Neste artigo, focaremos na análise operacional em tempo real e em como aplicar essa abordagem a um banco de dados OLTP. Quando olhamos para o modelo analítico tradicional, podemos ver que o OLTP e os ambientes analíticos são estruturas separadas. Em primeiro lugar, os ambientes de modelos analíticos tradicionais precisam criar tarefas ETL (Extrair, Transformar e Carregar). Porque precisamos transferir dados transacionais para o data warehouse. Esses tipos de arquitetura têm algumas desvantagens. Eles são custo, complexidade e latência de dados. Para eliminar essas desvantagens, precisamos de uma abordagem diferente.
Análise Operacional em Tempo Real
A Microsoft anunciou Real-Time Operational Analytics no SQL Server 2016. A capacidade desse recurso é combinar banco de dados transacional e carga de trabalho de consulta analítica sem nenhum problema de desempenho. A Análise Operacional em Tempo Real fornece:
- estrutura híbrida
- consultas transacionais e analíticas podem ser executadas ao mesmo tempo
- não causa problemas de desempenho e latência.
- uma implementação simples.
Esse recurso pode superar as desvantagens do ambiente analítico tradicional. O tema principal desse recurso é que o índice de armazenamento de colunas mantém uma cópia dos dados sem afetar o desempenho do sistema transacional. Este tema permite que as consultas analíticas sejam executadas sem afetar o desempenho. Portanto, isso minimiza o impacto no desempenho. A principal limitação desse recurso é que não podemos coletar dados de diferentes fontes de dados.
Índice de armazenamento de colunas não agrupadas
O SQL Server 2016 apresenta o “Índice de armazenamento de colunas não agrupado” atualizável. O índice de armazenamento de colunas não agrupado é um índice baseado em colunas que oferece benefícios de desempenho para consultas analíticas. Esse recurso nos permite criar a estrutura de análise operacional em tempo real. Isso significa que podemos executar transações e consultas analíticas ao mesmo tempo. Considere que precisamos de vendas totais mensais. Em um modelo tradicional, temos que desenvolver tarefas de ETL, data mart e data warehouse. Mas na análise operacional em tempo real, podemos fazê-lo sem exigir qualquer data warehouse ou qualquer alteração na estrutura OLTP. Precisamos apenas criar um índice de armazenamento de colunas não clusterizado adequado.
Arquitetura do índice de armazenamento de colunas não clusterizado
Vejamos brevemente a arquitetura do índice de armazenamento de colunas não clusterizado e o mecanismo em execução. O índice de armazenamento de colunas não clusterizadas contém uma cópia de uma parte ou de todas as linhas e colunas na tabela subjacente. O tema principal do índice de armazenamento de colunas não clusterizado é manter uma cópia dos dados e usar essa cópia dos dados. Portanto, esse mecanismo minimiza o impacto no desempenho do banco de dados transacional. O índice de armazenamento de colunas não clusterizado pode criar uma ou mais colunas e pode aplicar um filtro às colunas.
Quando inserimos uma nova linha em uma tabela que possui um índice de armazenamento de colunas não clusterizado, primeiro, o SQL Server cria um “rowgroup”. Rowgroup é uma estrutura lógica que representa um conjunto de linhas. Em seguida, o SQL Server armazena essas linhas em um armazenamento temporário. O nome desse armazenamento temporário é “deltastore”. O SQL Server usa essa área de armazenamento temporário porque esse mecanismo melhora a taxa de compactação e reduz a fragmentação do índice. Quando o número de linhas atinge 1.048.577, o SQL Server fecha o estado do grupo de linhas. O SQL Server compacta esse grupo de linhas e altera o estado para “compactado”.
Agora, criaremos uma tabela e adicionaremos o índice de armazenamento de colunas não clusterizado.
DROP TABLE IF EXISTS Analysis_TableTest CREATE TABLE Analysis_TableTest (ID INT PRIMARY KEY IDENTITY(1,1), Continent_Name VARCHAR(20), Country_Name VARCHAR(20), City_Name VARCHAR(20), Sales_Amnt INT, Profit_Amnt INT) GO
CREATE NONCLUSTERED COLUMNSTORE INDEX [NonClusteredColumnStoreIndex] ON [dbo].[Analysis_TableTest]
(
[Country_Name],
[City_Name] ,
Sales_Amnt
)WITH (DROP_EXISTING = OFF, COMPRESSION_DELAY = 0) ON [PRIMARY]
Nesta etapa, inseriremos várias linhas e examinaremos as propriedades do índice de armazenamento de colunas não clusterizadas.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO
Essa consulta exibirá os estados do grupo de linhas, o número total de tamanho das linhas e outros valores.
SELECT i.object_id, object_name(i.object_id) AS TableName,
i.name AS IndexName, i.index_id, i.type_desc,
CSRowGroups.*,
100*(total_rows - ISNULL(deleted_rows,0))/total_rows AS PercentFull
FROM sys.indexes AS i
JOIN sys.column_store_row_groups AS CSRowGroups
ON i.object_id = CSRowGroups.object_id
AND i.index_id = CSRowGroups.index_id
ORDER BY object_name(i.object_id), i.name, row_group_id;

A imagem acima nos mostra o estado deltastore e o número total de linhas que não estão compactadas. Agora vamos preencher mais dados na tabela e quando o número de linhas atingir 1.048.577, o SQL Server fechará o primeiro rowgroup e abrirá um novo rowgroup.
INSERT INTO Analysis_TableTest VALUES('Europe','Germany','Munich','100','12')
INSERT INTO Analysis_TableTest VALUES('Europe','Turkey','Istanbul','200','24')
INSERT INTO Analysis_TableTest VALUES('Europe','France','Paris','190','23')
INSERT INTO Analysis_TableTest VALUES('America','USA','Newyork','180','19')
INSERT INTO Analysis_TableTest VALUES('Asia','Japan','Tokyo','190','17')
GO 2000000

O SQL Server compactará esse rowgroup e criará um novo rowgroup. A opção “COMPRESSION_DELAY” nos permite controlar quanto tempo o rowgroup espera no status fechado.

Quando executamos os comandos de manutenção do índice (reorganizar, reconstruir), as linhas excluídas são removidas fisicamente e o índice é desfragmentado.

Quando atualizamos (excluir + inserir) algumas linhas nesta tabela, as linhas excluídas são marcadas como “excluídas” e novas linhas atualizadas são inseridas no deltastore.
Referência de desempenho de consulta analítica
Neste título, preencheremos os dados na tabela Analysis_TableTest. Inseri 4 milhões de registros. (Você precisa testar esta etapa e as próximas etapas em seu ambiente de teste. Problemas de desempenho podem ocorrer e também o comando DBCC DROPCLEANBUFFERS pode prejudicar o desempenho. Este comando removerá todos os dados de buffer no pool de buffers.)
Agora executaremos a seguinte consulta analítica e examinaremos os valores de desempenho.
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name

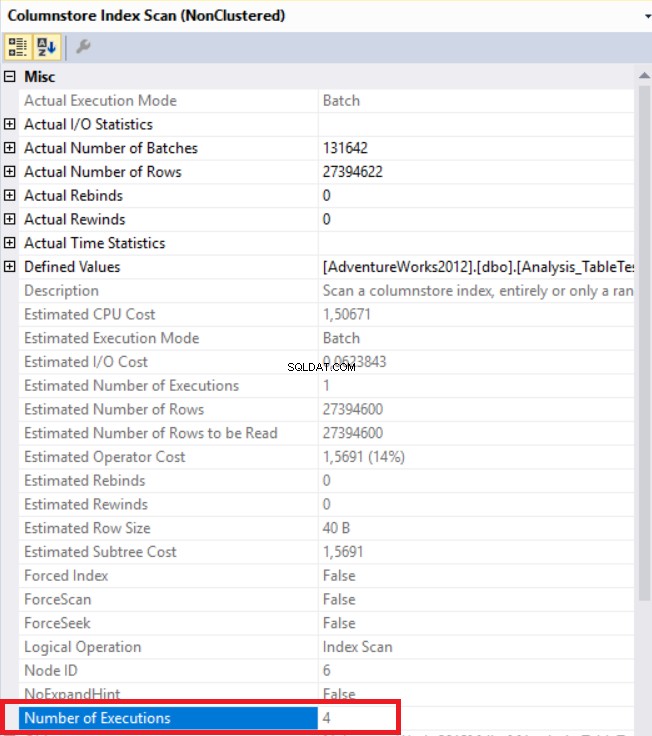
Na imagem acima, podemos ver o operador de verificação de índice de armazenamento de colunas não clusterizadas. A tabela abaixo mostra a CPU e os tempos de execução. Essa consulta consome 1,765 milissegundos na CPU e é concluída em 0,791 milissegundos. O tempo de CPU é maior que o tempo decorrido porque o plano de execução usa processadores paralelos e distribui tarefas para 4 processadores. Podemos vê-lo nas propriedades do operador “Columnstore Index Scan”. O valor “Número de execuções” indica isso.

Agora vamos adicionar uma dica à consulta para reduzir o número de processadores. Não veremos nenhum operador de paralelismo.
SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)
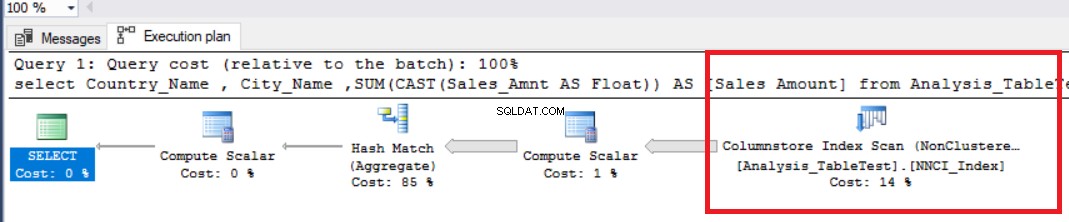

A tabela abaixo define os tempos de execução. Neste gráfico, podemos ver que o tempo decorrido é maior que o tempo de CPU porque o SQL Server utilizou apenas um processador.
Agora vamos desabilitar o índice de armazenamento de colunas não clusterizadas e executar a mesma consulta.
ALTER INDEX [NNCI_Index] ON [dbo].[Analysis_TableTest] DISABLE GO SET STATISTICS TIME ON SET STATISTICS IO ON DBCC DROPCLEANBUFFERS select Country_Name , City_Name ,SUM(CAST(Sales_Amnt AS Float)) AS [Sales Amount] from Analysis_TableTest group by Country_Name ,City_Name OPTION (MAXDOP 1)

A tabela acima nos mostra que o índice de armazenamento de colunas não clusterizado oferece um desempenho incrível em consultas analíticas. Aproximadamente, a consulta indexada de armazenamento de colunas é cinco vezes melhor que a outra.
Conclusão
O Real-Time Operational Analytics oferece uma flexibilidade incrível porque podemos executar consultas analíticas em sistemas OLTP sem qualquer latência de dados. Ao mesmo tempo, essas consultas analíticas não afetam o desempenho do banco de dados OLTP. Esse recurso nos dá a capacidade de gerenciar dados transacionais e as consultas analíticas no mesmo ambiente.
Referências
Índices de armazenamento de colunas – orientação de carregamento de dados
Comece com o Column Store para análises operacionais em tempo real
Análise operacional em tempo real
Leituras adicionais:
Verificação inversa do índice do SQL Server:Noções básicas, ajuste
Usando índices em tabelas com otimização de memória do SQL Server