Bem, para responder à sua pergunta por que o SQL Server está fazendo isso, a resposta é que a consulta não é compilada em uma ordem lógica, cada instrução é compilada por seu próprio mérito, portanto, quando o plano de consulta para sua instrução select está sendo gerado, o otimizador não sabe que @val1 e @Val2 se tornarão 'val1' e 'val2' respectivamente.
Quando o SQL Server não sabe o valor, ele precisa adivinhar quantas vezes essa variável aparecerá na tabela, o que às vezes pode levar a planos abaixo do ideal. Meu ponto principal é que a mesma consulta com valores diferentes pode gerar planos diferentes. Imagine este exemplo simples:
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 991 1
FROM sys.all_objects a
UNION ALL
SELECT TOP 9 ROW_NUMBER() OVER(ORDER BY a.object_id) + 1
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Tudo o que fiz aqui foi criar uma tabela simples e adicionar 1000 linhas com valores de 1 a 10 para a coluna
val , porém 1 aparece 991 vezes e os outros 9 aparecem apenas uma vez. A premissa é esta consulta:SELECT COUNT(Filler)
FROM #T
WHERE Val = 1;
Seria mais eficiente apenas escanear a tabela inteira, do que usar o índice para uma busca e fazer 991 pesquisas de favoritos para obter o valor de
Filler , porém com apenas 1 linha a seguinte consulta:SELECT COUNT(Filler)
FROM #T
WHERE Val = 2;
será mais eficiente fazer uma busca de índice e uma única pesquisa de marcador para obter o valor de
Filler (e executar essas duas consultas ratificará isso) Tenho certeza de que o corte para uma pesquisa de busca e favoritos varia de acordo com a situação, mas é bastante baixo. Usando a tabela de exemplo, com um pouco de tentativa e erro, descobri que precisava do
Val coluna para ter 38 linhas com o valor 2 antes que o otimizador fosse para uma varredura completa da tabela em uma busca de índice e pesquisa de favoritos:IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
DECLARE @I INT = 38;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP (991 - @i) 1
FROM sys.all_objects a
UNION ALL
SELECT TOP (@i) 2
FROM sys.all_objects a
UNION ALL
SELECT TOP 8 ROW_NUMBER() OVER(ORDER BY a.object_id) + 2
FROM sys.all_objects a;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
SELECT COUNT(Filler), COUNT(*)
FROM #T
WHERE Val = 2;
Portanto, para este exemplo, o limite é de 3,7% de linhas correspondentes.
Como a consulta não sabe quantas linhas corresponderão quando você estiver usando uma variável, ela precisa adivinhar, e a maneira mais simples é descobrir o número total de linhas e dividir isso pelo número total de valores distintos na coluna, então neste exemplo o número estimado de linhas para
WHERE val = @Val é 1000 / 10 =100, O algoritmo real é mais complexo do que isso, mas, por exemplo, isso servirá. Então, quando olhamos para o plano de execução para:DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
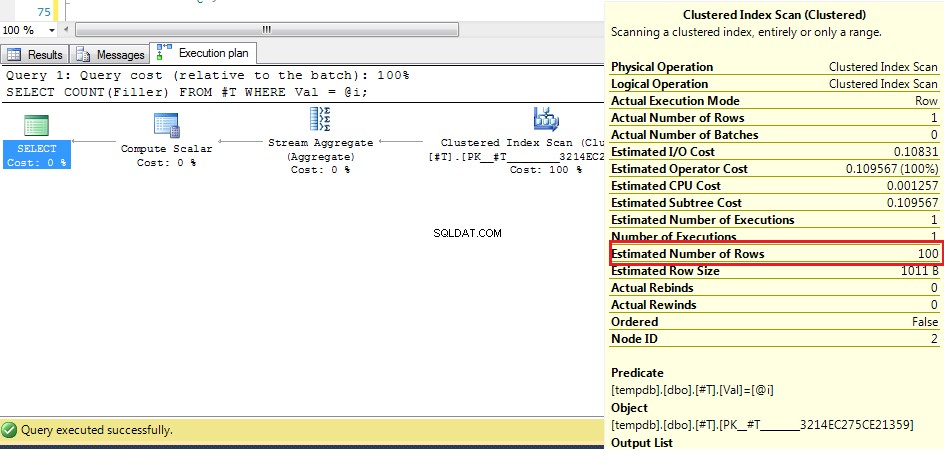
Podemos ver aqui (com os dados originais) que o número estimado de linhas é 100, mas as linhas reais são 1. Das etapas anteriores, sabemos que com mais de 38 linhas o otimizador optará por uma varredura de índice clusterizado em vez de um índice search, portanto, como a melhor estimativa para o número de linhas é maior que isso, o plano para uma variável desconhecida é uma varredura de índice clusterizado.
Apenas para provar ainda mais a teoria, se criarmos a tabela com 1000 linhas de números de 1 a 27 distribuídas uniformemente (portanto, a contagem de linhas estimada será aproximadamente 1000 / 27 =37,037)
IF OBJECT_ID(N'tempdb..#T', 'U') IS NOT NULL
DROP TABLE #T;
CREATE TABLE #T (ID INT IDENTITY PRIMARY KEY, Val INT NOT NULL, Filler CHAR(1000) NULL);
INSERT #T (Val)
SELECT TOP 27 ROW_NUMBER() OVER(ORDER BY a.object_id)
FROM sys.all_objects a;
INSERT #T (val)
SELECT TOP 973 t1.Val
FROM #T AS t1
CROSS JOIN #T AS t2
CROSS JOIN #T AS t3
ORDER BY t2.Val, t3.Val;
CREATE NONCLUSTERED INDEX IX_T__Val ON #T (Val);
Em seguida, execute a consulta novamente, obtemos um plano com uma busca de índice:
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
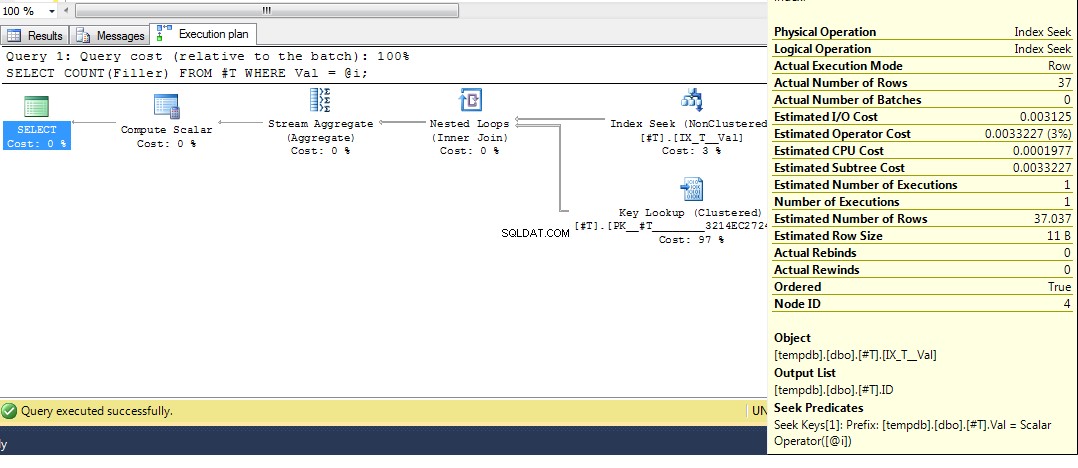
Espero que isso cubra de maneira bastante abrangente por que você obtém esse plano. Agora, suponho que a próxima pergunta seja como você força um plano diferente, e a resposta é usar a dica de consulta
OPTION (RECOMPILE) , para forçar a compilação da consulta em tempo de execução quando o valor do parâmetro for conhecido. Revertendo para os dados originais, onde o melhor plano para Val = 2 é uma pesquisa, mas usando uma variável produz um plano com uma varredura de índice, podemos executar:DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i;
GO
DECLARE @i INT = 2;
SELECT COUNT(Filler)
FROM #T
WHERE Val = @i
OPTION (RECOMPILE);
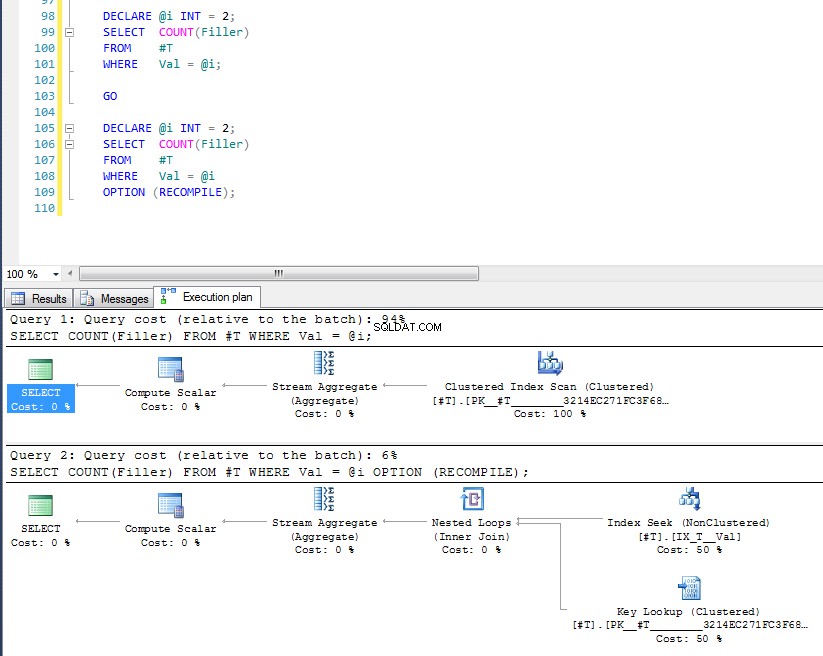
Podemos ver que este último utiliza o index seek e key lookup porque verificou o valor da variável em tempo de execução, e o plano mais adequado para aquele valor específico é escolhido. O problema com
OPTION (RECOMPILE) é que isso significa que você não pode tirar proveito dos planos de consulta em cache, portanto, há um custo adicional de compilar a consulta a cada vez.