Eu escrevi um post recentemente sobre DISTINCT e GROUP BY. Foi uma comparação que mostrou que GROUP BY geralmente é uma opção melhor que DISTINCT. Está em um site diferente, mas certifique-se de voltar ao sqlperformance.com logo após.
Uma das comparações de consultas que mostrei nesse post foi entre um GROUP BY e DISTINCT para uma subconsulta, mostrando que o DISTINCT é bem mais lento, pois tem que buscar o Product Name para cada linha da tabela Sales, ao invés do que apenas para cada ProductID diferente. Isso fica bem claro nos planos de consulta, onde você pode ver que na primeira consulta, o Agregado opera nos dados de apenas uma tabela, e não nos resultados da junção. Ah, e ambas as consultas fornecem as mesmas 266 linhas.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID;
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od; 
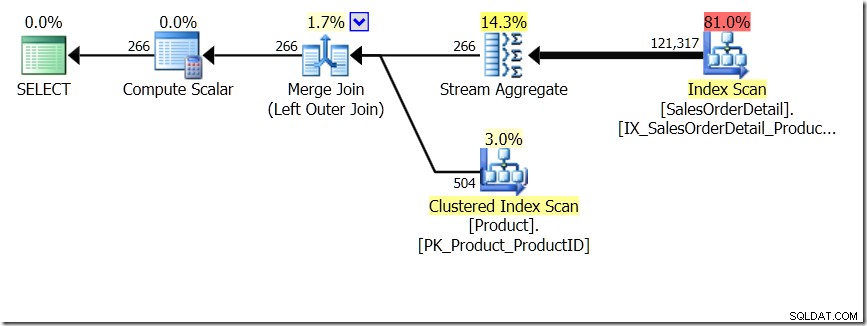
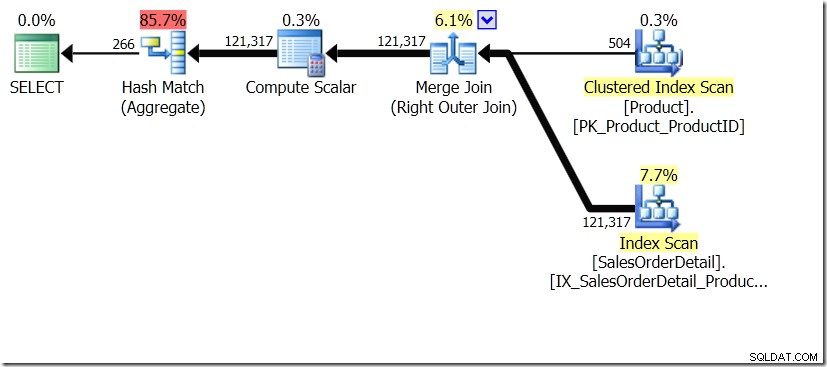
Agora, foi apontado, inclusive por Adam Machanic (@adammachanic) em um tweet referenciando a postagem de Aaron sobre GROUP BY v DISTINCT que as duas consultas são essencialmente diferentes, que uma está realmente pedindo o conjunto de combinações distintas nos resultados do subconsulta, em vez de executar a subconsulta nos valores distintos que são passados. É o que vemos no plano e é a razão pela qual o desempenho é tão diferente.
A coisa é que todos nós assumiríamos que os resultados serão idênticos.
Mas isso é uma suposição, e não é uma boa.
Vou imaginar por um momento que o Otimizador de Consultas criou um plano diferente. Eu usei dicas para isso, mas como você sabe, o Query Optimizer pode optar por criar planos em todos os tipos de formas por todos os tipos de motivos.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID
option (loop join);
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
option (loop join); 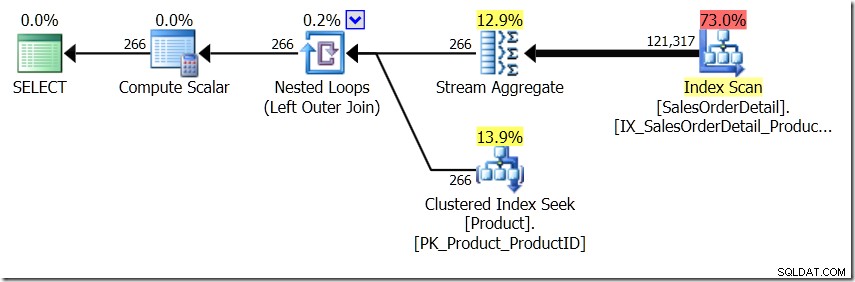
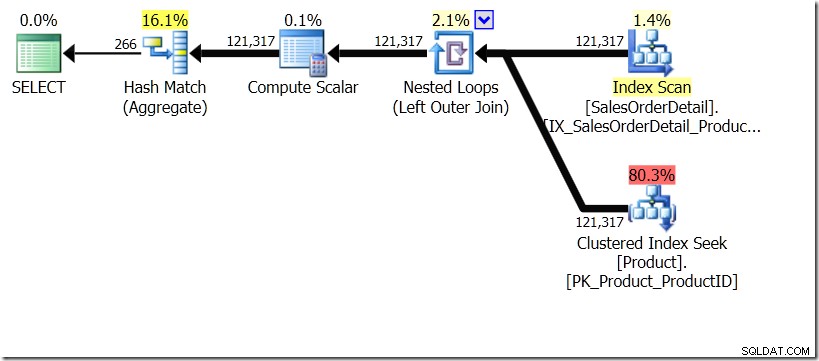
Nessa situação, fazemos 266 Buscas na tabela Produto, uma para cada ProductID diferente em que estamos interessados, ou 121.317 Buscas. Portanto, se estamos pensando em um ProductID específico, sabemos que obteremos um único Nome de volta do primeiro. E assumimos que obteremos um único Nome de volta para esse ProductID, mesmo que tenhamos que solicitá-lo centenas de vezes. Nós apenas assumimos que vamos obter os mesmos resultados de volta.
Mas e se não o fizermos?
Isso soa como uma coisa de nível de isolamento, então vamos usar NOLOCK quando chegarmos à tabela Product. E vamos executar (em uma janela diferente) um script que altera o texto nas colunas Name. Vou fazer isso várias vezes, para tentar obter algumas das alterações entre a minha consulta.
update Production.Product set Name = cast(newid() as varchar(36)); go 1000
Agora, meus resultados são diferentes. Os planos são os mesmos (exceto pelo número de linhas que saem do Hash Aggregate na segunda consulta), mas meus resultados são diferentes.
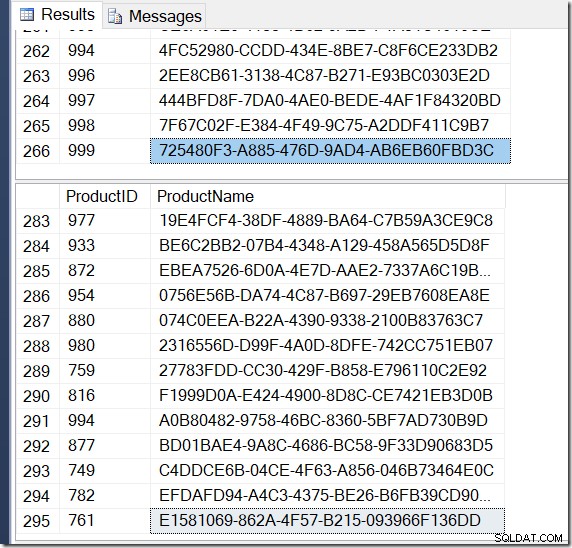
Com certeza, eu tenho mais linhas com DISTINCT, porque ele encontra valores de nome diferentes para o mesmo ProductID. E eu não tenho necessariamente 295 linhas. Outro que eu corro, posso obter 273, ou 300, ou possivelmente, 121.317.
Não é difícil encontrar um exemplo de ProductID que mostre vários valores de Nome, confirmando o que está acontecendo.

Claramente, para garantir que não vejamos essas linhas nos resultados, precisaríamos NÃO usar DISTINCT ou usar um nível de isolamento mais rigoroso.
O problema é que, embora eu tenha mencionado o uso do NOLOCK para este exemplo, não precisei. Essa situação ocorre mesmo com READ COMMITTED, que é o nível de isolamento padrão em muitos sistemas SQL Server.
Veja, precisamos do nível de isolamento REPEATABLE READ para evitar essa situação, para manter os bloqueios em cada linha depois de lida. Caso contrário, um thread separado pode alterar os dados, como vimos.
Mas… não posso mostrar que os resultados estão corrigidos, porque não consegui evitar um impasse na consulta.
Portanto, vamos alterar as condições, certificando-nos de que nossa outra consulta seja menos problemática. Em vez de atualizar a tabela inteira de uma vez (o que é muito menos provável no mundo real), vamos apenas atualizar uma única linha de cada vez.
declare @id int = 1; declare @maxid int = (select count(*) from Production.Product); while (@id < @maxid) begin with p as (select *, row_number() over (order by ProductID) as rn from Production.Product) update p set Name = cast(newid() as varchar(36)) where rn = @id; set @id += 1; end go 100
Agora, ainda podemos demonstrar o problema em um nível de isolamento menor, como READ COMMITTED ou READ UNCOMMITTED (embora você possa precisar executar a consulta várias vezes se obtiver 266 na primeira vez, porque a chance de atualizar uma linha durante a consulta é menor), e agora podemos demonstrar que REPEATABLE READ corrige isso (não importa quantas vezes executamos a consulta).
REPEATABLE READ faz o que diz na lata. Depois de ler uma linha em uma transação, ela é bloqueada para garantir que você possa repetir a leitura e obter os mesmos resultados. Os níveis de isolamento menores não removem esses bloqueios até que você tente alterar os dados. Se o seu plano de consulta nunca precisar repetir uma leitura (como é o caso do formato de nossos planos GROUP BY), você não precisará de REPEATABLE READ.
Indiscutivelmente, devemos sempre usar os níveis de isolamento mais altos, como REPEATABLE READ ou SERIALIZABLE, mas tudo se resume a descobrir o que nossos sistemas precisam. Esses níveis podem introduzir bloqueios indesejados, e os níveis de isolamento SNAPSHOT exigem versões que também vêm com um preço. Para mim, acho que é uma troca. Se estou solicitando uma consulta que pode ser afetada pela alteração de dados, talvez seja necessário aumentar o nível de isolamento por um tempo.
Idealmente, você simplesmente não atualiza os dados que acabaram de ser lidos e podem precisar ser lidos novamente durante a consulta, para que você não precise de REPEATABLE READ. Mas definitivamente vale a pena entender o que pode acontecer e reconhecer que esse é o tipo de cenário em que DISTINCT e GROUP BY podem não ser a mesma coisa.
@rob_farley