"O Waitstats nos ajuda a identificar contadores relacionados ao desempenho. Mas as informações de espera por si só não são suficientes para diagnosticar com precisão os problemas de desempenho. O componente de filas de nossa metodologia vem dos contadores do Monitor de Desempenho, que fornecem uma visão do desempenho do sistema do ponto de vista dos recursos.”
Tom Davidson, Abrindo a caixa de ferramentas de ajuste de desempenho da Microsoft
SQL Server Pro Magazine, dezembro de 2003
Waits and Queues tem sido usado como uma metodologia de ajuste de desempenho do SQL Server desde que Tom Davidson publicou o artigo acima, bem como o conhecido whitepaper de Waits and Queues do SQL Server 2005 em 2006. Quando aplicado em combinação com métricas de recursos, esperas podem ser valiosas para avaliar certas características de desempenho da carga de trabalho e auxiliar nos esforços de ajuste de direção. Os dados de espera são exibidos por muitas soluções de monitoramento de desempenho do SQL Server, e tenho defendido o ajuste usando essa metodologia desde o início. A abordagem foi influente no design do painel de desempenho do SQL Sentry, que apresenta esperas ladeadas por filas (métricas de recursos principais) para fornecer uma visão abrangente do desempenho do servidor.
No entanto, alguns parecem ter perdido o ponto de Davidson em relação à importância dos recursos e dependem quase inteiramente de esperas para apresentar uma imagem do desempenho da consulta e da integridade do sistema. As estatísticas de espera vêm diretamente do mecanismo do SQL Server e são fáceis de consumir e categorizar. Consultas em espera significam aplicativos e usuários em espera, e ninguém gosta de esperar! É mais fácil evangelizar o ajuste com esperas como a solução singular para tornar as consultas e aplicativos mais rápidos do que contar a história completa, que é mais envolvente.
Infelizmente, uma abordagem focada na espera para a exclusão da análise de recursos pode enganar e, na pior das hipóteses, deixá-lo voando às cegas. Os membros da equipe SentryOne, Kevin Kline e Steve Wright, já falaram sobre isso aqui e aqui. Neste post, vou mergulhar mais fundo em algumas pesquisas recentes possibilitadas pelo Query Store que lançou uma nova luz sobre como o ajuste exclusivo de esperas deficiente pode realmente ser.
As principais consultas que não foram
Recentemente, um cliente do SentryOne entrou em contato comigo sobre problemas de desempenho com seu banco de dados do SentryOne. Há um único banco de dados SQL Server no centro de cada ambiente de monitoramento SentryOne, e esse cliente estava monitorando cerca de 600 servidores com nosso software. Nessa escala, não é incomum ver o problema ocasional de desempenho de consulta e fazer um pequeno ajuste, e algumas consultas supostamente novas na carga de trabalho foram a fonte de sua preocupação.
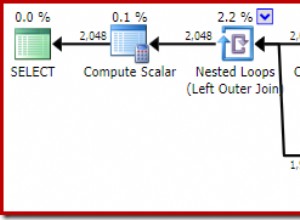
Entrei em uma sessão de compartilhamento de tela para dar uma olhada, e o cliente primeiro me apresentou dados de um sistema diferente que também estava monitorando o banco de dados SentryOne. O sistema usou uma abordagem de esperas em nível de consulta e mostrou dois procedimentos armazenados como responsáveis por aproximadamente metade das esperas no servidor de banco de dados SQL Sentry. Isso era incomum porque esses dois procedimentos sempre são executados muito rapidamente e nunca foram indicativos de um problema real de desempenho em nosso banco de dados. Intrigado, mudei para o SQL Sentry para ver o que ele nos mostraria, e fiquei surpreso ao ver que no mesmo intervalo o procedimento #1 no outro sistema era #6, #7 e #8 em termos de duração total, CPU e leituras lógicas, respectivamente:
 Visão “Top SQL” do SQL Sentry
Visão “Top SQL” do SQL Sentry Do ponto de vista do consumo de recursos, isso significava que as consultas acima representavam 75% da duração total, 87% da CPU total e 88% das leituras lógicas. Além disso, o procedimento nº 2 no outro sistema não estava nem entre os 30 primeiros no SQL Sentry, de forma alguma! Essas duas consultas estavam longe das 2 principais, e as consultas que representavam a maior parte dos reais consumo no sistema estavam sendo severamente sub-representados.
Sempre presumi que havia uma correlação mais forte entre os melhores garçons e os principais consumidores de recursos, mas nunca havia realizado uma comparação direta no nível de consulta como essa, portanto, esses resultados foram surpreendentes, para dizer o mínimo. Despertou meu interesse, decidi investigar para determinar se essa situação era típica ou anômala.
Reserva de consultas 2017 para o resgate
No SQL Server 2017 e superior, o Repositório de Consultas captura esperas em nível de consulta, além do consumo de recursos de consulta. Erin Stellato fez um ótimo post sobre o Query Store Waits aqui. É uma sobrecarga menor e mais precisa do que a consulta espera DMVs a cada segundo na esperança de capturar consultas em andamento, a abordagem padrão usada por outras ferramentas, incluindo a mencionada anteriormente.
O SQL Sentry sempre capturou esperas, mas no nível de instância do SQL Server, devido a essas preocupações sobre sobrecarga e precisão. As esperas de consulta detalhadas estão disponíveis sob demanda por meio do Plan Explorer integrado e estamos avaliando o aumento das esperas no nível da instância com dados no nível da consulta do Query Store, quando disponíveis.
Para esse empreendimento, recrutei a ajuda do SentryOne Product Advisory Council, um grupo de clientes, parceiros e amigos do SentryOne do setor que participam de um canal privado do Slack. Compartilhei este script para despejar as 8 horas anteriores de dados do Query Store e recebi os resultados de volta para 11 servidores de produção em vários setores, incluindo serviços financeiros, publicação de jogos, rastreamento de condicionamento físico e seguro.
As categorias de espera do Repositório de Consultas são documentadas aqui. Todas as categorias foram incluídas na análise, exceto estas, que foram removidas pelos motivos citados:
- Paralelismo – Ele pode inflar descontroladamente o tempo de espera de uma consulta muito além de sua duração real, pois vários encadeamentos podem eliminar as esperas associadas, confundindo a correlação com a duração e outras métricas. Além disso, embora a divisão CXPACKET/CXCONSUMER seja útil, CXPACKET ainda significa apenas que você tem paralelismo e não é necessariamente problemático ou acionável.
- CPU – O tempo de espera do sinal pode ser útil para determinar gargalos de CPU por meio da correlação com esperas de recursos, mas o Repositório de Consultas atualmente inclui apenas SOS_SCHEDULER_YIELD nesta categoria, que não é uma espera no sentido tradicional, conforme abordado aqui. Não se presta a fácil comparação ou correlação, especialmente quando o SQL Server está em uma VM que reside em um host com excesso de assinatura. Por exemplo, em um servidor, as esperas de CPU do Query Store foram 227% do tempo total de CPU em todas as consultas sem qualquer paralelismo, o que não deveria ser possível.
- Aguarda do usuário e Inativo – Essas categorias são compostas exclusivamente por timer e fila waits e foram excluídas pelo mesmo motivo que se deve sempre excluir esses tipos – são inócuos e apenas criam ruído.
Como um aparte, conversei recentemente com o pai da Query Store, Conor Cunningham, sobre a probabilidade de futuras alterações nos tipos e categorias de espera da Query Store e ele indicou que certamente era possível... isto.
Resultados da Análise TL;DR
Após extensa análise, confirmei que os resultados observados no sistema do cliente não são anômalos, mas sim comuns. Isso significa que, se você depende de uma ferramenta focada em esperas para monitorar e ajustar suas cargas de trabalho, há uma grande probabilidade de estar se concentrando nas consultas erradas e perdendo os responsáveis pela maioria da duração da consulta e do consumo de recursos em um sistema. Como o consumo de CPU e E/S se traduz diretamente em hardware de servidor e gastos em nuvem, isso é significativo.
A maioria das consultas não espera
Uma descoberta interessante e importante que abordarei primeiro é que a maioria das consultas não gera nenhuma espera. Do total de 56.438 consultas em todos os servidores, apenas 9.781 (17%) tiveram algum tempo de espera e apenas 8.092 (14%) tiveram tempo de espera de tipos significativos. Se você estiver usando esperas isoladas para determinar quais consultas otimizar, perderá a maioria das consultas na carga de trabalho.
Correlacionando esperas e recursos
Analisei como as esperas se relacionam com o consumo de recursos classificando todas as consultas em cada sistema por esperas e recursos e usando as classificações para calcular uma correlação de Spearman. O que estamos tentando determinar é se os melhores garçons tendem a ser os principais consumidores. Como se vê, eles não.
Tabela 1 mostra os coeficientes de correlação em escala de cores para espera média de consulta hora para outras medidas – um valor de 1,00 (azul escuro) representa dados perfeitamente correlacionados. Como você pode ver, a correlação com esperas e outras medidas na maioria dos servidores não é forte e, para um servidor, há uma correlação negativa com a maioria das medidas.
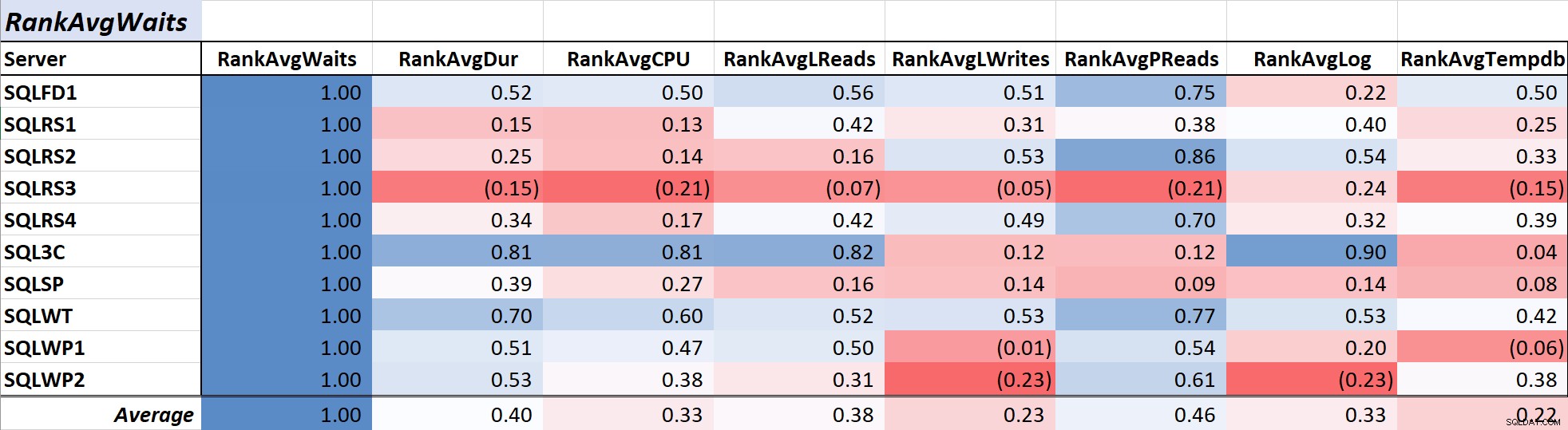 Tabela 1:Correlação com o tempo médio de espera da consulta (ms)
Tabela 1:Correlação com o tempo médio de espera da consulta (ms) A duração da consulta geralmente é a principal preocupação para DBAs e desenvolvedores, pois se traduz diretamente na experiência do usuário e Tabela 2 mostra a correlação entre a duração média da consulta e as demais medidas. A correlação com a duração e as duas medidas de recursos primários, CPU e leituras lógicas, é bastante forte em 0,97 e 0,75, respectivamente.
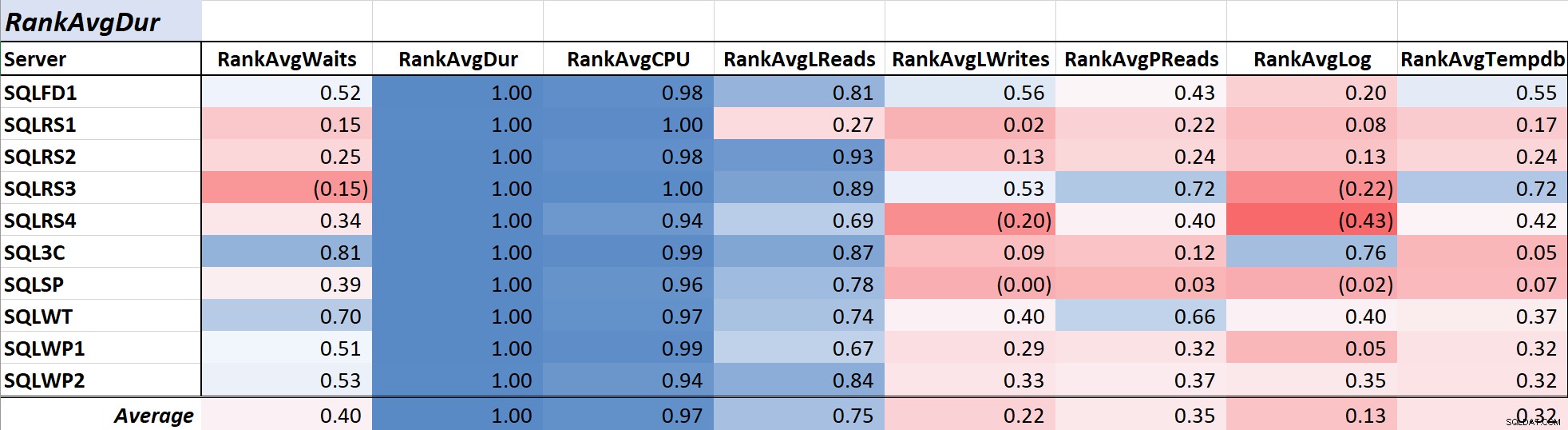 Tabela 2:Correlação com a duração média da consulta (ms)
Tabela 2:Correlação com a duração média da consulta (ms) Como as leituras lógicas sempre usam CPU e, como a duração, a CPU é medida em milissegundos, essa relação não é surpreendente. Os resultados são consistentes com a ideia de que, se você deseja que seus aplicativos de banco de dados sejam executados o mais rápido possível, focar na redução da CPU de consulta e leituras lógicas será mais eficaz na redução da duração do que usar apenas esperas. Felizmente, fazer isso por meio de um melhor design de consulta, indexação etc. geralmente é uma proposta mais direta do que reduzir o tempo de espera de consulta diretamente. O colega Aaron Bertrand apresenta efetivamente algumas das advertências ao sintonizar com esperas aqui.
% do tempo total de espera
Em seguida, verifiquei se as consultas com o maior tempo de espera tendem a representar o maior consumo de recursos. Queremos determinar se o que vimos no sistema do cliente é atípico, onde as 2 principais consultas em espera representavam uma porcentagem relativamente pequena do consumo total de recursos.
Gráfico 1 abaixo mostra a % do total de CPU e leituras lógicas para cada servidor contabilizado pelas consultas representando 75% do tempo total de espera. Apenas um servidor tinha um recurso superior a 75% – lê-se no SQLRS3. De resto, as consultas responsáveis por 75% do tempo de espera consumiram menos de 75% dos recursos – muitas vezes muito menos. Isso reflete o que vimos no sistema do cliente e é consistente com a análise de correlação.
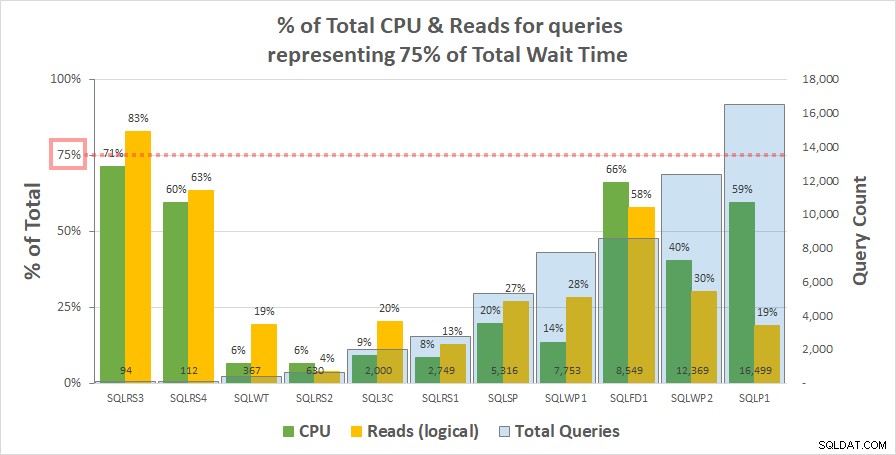 Gráfico 1
Gráfico 1 Observe que parece haver uma relação com o número total de consultas na carga de trabalho. Isso é representado pela série de colunas azul claro no eixo y secundário e o gráfico é classificado em ordem crescente por essa série. Os dois servidores com as medidas de recursos mais altas com 75% de esperas também tiveram o menor número de consultas (SQLRS3 e SQLRS4). Quanto menor o conjunto de carga de trabalho, maior a influência potencial de um pequeno número de consultas e, com certeza, em ambos os servidores, apenas duas consultas representaram a maioria das esperas e recursos. Uma maneira de ver isso é que as esperas ajudam mais a identificar suas consultas mais pesadas quando você menos precisa.
Tempo de espera e duração da consulta
Por fim, avaliei a % do tempo total de espera para a duração total da consulta em cada sistema. Tabela 3 tem colunas para:
- Duração total da consulta em ms
- Tempo total de espera ms – bruto
- Tempo total de espera ms – sem paralelismo, inatividade e esperas do usuário (Rev1)
- Tempo total de espera ms – sem paralelismo, inatividade, esperas do usuário e CPU (Rev2)
- A % de duração das 3 colunas de tempo de espera, com barras de dados
- Contagem total de consultas exclusivas, com barras de dados
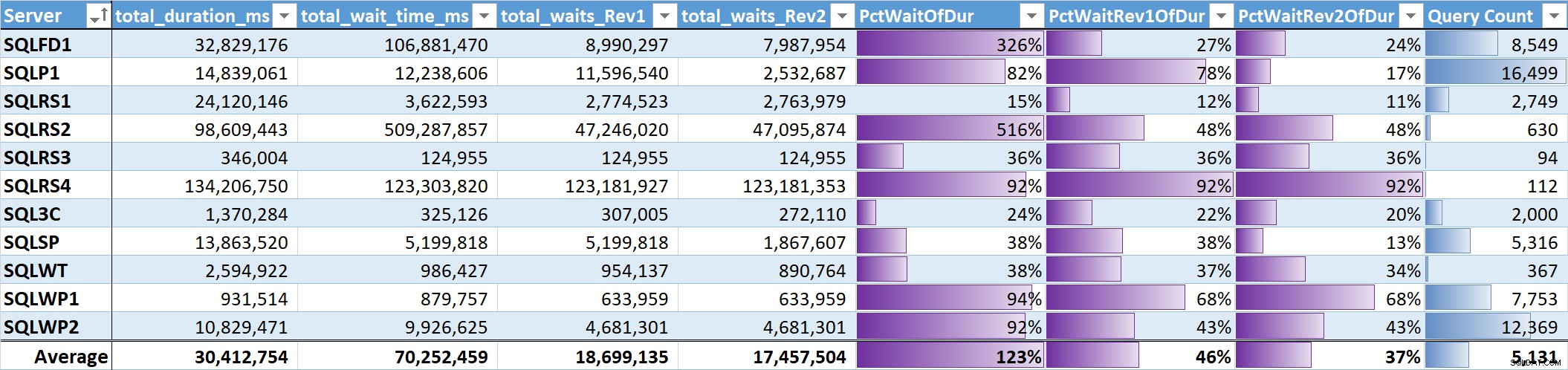 Tabela 3
Tabela 3 A média não ponderada das esperas significativas (Rev2) em todos os sistemas é 37% da duração total da consulta. Em cinco dos sistemas foi inferior a 25%, e em apenas dois sistemas foi superior a 50%. No sistema com 92% de tempo de espera (SQLRS4), um com o menor número de consultas, duas consultas foram responsáveis por 99% das esperas, 97% da duração, 84% da CPU e 86% das leituras.
Embora o tempo de espera possa representar uma parte significativa do tempo de execução da consulta em determinados sistemas, e pareça intuitivo que, se você reduzir o tempo de espera, a duração da consulta também diminuirá, vimos que o tempo de espera e a duração estão fracamente correlacionados. É improvável que seja tão simples, e minha própria experiência corrobora isso. Mais pesquisas são necessárias aqui.
Ajuste abrangente com o Plan Explorer e o SQL Sentry
Como este excelente whitepaper sobre SQLskills sugere frequentemente, a raiz das altas esperas geralmente são consultas e índices não otimizados. O SentryOne Plan Explorer gratuito foi desenvolvido especificamente para reduzir o consumo de recursos por meio de um ajuste de consulta eficiente usando seu módulo de análise de índice e muitos outros recursos inovadores. O SQL Sentry integra o Plan Explorer diretamente aos módulos Top SQL, Blocking e Deadlocks, para que você possa capturar e ajustar automaticamente consultas problemáticas em um só lugar. Você pode selecionar facilmente um intervalo de interesse nos gráficos de espera, CPU ou IO do painel SQL Sentry e pular para a visualização Top SQL para encontrar as principais consultas que consomem recursos durante esse período. Em seguida, com um único clique, você pode abrir uma consulta no Plan Explorer e obter esperas detalhadas em nível de consulta e recursos sob demanda quando necessário. Não acho que exista uma melhor incorporação da metodologia completa de ajuste de Waits and Queues do que essa.
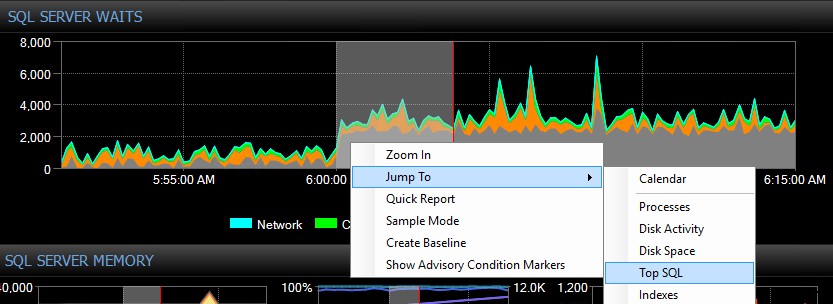 Gráfico de “Aguardas” do SQL Sentry Dashboard
Gráfico de “Aguardas” do SQL Sentry Dashboard 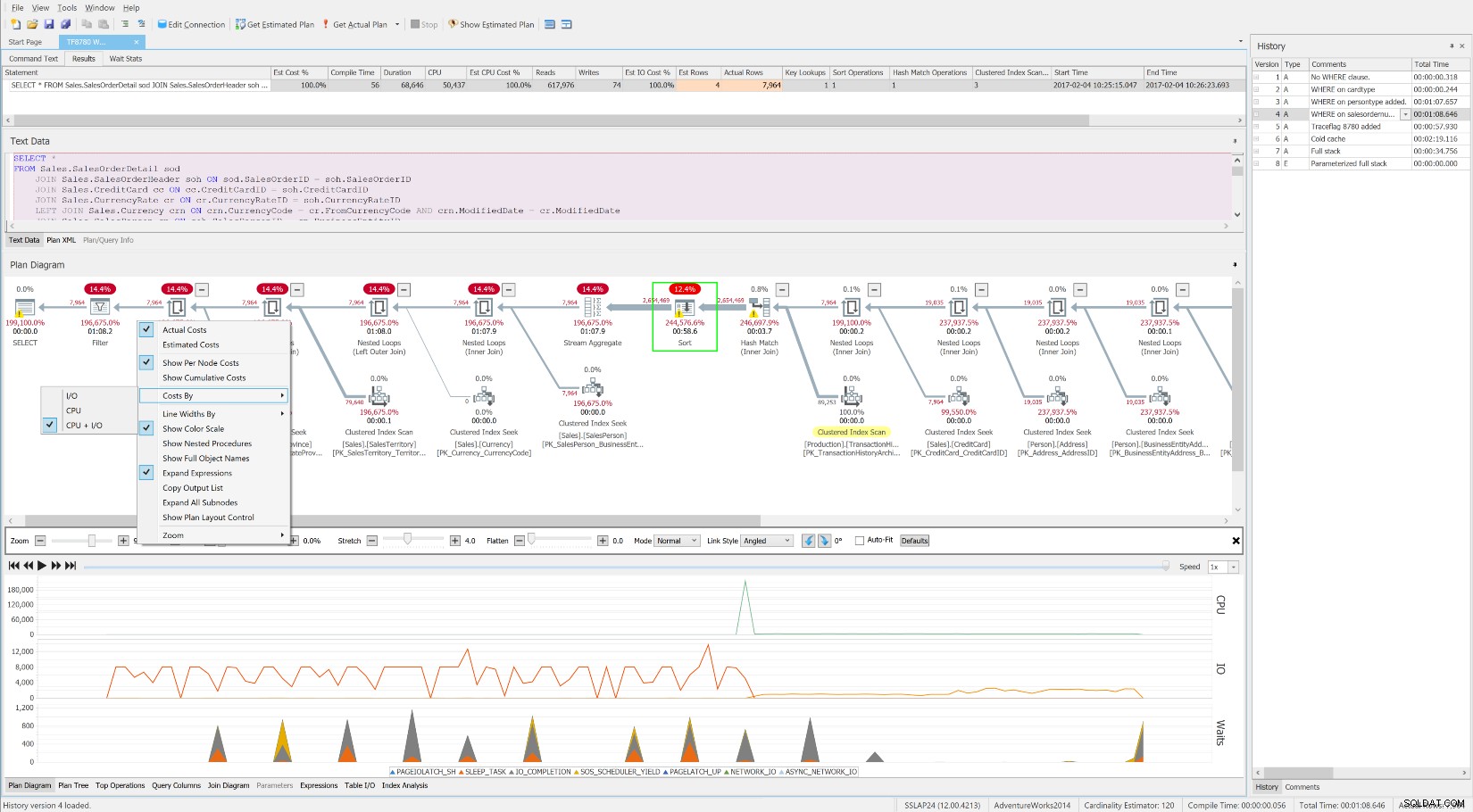 O SentryOne Plan Explorer gratuito mostrando esperas ao longo do tempo, juntamente com o nível de operação custos e recursos
O SentryOne Plan Explorer gratuito mostrando esperas ao longo do tempo, juntamente com o nível de operação custos e recursos Conclusão
O ajuste com esperas e filas é tão aplicável ao desempenho do SQL Server hoje quanto era em 2006. No entanto, focar em esperas com exclusão de recursos é um negócio perigoso, pois fica claro pelos dados que isso levará a sistemas de baixo custo. Quando se trata de recursos de hardware e gastos na nuvem, você está pagando por recursos de computação e E/S, não pelo tempo de espera, por isso é conveniente otimizar diretamente para consumo. Na minha experiência, à medida que o consumo de recursos e a contenção relacionada são reduzidos, o tempo de espera reduzido ocorrerá naturalmente.
Agradecimento
Gostaria de agradecer a Fred Frost, Cientista de Dados Líder da SentryOne, por sua valiosa contribuição e revisão crítica desta análise.