Crescendo, eu adorava jogos que testavam memória e habilidades de correspondência de padrões. Vários dos meus amigos tinham Simon, enquanto eu tinha uma imitação chamada Einstein. Outros tinham um Atari Touch Me, que mesmo naquela época eu sabia que era uma decisão de nome questionável. Atualmente, a correspondência de padrões significa algo muito diferente para mim e pode ser uma parte cara das consultas diárias de banco de dados.
Crescendo, eu adorava jogos que testavam memória e habilidades de correspondência de padrões. Vários dos meus amigos tinham Simon, enquanto eu tinha uma imitação chamada Einstein. Outros tinham um Atari Touch Me, que mesmo naquela época eu sabia que era uma decisão de nome questionável. Atualmente, a correspondência de padrões significa algo muito diferente para mim e pode ser uma parte cara das consultas diárias de banco de dados. Recentemente, deparei com alguns comentários no Stack Overflow em que um usuário estava afirmando, como se de fato, que
CHARINDEX tem um desempenho melhor que LEFT ou LIKE . Em um caso, a pessoa citou um artigo de David Lozinski, "SQL:LIKE vs SUBSTRING vs LEFT/RIGHT vs CHARINDEX". Sim, o artigo mostra que, no exemplo artificial, CHARINDEX melhor desempenhou. No entanto, como sempre sou cético em relação a declarações gerais como essa, e não conseguia pensar em uma razão lógica para que uma função de string sempre desempenho melhor do que outro, com todo o resto sendo igual , eu fiz seus testes. Com certeza, tive resultados repetidamente diferentes na minha máquina (clique para ampliar):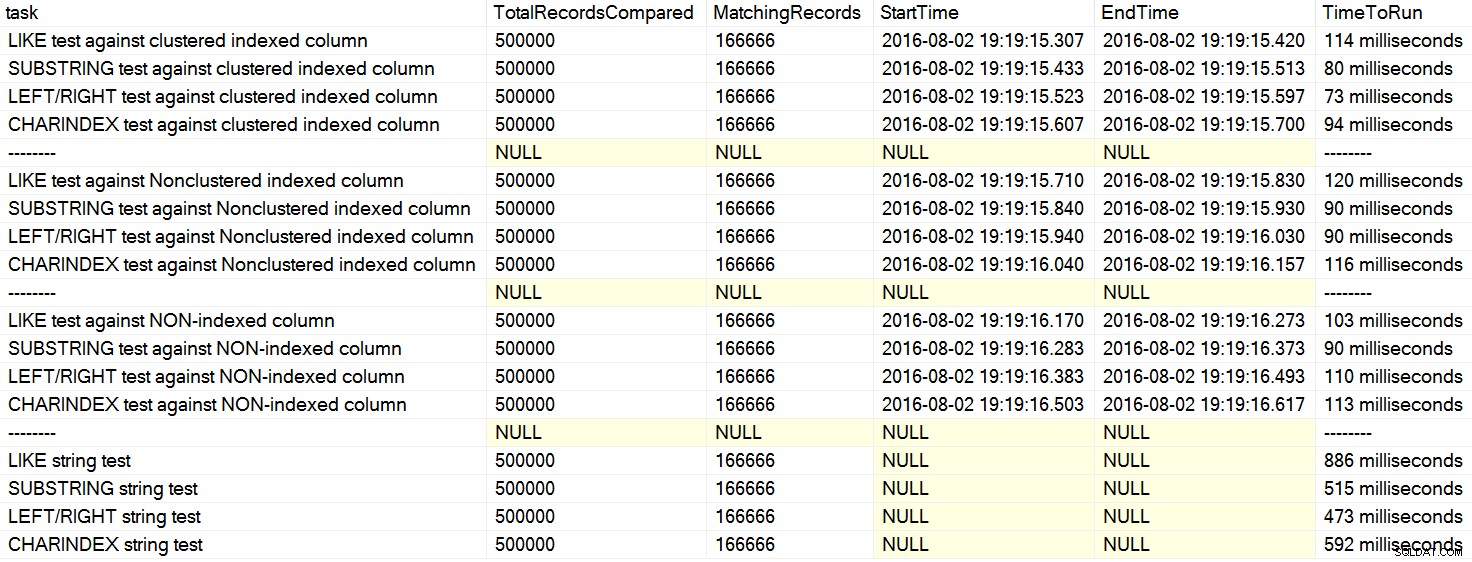 Na minha máquina, CHARINDEX era mais lento do que ESQUERDA/DIREITA/SUBSTRING.
Na minha máquina, CHARINDEX era mais lento do que ESQUERDA/DIREITA/SUBSTRING. Os testes de David estavam basicamente comparando essas estruturas de consulta – procurando um padrão de string no início ou no final de um valor de coluna – em termos de duração bruta:
WHERE Coluna LIKE @pattern + '%' OU Coluna LIKE '%' + @pattern; WHERE SUBSTRING(Column, 1, LEN(@pattern)) =@pattern OR SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)) =@pattern; WHERE LEFT(Column, LEN(@pattern)) =@pattern OR RIGHT(Column, LEN(@pattern)) =@pattern; WHERE CHARINDEX(@pattern, SUBSTRING(Column, 1, LEN(@pattern)), 0)> 0 OR CHARINDEX(@pattern, SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern) )), 0)> 0;
Apenas olhando para essas cláusulas, você pode ver porque
CHARINDEX pode ser menos eficiente – faz várias chamadas funcionais adicionais que as outras abordagens não precisam executar. Por que essa abordagem teve melhor desempenho na máquina de David, não tenho certeza; talvez ele tenha executado o código exatamente como postado e não tenha realmente descartado buffers entre os testes, de modo que os últimos testes se beneficiaram dos dados em cache. Em teoria,
CHARINDEX poderia ter sido expresso de forma mais simples, por exemplo:WHERE CHARINDEX(@pattern, Column) =1 OR CHARINDEX(@pattern, Column) =LEN(Column) - LEN(@pattern) + 1;
(Mas isso realmente teve um desempenho ainda pior em meus testes casuais.)
E por que eles são mesmo
OR condições, não tenho certeza. Realisticamente, na maioria das vezes você está fazendo um dos dois tipos de pesquisa de padrões:começa com ou contém (é muito menos comum procurar por termina com ). E, na maioria desses casos, o usuário tende a declarar antecipadamente se deseja começar com ou contém , pelo menos em todos os aplicativos com os quais estive envolvido em minha carreira. Faz sentido separá-los como tipos separados de consultas, em vez de usar um OU condicional, pois começa com pode fazer uso de um índice (se existir um que seja adequado o suficiente para uma busca, ou seja mais fino que o índice clusterizado), enquanto termina com não pode (e OU condições tendem a jogar chaves no otimizador em geral). Se eu puder confiar LIKE para usar um índice quando possível, e ter um desempenho tão bom ou melhor do que as outras soluções acima na maioria ou em todos os casos, então posso tornar essa lógica muito fácil. Um procedimento armazenado pode ter dois parâmetros – o padrão que está sendo pesquisado e o tipo de pesquisa a ser executada (geralmente há quatro tipos de correspondência de string – começa com, termina com, contém ou correspondência exata).
CREATE PROCEDURE dbo.Search @pattern nvarchar(100), @option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains' -- os dois últimos são suportados, mas não serão testados aquiASBEGIN SET NOCOUNT ON; SELECT ... WHERE Column LIKE -- se contém ou termina com, precisa de um curinga inicial CASE WHEN @option IN ('Contains','EndsWith') THEN N'%' ELSE N'' END + @pattern + -- if contém ou começa com, precisa de um curinga à direita CASE WHEN @option IN ('Contém','Inicia com') THEN N'%' ELSE N'' END OPTION (RECOMPILE); ENDGO Isso trata cada caso potencial sem usar SQL dinâmico; a
OPTION (RECOMPILE) existe porque você não deseja que um plano otimizado para "termina com" (que quase certamente precisará ser verificado) seja reutilizado para uma consulta "começa com" ou vice-versa; também garantirá que as estimativas estejam corretas ("começa com S" provavelmente tem cardinalidade muito diferente de "começa com QX"). Mesmo se você tiver um cenário em que os usuários escolhem um tipo de pesquisa 99% do tempo, você pode usar SQL dinâmico aqui em vez de recompilar, mas nesse caso você ainda estaria vulnerável à detecção de parâmetros. Em muitas consultas de lógica condicional, recompilar e/ou SQL dinâmico completo costumam ser a abordagem mais sensata (veja meu post sobre "a pia da cozinha"). Os testes
Desde que comecei recentemente a olhar para o novo banco de dados de amostra WideWorldImporters, decidi executar meus próprios testes lá. Foi difícil encontrar uma tabela de tamanho decente sem um índice ColumnStore ou uma tabela de histórico temporal, mas
Sales.Invoices , que tem 70.510 linhas, tem um simples nvarchar(20) coluna chamada CustomerPurchaseOrderNumber que decidi usar para os testes. (Por que é nvarchar(20) quando cada valor é um número de 5 dígitos, não tenho ideia, mas a correspondência de padrões não se importa se os bytes abaixo representam números ou strings.) | Vendas.Faturas CustomerPurchaseOrderNumber | ||
|---|---|---|
| Padrão | Nº de linhas | % da Tabela |
| Começa com "1" | 70.505 | 99,993% |
| Começa com "2" | 5 | 0,007% |
| Termina com "5" | 6.897 | 9,782% |
| Termina com "30" | 749 | 1,062% |
Eu vasculhei os valores na tabela para encontrar vários critérios de pesquisa que produziriam números muito diferentes de linhas, esperançosamente para revelar qualquer comportamento de ponto de inflexão com uma determinada abordagem. À direita estão as consultas de pesquisa em que cheguei.
Eu queria provar a mim mesmo que o procedimento acima era inegavelmente melhor em geral para todas as pesquisas possíveis do que qualquer uma das consultas que usam
OR condicionais, independentemente de usarem LIKE , LEFT/RIGHT , SUBSTRING , ou CHARINDEX . Peguei as estruturas básicas de consulta de David e as coloquei em procedimentos armazenados (com a ressalva de que não posso realmente testar "contém" sem a entrada dele e que tive que fazer seu OR logic um pouco mais flexível para obter o mesmo número de linhas), juntamente com uma versão da minha lógica. Também planejei testar os procedimentos com e sem um índice que eu criaria na coluna de pesquisa e em um cache quente e frio. Os procedimentos:
CREATE PROCEDURE dbo.David_LIKE @pattern nvarchar(10), @option varchar(10) -- Começa com ou Termina comASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND CustomerPurchaseOrderNumber LIKE @pattern + N'%') OR (@option ='EndsWith' AND CustomerPurchaseOrderNumber LIKE N'%' + @pattern) OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_SUBSTRING @pattern nvarchar(10), @option varchar(10) -- Começa com ou Termina comASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)) =@pattern) OR (@option ='EndsWith' AND SUBSTRING(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1, LEN(@pattern)) =@pattern) OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_LEFTRIGHT @pattern nvarchar(10), @option varchar(10) -- StartsWith ou EndsWithASBEGIN SET NOCOUNT EM; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) =@pattern) OR (@option ='EndsWith' AND RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) =@pattern) OPÇÃO (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_CHARINDEX @pattern nvarchar(10), @option varchar(10) -- Começa com ou termina com ASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE (@option ='StartsWith' AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)), 0)> 0) OR (@option ='EndsWith' AND CHARINDEX (@pattern, SUBSTRING(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1, LEN(@pattern)), 0)> 0) OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.Aaron_Conditional @pattern nvarchar(10) , @option varchar(10) -- 'Inicia com', 'Termina com', 'ExactMatch', 'Contém'ASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE CustomerPurchaseOrderNumber LIKE -- se contém ou termina com, precisa de um curinga inicial CASE WHEN @option IN ('Contains','EndsWith') THEN N'%' ELSE N'' END + @pattern + -- se contém ou começa com, precisa de um curinga à direita CASE WHEN @option IN ('Contém','Inicia com') THEN N'%' ELSE N'' END OPTION (RECOMPILE); ENDGO Também fiz versões dos procedimentos de David fiéis à sua intenção original, assumindo que o requisito realmente é encontrar quaisquer linhas em que o padrão de pesquisa esteja no início *ou* no final da string. Fiz isso simplesmente para poder comparar o desempenho das diferentes abordagens, exatamente como ele as escreveu, para ver se nesse conjunto de dados meus resultados corresponderiam aos meus testes do script original no meu sistema. Nesse caso, não havia motivo para introduzir uma versão minha, pois ela simplesmente corresponderia ao seu
LIKE % + @pattern OR LIKE @pattern + % variação. CREATE PROCEDURE dbo.David_LIKE_Original @pattern nvarchar(10)ASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE CustomerPurchaseOrderNumber LIKE @pattern + N'%' OR CustomerPurchaseOrderNumber LIKE N'%' + @pattern OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_SUBSTRING_Original @pattern nvarchar(10)ASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)) =@pattern OR SUBSTRING(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1, LEN(@pattern)) =@ pattern OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_LEFTRIGHT_Original @pattern nvarchar(10)ASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) =@pattern OR RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) =@pattern OPTION (RECOMPILE);ENDGO CREATE PROCEDURE dbo.David_CHARINDEX_Original @pattern nvarchar (10)ASBEGIN SET NOCOUNT ON; SELECT CustomerPurchaseOrderNumber, OrderID FROM Sales.Invoices WHERE CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1, LEN(@pattern)), 0)> 0 OR CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) ) + 1, LEN(@pattern)), 0)> 0 OPÇÃO (RECOMPILE);ENDGO
Com os procedimentos implementados, pude gerar o código de teste – o que geralmente é tão divertido quanto o problema original. Primeiro, uma tabela de log:
DROP TABLE SE EXISTE dbo.LoggingTable;GOSET NOCOUNT ON; CREATE TABLE dbo.LoggingTable( LogID int IDENTITY(1,1), prc sysname, opt varchar(10), pattern nvarchar(10), frame varchar(11), duração int, LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME());
Em seguida, o código que realizaria operações de seleção usando os vários procedimentos e argumentos:
SET NOCOUNT ON;;WITH prc(name) AS (SELECT name FROM sys.procedures WHERE LEFT(name,5) IN (N'David', N'Aaron')),args(opt,pattern) AS (SELECT 'StartsWith', N' 1' UNION ALL SELECT 'Começa com', N'2' UNION ALL SELECT 'Termina com', N'5' UNION ALL SELECT 'Termina com', N'30'), frame(w) AS ( SELECT 'BeforeIndex' UNION ALL SELECT 'AfterIndex'),y AS( -- comente as linhas 2-4 aqui se quisermos cache quente SELECT cmd ='GO DBCC FREEPROCCACHE() WITH NO_INFOMSGS; DBCC DROPCLEANBUFFERS() WITH NO_INFOMSGS; GO DECLARE @d datetime2, @delta int; SET @d =SYSUTCDATETIME(); EXEC dbo.' + prc.name + ' @pattern =N''' + args.pattern + '''' + CASE WHEN prc.name LIKE N'%_Original' THEN '' ELSE ',@option =''' + args.opt + '''' END + '; SET @delta =DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME()); INSERT dbo.LoggingTable(prc,opt,pattern,frame ,duração) SELECT N''' + prc.name + ''',''' + args.opt + ''',N''' + args.pattern + ''',''' + frame.w + ''',@delta; ', *, rn =ROW_NUMBER() OVER (PARTITIO N BY frame.w ORDER BY frame.w DESC, LEN(prc.name), args.opt DESC, args.pattern) FROM prc CROSS JOIN args CROSS JOIN frame)SELECT cmd =cmd + CASE WHEN rn =36 THEN CASE WHEN w ='BeforeIndex' THEN 'CREATE INDEX testing ON '+ 'Sales.Invoices(CustomerPurchaseOrderNumber); ' ELSE 'DROP INDEX Vendas.Faturas.testes;' END ELSE '' END--, name, opt, pattern, w, rn FROM yORDER BY w DESC, rn;Resultados
Executei esses testes em uma máquina virtual, rodando Windows 10 (1511/10586.545), SQL Server 2016 (13.0.2149), com 4 CPUs e 32 GB de RAM. Executei cada conjunto de testes 11 vezes; para os testes de cache quente, descartei o primeiro conjunto de resultados porque alguns deles eram testes de cache realmente frios.
Eu lutei com a forma de representar graficamente os resultados para mostrar padrões, principalmente porque simplesmente não havia padrões. Quase todos os métodos foram os melhores em um cenário e os piores em outro. Nas tabelas a seguir, destaquei o procedimento de melhor e pior desempenho para cada coluna, e você pode ver que os resultados estão longe de ser conclusivos:
Nestes testes, às vezes o CHARINDEX venceu, às vezes não. em>
O que eu aprendi é que, no geral, se você estiver enfrentando muitas situações diferentes (diferentes tipos de correspondência de padrões, com um índice de suporte ou não, os dados nem sempre podem estar na memória), realmente não há vencedor claro, e a faixa de desempenho em média é bem pequena (na verdade, como um cache quente nem sempre ajudava, eu suspeitaria que os resultados foram afetados mais pelo custo de renderizar os resultados do que recuperá-los). Para cenários individuais, não confie em meus testes; execute alguns benchmarks por conta própria, considerando seu hardware, configuração, dados e padrões de uso.
Advertências
Algumas coisas que não considerei para esses testes:
- Em cluster x não em cluster . Uma vez que é improvável que seu índice clusterizado esteja em uma coluna onde você está realizando pesquisas de correspondência de padrões no início ou no final da string, e uma vez que uma busca será basicamente a mesma em ambos os casos (e as diferenças entre as verificações serão em grande parte ser função da largura do índice versus largura da tabela), testei apenas o desempenho usando um índice não clusterizado. Se você tiver algum cenário específico em que essa diferença por si só faça uma grande diferença na correspondência de padrões, entre em contato.
- tipos MAX . Se você estiver procurando por strings dentro de
varchar(max)/nvarchar(max), eles não podem ser indexados, portanto, a menos que você use colunas computadas para representar partes do valor, uma varredura será necessária – se você estiver procurando por começa com, termina com ou contém. Se a sobrecarga de desempenho se correlaciona com o tamanho da string ou se a sobrecarga adicional é introduzida simplesmente devido ao tipo, não testei.
- Pesquisa de texto completo . Eu brinquei com esse recurso aqui e lá, e posso soletrar, mas se meu entendimento estiver correto, isso só pode ser útil se você estiver procurando por palavras inteiras sem parar e não se preocupar com onde na string elas estavam encontrado. Não seria útil se você estivesse armazenando parágrafos de texto e quisesse encontrar todos aqueles que começam com "Y", contêm a palavra "the" ou terminam com um ponto de interrogação.
Resumo
A única declaração geral que posso fazer saindo desse teste é que não há declarações gerais sobre qual é a maneira mais eficiente de realizar a correspondência de padrões de string. Embora eu seja tendencioso em relação à minha abordagem condicional para flexibilidade e capacidade de manutenção, ela não foi a vencedora do desempenho em todos os cenários. Para mim, a menos que eu esteja atingindo um gargalo de desempenho e perseguindo todos os caminhos, continuarei usando minha abordagem para obter consistência. Como sugeri acima, se você tiver um cenário muito restrito e for muito sensível a pequenas diferenças na duração, convém executar seus próprios testes para determinar qual método é consistentemente o melhor desempenho para você.