Em um afastamento da minha série de 'ajuste de desempenho instintivo', gostaria de discutir como a fragmentação de índice pode surgir em você em algumas circunstâncias.
O que é fragmentação de índice?
A maioria das pessoas pensa em 'fragmentação de índice' como significando o problema em que as páginas de folha de índice estão fora de ordem - a página de folha de índice com o próximo valor de chave não é aquela que é fisicamente contígua no arquivo de dados à página de folha de índice que está sendo examinada . Isso é chamado de fragmentação lógica (e algumas pessoas se referem a ela como fragmentação externa – um termo confuso que eu não gosto).
A fragmentação lógica acontece quando uma página de folha de índice está cheia e é necessário espaço nela, seja para uma inserção ou para tornar um registro existente mais longo (da atualização de uma coluna de comprimento variável). Nesse caso, o Storage Engine cria uma nova página vazia e move 50% das linhas (geralmente, mas nem sempre) da página inteira para a nova página. Essa operação cria espaço em ambas as páginas, permitindo que a inserção ou atualização prossiga, e é chamada de divisão de página. Existem casos patológicos interessantes envolvendo divisões de página repetidas de uma única operação e divisões de página que se espalham pelos níveis de índice, mas estão além do escopo deste post.
Quando ocorre uma divisão de página, geralmente causa fragmentação lógica porque é altamente improvável que a nova página alocada seja fisicamente contígua àquela que está sendo dividida. Quando um índice tem muita fragmentação lógica, as varreduras de índice ficam mais lentas porque as leituras físicas das páginas necessárias não podem ser feitas com a mesma eficiência (usando leituras 'readahead' de várias páginas) quando as páginas folha não são armazenadas em ordem no arquivo de dados .
Essa é a definição básica de fragmentação de índice, mas há um segundo tipo de fragmentação de índice que a maioria das pessoas não considera:baixa densidade de página (às vezes chamo de fragmentação interna, novamente, um termo confuso que não gosto).
A densidade da página é uma medida de quantos dados são armazenados em uma página de folha de índice. Quando ocorre uma divisão de página com o caso usual de 50/50, cada página folha (a que se divide e a nova) fica com uma densidade de página de apenas 50%. Quanto menor a densidade da página, mais espaço vazio há no índice e, portanto, mais espaço em disco e memória do buffer pool você pode considerar como sendo desperdiçado. Eu escrevi sobre esse problema alguns anos atrás e você pode ler sobre isso aqui.
Agora que dei uma definição básica dos dois tipos de fragmentação de índice, vou me referir a eles coletivamente como simplesmente "fragmentação".
Para o restante desta postagem, gostaria de discutir três casos em que os índices clusterizados podem se tornar fragmentados, mesmo se você estiver evitando operações que obviamente causariam fragmentação (ou seja, inserções aleatórias e registros de atualização mais longos).
Fragmentação de exclusões
“Como uma exclusão de uma página de folha de índice clusterizado pode causar uma divisão de página?” você pode estar perguntando. Não vai, em circunstâncias normais (e eu fiquei pensando sobre isso por alguns minutos para ter certeza de que não havia algum caso patológico estranho! Mas veja a seção abaixo…) No entanto, as exclusões podem fazer com que a densidade da página fique progressivamente menor.
Imagine o caso em que o índice clusterizado tem um valor de chave de identidade bigint, de modo que as inserções sempre irão para o lado direito do índice e nunca, jamais, serão inseridas em uma parte anterior do índice (exceto alguém resemeando o valor de identidade – potencialmente muito problemático!). Agora imagine que a carga de trabalho exclua registros da tabela que não são mais necessários, após o que a tarefa de limpeza fantasma em segundo plano recuperará o espaço na página e se tornará espaço livre.
Na ausência de inserções aleatórias (impossível em nosso cenário, a menos que alguém resemeie a identidade ou especifique um valor de chave a ser usado após habilitar SET IDENTITY INSERT para a tabela), nenhum novo registro usará o espaço que foi liberado dos registros excluídos. Isso significa que a densidade média de páginas das partes anteriores do índice clusterizado diminuirá constantemente, levando ao aumento da quantidade de espaço em disco desperdiçado e memória do buffer pool, conforme descrevi anteriormente.
As exclusões podem causar fragmentação, desde que você considere a densidade da página como parte da "fragmentação".
Fragmentação do isolamento de instantâneo
O SQL Server 2005 introduziu dois novos níveis de isolamento:isolamento de instantâneo e isolamento de instantâneo de leitura confirmada. Esses dois têm semânticas ligeiramente diferentes, mas basicamente permitem que as consultas vejam uma visão pontual de um banco de dados e para seleções sem bloqueio de colisão. Essa é uma grande simplificação, mas é suficiente para meus propósitos.
Para facilitar esses níveis de isolamento, a equipe de desenvolvimento da Microsoft que liderei implementou um mecanismo chamado versionamento. A maneira como o controle de versão funciona é que sempre que um registro é alterado, a versão de pré-alteração do registro é copiada para o armazenamento de versão em tempdb, e o registro alterado recebe uma tag de versão de 14 bytes adicionada no final dele. A tag contém um ponteiro para a versão anterior do registro, além de um carimbo de data/hora que pode ser usado para determinar qual é a versão correta de um registro para uma consulta específica ler. Novamente, extremamente simplificado, mas é apenas a adição dos 14 bytes que nos interessa.
Portanto, sempre que um registro for alterado quando um desses níveis de isolamento estiver em vigor, ele poderá expandir em 14 bytes se ainda não houver uma tag de versão para o registro. E se não houver espaço suficiente para os 14 bytes extras na página de folha de índice? Isso mesmo, ocorrerá uma divisão de página, causando fragmentação.
Grande coisa, você pode pensar, já que o registro está mudando de qualquer maneira, então se ele estivesse mudando de tamanho de qualquer maneira, uma divisão de página provavelmente teria ocorrido. Não – essa lógica só vale se a alteração do registro for aumentar o tamanho de uma coluna de comprimento variável. Uma tag de versão será adicionada mesmo se uma coluna de tamanho fixo for atualizada!
Isso mesmo – quando o controle de versão está em execução, as atualizações em colunas de tamanho fixo podem fazer com que um registro se expanda, potencialmente causando uma divisão e fragmentação da página. O que é ainda mais interessante é que uma exclusão também adicionará a tag de 14 bytes, portanto, uma exclusão em um índice clusterizado pode causar uma divisão de página quando o controle de versão estiver em uso!
A conclusão aqui é que habilitar qualquer forma de isolamento de instantâneo pode levar à fragmentação que começa repentinamente a ocorrer em índices clusterizados onde anteriormente não havia possibilidade de fragmentação.
Fragmentação de secundários legíveis
O último caso que quero discutir é o uso de secundários legíveis, parte do recurso de grupo de disponibilidade que foi adicionado no SQL Server 2012.
Quando você habilita um secundário legível, todas as consultas feitas na réplica secundária são convertidas para usar o isolamento de instantâneo nos bastidores. Isso evita que as consultas bloqueiem a reprodução constante de registros de log da réplica primária, pois o código de recuperação adquire bloqueios à medida que avança.
Para fazer isso, é necessário haver marcas de versão de 14 bytes nos registros da réplica secundária. Há um problema, porque todas as réplicas precisam ser idênticas, para que a repetição do log funcione. Bem, não exatamente. O conteúdo da tag de controle de versão não é relevante, pois é usado apenas na instância que os criou. Mas a réplica secundária não pode adicionar tags de versão, tornando os registros mais longos, pois isso alteraria o layout físico dos registros em uma página e interromperia a reprodução do log. Se as tags de versão já estivessem lá, ele poderia usar o espaço sem quebrar nada.
Então é exatamente isso que acontece. O mecanismo de armazenamento garante que todas as tags de versão necessárias para a réplica secundária já estejam lá, adicionando-as à réplica primária!
Assim que uma réplica secundária legível de um banco de dados é criada, qualquer atualização em um registro na réplica primária faz com que o registro tenha uma tag vazia de 14 bytes adicionada, para que os 14 bytes sejam devidamente contabilizados em todos os registros de log . A tag não é usada para nada (a menos que o isolamento de instantâneo esteja habilitado na própria réplica primária), mas o fato de ser criada faz com que o registro se expanda e, se a página já estiver cheia, então…
Sim, habilitar um secundário legível causa o mesmo efeito na réplica primária como se você habilitasse o isolamento de instantâneo nela – fragmentação.
Resumo
Não pense que, como você está evitando usar GUIDs como chaves de cluster e evitando atualizar colunas de comprimento variável em suas tabelas, seus índices clusterizados ficarão imunes à fragmentação. Como descrevi acima, há outros fatores ambientais e de carga de trabalho que podem causar problemas de fragmentação em seus índices clusterizados dos quais você precisa estar ciente.
Agora, não pense que você não deve excluir registros, não deve usar isolamento de instantâneo e não deve usar secundários legíveis. Você só precisa estar ciente de que todos eles podem causar fragmentação e saber como detectá-la, removê-la e mitigá-la.
O SQL Sentry tem uma ferramenta legal, o Fragmentation Manager, que você pode usar como complemento do Performance Advisor para ajudar a descobrir onde estão os problemas de fragmentação e resolvê-los. Você pode se surpreender com a fragmentação que encontrará ao verificar! Como um exemplo rápido, aqui posso ver visualmente – até o nível de partição individual – quanta fragmentação existe, a rapidez com que ficou assim, quaisquer padrões que existam e o impacto real que isso tem no desperdício de memória no sistema:
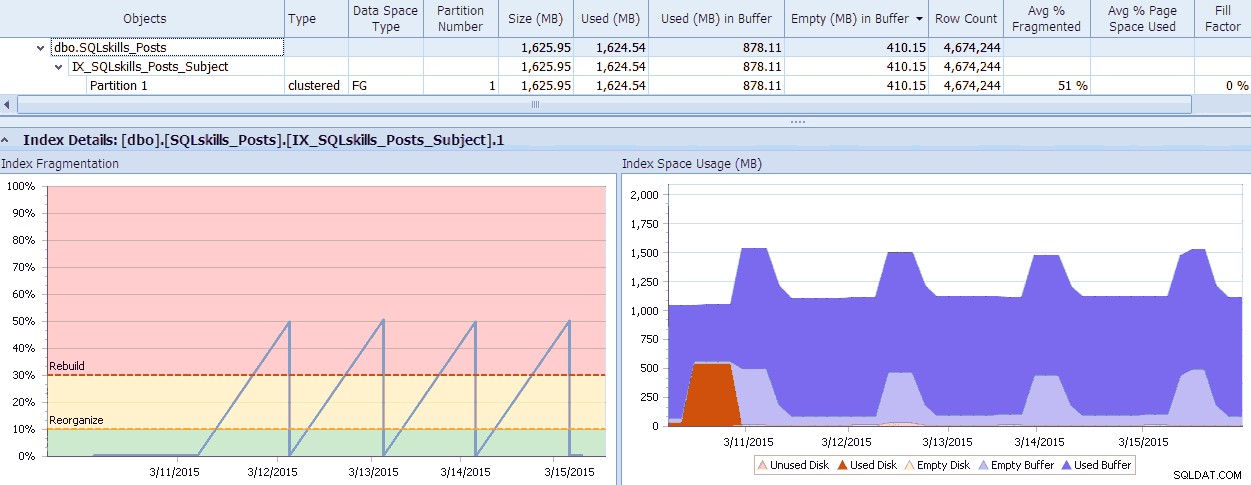 Dados do SQL Sentry Fragmentation Manager (clique para ampliar)
Dados do SQL Sentry Fragmentation Manager (clique para ampliar) No meu próximo post, discutirei mais sobre fragmentação e como mitigá-la para torná-la menos problemática.