Este post faz parte de uma série sobre metas de linha. Você pode encontrar as outras partes aqui:
- Parte 1:definindo e identificando metas de linha
- Parte 2:Semijunções
- Parte 3:Antijunções
Aplicar o Anti Join com um operador principal
Muitas vezes, você verá um operador Top (1) do lado interno em aplicar antijunção planos de execução. Por exemplo, usando o banco de dados AdventureWorks:
SELECT P.ProductID
FROM Production.Product AS P
WHERE
NOT EXISTS
(
SELECT 1
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); O plano mostra um operador Top (1) no lado interno da antijunção de aplicação (referências externas):
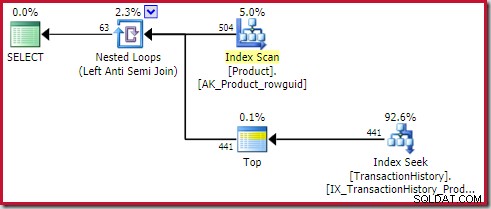
Este operador Top é completamente redundante . Não é necessário para correção, eficiência ou para garantir que uma meta de linha seja definida.
O operador apply anti join irá parar de verificar as linhas no lado interno (para a iteração atual) assim que uma linha for vista na junção. É perfeitamente possível gerar um plano de aplicação anti-junção sem o Top. Então, por que há um operador Top neste plano?
Fonte do operador principal
Para entender de onde vem esse operador Top inútil, precisamos seguir as principais etapas realizadas durante a compilação e otimização de nossa consulta de exemplo.
Como de costume, a consulta é primeiro analisada em uma árvore. Isso apresenta um operador lógico 'não existe' com uma subconsulta, que corresponde à forma escrita da consulta neste caso:

A subconsulta não existe é desenrolada em uma antijunção de aplicação:

Isso é então transformado em uma anti-semi-junção à esquerda lógica. A árvore resultante passada para a otimização baseada em custo se parece com isso:

A primeira exploração realizada pelo otimizador baseado em custo é introduzir uma lógica distinta operação na entrada antijunção inferior, para produzir valores exclusivos para a chave antijunção. A ideia geral é que, em vez de testar valores duplicados na junção, o plano pode se beneficiar ao agrupar esses valores antecipadamente.
A regra de exploração responsável é chamada LASJNtoLASJNonDist (anti semi-junção esquerda para anti-semi-junção esquerda em distinto). Nenhuma implementação física ou custeio foi realizada ainda, então este é apenas o otimizador explorando uma equivalência lógica, com base na presença de ProductID duplicado valores. A nova árvore com a operação de agrupamento adicionada é mostrada abaixo:

A próxima transformação lógica considerada é reescrever a junção como um aplicar . Isso é explorado usando a regra LASJNtoApply (esquerda anti semijunção para aplicar com seleção relacional). Conforme mencionado anteriormente na série, a transformação anterior de aplicação para junção foi para habilitar transformações que funcionam especificamente em junções. Sempre é possível reescrever uma junção como uma aplicação, então isso expande o leque de otimizações disponíveis.
Agora, o otimizador nem sempre considere uma reescrita de aplicação como parte da otimização baseada em custo. Tem que haver algo na árvore lógica para fazer valer a pena empurrar o predicado de junção para o lado interno. Normalmente, isso será a existência de um índice de correspondência, mas existem outros alvos promissores. Nesse caso, é a chave lógica em ProductID criado pela operação agregada.
O resultado desta regra é um antijoin correlacionado com a seleção no lado interno:

Em seguida, o otimizador considera mover a seleção relacional (o predicado de junção correlacionada) mais abaixo no lado interno, além do distinto (grupo por agregado) introduzido anteriormente pelo otimizador. Isso é feito pela regra SelOnGbAgg , que move o máximo possível de uma seleção (predicado) além de um grupo adequado por agregado (parte da seleção pode ser deixada para trás). Esta atividade ajuda a enviar seleções o mais próximo possível dos operadores de acesso a dados em nível de folha, para eliminar as linhas mais cedo e facilitar a correspondência de índice posterior.
Nesse caso, o filtro está na mesma coluna que a operação de agrupamento, portanto, a transformação é válida. Isso resulta em toda a seleção sendo empurrada para o agregado:

A operação final de interesse é realizada pela regra GbAggToConstScanOrTop . Essa transformação procura substituir um grupo por agregado com Constant Scan ou Top operação lógica. Essa regra corresponde à nossa árvore porque a coluna de agrupamento é constante para cada linha que passa pela seleção pressionada. Todas as linhas têm a mesma garantia de ProductID . O agrupamento nesse valor único sempre produzirá uma linha. Portanto, é válido transformar o agregado em um Top (1). Então é daí que vem o topo.
Implementação e custeio
O otimizador agora executa uma série de regras de implementação para encontrar operadores físicos para cada uma das alternativas lógicas promissoras que considerou até agora (armazenadas de forma eficiente em uma estrutura de memorando). As opções físicas anti-junção de hash e mesclagem vêm da árvore inicial com agregação introduzida (cortesia da regra LASJNtoLASJNonDist lembrar). A aplicação precisa de um pouco mais de trabalho para construir um top físico e combinar a seleção com uma busca de índice.
A melhor anti-junção de hash solução encontrada custa 0,362143 unidades:
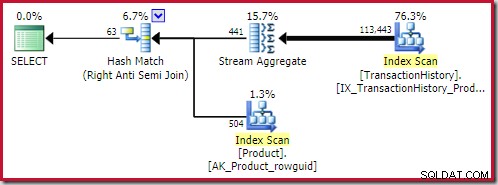
O melhor anti-junção de mesclagem a solução chega a 0,353479 unidades (um pouco mais barato):
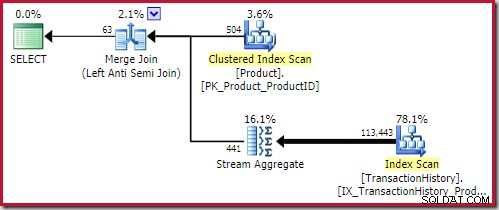
O aplicar anti-junção custa 0,091823 unidades (mais barato por uma ampla margem):
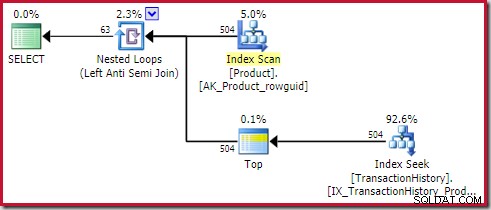
O leitor astuto pode notar que a contagem de linhas no lado interno da aplicação antijunção (504) difere da captura de tela anterior do mesmo plano. Isso porque este é um plano estimado, enquanto o plano anterior era pós-execução. Quando este plano é executado, apenas um total de 441 linhas são encontradas no lado interno em todas as iterações. Isso destaca uma das dificuldades de exibição com a aplicação de planos de semi/anti-junção:A estimativa mínima do otimizador é uma linha, mas uma semi ou anti-junção sempre localizará uma linha ou nenhuma linha em cada iteração. As 504 linhas mostradas acima representam 1 linha em cada uma das 504 iterações. Para fazer os números corresponderem, a estimativa precisaria ser 441/504 =0,875 linhas de cada vez, o que provavelmente confundiria as pessoas.
De qualquer forma, o plano acima tem 'sorte' o suficiente para se qualificar para uma meta de linha no lado interno da aplicação anti-junção por dois motivos:
- A antijunção é transformada de uma junção em uma aplicação no otimizador baseado em custo. Isso define uma meta de linha (conforme estabelecido na parte três).
- O operador Top(1) também define uma meta de linha em sua subárvore.
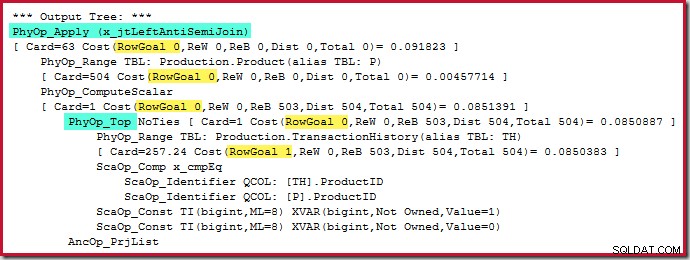
O próprio operador Top não tem uma meta de linha (do apply), pois a meta de linha de 1 não seria menor do que a estimativa normal, que também é 1 linha (Card=1 para PhyOp_Top abaixo):
O padrão anti-junção
A seguinte forma de plano geral é uma que considero um antipadrão:
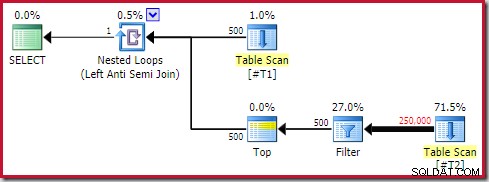
Nem todo plano de execução contendo uma aplicação anti-junção com um operador Top (1) em seu lado interno será problemático. No entanto, é um padrão a reconhecer e que quase sempre requer uma investigação mais aprofundada.
Os quatro principais elementos a serem observados são:
- Um loop aninhado correlacionado (aplicar ) anti-junção
- Um Top (1) operador imediatamente no lado interno
- Um número significativo de linhas na entrada externa (para que o lado interno seja executado muitas vezes)
- Um potencialmente caro subárvore abaixo do topo
A subárvore "$$$" é potencialmente cara em tempo de execução . Isso pode ser difícil de reconhecer. Se tivermos sorte, haverá algo óbvio como uma tabela completa ou varredura de índice. Em casos mais desafiadores, a subárvore parecerá perfeitamente inocente à primeira vista, mas conterá algo caro quando observada mais de perto. Para dar um exemplo bastante comum, você pode ver um Index Seek que deve retornar um pequeno número de linhas, mas que contém um predicado residual caro que testa um número muito grande de linhas para encontrar as poucas que se qualificam.
O exemplo de código AdventureWorks anterior não tinha uma subárvore "potencialmente cara". A Busca de Índice (sem predicado residual) seria um método de acesso ideal, independentemente das considerações de meta de linha. Este é um ponto importante:fornecer ao otimizador uma ferramenta sempre eficiente caminho de acesso a dados no lado interno de uma junção correlacionada é sempre uma boa ideia. Isso é ainda mais verdadeiro quando o apply está sendo executado no modo antijoin com um operador Top (1) no lado interno.
Vejamos agora um exemplo que tem um desempenho de tempo de execução bastante desanimador devido a esse antipadrão.
Exemplo
O script a seguir cria duas tabelas temporárias de heap. A primeira tem 500 linhas contendo os inteiros de 1 a 500 inclusive. A segunda tabela tem 500 cópias de cada linha da primeira tabela, totalizando 250.000 linhas. Ambas as tabelas usam a
sql_variant tipo de dados. DROP TABLE IF EXISTS #T1, #T2;
CREATE TABLE #T1 (c1 sql_variant NOT NULL);
CREATE TABLE #T2 (c1 sql_variant NOT NULL);
-- Numbers 1 to 500 inclusive
-- Stored as sql_variant
INSERT #T1
(c1)
SELECT
CONVERT(sql_variant, SV.number)
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 500;
-- 500 copies of each row in table #T1
INSERT #T2
(c1)
SELECT
T1.c1
FROM #T1 AS T1
CROSS JOIN #T1 AS T2;
-- Ensure we have the best statistical information possible
CREATE STATISTICS sc1 ON #T1 (c1) WITH FULLSCAN, MAXDOP = 1;
CREATE STATISTICS sc1 ON #T2 (c1) WITH FULLSCAN, MAXDOP = 1; Desempenho
Agora executamos uma consulta procurando linhas na tabela menor que não estão presentes na tabela maior (é claro que não há nenhuma):
SELECT
T1.c1
FROM #T1 AS T1
WHERE
NOT EXISTS
(
SELECT 1
FROM #T2 AS T2
WHERE T2.c1 = T1.c1
); Esta consulta é executada por cerca de 20 segundos , que é muito tempo para comparar 500 linhas com 250.000. O plano estimado do SSMS torna difícil ver por que o desempenho pode ser tão ruim:
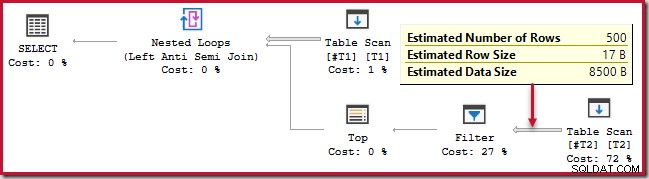
O observador precisa estar ciente de que os planos estimados do SSMS mostram estimativas internas por iteração da junção de loop aninhado. Confusamente, os planos reais do SSMS mostram o número de linhas em todas as iterações . O Plan Explorer executa automaticamente os cálculos simples necessários para que os planos estimados também mostrem o número total de linhas esperado:
Mesmo assim, o desempenho do tempo de execução é muito pior do que o estimado. O plano de execução pós-execução (real) é:
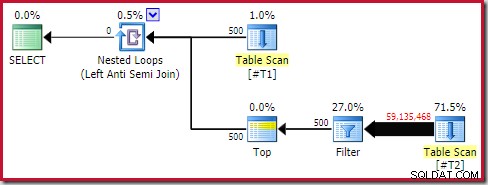
Observe o Filtro separado, que normalmente seria empurrado para baixo na varredura como um predicado residual. Esta é a razão para usar o
sql_variant tipo de dados; ele impede o envio do predicado, o que facilita a visualização do grande número de linhas da varredura. Análise
A razão para a discrepância se resume a como o otimizador estima o número de linhas que ele precisará ler da Verificação de Tabela para atingir a meta de uma linha definida no Filtro. A suposição simples é que os valores são distribuídos uniformemente na tabela, portanto, para encontrar 1 dos 500 valores exclusivos presentes, o SQL Server precisará ler 250.000 / 500 =500 linhas. Mais de 500 iterações, isso chega a 250.000 linhas.
A suposição de uniformidade do otimizador é geral, mas não funciona bem aqui. Você pode ler mais sobre isso em A Row Goal Request de Joe Obbish e votar em sua sugestão no fórum de feedback de substituição do Connect em Use More Than Density to Cost a Scan on the Inner Side of a Nested Loop with TOP.
Minha opinião sobre esse aspecto específico é que o otimizador deve recuar rapidamente de uma simples suposição de uniformidade quando o operador está no lado interno de uma junção de loops aninhados (ou seja, retrocessos estimados mais religações são maiores que um). Uma coisa é supor que precisamos ler 500 linhas para encontrar uma correspondência na primeira iteração do loop. Assumir isso em cada iteração parece terrivelmente improvável de ser preciso; significa que as primeiras 500 linhas encontradas devem conter um de cada valor distinto. É altamente improvável que isso aconteça na prática.
Uma série de eventos infelizes
Independentemente da forma como os operadores principais repetidos são custeados, parece-me que toda a situação deve ser evitada em primeiro lugar . Lembre-se de como o Top neste plano foi criado:
- O otimizador introduziu um agregado distinto interno como uma otimização de desempenho .
- Esse agregado fornece uma chave na coluna de junção por definição (produz exclusividade).
- Essa chave construída fornece um destino para a conversão de uma junção para uma aplicação.
- O predicado (seleção) associado à aplicação é empurrado para baixo além da agregação.
- Agora é garantido que o agregado esteja operando em um único valor distinto por iteração (já que é um valor de correlação).
- O agregado é substituído por um Top (1).
Todas essas transformações são válidas individualmente. Eles fazem parte das operações normais do otimizador, pois ele procura um plano de execução razoável. Infelizmente, o resultado aqui é que o agregado especulativo introduzido pelo otimizador acaba sendo transformado em um Top (1) com uma meta de linha associada . A meta de linha leva ao cálculo de custos impreciso com base na suposição de uniformidade e, em seguida, à seleção de um plano que provavelmente não terá um bom desempenho.
Agora, pode-se objetar que a antijunção aplicada teria um objetivo de linha de qualquer maneira – sem a sequência de transformação acima. O contra-argumento é que o otimizador não consideraria transformação de anti join para apply anti join (definindo o objetivo da linha) sem o agregado introduzido pelo otimizador fornecendo o LASJNtoApply governar algo a que se ligar. Além disso, vimos (na parte três) que, se a antijunção tivesse inserido a otimização baseada em custo como uma aplicação (em vez de uma junção), novamente não haveria nenhuma meta de linha .
Em resumo, o objetivo de linha no plano final é totalmente artificial e não tem base na especificação de consulta original. O problema com o objetivo de cima e linha é um efeito colateral desse aspecto mais fundamental.
Soluções alternativas
Existem muitas soluções potenciais para este problema. A remoção de qualquer uma das etapas na sequência de otimização acima garantirá que o otimizador não produza uma implementação de aplicação antijunção com custos drasticamente (e artificialmente) reduzidos. Espero que esse problema seja resolvido no SQL Server mais cedo ou mais tarde.
Enquanto isso, meu conselho é tomar cuidado com o padrão anti-junção. Certifique-se de que o lado interno de uma aplicação antijunção sempre tenha um caminho de acesso eficiente para todas as condições de tempo de execução. Se isso não for possível, talvez seja necessário usar dicas, desabilitar metas de linha, usar um guia de plano ou forçar um plano de armazenamento de consultas para obter um desempenho estável de consultas anti-associação.
Resumo da série
Cobrimos muito terreno ao longo das quatro parcelas, então aqui está um resumo de alto nível:
- Parte 1 – Definindo e identificando metas de linha
- A sintaxe da consulta não determina a presença ou ausência de uma meta de linha.
- Uma meta de linha só é definida quando a meta é menor que a estimativa normal.
- Os operadores físicos principais (incluindo aqueles introduzidos pelo otimizador) adicionam uma meta de linha à subárvore.
- Um
FASTouSET ROWCOUNTA instrução define uma meta de linha na raiz do plano. - Semi-associação e anti-associação podem adicione uma meta de linha.
- SQL Server 2017 CU3 adiciona o atributo showplan EstimateRowsWithoutRowGoal para operadores afetados por uma meta de linha
- As informações de meta de linha podem ser reveladas por sinalizadores de rastreamento não documentados 8607 e 8612.
- Parte 2 – Semijunções
- Não é possível expressar uma semijunção diretamente no T-SQL, então usamos sintaxe indireta, por exemplo.
IN,EXISTS, ouINTERSECT. - Essas sintaxes são analisadas em uma árvore contendo uma aplicação (junção correlacionada).
- O otimizador tenta transformar a aplicação em uma junção regular (nem sempre é possível).
- Hash, mesclagem e semijunção de loops aninhados regulares não definem uma meta de linha.
- Aplicar semijunção sempre define uma meta de linha.
- A aplicação de semijunção pode ser reconhecida com referências externas no operador de junção de loops aninhados.
- Aplicar semijunção não usa um operador Top (1) no lado interno.
- Parte 3 – Anti-junções
- Também analisado em uma aplicação, com uma tentativa de reescrever isso como uma junção (nem sempre possível).
- Hash, mesclagem e antijunção de loops aninhados regulares não definem uma meta de linha.
- Aplicar antijunção nem sempre define uma meta de linha.
- Somente as regras de otimização baseada em custo (CBO) que transformam a antijunção para aplicar definem uma meta de linha.
- A antijunção deve entrar no CBO como uma junção (não se aplica). Caso contrário, a junção para aplicar a transformação não poderá ocorrer.
- Para entrar no CBO como uma junção, a reescrita pré-CBO de aplicar para junção deve ter sido bem-sucedida.
- A CBO só explora a reescrita de uma antijunção para uma aplicação em casos promissores.
- As simplificações pré-CBO podem ser visualizadas com o sinalizador de rastreamento não documentado 8621.
- Parte 4 – Anti padrão anti-junção
- O otimizador só define uma meta de linha para aplicar antijunção quando há um motivo promissor para isso.
- Infelizmente, várias transformações de otimizador de interação adicionam um operador Top (1) ao lado interno de uma antijunção aplicada.
- O operador Top é redundante; não é necessário para correção ou eficiência.
- O Top sempre define uma meta de linha (ao contrário do apply, que precisa de um bom motivo).
- A meta de linha injustificada pode levar a um desempenho extremamente ruim.
- Cuidado com uma subárvore potencialmente cara sob o topo artificial (1).