Este post é parte de uma série de artigos sobre metas de linha. Você pode encontrar a primeira parte aqui:
- Parte 1:definindo e identificando metas de linha
É relativamente conhecido que usar
TOP ou um FAST n a dica de consulta pode definir uma meta de linha em um plano de execução (consulte Definindo e identificando metas de linha em planos de execução se você precisar de uma atualização sobre metas de linha e suas causas). É bem menos comum que semijunções (e antijunções) também possam introduzir um objetivo de linha, embora isso seja um pouco menos provável do que é o caso de TOP , FAST e SET ROWCOUNT . Este artigo ajudará você a entender quando e por que uma semijunção invoca a lógica de meta de linha do otimizador.
Semi-junções
Uma semijunção retorna uma linha de uma entrada de junção (A) se houver pelo menos uma linha correspondente na outra entrada de junção (B).
As diferenças essenciais entre uma semijunção e uma junção regular são:
- A semijunção retorna cada linha da entrada A ou não. Nenhuma duplicação de linha pode ocorrer.
- A junção regular duplica as linhas se houver várias correspondências no predicado de junção.
- A semijunção é definida para retornar apenas colunas da entrada A.
- A junção regular pode retornar colunas de uma (ou ambas) entradas de junção.
T-SQL atualmente não tem suporte para sintaxe direta como
FROM A SEMI JOIN B ON A.x = B.y , então precisamos usar formas indiretas como EXISTS , SOME/ANY (incluindo a abreviação equivalente IN para comparações de igualdade) e defina INTERSECT . A descrição de uma semijunção acima indica naturalmente a aplicação de um objetivo de linha, pois estamos interessados em encontrar qualquer linha correspondente em B, não todas essas linhas . No entanto, uma semijunção lógica expressa em T-SQL pode não levar a um plano de execução usando uma meta de linha por vários motivos, que serão descompactados a seguir.
Transformação e simplificação
Uma semi-junção lógica pode ser simplificada ou substituída por outra coisa durante a compilação e otimização da consulta. O exemplo do AdventureWorks abaixo mostra uma semijunção sendo removida totalmente, devido a um relacionamento de chave estrangeira confiável:
SELECT TH.ProductID FROM Production.TransactionHistory AS THWHERE TH.ProductID IN(SELECT P.ProductID FROM Production.Product AS P);
A chave estrangeira garante que
Product sempre existirão linhas para cada linha do Histórico. Como resultado, o plano de execução acessa apenas o TransactionHistory tabela: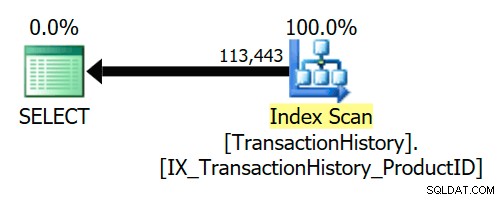
Um exemplo mais comum é visto quando a semijunção pode ser transformada em uma junção interna. Por exemplo:
SELECT P.ProductID FROM Production.Product AS P WHERE EXISTS(SELECT * FROM Production.ProductInventory AS INV WHERE INV.ProductID =P.ProductID);
O plano de execução mostra que o otimizador introduziu um agregado (agrupamento em
INV.ProductID ) para garantir que a junção interna possa retornar apenas Product linhas uma vez ou nenhuma (conforme necessário para preservar a semântica de semijunção):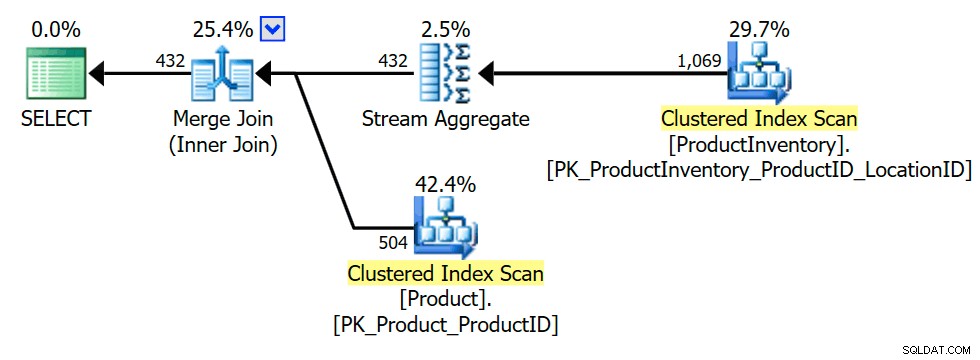
A transformação para junção interna é explorada cedo porque o otimizador conhece mais truques para equijunções internas do que para semijunções, potencialmente levando a mais oportunidades de otimização. Naturalmente, a escolha final do plano ainda é uma decisão baseada em custo entre as alternativas exploradas.
Otimizações antecipadas
Embora o T-SQL não tenha
SEMI JOIN direto sintaxe, o otimizador sabe tudo sobre semijunções nativamente e pode manipulá-las diretamente. As sintaxes de semijunção comuns da solução alternativa são transformadas em uma semijunção interna "real" no início do processo de compilação da consulta (bem antes mesmo de um plano trivial ser considerado). Os dois principais grupos de sintaxe de solução alternativa são
EXISTS/INTERSECT , e ANY/SOME/IN . O EXISTS e INTERSECT casos diferem apenas porque o último vem com um DISTINCT implícito (agrupamento em todas as colunas projetadas). Ambos EXISTS e INTERSECT são analisados como um EXISTS com subconsulta correlacionada. O ANY/SOME/IN representações são todas interpretadas como uma operação SOME. Podemos explorar antecipadamente essa atividade de otimização com alguns sinalizadores de rastreamento não documentados, que enviam informações sobre a atividade do otimizador para a guia de mensagens do SSMS. Por exemplo, a semi-junção que usamos até agora também pode ser escrita usando
IN :SELECT P.ProductIDFROM Production.Product AS PWHERE P.ProductID IN /* ou =ANY/SOME */(SELECT TH.ProductID FROM Production.TransactionHistory AS TH)OPTION (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621);
A árvore de entrada do otimizador é a seguinte:

O operador escalar ScaOp_SomeComp é oSOMEcomparação mencionada acima. O 2 é o código para um teste de igualdade, poisINé equivalente a= SOME. Se você estiver interessado, existem códigos de 1 a 6 representando operadores de comparação (<, =, <=,>, !=,>=) respectivamente.
Retornando aoEXISTSsintaxe que prefiro usar com mais frequência para expressar uma semi-junção indiretamente:
SELECT P.ProductIDFROM Production.Product AS PWHERE EXISTS(SELECT * FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID)OPÇÃO (QUERYTRACEON 3604, QUERYTRACEON 8606, QUERYTRACEON 8621);
A árvore de entrada do otimizador é:

Essa árvore é uma tradução bastante direta do texto da consulta; embora note que oSELECT *já foi substituído por uma projeção do valor inteiro constante 1 (veja a penúltima linha de texto).
A próxima coisa que o otimizador faz é desaninhar a subconsulta na seleção relacional (=filtro) usando a regra RemoveSubqInSel . O otimizador sempre faz isso, pois não pode operar diretamente em subconsultas. O resultado é uma aplicação (também conhecido como junção correlacionada ou lateral):

(A mesma regra de remoção de subconsulta produz a mesma saída para oSOMEárvore de entrada também).
O próximo passo é reescrever a aplicação como uma junção regular usando o ApplyHandler regra família. Isso é algo que o otimizador sempre tenta fazer, porque tem mais regras de exploração para junções do que para aplicar. Nem toda aplicação pode ser reescrita como uma junção, mas o exemplo atual é direto e bem-sucedido:

Observe que o tipo de junção é semi à esquerda. De fato, esta é exatamente a mesma árvore que obteríamos imediatamente se o T-SQL suportasse sintaxe como:
SELECT P.ProductID FROM Production.Product AS P LEFT SEMI JOIN Produção.TransactionHistory AS TH ON TH.ProductID =P.ProductID;
Seria bom poder expressar consultas mais diretamente assim. De qualquer forma, o leitor interessado é encorajado a explorar as atividades de simplificação acima com outras formas logicamente equivalentes de escrever essa semijunção em T-SQL.
O importante neste estágio é que o otimizador sempre remove as subconsultas , substituindo-os por um apply. Em seguida, ele tenta reescrever a aplicação como uma junção regular para maximizar as chances de encontrar um bom plano. Lembre-se de que todo o precedente ocorre antes mesmo de um plano trivial ser considerado. Durante a otimização baseada em custo, o otimizador também pode considerar a transformação de junção de volta para uma aplicação.
Hash e Mesclar Semi Junção
O SQL Server tem três opções de implementações físicas principais disponíveis para uma semi-junção lógica. Enquanto um predicado de equijoin estiver presente, o hash e o merge join estarão disponíveis; ambos podem operar nos modos de semi-junção esquerda e direita. A junção de loops aninhados suporta apenas a semijunção esquerda (não a direita), mas não requer um predicado de equijoin. Vejamos as opções físicas de hash e mesclagem para nossa consulta de exemplo (escrita como uma interseção de conjunto desta vez):
SELECT P.ProductID FROM Production.Product AS PINTERSECTSELECT TH.ProductID FROM Production.TransactionHistory AS TH;
O otimizador pode encontrar um plano para todas as quatro combinações de semijunção (esquerda/direita) e (hash/merge) para esta consulta:
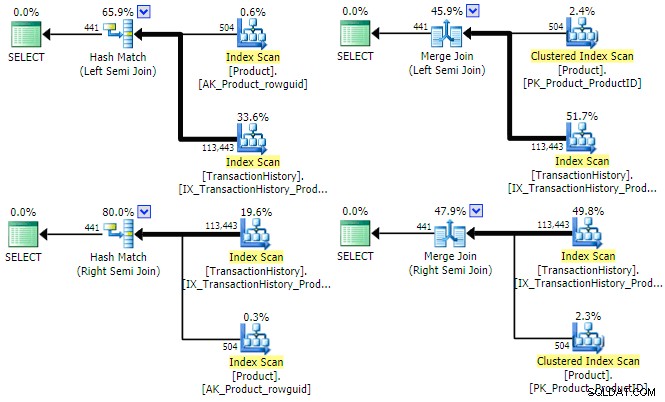
Vale a pena mencionar brevemente porque o otimizador pode considerar ambas as semijunções esquerda e direita para cada tipo de junção. Para a semijunção de hash, uma consideração importante de custo é o tamanho estimado da tabela de hash, que é sempre a entrada esquerda (superior) inicialmente. Para a semijunção de mesclagem, as propriedades de cada entrada determinam se uma mesclagem de um para muitos ou menos eficiente de muitos para muitos com a tabela de trabalho será usada.
Pode ser aparente nos planos de execução acima que nem hash nem merge semi join se beneficiariam da definição de uma meta de linha . Ambos os tipos de junção sempre testam o predicado de junção na própria junção e visam consumir todas as linhas de ambas as entradas para retornar um conjunto de resultados completo. Isso não quer dizer que não existam otimizações de desempenho para junção de hash e mesclagem em geral – por exemplo, ambos podem utilizar bitmaps para reduzir o número de linhas que atingem a junção. Em vez disso, o ponto é que um objetivo de linha em qualquer entrada não tornaria um hash ou merge semi join mais eficiente.
Loops aninhados e aplicar semijunção
O tipo de junção física restante são loops aninhados, que vêm em dois tipos:loops aninhados regulares (não correlacionados) e aplicar loops aninhados (às vezes também chamados de correlacionados ou lateral Junte-se).
A junção de loops aninhados regulares é semelhante à junção de hash e mesclagem em que o predicado de junção é avaliado na junção. Como antes, isso significa que não há valor em definir uma meta de linha em qualquer entrada. A entrada esquerda (superior) sempre será totalmente consumida eventualmente, e a entrada interna não tem como determinar quais linhas devem ser priorizadas, pois não podemos saber se uma linha será unida ou não até que o predicado seja testado na junção .
Por outro lado, uma junção de loops aninhados de aplicação tem uma ou mais referências externas (parâmetros correlacionados) na junção, com o predicado de junção pressionado o lado interno (inferior) da junção. Isso cria uma oportunidade para a aplicação útil de uma meta de linha. Lembre-se de que uma semijunção exige apenas que verifiquemos a existência de uma linha na entrada de junção B que corresponda à linha atual na entrada de junção A (pensando apenas em estratégias de junção de loops aninhados agora).
Em outras palavras, em cada iteração de um apply, podemos parar de olhar para a entrada B assim que a primeira correspondência for encontrada, usando o predicado de junção empurrado para baixo. Este é exatamente o tipo de coisa para a qual uma meta de linha é boa:gerar parte de um plano otimizado para retornar as primeiras n linhas correspondentes rapidamente (onden = 1aqui).
Claro, um gol de linha pode ser uma coisa boa ou não, dependendo das circunstâncias. Não há nada de especial sobre o objetivo de semi-juntar a esse respeito. Considere uma situação em que o lado interno da semijunção é mais complexo do que um único acesso a uma tabela simples, talvez uma junção de várias tabelas. Definir uma meta de linha pode ajudar o otimizador a selecionar uma estratégia de navegação eficiente apenas para essa subárvore específica , encontrando a primeira linha correspondente para satisfazer a semijunção por meio de junções de loops aninhados e buscas de índice. Sem o objetivo de linha, o otimizador pode naturalmente escolher hash ou mesclar junções com classificações para minimizar o custo esperado de retornar todas as linhas possíveis. Observe que há uma suposição aqui, a saber, que as pessoas normalmente escrevem semijunções com a expectativa de que uma linha que corresponda à condição de pesquisa realmente exista. Isso me parece uma suposição bastante justa.
Independentemente disso, o ponto importante nesta fase é:Somente aplicar a junção de loops aninhados tem um objetivo de linha aplicado pelo otimizador (lembre-se, porém, que um objetivo de linha para a junção de loops aninhados é adicionado apenas se o objetivo de linha for menor que a estimativa sem ele). Veremos alguns exemplos trabalhados para deixar tudo isso claro a seguir.
Exemplos de semijunção de loops aninhados
O script a seguir cria duas tabelas temporárias de heap. A primeira tem números de 1 a 20 inclusive; o outro tem 10 cópias de cada número da primeira tabela:
DROP TABLE SE EXISTE #E1, #E2; CREATE TABLE #E1 (c1 inteiro NULL);CREATE TABLE #E2 (c1 inteiro NULL); INSERT #E1 (c1)SELECT SV.numberFROM master.dbo.spt_values AS SVWHERE SV.[tipo] =N'P' AND SV.number>=1 AND SV.number <=20; INSERT #E2 (c1)SELECT (SV.number % 20) + 1FROM master.dbo.spt_values AS SVWHERE SV.[tipo] =N'P' AND SV.number>=1 AND SV.number <=200;
Sem índices e com um número relativamente pequeno de linhas, o otimizador escolhe uma implementação de loops aninhados (em vez de hash ou mesclagem) para a seguinte consulta de semijunção). Os sinalizadores de rastreamento não documentados nos permitem ver a árvore de saída do otimizador e as informações de meta de linha:
SELECT E1.c1 FROM #E1 AS E1WHERE E1.c1 IN (SELECT E2.c1 FROM #E2 AS E2)OPÇÃO (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);
O plano de execução estimado apresenta uma junção de loops aninhados de semi-junção, com 200 linhas por varredura completa da tabela#E2. As 20 iterações do loop fornecem uma estimativa total de 4.000 linhas:
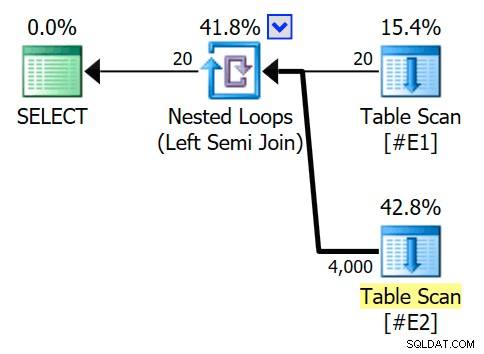
As propriedades do operador de loops aninhados mostram que o predicado é aplicado na junção significando que esta é uma junção de loops aninhados não correlacionados :
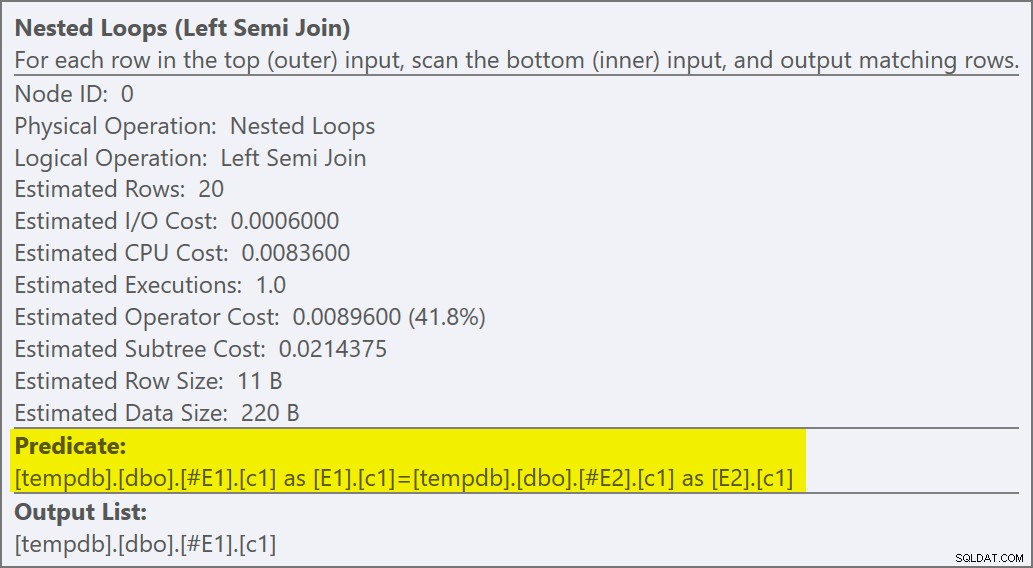
A saída do sinalizador de rastreamento (na guia de mensagens do SSMS) mostra uma semi-junção de loops aninhados e nenhum objetivo de linha (RowGoal 0):

Observe que o plano de pós-execução para esta consulta de brinquedo não mostrará 4.000 linhas lidas da tabela #E2 no total. A semijunção de loops aninhados (correlacionados ou não) parará de procurar mais linhas no lado interno (por iteração) assim que a primeira correspondência para a linha externa atual for encontrada. Agora, a ordem das linhas encontradas na varredura de heap de #E2 em cada iteração não é determinística (e pode ser diferente em cada iteração), então em princípio quase todas as linhas podem ser testadas em cada iteração, caso a linha correspondente seja encontrada o mais tarde possível (ou, de fato, no caso de nenhuma linha correspondente, de modo algum).
Por exemplo, se assumirmos uma implementação de tempo de execução em que as linhas são verificadas na mesma ordem (por exemplo, "ordem de inserção") a cada vez, o número total de linhas verificadas neste exemplo de brinquedo seria 20 linhas na primeira iteração, 1 linha na segunda iteração, 2 linhas na terceira iteração e assim por diante para um total de 20 + 1 + 2 + (…) + 19 =210 linhas. Na verdade, é bem provável que você observe esse total, que diz mais sobre as limitações do código de demonstração simples do que sobre qualquer outra coisa. Não se pode confiar na ordem das linhas retornadas de um método de acesso não ordenado mais do que se pode confiar na saída aparentemente ordenada de uma consulta sem umORDER BYde nível superior cláusula.
Aplicar Semi Junção
Agora criamos um índice não clusterizado na tabela maior (para incentivar o otimizador a escolher uma semijunção de aplicação) e executamos a consulta novamente:
CRIAR ÍNDICE NÃO-CLUSTER nc1 ON #E2 (c1); SELECT E1.c1 FROM #E1 AS E1WHERE E1.c1 IN (SELECT E2.c1 FROM #E2 AS E2)OPÇÃO (QUERYTRACEON 3604, QUERYTRACEON 8607, QUERYTRACEON 8612);
O plano de execução agora apresenta uma semi-junção de aplicação, com 1 linha por busca de índice (e 20 iterações como antes):
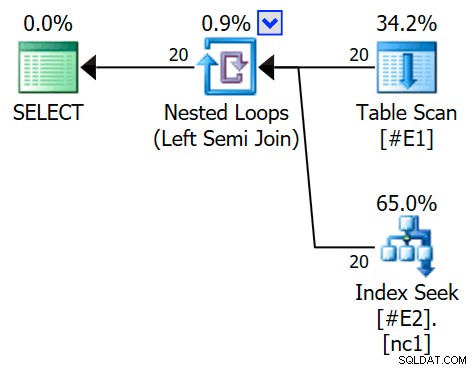
Podemos dizer que é uma aplicação de semi-junção porque as propriedades de junção mostram uma referência externa em vez de um predicado de junção:
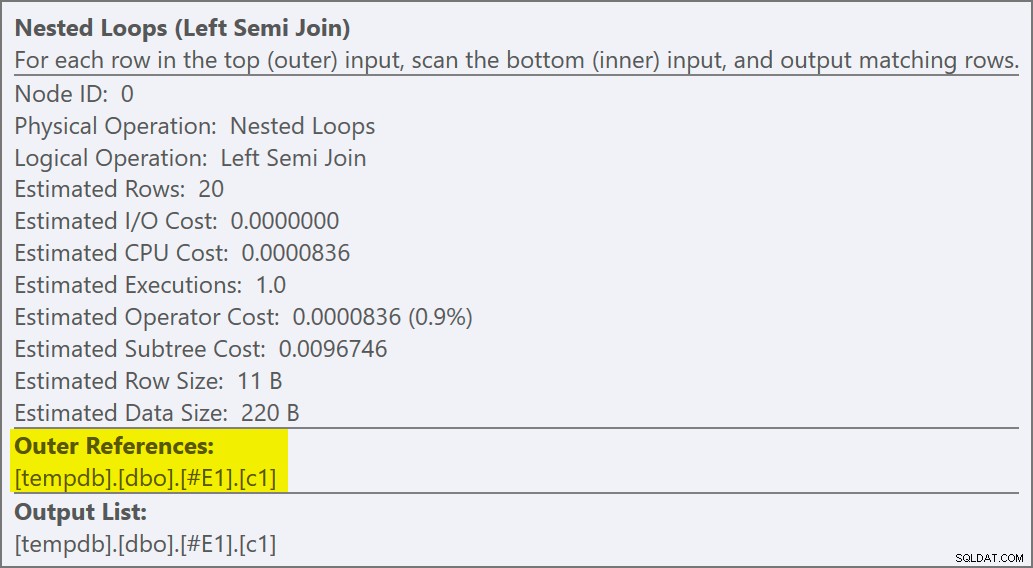
O predicado de junção foi abaixado o lado interno da aplicação e correspondido ao novo índice:
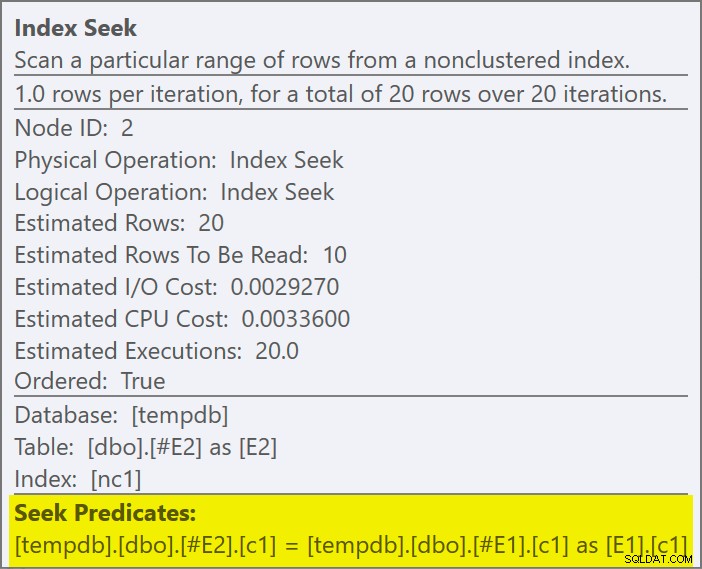
Espera-se que cada busca retorne 1 linha, apesar de cada valor ser duplicado 10 vezes nessa tabela; isso é um efeito da meta de linha . A meta de linha será mais fácil de identificar em compilações do SQL Server que expõem o EstimateRowsWithoutRowGoal atributo de plano (SQL Server 2017 CU3 no momento da escrita). Em uma próxima versão do Plan Explorer, isso também será exposto em dicas de ferramentas para operadores relevantes:

A saída do sinalizador de rastreamento é:
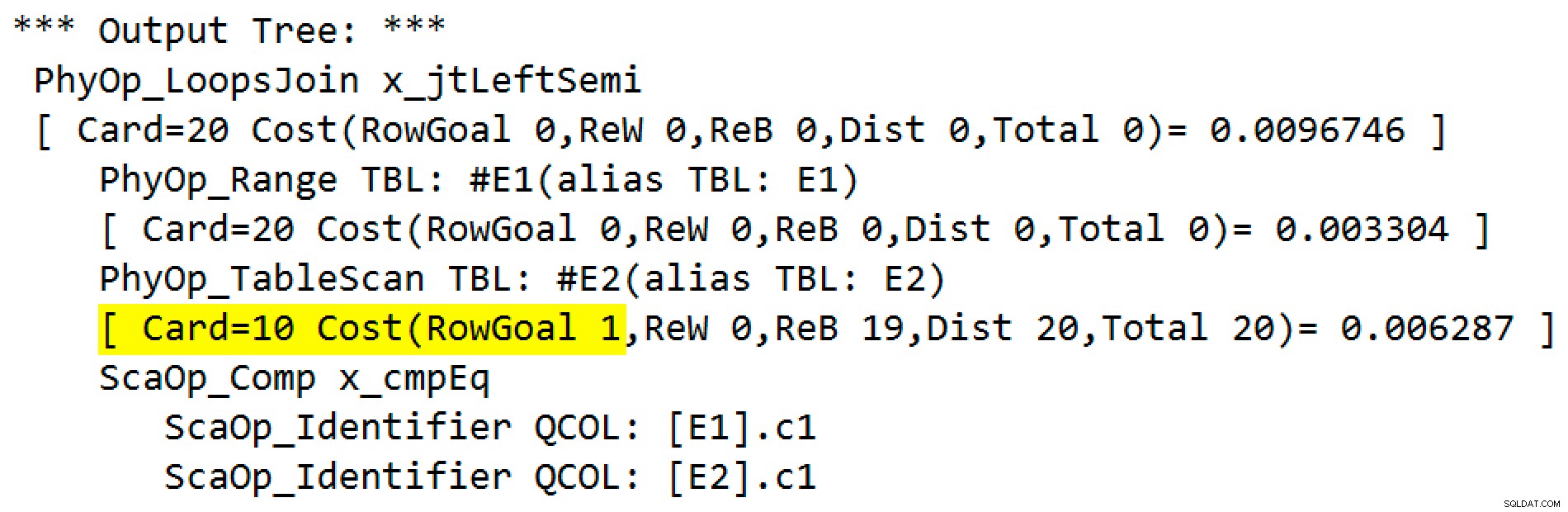
O operador físico mudou de uma junção de loops para uma aplicação em execução no modo de semijunção esquerda. Acesso à tabela#E2adquiriu uma meta de linha de 1 (a cardinalidade sem a meta de linha é mostrada como 10). A meta de linha não é um grande problema neste caso porque o custo de recuperar uma estimativa de dez linhas por busca não é muito maior do que para uma linha. Desativando metas de linha para esta consulta (usando o sinalizador de rastreamento 4138 ou oDISABLE_OPTIMIZER_ROWGOALdica de consulta) não alteraria a forma do plano.
No entanto, em consultas mais realistas, a redução de custos devido ao objetivo da linha interna pode fazer a diferença entre as opções de implementação concorrentes. Por exemplo, desabilitar a meta de linha pode fazer com que o otimizador escolha um hash ou uma semijunção de mesclagem, ou qualquer uma das muitas outras opções consideradas para a consulta. Se nada mais, o objetivo da linha aqui reflete com precisão o fato de que uma semi-junção aplicada parará de pesquisar o lado interno assim que a primeira correspondência for encontrada e passará para a próxima linha lateral externa.
Observe que duplicatas foram criadas na tabela#E2de modo que o objetivo de aplicar semijunção de linha (1) seja menor que a estimativa normal (10, a partir de informações de densidade estatística). Se não houver duplicatas, a estimativa de linha para cada busca em#E2também seria 1 linha, então uma meta de linha de 1 não seria aplicada (lembre-se da regra geral sobre isso!)
Linha de metas versus Topo
Dado que os planos de execução não indicam a presença de uma meta de linha antes do SQL Server 2017 CU3, pode-se pensar que seria mais claro implementar essa otimização usando um operador Top explícito, em vez de uma propriedade oculta como uma meta de linha. A ideia seria simplesmente colocar um operador Top (1) no lado interno de uma junção semi/anti aplicada em vez de definir uma meta de linha na própria junção.
Usar um operador Top dessa maneira não teria sido totalmente sem precedentes. Por exemplo, já existe uma versão especial do Top conhecido como topo de contagem de linhas visto em planos de execução de modificação de dados quando umSET ROWCOUNTdiferente de zero está em vigor (observe que esse uso específico foi preterido desde 2005, embora ainda seja permitido no SQL Server 2017). A implementação do topo da contagem de linhas é um pouco desajeitada, pois o operador superior é sempre mostrado como um Top (0) no plano de execução, independentemente do limite real de contagem de linhas em vigor.
Não há nenhuma razão convincente para que o objetivo de linha de semijunção de aplicação não possa ter sido substituído por um operador Top (1) explícito. Dito isso, existem alguns motivos para preferir não fazer isso:
- Adicionar um Top (1) explícito requer mais esforço e teste de codificação do otimizador do que adicionar uma meta de linha (que já é usada para outras coisas).
- Top não é um operador relacional; o otimizador tem pouco suporte para raciocinar sobre isso. Isso pode afetar negativamente a qualidade do plano, limitando a capacidade do otimizador de transformar partes de um plano de consulta, por exemplo movendo agregados, uniões, filtros e junções.
- Isso introduziria um acoplamento forte entre a implementação de aplicação da semijunção e o topo. Casos especiais e acoplamento rígido são ótimas maneiras de introduzir bugs e tornar as alterações futuras mais difíceis e propensas a erros.
- O Top (1) seria logicamente redundante e estaria presente apenas para o efeito colateral da meta de linha.
Vale a pena expandir esse último ponto com um exemplo:
SELECT P.ProductID FROM Production.Product AS PWHERE EXISTS ( SELECT TOP (1) TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID );
O
TOP (1) na subconsulta existe é simplificada pelo otimizador, fornecendo um plano de execução de semi-junção simples: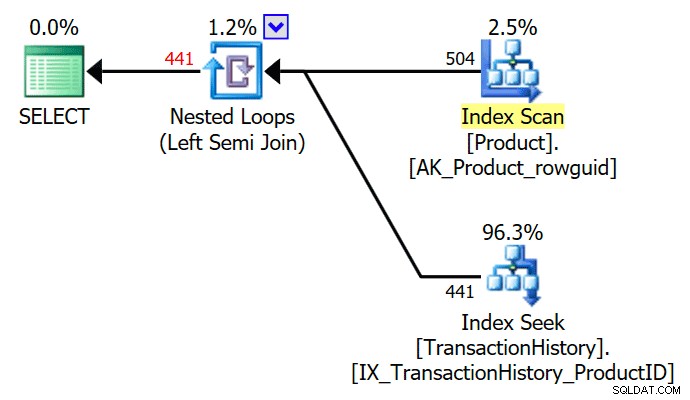
O otimizador também pode remover um
DISTINCT redundante ou GROUP BY na subconsulta. Todos os seguintes produzem o mesmo plano acima:-- Redundante DISTINCTSELECT P.ProductID FROM Production.Product AS PWHERE EXISTS (SELECT DISTINCT TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID); -- Redundante GROUP BYSELECT P.ProductID FROM Production.Product AS PWHERE EXISTS (SELECT TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID GROUP BY TH.ProductID); -- Redundante DISTINCT TOP (1)SELECT P.ProductID FROM Production.Product AS PWHERE EXISTS (SELECT DISTINCT TOP (1) TH.ProductID FROM Production.TransactionHistory AS TH WHERE TH.ProductID =P.ProductID );
Resumo e Considerações Finais
Apenas aplicar loops aninhados semi join podem ter uma meta de linha definida pelo otimizador. Este é o único tipo de junção que empurra o(s) predicado(s) de junção para baixo da junção, permitindo que o teste da existência de uma correspondência seja executado antes . Semi-junção de loops aninhados não correlacionados quase nunca* define um objetivo de linha, e nem um hash ou merge semi join. A aplicação de loops aninhados pode ser diferenciada da junção de loops aninhados não correlacionados pela presença de referências externas (em vez de um predicado) no operador de junção de loops aninhados para uma aplicação.
As chances de ver uma semi-junção de aplicação no plano de execução final dependem um pouco da atividade de otimização inicial. Na falta de sintaxe T-SQL direta, temos que expressar semijunções em termos indiretos. Eles são analisados em uma árvore lógica contendo uma subconsulta, que a atividade do otimizador inicial transforma em uma aplicação e, em seguida, em uma semijunção não correlacionada, sempre que possível.
Essa atividade de simplificação determina se uma semijunção lógica é apresentada ao otimizador baseado em custo como uma semijunção de aplicação ou regular. Quando apresentado como um aplicar lógico semi join, é quase certo que o CBO produzirá um plano de execução final com loops aninhados de aplicação física (e, portanto, definindo uma meta de linha). Quando apresentado com uma semijunção não correlacionada, o CBO pode considere a transformação para uma aplicação (ou não). A escolha final do plano é uma série de decisões baseadas em custos, como de costume.
Como todos os objetivos de linha, o objetivo de semi-juntar pode ser bom ou ruim para o desempenho. Saber que uma semijunção de aplicação define uma meta de linha pelo menos ajudará as pessoas a reconhecer e abordar a causa se ocorrer um problema. A solução nem sempre (ou mesmo geralmente) desabilitará os objetivos de linha para a consulta. Aprimoramentos na indexação (e/ou na consulta) geralmente podem ser feitos para fornecer uma maneira eficiente de localizar a primeira linha correspondente.
Vou cobrir anti semijunções em um artigo separado, continuando a série de gols de linha.
* A exceção é uma semi-junção de loops aninhados não correlacionados sem nenhum predicado de junção (uma visão incomum). Isso define uma meta de linha.