Algumas semanas atrás, a equipe do SQLskills estava em Tampa para nosso evento de imersão de ajuste de desempenho (IE2) e eu estava cobrindo as linhas de base. Linhas de base é um tópico que está próximo e querido ao meu coração, porque eles são muito valiosos por muitas razões. Duas dessas razões, que sempre abordo seja ensinando ou trabalhando com clientes, são o uso de linhas de base para solucionar problemas de desempenho e também a tendência de uso e o fornecimento de estimativas de planejamento de capacidade. Mas eles também são essenciais quando você está fazendo ajustes ou testes de desempenho – quer você pense em suas métricas de desempenho existentes como linhas de base ou não.
Durante o módulo, revisei diferentes fontes de dados, como Monitor de desempenho, DMVs e dados de rastreamento ou XE, e surgiu uma pergunta relacionada a cargas de dados. Especificamente, a questão era se é melhor carregar dados em uma tabela sem índices e criá-los quando terminar, em vez de ter os índices no lugar durante o carregamento de dados. Minha resposta foi:"Normalmente, sim". Minha experiência pessoal tem sido que esse é sempre o caso, mas você nunca sabe qual ressalva ou cenário único alguém pode encontrar em que a mudança de desempenho não é a esperada e, como acontece com todas as questões de desempenho, você não sabe ao certo até testá-lo. Até estabelecer uma linha de base para um método e ver se o outro método melhora essa linha de base, você está apenas supondo. Achei que seria divertido testar nesse cenário, não apenas para provar o que espero ser verdade, mas também para mostrar quais métricas eu examinaria, por que e como capturá-las. Se você já fez testes de desempenho anteriormente, provavelmente isso é antigo. Mas para aqueles de vocês que são novos na prática, vou seguir o processo que sigo para ajudá-los a começar. Perceba que há muitas maneiras de obter a resposta para "Qual método é melhor?" Espero que você pegue esse processo, ajuste-o e torne-o seu ao longo do tempo.
O que você está tentando provar?
O primeiro passo é decidir exatamente o que você está testando. No nosso caso, é simples:é mais rápido carregar dados em uma tabela vazia e adicionar os índices ou é mais rápido ter os índices na tabela durante o carregamento de dados? Mas, podemos adicionar alguma variação aqui, se quisermos. Considere o tempo necessário para carregar dados em um heap e, em seguida, crie os índices clusterizados e não clusterizados, em comparação com o tempo necessário para carregar dados em um índice clusterizado e, em seguida, crie os índices não clusterizados. Existe diferença no desempenho? A chave de agrupamento seria um fator? Espero que a carga de dados faça com que os índices não clusterizados existentes se fragmentem, então talvez eu queira ver o impacto da reconstrução dos índices após a carga na duração total. É importante definir o escopo dessa etapa o máximo possível e ser muito específico sobre o que você deseja medir, pois isso determinará quais dados você captura. Para o nosso exemplo, nossos quatro testes serão:
Teste 1: Carregue dados em um heap, crie o índice clusterizado, crie os índices não clusterizados
Teste 2: Carregue dados em um índice clusterizado, crie os índices não clusterizados
Teste 3: Crie o índice clusterizado e os índices não clusterizados, carregue os dados
Teste 4: Crie o índice clusterizado e os índices não clusterizados, carregue os dados, reconstrua os índices não clusterizados
O que você precisa saber?
Em nosso cenário, nossa principal pergunta é “qual método é mais rápido”? Portanto, queremos medir a duração e, para isso, precisamos capturar um horário de início e um horário de término. Poderíamos deixar por isso mesmo, mas podemos querer entender como é a utilização de recursos para cada método, ou talvez queiramos saber as esperas mais altas, ou o número de transações, ou o número de deadlocks. Os dados mais interessantes e relevantes dependerão de quais processos você está comparando. Capturar o número de transações não é tão interessante para nossa carga de dados; mas para uma mudança de código pode ser. Como estamos criando índices e reconstruindo-os, estou interessado em quanto IO cada método gera. Embora a duração geral seja provavelmente o fator decisivo no final, examinar a E/S pode ser útil não apenas para entender qual opção gera mais E/S, mas também se o armazenamento do banco de dados está funcionando conforme o esperado.
Onde estão os dados de que você precisa?
Depois de determinar quais dados você precisa, decida de onde eles serão capturados. Estamos interessados na duração, por isso queremos registrar a hora em que cada teste de carga de dados começa e quando termina. Também estamos interessados em IO e podemos extrair esses dados de vários locais – os contadores do Monitor de desempenho e o DMV sys.dm_io_virtual_file_stats vêm à mente.
Entenda que poderíamos obter esses dados manualmente. Antes de executar um teste, podemos selecionar sys.dm_io_virtual_file_stats e salvar os valores atuais em um arquivo. Podemos anotar o tempo e, em seguida, iniciar o teste. Quando terminar, anotamos o tempo novamente, consultamos sys.dm_io_virtual_file_stats novamente e calculamos as diferenças entre os valores para medir a E/S.
Existem inúmeras falhas nesta metodologia, nomeadamente que deixa uma margem significativa para erros; e se você esquecer de anotar a hora de início ou se esquecer de capturar as estatísticas do arquivo antes de começar? Uma solução muito melhor é automatizar não apenas a execução do script, mas também a captura de dados. Por exemplo, podemos criar uma tabela que contém nossas informações de teste – uma descrição do que é o teste, a que horas ele começou e a que horas foi concluído. Podemos incluir as estatísticas do arquivo na mesma tabela. Se estivermos coletando outras métricas, podemos adicioná-las à tabela. Ou pode ser mais fácil criar uma tabela separada para cada conjunto de dados que capturamos. Por exemplo, se armazenarmos dados de estatísticas de arquivo em uma tabela diferente, precisamos dar a cada teste um id exclusivo, para que possamos corresponder nosso teste com os dados de estatísticas de arquivo corretos. Ao capturar estatísticas de arquivos, temos que capturar os valores para nosso banco de dados antes de começar, e depois depois, e calcular a diferença. Podemos então armazenar essas informações em sua própria tabela, juntamente com o ID de teste exclusivo.
Um exemplo de exercício
Para este teste, criei uma cópia vazia da tabela Sales.SalesOrderHeader chamada Sales.Big_SalesOrderHeader e usei uma variação de um script que usei em minha postagem de particionamento para carregar dados na tabela em lotes de aproximadamente 25.000 linhas. Você pode baixar o script para o carregamento de dados aqui. Executei quatro vezes para cada variação e também variei o número total de linhas inseridas. Para o primeiro conjunto de testes, inseri 20 milhões de linhas e, para o segundo conjunto, inseri 60 milhões de linhas. Os dados de duração não são surpreendentes:
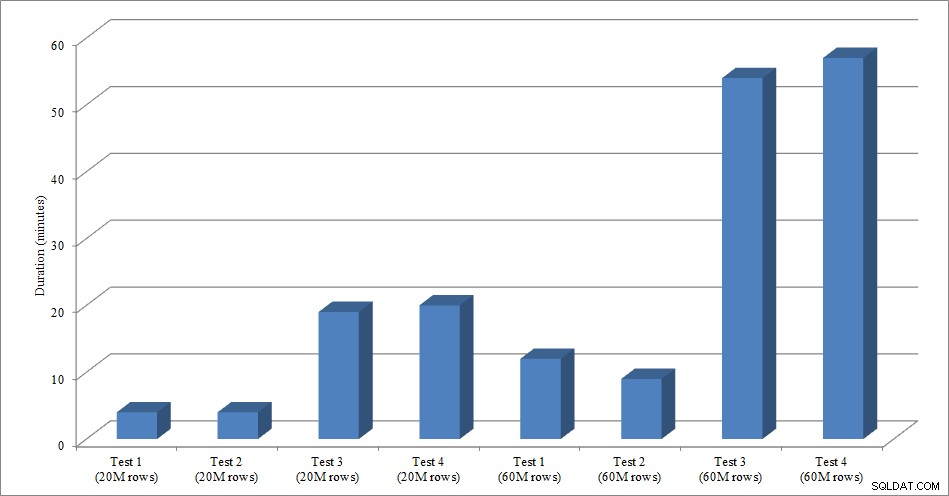
Duração do carregamento de dados
Carregar dados, sem os índices não clusterizados, é muito mais rápido do que carregá-los com os índices não clusterizados já instalados. O que achei interessante é que, para o carregamento de 20 milhões de linhas, a duração total foi aproximadamente a mesma entre o Teste 1 e o Teste 2, mas o Teste 2 foi mais rápido ao carregar 60 milhões de linhas. Em nosso teste, nossa chave de cluster foi SalesOrderID, que é uma identidade e, portanto, uma boa chave de cluster para nossa carga, pois é ascendente. Se tivéssemos uma chave de cluster que fosse um GUID, o tempo de carregamento pode ser maior devido a inserções aleatórias e divisões de página (outra variação que poderíamos testar).
Os dados de IO imitam a tendência dos dados de duração? Sim, com as diferenças de ter os índices já colocados, ou não, ainda mais exagerados:
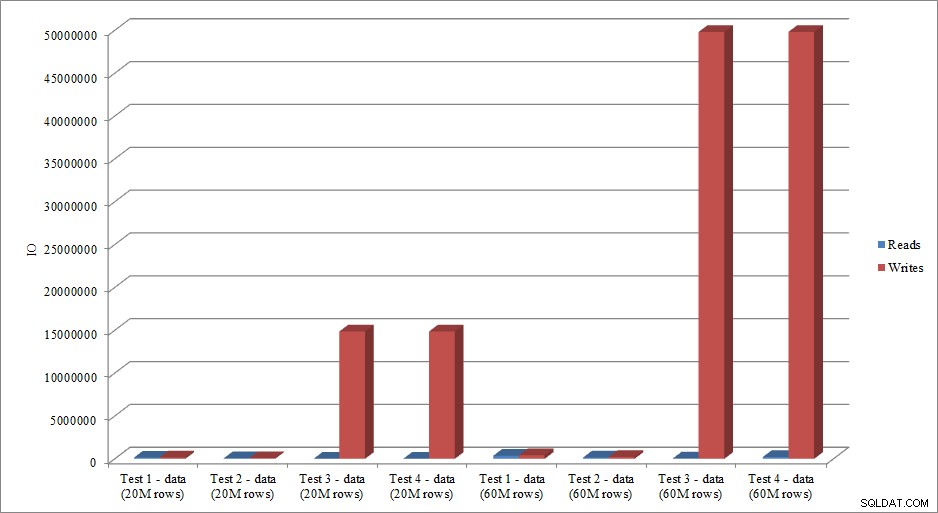
Leituras e gravações de carga de dados
O método que apresentei aqui para teste de desempenho, ou medição de alterações no desempenho com base em modificações no código, design, etc., é apenas uma opção para capturar informações básicas. Em alguns cenários, isso pode ser um exagero. Se você tiver uma consulta que está tentando ajustar, configurar esse processo para capturar dados pode levar mais tempo do que para fazer ajustes na consulta! Se você fez algum ajuste de consulta, provavelmente tem o hábito de capturar dados de STATISTICS IO e STATISTICS TIME, juntamente com o plano de consulta, e comparar a saída à medida que faz as alterações. Faço isso há anos, mas recentemente descobri uma maneira melhor… SQL Sentry Plan Explorer PRO. De fato, depois de concluir todos os testes de carga descritos acima, fiz e re-executei meus testes através do PE e descobri que poderia capturar as informações que desejava, sem precisar configurar minhas tabelas de coleta de dados.
No Plan Explorer PRO, você tem a opção de obter o plano real – o PE executará a consulta na instância e no banco de dados selecionados e retornará o plano. E com ele, você obtém todos os outros ótimos dados que o PE fornece (estatísticas de tempo, leituras e gravações, IO por tabela), bem como as estatísticas de espera, o que é um ótimo benefício. Usando nosso exemplo, comecei com o primeiro teste – criando o heap, carregando dados e adicionando o índice clusterizado e os índices não clusterizados – e então executei a opção Get Actual Plan. Quando concluído modifiquei meu script test 2, executei a opção Get Actual Plan novamente. Repeti isso para o terceiro e quarto testes e, quando terminei, tive isso:
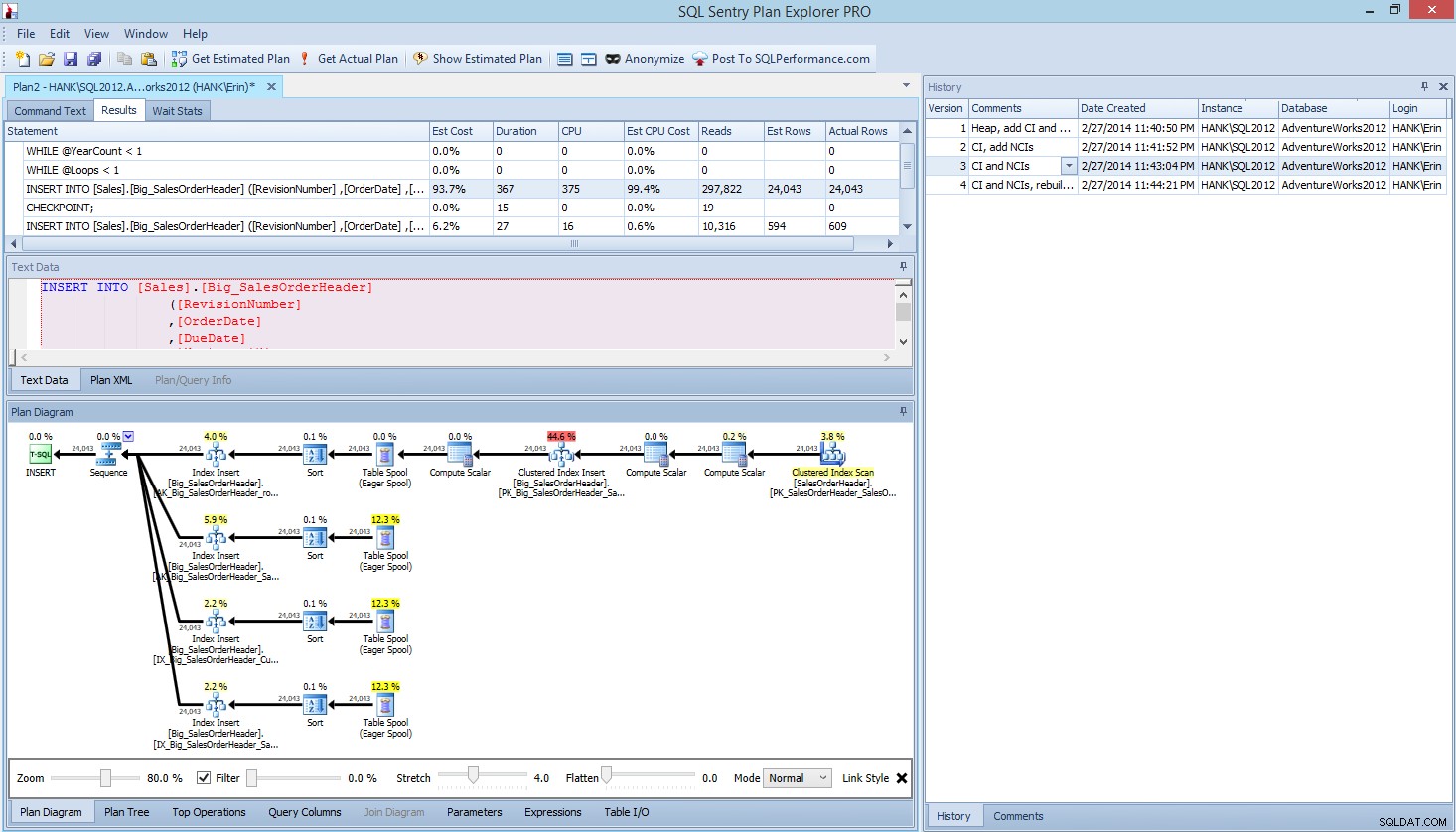
Planeje a visualização do Explorer PRO após executar 4 testes
Observe o painel de histórico no lado direito? Toda vez que eu modificava meu código e recuperava o plano real, ele salvava um novo conjunto de informações. Tenho a capacidade de salvar esses dados como um arquivo .pesession para compartilhar com outro membro da minha equipe ou voltar mais tarde e percorrer os diferentes testes e detalhar diferentes instruções dentro do lote conforme necessário, analisando diferentes métricas, como como duração, CPU e E/S. Na captura de tela acima, destaquei o INSERT do Teste 3 e o plano de consulta mostra as atualizações para todos os quatro índices não clusterizados.
Resumo
Assim como acontece com tantas tarefas no SQL Server, há muitas maneiras de capturar e revisar dados ao executar testes de desempenho ou realizar ajustes. Quanto menos esforço manual você tiver que fazer, melhor, pois sobra mais tempo para realmente fazer alterações, entender o impacto e depois passar para sua próxima tarefa. Independentemente de você personalizar um script para capturar dados ou permitir que um utilitário de terceiros faça isso por você, as etapas descritas ainda são válidas:
- Defina o que você deseja melhorar
- Escopo seu teste
- Determine quais dados podem ser usados para medir a melhoria
- Decida como capturar os dados
- Configure um método automatizado, sempre que possível, para teste e captura
- Teste, avalie e repita conforme necessário
Feliz teste!