no T-SQL.
Uma solução comum que as pessoas usam no T-SQL é preceder a expressão de ordenação com uma expressão CASE que retorna uma constante com um valor de ordenação menor para valores não NULL do que para NULLs, assim (chamaremos essa solução de Consulta 1):
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY CASE WHEN shippeddate IS NOT NULL THEN 0 ELSE 1 END, shippeddate, orderid;
Esta consulta gera a saída desejada com NULLs aparecendo por último:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 11008 NULL 11019 NULL 11039 NULL ...
Há um índice de cobertura definido na tabela Sales.Orders, com a coluna data de envio como chave. No entanto, semelhante à maneira como uma coluna de filtragem manipulada impede a SARGability do filtro e a capacidade de aplicar uma busca a um índice, uma coluna de ordenação manipulada impede a capacidade de confiar na ordenação do índice para dar suporte à cláusula ORDER BY da consulta. Portanto, o SQL Server gera um plano para a Consulta 1 com um operador Sort explícito, conforme mostrado na Figura 1.
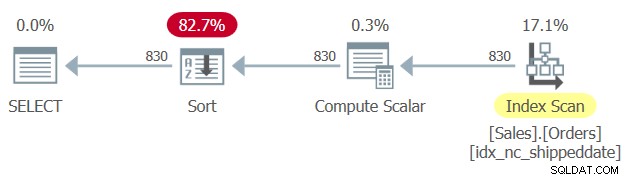 Figura 1:plano para a consulta 1
Figura 1:plano para a consulta 1 Às vezes, o tamanho dos dados não é tão grande para que a classificação explícita seja um problema. Mas às vezes é. Com a classificação explícita, a escalabilidade da consulta se torna extralinear (você paga mais por linha quanto mais linhas tiver) e o tempo de resposta (tempo que leva para a primeira linha ser retornada) é atrasado.
Há um truque que você pode usar para evitar a classificação explícita nesse caso com uma solução que é otimizada usando um operador Merge Join Concatenation que preserva a ordem. Você pode encontrar uma cobertura detalhada dessa técnica empregada em diferentes cenários no SQL Server:Evitando uma classificação com concatenação de junção de mesclagem. A primeira etapa na solução unifica os resultados de duas consultas:uma consulta retornando as linhas em que a coluna de ordenação não é NULL com uma coluna de resultado (chamaremos de sortcol) baseada em uma constante com algum valor de ordenação, digamos 0, e outra consulta retornando as linhas com os NULLs, com sortcol definido como uma constante com um valor de ordenação mais alto do que na primeira consulta, digamos 1. Na segunda etapa, você define uma expressão de tabela com base no código da primeira etapa e, em seguida, na consulta externa, você ordena as linhas da expressão de tabela primeiro por sortcol e, em seguida, pelos elementos de ordenação restantes. Aqui está o código completo da solução implementando essa técnica (chamaremos essa solução de Consulta 2):
WITH C AS ( SELECT orderid, shippeddate, 0 AS sortcol FROM Sales.Orders WHERE shippeddate IS NOT NULL UNION ALL SELECT orderid, shippeddate, 1 AS sortcol FROM Sales.Orders WHERE shippeddate IS NULL ) SELECT orderid, shippeddate FROM C ORDER BY sortcol, shippeddate, orderid;
O plano para esta consulta é mostrado na Figura 2.
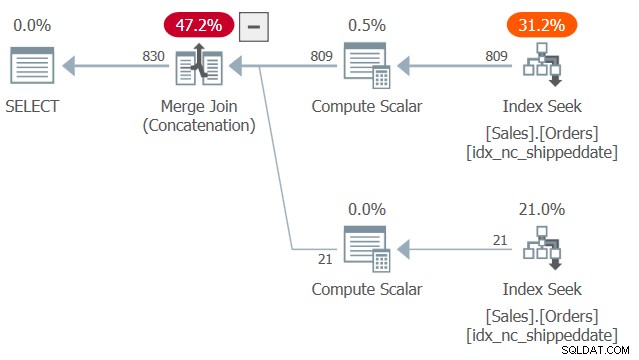 Figura 2:plano para a consulta 2
Figura 2:plano para a consulta 2 Observe duas buscas e varreduras de intervalo ordenadas no índice de cobertura idx_nc_shippeddate — uma puxando as linhas em que datadespachada não é NULL e outra puxando as linhas em que datadespachada é NULA. Então, semelhante à maneira como o algoritmo Merge Join funciona em uma junção, o algoritmo Merge Join (Concatenação) unifica as linhas dos dois lados ordenados de maneira semelhante a um zíper e preserva a ordem ingerida para dar suporte às necessidades de ordenação de apresentação da consulta. Não estou dizendo que essa técnica é sempre mais rápida do que a solução mais típica com a expressão CASE, que emprega classificação explícita. No entanto, o primeiro tem escala linear e o segundo tem escala n log n. Assim, o primeiro tenderá a se sair melhor com grandes números de linhas e o último com números pequenos.
Obviamente, é bom ter uma solução para essa necessidade comum, mas será muito melhor se o T-SQL adicionar suporte para a cláusula de ordenação NULL padrão no futuro.
Conclusão
O padrão ISO/IEC SQL tem muitos recursos de manipulação de NULL que ainda não chegaram ao T-SQL. Neste artigo, abordei alguns deles:o predicado DISTINCT, a cláusula de tratamento NULL e o controle se os NULLs ordenam primeiro ou por último. Também forneci soluções alternativas para esses recursos que são suportados no T-SQL, mas eles são obviamente complicados. No próximo mês, continuarei a discussão abordando a restrição exclusiva padrão, como ela difere da implementação do T-SQL e as soluções alternativas que podem ser implementadas no T-SQL.